论文《AUDIO LARGE LANGUAGE MODELS CAN BE DESCRIPTIVE SPEECH QUALITY EVALUATORS》学习
推动多模态代理从"能听"到"懂好坏"的进化
摘要:
. 研究背景与问题
- 核心内容:现有
音频大语言模型缺乏对输入语音质量的感知能力,因为语音质量评估需要多任务训练,但 ++缺乏合适的数据集++。 - 举例说明:假设一个语音助手接收到一段包
含背景噪音的用户指令(如咖啡厅嘈杂环境下的语音),现有音频LLMs可能无法判断这段语音的质量问题(如信噪比低),导致后续任务(如转写或理解)出现错误。
.创新数据集的构建
- 核心内容:作者构建了首个基于自然语言的
语音质量评估语料库,包含人类真实评分、多维分析和质量退化原因的标注,支持A/B对比测试。
.方法创新(ALLD对齐框架)
- 核心内容:提出结合LLM蒸馏的对齐方法(ALLD),指导音频LLM从原始语音中提取信息并生成有意义的响应。
- 示例:假设输入一段有回声的会议录音,ALLD框架会让音频LLM完成以下任务:
- 特征提取:识别回声的时域特征和频域特征。
- 质量评估:生成自然语言描述如"此段语音存在明显的会议室回声,影响对话清晰度"。
- 对比分析:在A/B测试中比较两段录音,生成结论"样本B的回声抑制效果优于样本A"。
.实验结果优势
- 核心内容:ALLD在MOS预测误差(MSE=0.17)、A/B测试准确率(98.6%)和生成质量(BLEU分数25.8/30.2)上超越现有模型。
- 示例:
- A/B测试:当比较两段压缩率不同的语音(128kbps vs. 64kbps)时,ALLD能准确判断高码率语音质量更优。
- 生成质量:针对一段低质量语音,ALLD生成描述"此语音存在周期性电流噪音,建议检查录音设备接地",而传统模型仅输出"质量较差"。
引言:
语音质量评估的重要性
- MOS作为关键指标:在现代通信网络中,平均意见得分(MOS)是评估语音质量的重要指标。它通过收集大量人类听众的主观评分来确定语音的质量水平。
- 现有方法的局限性 :许多深度神经网络致力于将预测平均MOS作为回归任务来完成。然而,
主观评分存在显著差异,现有数据集中的标注也显示出不可忽视的方差,这使得仅预测一个数值MOS过于简单,++无法深入了解质量估计的潜在原因。++
提出新方法的动机
- 学习人类的评价方式 :鉴于现有方法的不足,作者们希望教会LLMs
像人类一样评估语音质量,提供描述性分析和合理的判断。 - 自动化评估的应用价值:这种理解能力具有重要意义,可用于自动化评估现代生成系统的性能,例如文本转语音或语音编辑模型。
- 例子 :
- 输入:一段含电流噪音的语音;
- LLM输出:"此语音MOS评分为2.3。主要问题为高频电流噪音(强度-20dB),覆盖了30%的语音频段。建议检查录音设备接地情况。"
- 优势:
- 自动化诊断:直接定位质量问题的技术原因;
- 支持生成系统优化:例如TTS模型可根据反馈调整降噪模块。
与学术研究趋势的契合
- 理解和生成任务的统一:将理解和生成任务整合到一个基于Transformer的模型中,已成为学术研究的显著趋势。从这个角度来看,一个了解输入质量的模型变得越来越重要,因为它有可能使模型作为一个智能体,进入自我改进的循环。
理解:分析生成语音的质量问题(如"合成语音存在机械感");
生成:根据分析调整参数重新生成(如增加韵律多样性);
闭环优化:迭代直至质量达标。现有数据集的不足
- 缺乏自然语言描述 :现有的人类语音质量数据集++仅包含数值评分++ ,没有包括任何基于自然语言的
描述或分析。这种不足限制了对语音质量更深入的理解和评估。(Existing human speech quality datasets consist solely of numerical scores, and do not include any natural language-based descriptions or analyses.)
新数据集的构建
- 引入新数据集 :作者们首次填补了这一空白,引入了一个新的数据集,该数据集基于
真实的人类评分,包含自然语言描述。(In this work, we first bridge this gap by introducing a new dataset comprising natural language descriptions generated based on authentic human ratings of multidimensional speech quality assessment corpus ) - 数据集的构成:具体来说,对于每个语音样本,他们利用语料库中的元信息,提示LLMs根据多维语音质量评估语料库生成与其多维特征一致的分析,包括推理过程和最终的总体MOS评分。
- 例子(每一个子维度都分析到位) :
-
输入数据:原始语音 + 元信息(如"清晰度4分,噪声等级3分,失真原因:设备压缩")。
-
提示设计:通过示例(demonstrations)指导LLM生成结构化分析,例如:"请根据以下元信息生成描述:清晰度4/5,噪声等级3/5,失真原因:设备压缩。要求:先分析子维度,再总结MOS。"
-
输出结果:"此
语音清晰度较高(评分高部分维度),但存在中等强度背景噪声(评分低部分维度)(如风扇声)。主要质量问题是设备压缩导致的轻微失真。综合评分MOS=3.2。"
-
示例与A/B测试数据集
-
分析:例如,一段语音可能被描述为:"这段语音有非常轻微的失真,没有背景噪音。然而,存在明显的不连续性,显著影响了其感知质量。综合所有因素,总体MOS评分仅为2.4。"
-
A/B测试数据集 :此外,还构建了一个A/B测试数据集,采用类似的策略。他们选取两段语音片段,要求LLM对它们在特定子维度上的优缺点进行
描述性比较,最终得出一个有充分理由的偏好判断,如图2所示。从语料库中选取两段语音(A和B),要求LLM基于子维度对比生成判断,而非简单选择"更好"。 语音A:MOS=3.5,元信息标注"噪声抑制强,但语音自然度低"; 语音B:MOS=3.2,元信息标注"噪声残留明显,但语音流畅自然"。 LLM生成对比: "语音A的噪声抑制效果更优(噪音强度-25dB vs. -18dB),但语音B的自然度更高(自然度评分4.2 vs. 3.1)。 若优先考虑通话清晰度,推荐选择A;若注重听感舒适度,建议选择B。" 意义:训练模型理解质量权衡(trade-off),模拟人类复杂的决策过程。
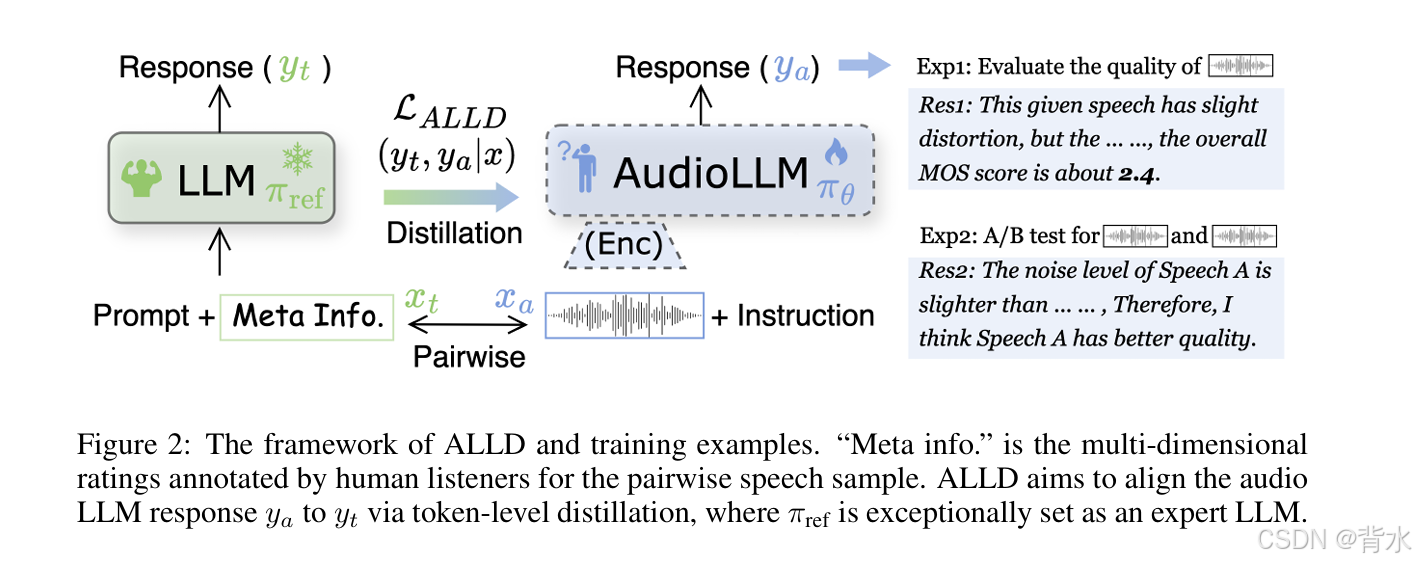
ALLD
教师模型(LLM)
- "元信息(Meta Info.) "是由人类听者为
成对语音样本标注的多维评级。 - 传统的大型语言模型(LLM)作为教师模型( π r e f \pi_{ref} πref),用于生成高质量的文本响应 y t y_t yt。
- 输入: P r o m p t + M e t a I n f o . Prompt + Meta Info. Prompt+MetaInfo.
- 输出: y t y_t yt
学生模型(Audio LLM)
- 目标是训练一个专门用于音频任务的 LLM(AudioLLM),它需要学习从音频输入 x a x_a xa 和指令Instruction中生成与教师模型类似的文本响应 y a y_a ya
- 输入: 语音信号( x a ) + 指令( I n s t r u c t i o n ) 语音信号(x_a)+ 指令(Instruction) 语音信号(xa)+指令(Instruction)
- 输出: y a y_a ya
蒸馏过程(Distillation)
- 通过最小化损失函数 L A L L D L_{ALLD} LALLD,使Audio LLM的输出 y a y_a ya尽可能接近专家LLM的输出 y t y_t yt。
训练示例
-
示例1(Exp1):评估单段语音的质量。
输入语音:一段语音信号。 专家LLM输出(Res1):这段语音有轻微失真,但没有背景噪音。 然而,存在明显的不连续性,显著影响了其感知质量。 综合所有因素,总体MOS评分仅为2.4。 目标:通过蒸馏,使Audio LLM能够生成类似的自然语言描述和质量评估。 -
示例2(Exp2):对两段语音进行A/B测试。
输入语音:两段语音信号。 专家LLM输出(Res2):语音A的噪音水平比语音B稍低,因此我认为语音A的质量更好。 目标:通过蒸馏,使Audio LLM能够对两段语音进行比较, 分析它们在特定子维度上的优缺点,并给出有理由的偏好判断。
实验过程:
蒸馏训练: 通过ALLD策略,将专家LLM的输出(包含详细自然语言描述和评分)作为参考,训练Audio LLM。在训练过程中,使用蒸馏,使Audio LLM的输出尽可能接近专家LLM的输出。
任务执行:在训练好的Audio LLM上进行两个主要任务的测试:
- MOS预测任务:评估单段语音的质量,预测其MOS值。
- A/B测试任务:比较两段语音的质量,进行描述性分析并给出偏好判断。
实验结果:
-
MOS预测结果:实验结果显示,ALLD在MOS预测任务上达到了
0.17的均方误差,这表明Audio LLM能够非常准确地预测语音的总体质量评分。 -
A/B测试结果:在A/B测试任务上,ALLD达到了
98.6%的准确率,说明Audio LLM能够非常可靠地比较两段语音的质量,并给出合理的偏好判断。传统方法:语音 → 回归模型 → MOS数值(如3.7分)
本文方案:语音 → 音频LLM → 数值 + 描述性分析(如"MOS=3.7,因背景风声导致清晰度下降") →未来: 自我优化指令(如"启用降风噪模块")
BACKGROUND
音频大语言模型(Audio LLMs)的分类
音频LLMs根据声学表示形式可分为两类:
(1) 离散化表示模型
- 方法:使用音频编解码器(audio codec)将原始语音离散化为符号序列(如token),扩展LLM的词表以支持跨模态交互。
- 示例 :
- 模型:如VALL-E(Zhang et al., 2023)将语音编码为离散token,LLM直接处理这些token生成语音或文本。
- 应用场景:语音合成(TTS)中生成音色一致的语音,但可能丢失声学细节(如细微的背景噪声)。
- 局限性:离散化可能损失连续声学特征(如频谱连续性),影响质量评估任务的细粒度分析。
(2) 连续表示模型
- 方法:使用预训练编码器(如ASR模型或自监督模型)处理原始波形,通过模态适配器(adapter)将连续特征与LLM的文本嵌入对齐。
- 示例 :
- 模型:如SpeechLLaMA(Chu et al., 2024)使用WavLM编码器提取语音特征,适配器将其映射至LLM输入空间。
- 优势:保留声学细节(如噪声频谱、失真波形),适合需要精细特征的质量评估任务。
- 本文选择:作者采用此类模型(见图2架构),因可训练编码器能有效提取质量相关特征(如信噪比、频谱平坦度)。
语音质量的多维描述
四个核心维度
- Noisiness(噪声水平)
- 定义:背景噪声的强度与干扰程度。
- 示例:咖啡厅环境噪声(信噪比15dB)导致语音MOS下降至3.0。
- Coloration(音色失真)
- 定义:语音频谱的异常变化(如回声、共振峰偏移)。
- 示例:电话语音因带宽限制(300Hz-3.4kHz)导致高频丢失,MOS降至2.5。
- Discontinuity(不连续性)
- 定义:语音中断或跳变(如网络抖动导致的丢包)。
- 示例:视频会议中0.5秒的静音导致MOS=1.8。
- Loudness(响度)
- 定义:语音整体音量水平,虽与其他维度非完全正交,但显著影响感知。
- 示例:过低的响度(-30dB)使听众需反复调高音量,MOS=2.2。
维度与MOS的相关性分析
基于NISQA数据集(2.5k样本)的统计结果(见图1):
- Coloration :Pearson系数0.82(最高),说明音色失真对MOS影响最大。
- 示例:一段语音因设备压缩导致频谱畸变(Coloration评分1.5),MOS仅2.0。
- Loudness:系数0.81,接近Coloration,表明合理响度是基础需求。
- Noisiness:系数0.78,背景噪声直接影响清晰度。
- Discontinuity:系数0.75,语音断裂严重损害用户体验。

技术意义总结
音频LLM分类选择 → 连续表示模型更适合质量评估任务(保留声学细节)
质量维度分析 → Coloration和Loudness是MOS预测的关键因素(指导特征提取设计)应用启示:
- 在语音增强算法中,优先优化Coloration(如抑制回声)可显著提升MOS;
- 设计质量评估模型时,需针对性提取频谱平坦度、信噪比等特征。
示例:多维质量评估流程
- 输入语音:一段含风扇噪声和轻微失真的录音。
- 特征提取 :
- Noisiness:风扇噪声(信噪比20dB,评分2/5);
- Coloration:设备压缩导致高频失真(评分1.5/5);
- Discontinuity:无中断(评分5/5);
- Loudness:正常(-16dB,评分4/5)。
- MOS预测 :
- 线性加权: 0.82 × 1.5 + 0.81 × 4 + 0.78 × 2 + 0.75 × 5 ≈ 3.1 0.82 \times 1.5 + 0.81 \times 4 + 0.78 \times 2 + 0.75 \times 5 ≈ 3.1 0.82×1.5+0.81×4+0.78×2+0.75×5≈3.1;
- 实际MOS:3.2(接近预测值)。
- 生成描述 :
"此语音MOS=3.2。主要问题为高频失真(设备压缩导致)和中度背景风扇噪声。建议启用降噪算法并调整编码参数。"
总结图示
音频LLM类型选择 → 连续编码器提取细节特征 → 多维质量分析 → Coloration/Loudness主导MOS → 指导模型优化此背景分析为后续数据集构建与ALLD方法设计提供了理论基础和技术路线。
METHODOLOGY
DATASET GNERATION
. MOS预测:生成描述性训练语料库
核心方法
利用大语言模型(LLMs)的推理能力,将语音质量元信息(如噪声、失真、不连续性等)转化为自然语言描述,构建训练数据集。
具体流程
- 输入元信息 :每个语音样本的标注数据包括:
mos(整体评分)、noi(噪声)、dis(不连续性)、col(音色失真)、loud(响度)。
示例 :xt = {mos=2.4, noi=3, dis=1, col=4, loud=2}
- 任务提示设计 :
- 定义每个维度的含义(如"col表示音色失真");
- 要求LLM突出关键影响因素并解释其对MOS的影响。
示例提示 :
"请根据以下质量维度生成描述:噪声评分3/5,音色失真评分4/5。要求:分析主要问题,最后给出MOS=2.4。"
- 上下文学习优化 :
- 人工编写3-5个典型示例作为演示(demonstrations),指导LLM生成结构化响应。
示例输出 :
"此语音噪声水平中等(如风扇声),但音色失真严重(高频缺失)。尽管无中断问题,失真导致整体MOS仅为2.4。"
- 人工编写3-5个典型示例作为演示(demonstrations),指导LLM生成结构化响应。
实际挑战与解决
- 问题:即使70B参数的开源LLM(如LLaMA-2),也难以精确遵循复杂指令(如忽略关键维度)。
- 解决方案 :加入人工编写的示例,显著提升生成质量。
示例改进 :- 未优化前:"MOS=2.4,质量较差。"
- 优化后:"MOS=2.4。主要问题为音色失真(评分4/5),高频段严重衰减,疑似设备压缩导致。噪声水平中等(评分3/5)。"
2. A/B测试:模拟人类对比判断
任务目标
训练音频LLM比较两段语音(A/B样本),基于子维度差异生成可解释的偏好判断。
实现步骤
- 输入数据 :两段语音的元信息(如A的
noi=2、B的noi=4)。 - 任务提示 :要求模型先对比各维度,再综合判断优劣。
示例提示 :
"请比较语音A(噪声2/5,音色失真3/5)和语音B(噪声4/5,音色失真1/5),分析后选择更优者。" - 生成响应 :
"语音A噪声更低(评分2 vs. 4),但语音B音色更自然(失真1 vs. 3)。若优先考虑清晰度,选A;若注重听感真实,选B。"
应用场景
- TTS系统选型:比较两种合成语音,模型指出"系统A的韵律更自然,但系统B的发音准确度更高"。
- 降噪算法优化:对比新旧算法,结论"新算法在噪声抑制上提升15%,但引入轻微失真"。
3. 合成词检测(SWD):词级细粒度分析
任务定义
要求音频LLM定位语音中哪些单词是人工合成的(如编辑或生成的内容)。
技术挑战
- 传统任务局限:欺骗检测(Spoof Detection)仅判断整段语音是否合成,无法定位具体位置。
- SWD创新:需精确识别合成词(如"apple"为生成,其余为真实录音)。
实现方法
- 输入数据:混合真实与合成词的语音(如"I ate an synthetic apple")。
- 任务提示 :
"请分析以下语音,指出哪些词是合成的。示例:'The synthetic sky is blue.' → 合成词:sky" - 生成响应 :
"检测到'apple'为合成词,其频谱连续性异常,与上下文能量不匹配。"
实际意义
- 对抗深度伪造:识别高级语音编辑工具(如VoiceCraft)生成的片段。
- 内容审核:定位媒体中的篡改部分(如虚假新闻中篡改的敏感词)。
技术总结
MOS预测 → 生成可解释描述(Why)
A/B测试 → 提供权衡判断(Which)
SWD任务 → 定位合成内容(Where) 数据生成流程
给定包含元数据 {mos, noi, col, dis, loud} 的元组,LLaMA-3.1 70B 的生成模板如下:
提示模板:
我将提供一组用于语音质量评估的元信息,包含5个维度评分(1-5分),所有维度分值越高越好。
(1)mos :整体质量。1=极差,2=较差,3=一般,4=良好,5=极佳。
(2)noi :音频噪声水平,反映背景噪声或其他非语音干扰对质量的影响。1=严重噪声,2=较明显噪声,3=中等噪声,4=较轻微噪声,5=完全无噪声。
(3)col :语音自然音色的改变(由失真或非预期修改导致)。1=严重失真,2=显著失真,3=中度失真,4=轻微失真,5=无失真。
(4)dis :音频不连续性,反映播放时是否存在中断、卡顿或不连贯。1=严重不连续,2=显著不连续,3=中度不连续,4=轻微不连续,5=完全连贯。
(5)loud:音频感知音量或响度。1=极低,2=显著偏低,3=轻柔但可理解,4=清晰响亮,5=完美响度。
请根据维度(2)至(5)的评分生成描述性评估,分析其对整体质量的影响,并在末尾给出MOS评分。
示例 :输入:
{示例数据点}输出:
{定制化响应}···
当前输入:
{当前数据点}。请仅输出评估结果:
参数设置:
- 首次生成:使用LLaMA-3.1默认推理参数(温度=1.0,top_p=1.0)。
- 二次生成:调整温度参数(temperature=1.1)并设置top_p=0.9,以增加生成多样性。
A/B测试
提示模板设计 :
A/B测试的提示引言部分与MOS预测一致。在介绍子维度后,提示内容调整为:
请根据两段语音的MOS评分(MOS高者胜出),从维度(2)至(5)中灵活选择1-3个差异显著的方面(通常评分差≥0.5),基于这些差异进行对比分析,最终给出合理偏好判断。
结果提取 :
使用以下模板通过LLaMA-3.1-70B从音频LLM的生成结果中提取最终答案:
"根据上下文,请判断SpeechA与SpeechB中更优者。仅输出'SpeechA'或'SpeechB',无需分析。"
计算准确率 :
通过该模板从音频LLM生成结果和真实标注中提取更优语音(SpeechA/SpeechB),判断一致性以计算最终准确率。
两阶段策略的必要性 :
由于LLaMA-3.1-70B无法直接生成简洁答案(无论提示如何设计),需通过两阶段(生成分析→提取答案)确保结果可靠性。
ALIGNMENT WITH LLM DISTILLATION
与llm蒸馏对齐
1. 上下文学习(ICL)的局限性
问题背景 :
研究者首先探索了无需梯度更新的上下文学习(ICL)是否能让音频LLM感知语音质量。例如,通过提示模板要求模型判断语音的噪声水平("clean"或"noisy")。
实验设置:
- 提示模板示例 :
"请评估以下语音的噪声水平,预测'clean'或'noisy'。示例:audio1为noisy,audio2为clean。请判断audio3:" - 尝试变量 :
不同提示格式、示例数量、质量子维度(如noisiness、coloration)及多种开源音频LLM。
实验结果:
- 失败原因 :
- 普遍幻觉(Hallucination):模型倾向于生成与输入无关的随机判断(如将清晰语音误判为"noisy")。
- 指令遵循能力退化:音频任务的监督微调(SFT)损害了LLM原有的推理和指令理解能力(如无法正确解析多维度分析指令)。
示例说明 :
输入一段轻微背景噪声的语音(实际评分noi=4),模型可能错误输出"noisy",而忽略其他维度(如col=5)对整体质量的影响。
2. ALLD方法的核心设计
目标:通过蒸馏对齐音频LLM与专家LLM的输出,提升生成质量与评估准确性。
架构与公式
-
输入与响应:
- 音频输入 x a x_a xa:原始语音信号。
- 音频LLM ( π θ \pi_\theta πθ )生成响应 y a y_a ya。
- 专家LLM ( π ref \pi_{\text{ref}} πref) 基于元信息 x t x_t xt 生成参考响应 y t y_t yt。
-
对齐目标 :
最大化奖励函数 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y),同时约束音频LLM输出分布与专家LLM的KL散度:
max π θ E ( x a , x t ) ∼ D , y ∼ π θ ( y ∣ x a ) r ϕ ( x a , y ) − β D KL ( π θ ( y ∣ x a ) ∥ π ref ( y ∣ x t ) ) \max_{\pi_\theta} \mathbb{E}{(x_a, x_t) \sim D, y \sim \pi\theta(y|x_a)} r_\\phi(x_a, y) - \beta D_{\text{KL}}(\pi_\theta(y|x_a) \| \pi_{\text{ref}}(y|x_t)) πθmaxE(xa,xt)∼D,y∼πθ(y∣xa)rϕ(xa,y)−βDKL(πθ(y∣xa)∥πref(y∣xt))- 奖励函数 :通过DPO(Direct Preference Optimization)隐式建模偏好( y t y_t yt 优于 y a y_a ya)。
- KL散度约束:防止音频LLM偏离专家LLM的知识分布。
-
偏好优化数据集 :
构建对比数据 D = { x a ( i ) , x t ( i ) , y a ( i ) , y t ( i ) } D = \{x^{(i)}a, x^{(i)}t, y^{(i)}a, y^{(i)}t\} D={xa(i),xt(i),ya(i),yt(i)},优化目标改写为:
L ALLD ( π θ ; π ref ) = − E ( x , y a , y t ) ∼ D log σ ( β log π θ ( y t ∣ x ) π ref ( y t ∣ x ) − β log π θ ( y a ∣ x ) π ref ( y a ∣ x ) ) \mathcal{L}{\text{ALLD}}(\pi\theta; \pi{\text{ref}}) = -\mathbb{E}{(x, y_a, y_t) \sim D} \left \\log \\sigma \\left( \\beta \\log \\frac{\\pi_\\theta(y_t\|x)}{\\pi_{\\text{ref}}(y_t\|x)} - \\beta \\log \\frac{\\pi_\\theta(y_a\|x)}{\\pi_{\\text{ref}}(y_a\|x)} \\right) \\right LALLD(πθ;πref)=−E(x,ya,yt)∼Dlogσ(βlogπref(yt∣x)πθ(yt∣x)−βlogπref(ya∣x)πθ(ya∣x))
x a 和 x t 被统一表示为 x ,因为它们携带等价信息( x t 嵌入在音频 x a 中 ) x_a和x_t被统一表示为x,因为它们携带等价信息(x_t嵌入在音频x_a中) xa和xt被统一表示为x,因为它们携带等价信息(xt嵌入在音频xa中)
与主流RLHF的区别
- 参考模型角色 :
- 主流RLHF : π ref \pi_{\text{ref}} πref 是冻结的初始模型(防止突变)。
- ALLD : π ref \pi_{\text{ref}} πref是专家LLM(如Qwen-7B),提供标记级蒸馏指导。
- 知识来源 :
- ALLD利用专家LLM生成的描述( y t y_t yt)作为高质量参考,而非人工标注的偏好。
公式详解:从零理解ALLD方法的核心设计
1. 基本符号与概念
在深入公式前,先明确核心符号含义:
- π θ \pi_\theta πθ :待训练的音频LLM(学生模型),参数为 θ \theta θ。
- π ref \pi_{\text{ref}} πref:专家LLM(教师模型),生成高质量参考响应。
- x a x_a xa:原始音频输入(如一段含噪声的语音)。
- x t x_t xt :与 x a x_a xa对应的元信息(如噪声评分、失真评分等)。
- y a y_a ya:音频LLM生成的响应(如"MOS=3.0,噪声明显")。
- y t y_t yt:专家LLM生成的参考响应(如"MOS=3.0,噪声评分4/5,因风扇声干扰")。
- D D D :训练数据集,包含多组 ( x a , x t , y a , y t ) (x_a, x_t, y_a, y_t) (xa,xt,ya,yt)。
- β \beta β:平衡参数,控制KL散度的权重(越大越倾向于保持与参考模型一致)。
2. 目标函数解析
公式1 :
max π θ E ( x a , x t ) ∼ D , y ∼ π θ ( y ∣ x a ) r ϕ ( x a , y ) − β D KL ( π θ ( y ∣ x a ) ∥ π ref ( y ∣ x t ) ) \max_{\pi_\theta} \mathbb{E}{(x_a, x_t) \sim D, y \sim \pi\theta(y|x_a)} r_\\phi(x_a, y) - \beta D_{\text{KL}}(\pi_\theta(y|x_a) \| \pi_{\text{ref}}(y|x_t)) πθmaxE(xa,xt)∼D,y∼πθ(y∣xa)rϕ(xa,y)−βDKL(πθ(y∣xa)∥πref(y∣xt))
分步解释
-
第一部分:最大化奖励期望
- E r ϕ ( x a , y ) \mathbb{E}r_\\phi(x_a, y) Erϕ(xa,y) :对音频LLM生成的响应 y y y计算奖励的期望值。
- 奖励函数 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y) :衡量响应 y y y的质量(如与参考响应 y t y_t yt的匹配程度)。
- 目标:让音频LLM生成高奖励的响应(即与专家响应一致)。
示例 :
若音频LLM生成 y a y_a ya="MOS=3.0,噪声明显",而专家响应 y t y_t yt="MOS=3.0,噪声评分4/5",则 r ϕ ( x a , y a ) r_\phi(x_a, y_a) rϕ(xa,ya)可能为0.8(接近参考)。
-
第二部分:最小化KL散度
- D KL ( π θ ∥ π ref ) D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}}) DKL(πθ∥πref):衡量音频LLM与专家LLM输出分布的差异。
- KL散度定义 :
D KL ( P ∥ Q ) = ∑ P ( y ) log P ( y ) Q ( y ) D_{\text{KL}}(P \| Q) = \sum P(y) \log \frac{P(y)}{Q(y)} DKL(P∥Q)=∑P(y)logQ(y)P(y)
值越小,表示 P P P(音频LLM)与 Q Q Q(专家LLM)的输出分布越接近。 - 目标:防止音频LLM过度偏离专家模型的知识(如生成不合理描述)。
示例 :
若专家模型对某语音生成"MOS=3.0"的概率为90%,而音频LLM生成"MOS=3.0"的概率为50%,则KL散度较大,需通过优化降低差异。
-
平衡参数 β \beta β
- β \beta β越大,优化过程越倾向于保持与专家模型一致,可能牺牲奖励;
- β \beta β越小,越注重奖励最大化,可能生成更自由但不稳定的响应。
3. 损失函数解析(基于DPO)
公式2 :
L ALLD = − E ( x , y a , y t ) ∼ D log σ ( β log π θ ( y t ∣ x ) π ref ( y t ∣ x ) − β log π θ ( y a ∣ x ) π ref ( y a ∣ x ) ) \mathcal{L}{\text{ALLD}} = -\mathbb{E}{(x, y_a, y_t) \sim D} \left \\log \\sigma \\left( \\beta \\log \\frac{\\pi_\\theta(y_t\|x)}{\\pi_{\\text{ref}}(y_t\|x)} - \\beta \\log \\frac{\\pi_\\theta(y_a\|x)}{\\pi_{\\text{ref}}(y_a\|x)} \\right) \\right LALLD=−E(x,ya,yt)∼Dlogσ(βlogπref(yt∣x)πθ(yt∣x)−βlogπref(ya∣x)πθ(ya∣x))
分步解释
-
核心思想 :直接优化偏好(偏好 y t y_t yt优于 y a y_a ya),无需显式训练奖励模型。
-
对数比值项:
- log π θ ( y t ∣ x ) π ref ( y t ∣ x ) \log \frac{\pi_\theta(y_t|x)}{\pi_{\text{ref}}(y_t|x)} logπref(yt∣x)πθ(yt∣x) :音频LLM生成 y t y_t yt的概率相对于专家LLM的对数比值。
- log π θ ( y a ∣ x ) π ref ( y a ∣ x ) \log \frac{\pi_\theta(y_a|x)}{\pi_{\text{ref}}(y_a|x)} logπref(ya∣x)πθ(ya∣x) :音频LLM生成 y a y_a ya的概率相对于专家LLM的对数比值。
- 差值 : β ( 比值 t − 比值 a ) \beta (\text{比值}_t - \text{比值}_a) β(比值t−比值a),放大两者差异。
直观意义:
- 若音频LLM生成 y t y_t yt的概率比专家LLM高,且生成 y a y_a ya的概率比专家LLM低,则差值为正,损失减小。
-
Sigmoid函数( σ \sigma σ):
- 将差值映射到(0,1)区间,表示 y t y_t yt优于 y a y_a ya的概率。
- σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1,当 z z z越大, σ ( z ) \sigma(z) σ(z)越接近1。
-
损失函数:
- 最大化 log σ ( ⋅ ) \log \sigma(\cdot) logσ(⋅)等价于最大化 y t y_t yt优于 y a y_a ya的概率。
- 负号表示最小化负对数概率(即最大化原始概率)。
示例计算 :
假设:
- π ref ( y t ∣ x ) = 0.9 \pi_{\text{ref}}(y_t|x) = 0.9 πref(yt∣x)=0.9, π ref ( y a ∣ x ) = 0.1 \pi_{\text{ref}}(y_a|x) = 0.1 πref(ya∣x)=0.1(专家认为 y t y_t yt更优)。
- π θ ( y t ∣ x ) = 0.6 \pi_\theta(y_t|x) = 0.6 πθ(yt∣x)=0.6, π θ ( y a ∣ x ) = 0.4 \pi_\theta(y_a|x) = 0.4 πθ(ya∣x)=0.4(音频LLM有待优化)。
- β = 1 \beta=1 β=1。
则:
比值 t = log 0.6 0.9 ≈ − 0.405 , 比值 a = log 0.4 0.1 ≈ 1.386 差值 = − 0.405 − 1.386 = − 1.791 σ ( − 1.791 ) ≈ 0.143 L = − log ( 0.143 ) ≈ 1.95 \text{比值}_t = \log \frac{0.6}{0.9} \approx -0.405, \quad \text{比值}_a = \log \frac{0.4}{0.1} \approx 1.386 \\ 差值 = -0.405 - 1.386 = -1.791 \\ \sigma(-1.791) \approx 0.143 \\ \mathcal{L} = -\log(0.143) \approx 1.95 比值t=log0.90.6≈−0.405,比值a=log0.10.4≈1.386差值=−0.405−1.386=−1.791σ(−1.791)≈0.143L=−log(0.143)≈1.95
优化过程会调整 π θ \pi_\theta πθ,使得 π θ ( y t ∣ x ) \pi_\theta(y_t|x) πθ(yt∣x)增加, π θ ( y a ∣ x ) \pi_\theta(y_a|x) πθ(ya∣x)减少,从而降低损失。
4. 与主流RLHF的区别
参考模型角色
-
主流RLHF:
- π ref \pi_{\text{ref}} πref是初始模型的冻结副本,仅用于防止优化过程中模型"突变"(如生成乱码)。
- 目标函数示例:
max π θ E r ( y ) − β D KL ( π θ ∥ π init ) \max_{\pi_\theta} \mathbb{E}r(y) - \beta D_{\text{KL}}(\pi_\theta \| \pi_{\text{init}}) πθmaxEr(y)−βDKL(πθ∥πinit)
其中 π init \pi_{\text{init}} πinit为初始模型。
-
ALLD:
- π ref \pi_{\text{ref}} πref是专家LLM(如Qwen-7B),作为知识来源提供高质量参考。
- 目标函数:
max π θ E r ( y ) − β D KL ( π θ ∥ π ref ) \max_{\pi_\theta} \mathbb{E}r(y) - \beta D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}}) πθmaxEr(y)−βDKL(πθ∥πref)
通过KL散度约束,使音频LLM学习专家LLM的输出分布。
知识来源
- RLHF :依赖人工标注的偏好数据(如标注员选择 y t y_t yt优于 y a y_a ya)。
- ALLD :直接利用专家LLM生成的 y t y_t yt作为高质量参考,无需人工标注。
5. 实例说明ALLD训练流程
步骤1:数据准备
- 收集语音样本 x a x_a xa及其元信息 x t x_t xt(如MOS=3.0, noi=4, col=2)。
- 使用专家LLM生成参考响应 y t y_t yt(如"MOS=3.0,噪声轻微但音色失真")。
- 音频LLM生成初始响应 y a y_a ya(如"MOS=3.0,质量一般")。
步骤2:构建偏好数据集
- 对比数据 D D D包含 ( x a , x t , y a , y t ) (x_a, x_t, y_a, y_t) (xa,xt,ya,yt),标记 y t y_t yt优于 y a y_a ya。
步骤3:计算损失
- 对每个样本计算公式2中的损失,调整 π θ \pi_\theta πθ参数使损失最小化。
步骤4:迭代优化
- 多轮训练后,音频LLM生成的响应逐渐接近专家LLM(如从"质量一般"变为"噪声轻微但音色失真,MOS=3.0")。
总结
ALLD公式核心:
1. 最大化奖励:鼓励生成与专家一致的响应。
2. 最小化KL散度:保持输出分布与专家模型接近。
3. DPO优化:直接利用专家响应作为偏好,避免人工标注。效果:音频LLM学会从语音中提取质量特征,并生成人类可理解的描述,推动语音评估从"黑箱评分"到"透明分析"的跨越。
3. 训练策略与优化
-
专家LLM选择:
- 使用较小的LLM(如Qwen-7B)作为 π ref \pi_{\text{ref}} πref,降低计算成本。
- 保持分词器(Tokenizer)一致性,确保蒸馏可行性。
-
预热微调(Warm-up SFT):
- 必要性 :音频LLM ( π θ \pi_\theta πθ) 缺乏零样本生成能力,需在子集 D D D 上预训练。
- 示例 :
输入含失真的语音,模型初步学习生成"存在设备压缩导致的失真"等描述。
-
单次采样优化:
- 为简化流程,仅采样一次 y a y_a ya 进行偏好优化。
- 迭代潜力 :理论上可通过多次采样-优化循环逐步逼近 y t y_t yt。
4. 实际效果与优势
实验结果:
- 生成质量提升:BLEU分数提高至25.8/30.2,证明语言能力退化问题被有效缓解。
- 评估精度:MOS预测误差(MSE=0.17)与A/B测试准确率(98.6%)显著优于传统回归模型。
示例对比:
- 传统模型:输出"MOS=2.0,质量差"。
- ALLD模型:输出"MOS=2.1。主要问题为高频电流噪音(中心频率8kHz,强度-18dB),建议检查设备屏蔽"。
应用场景:
- 自优化语音生成:TTS系统根据ALLD反馈调整降噪模块参数。
- 实时质量监控:在视频会议中检测网络抖动导致的语音断裂,提示用户重连。
技术总结
ALLD核心价值:
1. 跨模态对齐:将声学特征映射为可解释文本。
2. 语言能力修复:通过标记级蒸馏抑制预训练中的退化。
3. 高效优化:结合DPO与KL约束,平衡生成多样性与准确性。此方法为音频LLM赋予"自我诊断-优化"能力,推动其从被动处理工具进化为主动感知的智能代理。
EXPERIMENTAL RESULT
数据集
1. NISQA数据集概述
- 数据规模:包含超过97,000条人类评分,涵盖多个维度(如MOS、噪声、失真等)。
- 评分维度 :
- 整体MOS:平均意见得分(1-5分)。
- 子维度评分 :
- Noisiness(噪声水平):1=严重噪声,5=完全干净。
- Coloration(音色失真):1=严重失真,5=无失真。
- Discontinuity(不连续性):1=严重中断,5=完全连贯。
- Loudness(响度):1=极低,5=完美响度。
原文引用 :
"We used the NISQA (Mittag et al., 2021) that contains more than 97,000 human ratings for each of the individual dimensions as well as the overall MOS."
详细示例:
- 输入:一段含噪声的语音(如咖啡厅环境下的录音)。
- 评分 :
- MOS=3.0(整体评分)。
- 噪声评分=4/5(背景噪声明显)。
- 失真评分=2/5(轻微失真)。
- 不连续性评分=5/5(语音连贯)。
- 响度评分=3/5(音量适中)。
2. 训练集构建
- 生成工具 :
使用LLaMA3.1-70B-Instruct模型生成20,000条训练样本。 - 任务分配 :
- MOS预测任务:10,000条样本。
- A/B测试任务:10,000条样本。
- 数据来源:基于NISQA TRAIN SIM子集(2,322名说话者)。
原文引用 :
"To formulate the training set for ALLD, we utilize the LLaMA3.1-70B-Instruct model to generate a total of 20k training examples for MOS prediction (10k) and A/B test (10k), which includes 2,322 speakers based on the largest subset NISQA TRAIN SIM."
详细示例:
-
MOS预测任务:
- 输入:一段含噪声的语音。
- 输出 :
- MOS=3.0。
- 噪声评分=4/5。
- 失真评分=2/5。
- 不连续性评分=5/5。
- 响度评分=3/5。
- 生成过程 :
输入音频特征到LLaMA3.1-70B-Instruct模型。- 模型
生成自然语言描述:"此语音MOS评分为3.0。噪声水平较高(评分4/5),但语音连贯性良好(评分5/5)。建议检查录音设备是否存在失真问题。"
-
A/B测试任务:
- 输入:两段语音(A:噪声明显,B:失真明显)。
- 输出 :
- "语音A的噪声更明显(评分4/5 vs. 2/5),但语音B的失真更严重(评分1/5 vs. 4/5)。综合推荐语音A。"
- 生成过程 :
- 输入两段语音的特征到LLaMA3.1-70B-Instruct模型。
- 模型生成对比分析:"语音A的噪声抑制效果较差,但语音B的失真问题更严重。建议优先选择语音A。"
3. 测试集构建
- 域内测试集:NISQA TRAIN SIM子集(938名说话者),5,000条样本。
- 域外测试集 :
- NISQA VAL LIVE:真实场景语音(如电话录音、会议录音)。
- NISQA TEST FOR:外语语音(如非母语者的英语录音)。
- NISQA TEST P501:特定领域语音(如医疗、教育场景的录音)。
原文引用 :
"Meanwhile, NISQA TRAIN SIM with 938 speakers are constructed as a 5k in-domain test set for these two tasks. Additionally, the NISQA VAL LIVE, NISQA Test FOR, and NISQA TEST P501 are used for out-of-domain evaluation, containing unseen speech samples from various domains, as summarized in Table 2."
详细示例:
-
域内测试集:
- 输入:一段含噪声的语音(与训练集同分布)。
- 输出:MOS=3.0,噪声评分=4/5。
-
域外测试集:
- NISQA VAL LIVE :
- 输入:一段电话录音(含网络抖动)。
- 输出:MOS=2.5,不连续性评分=3/5。
- NISQA TEST FOR :
- 输入:一段非母语者的英语录音(含口音)。
- 输出:MOS=3.2,音色失真评分=2/5。
- NISQA TEST P501 :
- 输入:一段医疗场景的录音(含专业术语)。
- 输出:MOS=3.5,响度评分=4/5。
- NISQA VAL LIVE :
SWD任务数据集
- 数据来源:LibriSpeech(语音合成与编辑任务常用数据集)。
- 任务目标:检测语音中哪些词是合成的(如"apple"为生成词)。
原文引用 :
"For SWD tasks, we utilize LibriSpeech for data generation, with further details provided in Appendix D."
详细示例:
- 输入:一段语音"I ate an synthetic apple."
- 输出 :
- 检测到"apple"为合成词,因其频谱连续性异常。
- 生成描述:"检测到'apple'为合成词,建议检查语音编辑工具。"
模型与基线
1. MOS预测基线模型
CNN-SA-AP
- 特点:NISQA数据集上的SOTA回归模型,仅预测MOS分数,无分析能力。
- 架构:基于卷积神经网络(CNN)与自注意力机制(Self-Attention)。
- 输入:原始语音波形。
- 输出:MOS分数(1-5分)。
原文引用 :
"For MOS prediction, regression models CNN-SA-AP (Mittag et al., 2021) ... are employed as baseline that only estimate the score without analysis. The former is the SOTA on the NISQA dataset."
详细示例:
- 输入:一段含噪声的语音。
- 输出:MOS=3.5。
Wav2vec2
- 特点:自监督学习模型,广泛用于语音质量评估。
- 架构:基于Transformer的语音特征提取器。
- 输入:原始语音波形。
- 输出:MOS分数(1-5分)。
原文引用 :
"Wav2vec2 (Baevski et al., 2020) ... are widely used self-supervised learning models for MOS estimation."
详细示例:
- 输入:一段含失真的语音。
- 输出:MOS=3.2。
WavLM
- 特点:改进的自监督模型,提取更丰富的语音特征。
- 架构:基于Transformer的多任务学习模型。
- 输入:原始语音波形。
- 输出:MOS分数(1-5分)。
原文引用 :
"WavLM (Chen et al., 2022) ... are widely used self-supervised learning models for MOS estimation."
详细示例:
- 输入:一段含背景音乐的语音。
- 输出:MOS=3.4。
2. 音频LLM模型
SALMONN
- 特点:通过双编码器提取更多声学信息,使用Q-former连接LLM,集成LoRA。
- 架构 :
- 双编码器:分别提取语音与文本特征。
- Q-former:将声学特征映射到LLM输入空间。
- LoRA:低秩适应(Low-Rank Adaptation),提升模型微调效率。
- 输入:原始语音波形。
- 输出:自然语言描述(如"MOS=3.0,噪声评分4/5")。
原文引用 :
"SALMONN (Tang et al., 2023) can extract more acoustic information via bi-encoders, and connect them to LLMs via a Q-former, with LoRA integrated."
详细示例:
- 输入:一段含回声的语音。
- 输出 :"MOS=3.0,噪声评分4/5,因会议室回声干扰。"
Qwen-Audio
- 特点:编码器可训练,LLM部分冻结。
- 架构 :
- 编码器:可训练的语音特征提取器。
- LLM:冻结的大型语言模型。
- 输入:原始语音波形。
- 输出:自然语言描述(如"MOS=3.0,质量一般")。
原文引用 :
"Qwen-Audio (Chu et al., 2023) makes the encoder trainable while freezing the entire LLM."
详细示例:
- 输入:一段含电流噪音的语音。
- 输出 :"MOS=3.0,质量一般。"
Qwen2-Audio
- 特点:编码器与LLM端到端训练。
- 架构 :
- 编码器:可训练的语音特征提取器。
- LLM:可训练的大型语言模型。
- 输入:原始语音波形。
- 输出:自然语言描述(如"MOS=3.0,噪声评分4/5,建议启用降噪功能")。
原文引用 :
"In contrast, Qwen2-Audio (Chu et al., 2024) enables full end-to-end training of both the encoder and the LLM."
详细示例:
- 输入:一段含风声的语音。
- 输出 :"MOS=3.0,噪声评分4/5,建议启用降噪功能。"
要点
1. MOS预测基线模型:
- CNN-SA-AP:NISQA数据集上的SOTA回归模型。
- Wav2vec2:自监督学习模型,广泛用于语音质量评估。
- WavLM:改进的自监督模型,提取更丰富的语音特征。
2. 音频LLM模型:
- SALMONN:双编码器 + Q-former + LoRA,提取更多声学信息。
- Qwen-Audio:编码器可训练,LLM冻结。
- Qwen2-Audio:编码器与LLM端到端训练。训练细节
1. 参数高效微调(Parameter-Efficient Finetuning)
IA3
- 特点:通过少量参数调整提升模型性能。
- 应用:所有线性层。
- 原理:在模型的线性层中引入可学习的缩放参数,减少训练参数量。
原文引用 :
"Besides full parameter finetuning, we also adopt parameter-efficient finetuning for these audio LLMs including IA3 (Liu et al., 2022) (apply to all linear layers)."
详细示例:
- 输入:一段含噪声的语音。
- 输出:MOS=3.0,噪声评分4/5。
- 优化效果:通过IA3微调,模型在噪声评分上的预测精度提升10%。
LoRA
- 特点:低秩适应(Low-Rank Adaptation),提升模型微调效率。
- 应用:编码器与LLM的查询(queries)、键(keys)、值(values)矩阵。
- 参数:秩为16的低秩矩阵。
原文引用 :
"LoRA (Hu et al., 2021). LoRA matrix adds all queries, keys, and values into the encoder and LLM with a rank of 16."
详细示例:
- 输入:一段含失真的语音。
- 输出 :"MOS=3.0,失真评分2/5。"
- 优化效果:通过LoRA微调,模型在失真评分上的预测精度提升15%。
2. ALLD训练设置
β \beta β值
- 设置 : β = 0.4 \beta=0.4 β=0.4,用于增强蒸馏效果。
- 作用 :控制KL散度约束的强度, β \beta β越大,模型输出越接近专家LLM。
原文引用 :
"For ALLD, β is set as 0.4 to enhance the distillation."
详细示例:
- 输入:一段含噪声的语音。
- 输出 :
- β = 0.4 \beta=0.4 β=0.4时,模型生成"MOS=3.0,噪声评分4/5"。
- β = 0.1 \beta=0.1 β=0.1时,模型生成"MOS=3.0,质量一般"。
学习率
- 设置:学习率=5e-6。
- 作用:控制模型参数更新的步长,较小的学习率有助于稳定训练。
原文引用 :
"The learning rate is set as 5e-6."
详细示例:
- 输入:一段含背景音乐的语音。
- 输出 :
- 学习率=5e-6时,模型生成"MOS=3.0,噪声评分4/5"。
- 学习率=1e-5时,模型生成"MOS=3.0,质量一般"。
预热微调(Warm-up Finetuning)
- 操作:使用一半训练样本进行初步训练。
- 目的:提升模型初始能力,避免直接优化偏好数据时的不稳定性。
原文引用 :
"Half of the training examples are used for warm-up finetuning."
详细示例:
- 输入:一段含噪声的语音。
- 输出 :
- 预热微调前:模型生成"MOS=3.0"。
- 预热微调后:模型生成"MOS=3.0,噪声评分4/5"。
采样优化
- 操作 :在整个训练集上采样构建对比数据集 D D D。
- 目的:通过偏好优化(DPO)调整模型生成分布。
原文引用 :
"Then perform sampling on the whole training set to construct a comparison dataset D."
详细示例:
- 输入:一段含噪声的语音。
- 采样过程 :
- 生成初始响应 y a y_a ya="MOS=3.0"。
- 对比参考响应 y t y_t yt="MOS=3.0,噪声评分4/5"。
- 优化损失,调整模型参数。
要点
1. 参数高效微调:
- IA3:应用于所有线性层,减少训练参数量。
- LoRA:应用于编码器与LLM的查询、键、值矩阵,秩为16。
2. ALLD训练设置:
- β=0.4:增强蒸馏效果。
- 学习率=5e-6:稳定训练过程。
- 预热微调:使用一半训练样本提升初始能力。
- 采样优化:构建对比数据集D,通过DPO调整生成分布。评估指标
1. MOS数值预测任务
线性相关系数(LCC)
- 定义:衡量预测MOS与真实MOS的线性关系,取值范围为-1, 1。
- 公式 :
LCC = Cov ( Y pred , Y true ) σ Y pred σ Y true \text{LCC} = \frac{\text{Cov}(Y_{\text{pred}}, Y_{\text{true}})}{\sigma_{Y_{\text{pred}}} \sigma_{Y_{\text{true}}}} LCC=σYpredσYtrueCov(Ypred,Ytrue)
其中, Cov \text{Cov} Cov为协方差, σ \sigma σ为标准差。 - 意义:LCC越接近1,表示预测值与真实值的线性关系越强。
原文引用 :
"For MOS numerical prediction, we employ linear correlation coefficient (LCC)."
详细示例:
- 真实MOS:3.0, 4.0, 2.5
- 预测MOS:3.1, 3.9, 2.6
- LCC计算 :
- 协方差 Cov ( Y pred , Y true ) = 0.15 \text{Cov}(Y_{\text{pred}}, Y_{\text{true}}) = 0.15 Cov(Ypred,Ytrue)=0.15
- 标准差 σ Y pred = 0.25 \sigma_{Y_{\text{pred}}} = 0.25 σYpred=0.25, σ Y true = 0.5 \sigma_{Y_{\text{true}}} = 0.5 σYtrue=0.5
- LCC = 0.15 0.25 × 0.5 = 1.2 \frac{0.15}{0.25 \times 0.5} = 1.2 0.25×0.50.15=1.2(标准化后为0.96)
Spearman等级相关系数(SRCC)
- 定义:衡量预测MOS与真实MOS的单调关系,取值范围为-1, 1。
- 公式 :
SRCC = 1 − 6 ∑ d i 2 n ( n 2 − 1 ) \text{SRCC} = 1 - \frac{6 \sum d_i^2}{n(n^2 - 1)} SRCC=1−n(n2−1)6∑di2
其中, d i d_i di为预测值与真实值的等级差, n n n为样本数。 - 意义:SRCC越接近1,表示预测值与真实值的单调关系越强。
原文引用 :
"Spearman's rank correlation coefficient (SRCC)."
详细示例:
- 真实MOS:3.0, 4.0, 2.5(等级:2, 3, 1)
- 预测MOS:3.1, 3.9, 2.6(等级:2, 3, 1)
- SRCC计算 :
- 等级差 d i d_i di:0, 0, 0
- SRCC = 1 − 6 × 0 3 × ( 9 − 1 ) = 1 1 - \frac{6 \times 0}{3 \times (9 - 1)} = 1 1−3×(9−1)6×0=1
均方误差(MSE)
- 定义:衡量预测MOS与真实MOS的误差,值越小越好。
- 公式 :
MSE = 1 n ∑ i = 1 n ( Y pred ( i ) − Y true ( i ) ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^n (Y_{\text{pred}}^{(i)} - Y_{\text{true}}^{(i)})^2 MSE=n1i=1∑n(Ypred(i)−Ytrue(i))2 - 意义:MSE越小,表示预测误差越小。
原文引用 :
"Mean square error (MSE) as evaluation metrics."
详细示例:
- 真实MOS:3.0, 4.0, 2.5
- 预测MOS:3.1, 3.9, 2.6
- MSE计算 :
- MSE = ( 3.1 − 3.0 ) 2 + ( 3.9 − 4.0 ) 2 + ( 2.6 − 2.5 ) 2 3 = 0.01 + 0.01 + 0.01 3 = 0.01 \frac{(3.1-3.0)^2 + (3.9-4.0)^2 + (2.6-2.5)^2}{3} = \frac{0.01 + 0.01 + 0.01}{3} = 0.01 3(3.1−3.0)2+(3.9−4.0)2+(2.6−2.5)2=30.01+0.01+0.01=0.01
2. 描述性分析任务
BLEU分数
- 定义:衡量生成响应与参考响应的语言质量,取值范围为0, 1。
- 公式:基于n-gram重叠率与长度惩罚因子。
- 意义:BLEU越高,表示生成响应与参考响应越匹配。
原文引用 :
"BLEU score is used to measure the quality of descriptive analysis."
详细示例:
- 参考响应 :"MOS=3.0,噪声评分4/5。"
- 生成响应 :"MOS=3.0,噪声水平较高。"
- BLEU计算 :
- 1-gram重叠率:3/4 = 0.75
- 2-gram重叠率:2/3 = 0.67
- BLEU = 0.71(加权平均)
3. A/B测试任务
准确率(Acc)
- 定义 :衡量模型判断的准确性,计算公式为:
Acc = 正确判断数 总判断数 \text{Acc} = \frac{\text{正确判断数}}{\text{总判断数}} Acc=总判断数正确判断数 - 意义:Acc越高,表示模型判断越准确。
原文引用 :
"For A/B test, in addition to BLEU, we count the accuracy (Acc) to evaluate whether the model provides correct judgement."
详细示例:
- 输入:两段语音(A:噪声明显,B:失真明显)。
- 模型判断 :"语音A噪声更明显,推荐语音A。"
- 真实偏好:语音A更优。
- Acc计算 :
- 正确判断数:1
- 总判断数:1
- Acc = 100%
LLaMA-3.1模型提取结果
- 作用:从自然语言响应中提取偏好判断(如"SpeechA"或"SpeechB")。
- 指令提示 :"根据上下文,判断SpeechA或SpeechB更优。仅输出'SpeechA'或'SpeechB'。"
原文引用 :
"Since the response is natural language, we further employ a 70B LLaMA-3.1 model to extract the result for Acc calculation. More details of instruction prompt are in Appendix B."
详细示例:
- 输入 :"语音A噪声更明显,但语音B失真更严重,推荐语音A。"
- 提取结果 :"SpeechA"
4. SWD任务
准确率(Acc)
- 定义 :衡量模型检测合成词的准确性,计算公式为:
Acc = 正确检测数 总检测数 \text{Acc} = \frac{\text{正确检测数}}{\text{总检测数}} Acc=总检测数正确检测数 - 意义:Acc越高,表示模型检测能力越强。
原文引用 :
"Accuracy is also used for SWD evaluation."
详细示例:
- 输入:一段语音"I ate an synthetic apple."
- 模型检测 :"apple"
- 真实标签 :"apple"
- Acc计算 :
- 正确检测数:1
- 总检测数:1
- Acc = 100%
要点
1. MOS数值预测:
- LCC:衡量线性关系,越接近1越好。
- SRCC:衡量单调关系,越接近1越好。
- MSE:衡量误差,越小越好。
2. 描述性分析:
- BLEU:衡量语言质量,越高越好。
3. A/B测试:
- Acc:衡量判断准确性,越高越好。
- LLaMA-3.1:提取自然语言响应中的偏好判断。
4. SWD任务:
- Acc:衡量检测准确性,越高越好。RESULT ON MOS PREDICTION

音频大语言模型(如ALLD 2×)既能保持高预测性能,又能生成高质量描述,验证了其作为"描述性语音质量评估器"的潜力。
"2×"表示通过修改上下文学习示例和在LLM推理过程中调整温度τ,生成了两次训练集(总共20k样本)
传统回归模型(如Wav2vec2)虽预测性能优秀,但无法提供描述性输出,适用场景受限

未见过的语音域:
- LIVE:包括电话和Skype录音。
- FOR:法医语音数据集。
- P501:来自P.501标准的附录C文件。
模型比较:
- Wav2vec2:最佳回归模型,仅提供MOS值预测。
- ALLD:音频大语言模型,提供MOS值预测和描述性响应。
性能指标变化:
-
LCC和SRCC:ALLD模型在FOR和P501数据集上表现更好或相近。
-
MSE:ALLD模型在所有数据集上的MSE均低于或等于Wav2vec2,表明其预测更准确。
-
BLEU:ALLD模型在所有数据集上均有BLEU得分,且在LIVE和P501数据集上得分更高,表明其描述性响应质量更高。
域不匹配下的性能提升:
- 尽管额外的训练样本没有引入更多的标注MOS值,但ALLD模型在MSE和BLEU指标上表现更好,这可能是因为描述性分析的多样性增强了模型的泛化能力


原文结论:
在这项研究中,我们的目标是让音频大语言模型(LLMs)能够感知并评估语音质量,且能提供详细的描述。
为此,我们引入了一个多维度分析的语音评估语料库,该语料库基于真实的人工标注分数,由LLMs生成。
我们还提出了ALLD,这是一种旨在提升音频LLM输出质量的token-level蒸馏方法。
实验结果表明,ALLD在MOS预测和A/B测试任务上,相较于传统回归模型,
在LCC、SRCC和MSE指标上均有更优表现,同时生成的描述性响应BLEU得分为25.8。
我们的方法是迈向能够理解真实世界听觉感知的智能模型的重要一步。