0、前言
Raft 作为一种强一致性的共识算法,被广泛应用于分布式系统中,如 etcd、Consul 等。最近阅读了一篇关于 Raft 的技术文章,收获颇多,因此写下此学习笔记,记录其中的关键概念与个人理解。
需要说明的是,这篇文章并不是从零讲解 Raft ,而是基于已有的文章内容进行总结和思考。(并不保证文章严格的正确)
推荐阅读文章:两万字长文解析raft算法原理、通俗易懂 强一致性、弱一致性、最终一致性、读写一致性、单调读、因果一致性 的区别与联系 - 知乎、Raft算法详解 - 知乎
1、基本概念引入
1.1、CAP理论
CAP是经典的分布式系统理论,由**Consistency(一致性)、Availability(可用性)、Partition-tolerance(分区容错性)**组成。它们的具体含义如下:
Consistency:这里的一致性,指的是数据一致性。该项强调数据的正确性,每次操作,要么读取到最新的数据,要么读取失败;它要求整个分布式系统像一个不可分割的整体,写、读操作作用于集群像作用于单机一样。Availablitiy:从用户的角度出发,强调服务的体验性,客户端的请求能尽快的得到响应,不发生错误,也不会出现过长的等待时间。Partition-tolerance:强调整体分布式集群的系统稳定性,要求在不稳定的网络环境中,系统也是可靠的,具有容灾能力,出现问题不能让系统崩塌。
CAP理论强调在同一个系统中,系统不可能同时满足这三个性质,至多只能满足其二。
在分布式系统中,P是一定需要满足的 ,因此对于一致性和可用性,只能做到尽可能满足其中的一项,每一个分布式系统根据其需求与架构,都会有CP、AP的倾向。一般来说,分布式系统都会更加看重数据一致性C,在要求数据一致性的前提下,尽可能提高系统的可用性。
1.2、数据一致性
宏观的来说,数据一致性划分为两大类,即强一致性和弱一致性:
- 强一致性,也叫线性一致性要求,数据在多个副本之间能保持统一,当客户端进行读取的时候,不论读取的是哪一个节点的信息,都能读取到最新的数据。
- 弱一致性不要求每次读取的数据都是最新的,但至少要保证数据不会出现丢失,其允许客户端读到旧的数据。
这里在引入数据的最终一致性概念,即不论是强一致性还是弱一致性,一致性都必须满足在经过一段时间之后,所有的节点的数据都能是统一的,不存在数据的丢失。
考虑有这样一个场景:假如客户端向集群主节点A 发送了set x = 3,set x = 4的信息,并且节点A向客户端提交了ACK确认信息,然后再向次节点B发送这两条更新指令。由于网络发生了故障,B节点收到的指令顺序为set x = 4,set x = 3,最终B节点存储x的值为3,值4被覆盖了,不论如何,主节点A和副节点B在最终的状态中,x的值是不一样的,这时候就发生了丢失最终一致性问题,这是分布式系统中非常严重的问题。
2、Raft共识算法
Raft算法意向在保证系统的数据一致性、分区容错性的前提下,尽可能的不让系统处理请求过久,提高对用户的体验。
其设计的术语如下:
| 术语 | 英文术语 | 含义 |
|---|---|---|
| 领导者 | leader | 节点的三种角色之一,是集群的首脑,负责发起"提议"与"提交"多数派认可的决断。 |
| 跟随者 | follower | 节点的三种角色之一,负责对领导者发起的"提议"、"提交"以及候选者的"竞选"进行响应。 |
| 候选人 | candidate | 节点的三种角色之一,负责拉票当选新的领导者,是一个临时的状态。 |
| 预写日志 | write ahead log | 记录写请求明细的日志。 |
| 状态机 | state machine | 存储数据的物理介质。 |
| 提议 | proposal | 领导者进行两阶段提交的第一个阶段,指的是leader向所有follower发起日志同步请求的过程。 |
| 提交 | commit | 领导者进行两阶段提交的第二个阶段,指的是leader获取了多数派的同意后,向客户端发送认可响应,表示请求已被系统采纳。 |
| 应用 | apply | 指的是将预习日志中记录的写操作应用到状态机的过程。 |
| 任期 | term | 用于标识leader更迭的概念,每个任期至多只允许存在一个leader。 |
| 日志索引 | index | 指的是单个日志在日志索引中的位置。 |
| 脑裂 | brain split | 在同一任期内,出现了两个leader的异常情况,系统会错乱崩盘。 |
接下来总结一下核心流程。
2.1、角色转变
Leader->Follower:若当前的Leader发现了系统中出现了更大的任期Term,会主动退让,从Leader转变为Follower,发现信息的来源:- 向Follower提交日志同步请求时,从Follower的响应可以获取;
- 收到来自新任Leader的心跳或者同步日志请求;
- 收到了任期更大的candidate的拉票;
Follower->Candidate:若超过了一定的时间阈值没有收到来自Leader的心跳,则将自身的任期+1,转变为Candidate进行拉票。Candidate->Leader:当获取的投票数超过所有节点数的一半,则晋升为Leader。Candidate->Candidate:若拉票时间超过了一定的阈值,也没有获取半数以上的票,若还是不存在新的Leader,则将任期+1,开启新的一轮拉票。
2.2、角色职责
2.2.1、Leader
领导者是写请求的统一入口,收到来自客户端的写请求时,会进入两阶段提交的流程:
- 首先将写请求记录在自己的日志中,然后向所有节点发起同步日志的请求(请求信息包括当前最新的日志以及上一次的日志id);
- 若发起的同步日志请求获取了超过一半节点的同意,则向客户端响应提交这一请求。
除此之外,领导者需要定期向所有节点发送自己的"心跳",意图包括:
- 让Follower重置自己的心跳检测器,避免超长时间没有接受转化为候选人发起拉票;
- 在心跳请求上携带上自己最新的日志ID(Term+Index),防止错误发起新的选举,以及推动节点应用自身数据。
2.2.2、Follower
Follower的职责如下:
- 接收Leader发送的日志同步请求,若获取到的
commitIndex信息对得上自己的日志,则会进行日志同步,推进自己的日志应用进状态机中,然后通知Leader已经提交请求。(同时做了数据备份以及反馈Leader接收成功) - 负责参于Candidate的竞选,若Candidate的最后一个
LogTerm>自己的最后一个LogTerm,或LogTerm相等且最后一个LogIndex>= 自己的最后一个LogIndex,则为这个候选人投票。(保证了最终成为Leader的候选者,它的日志都是最新的) - 接收来自Leader发送的心跳,更新自己上一次接收到心跳的时间,若超时则转化为候选人进行Leader候选。
2.2.3、Candidate
职责如下:
- 自身任期+1,负责向所有节点发送请求,继续拉票,若获取的票数>总节点数一半,那么就成为新的Leader。
- 若接收到来自最新Term的Leader发来的信息,则重新变换为Follower,同时回退任期。
- 若超时也没有选出新的Leader,则任期+1,开启新的一轮选举。
2.3、宏观正常流程
2.3.1、系统的写流程
写流程的正常流程具体如下:
(1)客户端向系统发起写请求,这个写请求最终会被Leader接收,若被Follower接收,则会告知客户端Leader的昨标,从而转发写请求给Leader。
(2)Leader收到写请求后,将这个请求写到日志里面,然后向所有的节点发送同步日志请求,包含了这次日志的信息,以及上一次日志的ID。这是二次提交的一个阶段"提议"。
(3)Follower接收到日志同步请求,若无问题,则更新自己的日志,回复Leader一个同步成功的ACK。
(4)Leader收到了来自过半的Follower的提交信息,于是告知客户端这一次流程提交成功。
具体的特殊case以及面对这些case的特殊处理,将放在下面总结。
2.3.2、系统的读流程
Raft有两种读流程,一种保证了数据的强一致性,一种保证了数据的弱一致性,但是可以让系统的可用性更高。
(1)强制读主
这种策略保证了读取的数据一定是最新的,代价就是所有的流量到跑到Leader节点上,并且Leader要发送一个空日志,导致性能下降显著,具体的做法是:
所有的读请求都会被转接到Leader上,Leader会向所有的节点发送一个空日志(no-op entry),用来保证自己的数据一定是最新的,当过半的节点提交了这个请求,此时Leader才会响应给客户端。
(2)租约读(Lease Read)
这是为了防止系统的整体可用性低,而对强制读主方案的优化做法,但是它并不能一定保证数据的强一致性(若Leader死亡),具体做法是:
客户端向Leader发送读请求(默认),然后Leader会检查自己是否仍在租约内(心跳未超时,即最近的心跳时间需要在心跳超时时间之内),若仍在租期内,说明自己仍然是Leader,于是可以不用发送空日志直接返回数据 ,从而减少了一次日志复制+commit的过程,大幅降低读请求延迟。
然而在实际的工程实现,如etcd中,对读流程进行了优化:
(3)ReadIndex(默认):
ReadIndex 机制是线性读(Linearizable Read)的一种,它保证读取到的数据是最新的。具体流程如下
- 当集群收到一个读请求时,首先 会从Leader获取集群最新的已提交的日志索引(committed index)。
- Leader收到来自其他节点的ReadIndex请求 后,会向Follower发送心跳确认,过半节点 确认Leader身份后,Leader才会把**已提交的日志索引(committed index)**发送给步骤一请求的节点。
- 节点收到后,进行等待,直到状态机已应用索引(applied index)>=Leader的已提交索引(committed index)的时候,才会将状态机的数据响应给客户端。
3、CASE&QUESTION
假如有以下特殊的CASE,其对应的细节如下:
(1)CASE1:当位于写流程中,若Follower接收到来自Leader的日志同步请求后,发现这个Leader并非最新任期,怎么办?
Follower会拒绝这个Leader的日志同步,并且在响应中告知已经改朝换代,让其退位成Follower。之后旧Leader的日志将会被新Leader的日志覆盖。
(2)CAES2:当位于写流程中,若Follower接收到日志同步请求,但是自己的日志落后怎么办?
Follower会拒绝这次的日志同步请求,并且响应自身的Term,Leader发现这个Term是正确的但是又拒绝了同步,就会递归尝试向Follower发送前一笔日志,直到补齐Follower所有的丢失日志后,回归正常。
(3)CASE3:当位于写流程中,若Follower接收到日志同步请求,但是自己的日志超前怎么办?
例如Leader向Follower发送「prevTerm:4,prevIndex:3,term:4」,但Follower的最新日志ID为「term:3,index:3」,于是Follower会移除这部分
超前的日志,然后同步Leader的传送日志。
要点:由CASE2、CASE3可以保证所有节点的日志不论是顺序还是内容都达到完全一致。
(4)极端CASE4:已提交日志被覆盖
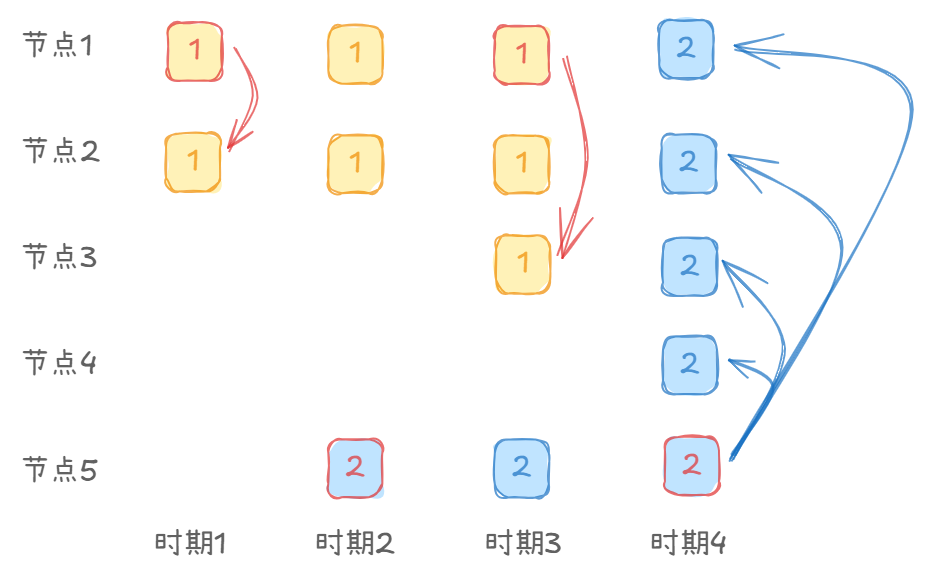
有这样一个情况:
- 时刻1:节点1是Leader,收到一个写请求,日志在节点1、节点2完成了同步,此时还不能提交,因为人数不够,然后节点1宕机。
- 时刻2;节点5获取了节点3、4、5的投票,当选新Leader,此时收到了一个写请求,日志记录在了节点5后,节点5宕机。
- 时刻3:节点1重新当选Leader,此时它继续同步term1时期的日志到节点3中,此时同步节点数过半,于是可以进行提交操作。提交后节点1宕机了。
- 时刻4:节点3恢复,因为它的最新的日志的term最大,可以当选上新的Leader,然后它会同步它的日志,因此其他节点的term1的日志就被覆盖了。
这样的情况导致了已经提交的日志被覆盖,这是绝对不允许的情况,会导致Raft算法的一致性原则遭到破坏。
为了解决这一个问题,Raft提出:新上任的Leader,必须完成一个最新的写请求后,才能对旧term的未提交日志进行提交。
有了这一项rule后,在时刻3,就算节点1当选了新的Leader,也需要完成一个Term3时期的写请求,才能提交日志1,避免了提交日志被覆盖的可能性。
实际在落地的工程项目中,每个Leader上任后,都会向集群广播同步一笔内容为空的日志(no-op),若这个请求提交成功,那么多数派都写入了这个任期的日志,就不会发生上述问题了(从时期2,节点5发送一个空日志,会覆盖掉日志1,这样日志1就不会被提交成功)。
这里将学习文章提到的Q都写下来,方便自己以后反问自己:
Q1:为什么能保证一个任期内至多只有一个领导者?
选举的机制可以保证,一个Follower只能投一张票,获取了半数票以上的才能当领导者。
Q2:为什么能保证通过任期和索引相同的日志内容一定相同?
首先,Raft的任期是非严格递增的,并且在统一任期内,只允许存在一个Leader。并且根据Raft的日志同步请求中,Follower的日志更新必须与Leader的日志相同(Term和Index),如此即可保证通过任期和索引相同的日志内容一定相同。
Q3:如果两个节点中分别存在一笔任期和索引均相同的日志,那么在这两笔日志之前的日志是否也保证在顺序和内容上都完全一致?
可以保证,因为在同步日志请求中,Follower收到的请求包含Leader上一次的日志的id,只有当前日志和上一个日志都相同的情况下,Follower才会提交这次日志,通过数学归纳法可以证明之前的完全一致。
Q4:关于选举机制方面,如何解决选票瓜分引发的问题?
可以通过防止在同一时刻,存在多个candidate这一情况来避免,具体做法是当Follower的心跳等待超时后,可以在等待随机的时间后再成为Candidate。
Q5:为什么新任 leader 一定拥有旧 leader 已提交的日志?
通过两阶段提交和选举流程中的多数派原则来保证的,首先两阶段提交中,多数Follower都会有旧Leader最新的日志;然后来到选举流程中,下一个被推举为Leader的Candidate必须含有最新的日志信息,于是就可以保证它拥有旧Leader已经提交的日志。
Q6:是否一项提议只需要被多数派通过就可以提交?
如CASE4,特定情况并不可以。
Q7:leader 向 follower 同步日志时,如何保证不出现乱序、丢失、重复的问题?
乱序、重复问题:follower同步日志的时候,会校验上一笔日志是否相同,因此可以避免。
丢失问题:Leader需要接收到Follower的ACK,否则会超时重发。
Q8:如何保证各节点已提交的预写日志顺序和内容都完全一致?
同Q3、Q2。
Q9:如何保证状态机数据的最终一致性?
保证了日志的顺序和内容完全一致,就能保证状态机数据的最终一致性。
Q10:如何解决网络分区引发的无意义选举问题?
该问题指的是假如有一个小群体被分割在了网络区域中,然后要选举新的Leader,因为它们并不知道自己被分割了,一直得不到多数的回应,会不断的迭代选举Term的情况。
通过每个Candidate在发出真实选举之前,发出请求试探能否得到多数派的回应,避免自己的网络区域出现了问题但是不知情,若得到了回应才发起选举。
Q11:如果保证客户端提交写请求不丢失、不重复?
不丢失:通过ACK机制保证。
不重复(客户端向 Leader 发送写请求,但在 Leader 处理完成前,网络超时 或 Leader 崩溃 ,客户端无法得到确认,导致重试请求):客户端的请求中携带一个唯一请求ID,最终由服务端的Leader实现对相同请求的幂等去重操作。