南京大学联合NVIDIA、浙江大学、上海交通大学、东京大学发布MM-Lifelong数据集,定义"多模态终身理解"新任务。181.1小时视频横跨三个时间尺度,GPT-5只能采样50帧来处理,准确率14.87%。人类80.4%。作者提出ReMA智能体,通过递归记忆管理将准确率提升至18.62%------目前最高,但与人类差距依然巨大。
大模型能理解连续视频吗?
多模态大模型的上下文窗口越来越长,但面对真正的长时间视频理解任务,这够用吗?
现实是:面对181小时的连续视频,GPT-5在测试中被输入了50帧采样。 在此基础上回答需要跨天、跨周推理的问题,准确率只有14.87%。
同一批问题,人类准确率80.4%。差距超过5倍。
这不是GPT-5一家的问题。同样的测试中,Qwen3-VL-235B采样1536帧,准确率14.33%;其他模型如Nemotron-v2-12B、Eagle-2.5-8B等,准确率在4%-10%之间。所有端到端多模态大模型的表现都在15%左右或更低。
南京大学联合NVIDIA、浙江大学、上海交通大学、东京大学,刚刚发布了揭示这个问题的数据集------MM-Lifelong。论文同时提出了一个新方案ReMA(递归多模态智能体),将准确率提到了18.62%。
论文第一单位是南京大学,合作机构包括NVIDIA、浙江大学、上海交通大学和东京大学。数据集由南大团队构建,模型开发由南大、浙大和NVIDIA联合完成。
什么是"终身理解"?
先澄清一个概念。传统视频理解任务是这样的:给AI一段3分钟的视频,问"视频里的人穿了什么颜色的衣服?"这不难,因为答案就在眼前。
MM-Lifelong要做的完全不同。它定义了一个新概念------终身理解(Lifelong Understanding) 。
核心区别在于两个时间维度:
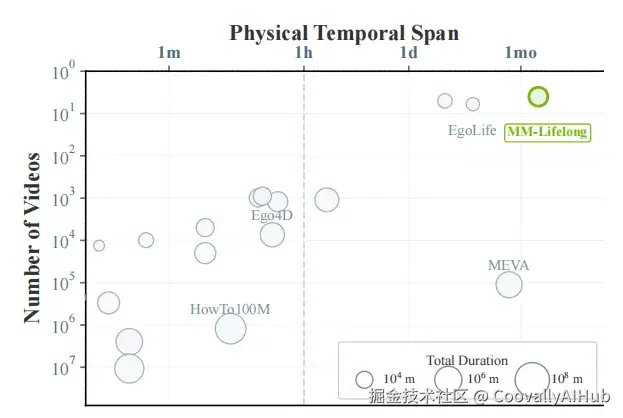
- 观测时长(T_dur) :AI实际要处理的视频总时长 → 181.1小时
- 物理时间跨度(T_span):这些视频在真实世界里横跨多长时间 → 最长51天
传统数据集中,这两个值几乎相等------一段3分钟的视频就是连续的3分钟。但在真实生活中,视频是断断续续的。你可能今天拍了2小时,三天后又拍了1小时,中间有大量未被记录的间隙。AI必须在这些"时间孤岛"之间建立联系。
论文把这种 T_span >> T_dur 的场景定义为终身区域(Lifelong Regime)。
- 三个尺度的设计
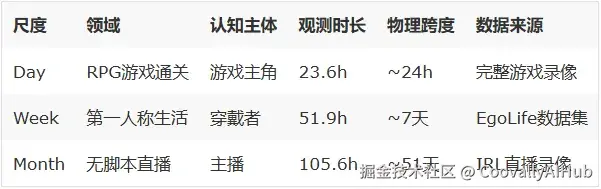
这三个尺度不是随便选的。Day尺度视频基本连续,测试AI的密集记忆能力;Week尺度有日间间隙,测试跨天推理;Month尺度跨51天,中间有大量未观测期,测试的是AI的长期记忆和跨事件推理------这是最难的。
- 两类挑战
数据集包含1289个问题和1810个线索区间,其中267个问题需要跨1-10小时推理,127个问题需要跨越超过10小时的时间跨度。

问题分两类:
- Needle-in-a-Lifestream(大海捞针型):在100多小时视频中找到一个特定瞬间。比如"相机掉落的确切时刻"。
- Multi-Hop Reasoning(多跳推理型):聚合分散在数小时甚至数天的多个线索。比如"这个主播在A、B、C三个城市的地铁里分别唱了几次这首歌?"------回答这个问题需要从超过10小时的直播中找到分布在不同城市、不同天数的多个片段,逐一确认,再汇总。
两个关键发现:大模型为什么不行
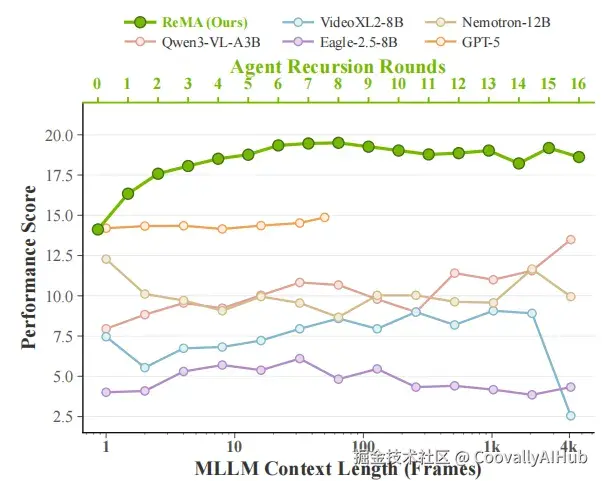
- 发现一:工作记忆瓶颈------帧数越多,反而越差
直觉上,给模型塞进去的视频帧越多,它应该看得越全、理解得越好。
但论文的实验结果完全相反。端到端MLLM在增加输入帧数时,性能先升后降。
以Video-XL-2-8B为例:用1024帧时,在Test@Week上准确率12.00%;增加到2048帧,准确率反而降到10.25%。Eagle-2.5-8B从32帧增加到512帧,在Val@Month上准确率从6.10%降到4.41%。
论文将这个现象称为Working Memory Bottleneck(工作记忆瓶颈) :硬件限制下的稀疏采样引入的是随机噪声而非有效信息。181小时视频中采样几百帧,关键瞬间大概率被漏掉,而被采到的无关帧反而干扰了推理。
更致命的问题不是"答错了",而是"找不到证据"。 论文设计了一个叫Ref@300的指标,衡量模型能否定位到视频中支撑答案的时间段。结果:GPT-5的Ref@300在Month任务上只有0.44,Qwen3-VL-235B更低到0.06------几乎为零。
论文原文的判断很明确:这些模型是在靠语义先验"猜"答案,不是真的从视频中"看到了"证据。
- 发现二:Agent方法也崩了------全局定位失效
那换一个思路:不把所有帧塞给模型,而是用Agent方法让AI自己去视频中"搜索"呢?
论文测试了三个Agent基线:VideoMind-7B、LongVT-7B和DeepVideoDiscovery。它们的策略是先浏览视频全局,再定位到相关片段做精细分析。
但面对MM-Lifelong的月级别时间线,定位能力直接崩溃。VideoMind在Month任务上准确率8.35%,LongVT只有7.54%------比端到端MLLM还低。
论文将此称为Global Localization Collapse(全局定位崩溃) :当时间线从几分钟扩展到51天,搜索空间急剧膨胀,这些Agent的定位策略失效了。
ReMA:教AI"做笔记、翻笔记"
面对这两个瓶颈,论文提出了ReMA(Recursive Multimodal Agent,递归多模态智能体)。
核心思路用一句话概括:不让大模型直接处理整个视频流,而是先把视频变成"笔记",再用"翻笔记"的方式回答问题。
- 两阶段架构
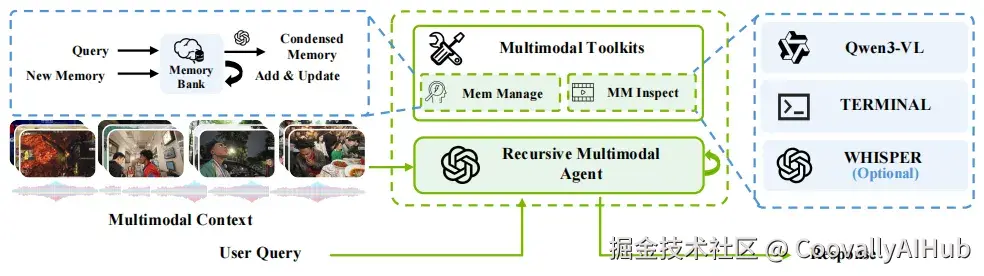
第一阶段:感知------把视频变成记忆库
ReMA把视频切成5分钟的片段。对每个片段,用多模态模型提取摘要,然后通过Memory Bank(记忆库)存储和整合。
181小时视频处理完成后,模型手中不再是几百帧采样图像,而是一个覆盖全时间线的语言化记忆库。
第二阶段:控制------递归搜索记忆回答问题
面对一个问题,ReMA的控制器有三个可选动作(论文主结果中,GPT-5同时担任控制器和多模态感知模型):
- MemSearch: 在记忆库中搜索相关条目
- MMInspect: 回到原始视频的特定时间段,做精细观察
- Answer: 认为信息足够,输出最终答案
控制器会迭代执行这些动作------搜索记忆→发现可能相关的时间段→回去看具体片段→更新自己的理解→继续搜索------直到信息足够或达到最大轮次。论文发现性能在4-5轮递归后趋于饱和。
这本质上模拟了人类的做法:先回忆大致印象,再翻阅笔记确认细节,反复迭代直到确认答案。
- 结果
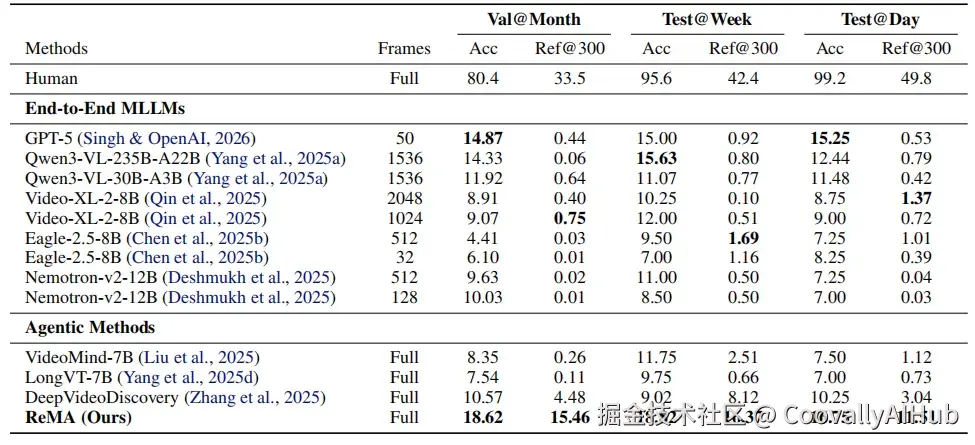
ReMA在所有数据集分割上都取得了最高准确率。在Month任务(最难的尺度)上,ReMA的Ref@300定位得分为15.46,是GPT-5端到端(0.44)的35倍------说明ReMA不只是"猜对了答案",还能真正定位到视频中的证据。
但必须指出:ReMA的18.62%和人类的80.4%之间差距依然巨大。 这篇论文解决的不是"终身理解"问题本身,而是暴露了这个问题的难度、定义了评估框架、并指出了一个可能的方向。
消融实验里的关键发现
论文做了几组消融实验,有几个发现对做AI Agent的开发者很有参考价值。
- 感知粒度:5分钟 vs 直接看全片
ReMA的感知阶段需要把视频切成片段。切多细?论文测了不同粒度(以下数据来自消融实验,使用的模型配置与主结果表不同,因此绝对数值较低,但趋势有参考意义):
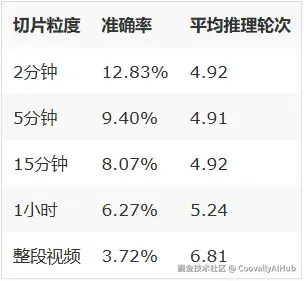
两个关键趋势:
- 粒度越细,效果越好------2分钟切片比5分钟高3.4个百分点。但更细也意味着更多的API调用和成本
- 直接把整段视频喂给Agent,效果最差(3.72%),而且推理轮次最多(6.81轮) ------模型被信息噪声淹没,需要更多轮次去"挣扎",但越挣扎越差
- 纯文本控制器直接崩溃
ReMA的控制器需要在语言空间做推理和规划。一个自然的问题是:这个控制器必须是多模态模型吗?用纯文本LLM行不行?
答案是不行。消融实验显示:
- GPT-5(多模态)作控制器: 准确率9.40%
- Qwen3-VL-A3B(多模态,小模型) :7.12%
- Qwen3-A3B(纯文本版本): 2.30%
- Tongyi-DR(纯文本): 2.88%
纯文本控制器不仅准确率暴跌,而且平均推理轮次仅2.1-2.8轮就提前终止------它无法理解记忆库中的多模态信息,很快就"放弃了"。
即使推理发生在语言空间,控制器也需要多模态对齐能力。 这对设计AI Agent系统有直接启示。
三个值得思考的问题
- "无限上下文"是个幻觉吗?
硬件层面,百万token上下文窗口已经实现。但MM-Lifelong的实验表明:有能力存储不等于有能力理解。 181小时视频转成token数量是天文数字,即使上下文窗口装得下,模型也无法有效利用------帧数增加反而性能下降。
这不意味着长上下文没用。而是说:对于真正的长时间理解任务,暴力扩上下文不是解法。需要的是像ReMA这样的结构化记忆管理。
- Agent范式比端到端更有前途?
在这个任务上,是的。ReMA的核心优势在于把"理解"拆成了"记忆+检索+推理"三个步骤,每一步都可以独立优化。端到端模型试图一步到位,在数据量和时间跨度足够大时就会崩溃。
这个思路不局限于视频理解。做长文档分析、多轮对话记忆、RAG系统的开发者,都可以从ReMA的架构中获得启发:与其让模型记住一切,不如教它如何高效地"做笔记"和"翻笔记"。
- 人类80% vs AI 18%:差距在哪?
不是算力,不是参数量。差距在于人类天然具备的三种能力:
- 选择性记忆------不需要记住每一帧,自动记住"重要的事"
- 事件驱动的检索------不按时间顺序搜索,而是按事件关联跳转
- 跨时间因果推理------能在三天前看到的一件事和今天发生的一件事之间建立因果链
ReMA在模仿这三种能力,但还非常初级。弥合这个差距,可能需要根本性的架构创新,而不仅仅是"更大的模型"或"更长的上下文"。
论文信息
- 论文:Towards Multimodal Lifelong Understanding: A Dataset and Agentic Baseline
- 作者:Guo Chen, Lidong Lu 等(南京大学、NVIDIA、浙江大学、上海交大、东京大学)
- 通讯作者:Tong Lu(南京大学)
- 日期:Preprint, March 6, 2026
- 数据集:181.1小时,1289个问题,1810个线索区间,三个时间尺度(Day/Week/Month)
- 评估方法:采用GPT-5作为自动评判器,对模型的自由文本回答打分(0/0.5/1分制),并通过人类验证确认一致性(F1=99.39)
- 开源:论文标注了Code和Dataset链接
写在最后
181小时视频、51天时间跨度、127个需要超过10小时推理的问题------MM-Lifelong把"AI理解连续视频"这个任务的难度拉到了一个新的量级。
最强模型18.62%,人类80.4%。这个差距本身就是一个清晰的信号:多模态大模型在感知单个画面上已经接近人类,但在跨长时间维度的理解上,差距依然巨大。
谁能解决"终身理解",谁就打开了AI Agent的下一扇门------不只是看一张图回答一个问题,而是像人一样理解一段持续的生活。