上文有介绍deepseek接入,但是需要 付费,虽然 sliconflow 可以白嫖token,但是毕竟是有限的,本文将介绍一款完全免费的 API------讯飞星火
目录
接入讯飞星火(免费)
先去官网注册:讯飞开放平台-以语音交互为核心的人工智能开放平台
然后创建应用,获得自己的 APPID,APISecret 和 APIKey,不会操作的可以看下面这篇教程,也很详细:
如何使用api接入星火大模型(超详细,亲测有效!)_星火api-CSDN博客

只有一个大语言模型是免费的,其他的都是只能体验
获取到自己的 APPID、APISecret、APIKey

点击文档,点击调试,点击右上角转换模板为代码:

复制代码到 pycharm 中,会自动帮你补上 apiPassword

python
import requests
if __name__ == '__main__':
url = "https://spark-api-open.xf-yun.com/v1/chat/completions"
data = {
"max_tokens": 4096,
"top_k": 4,
"temperature": 0.5,
"messages": [
{
"role": "system",
"content": ""
},
{
"role": "user",
"content": "你是谁"
}
],
"model": "4.0Ultra"
}
data["stream"] = True
header = {
"Authorization": "Bearer 你的password"
}
response = requests.post(url, headers=header, json=data, stream=True)
# 流式响应解析示例
response.encoding = "utf-8"
for line in response.iter_lines(decode_unicode="utf-8"):
print(line)代码中 content 就是你要提问的问题,我这里问题是"你是谁",右键运行(记得改api password):
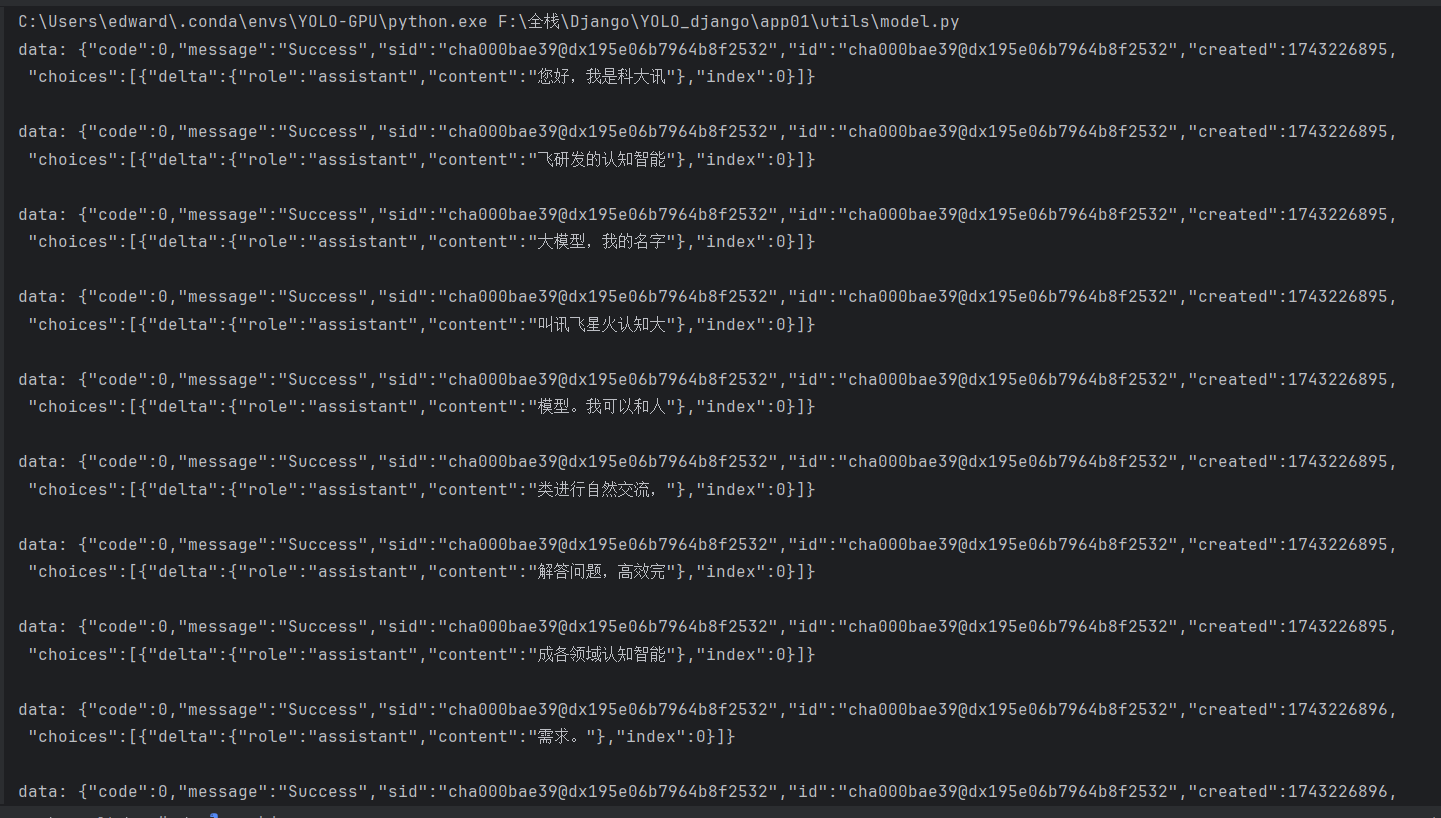
测试对话
大模型是可以根据上下文进行推断的,即根据系统和用户的对话不断改正模型,用户的每次对话,都相当于在调整模型参数,知道最终得到用户想要的结果,下面举一个例子:
python
import requests
if __name__ == '__main__':
url = "https://spark-api-open.xf-yun.com/v1/chat/completions"
data = {
"max_tokens": 4096,
"top_k": 4,
"temperature": 0.5,
"messages": [
{
"role": "system",
"content": "你好,我是讯飞大模型"
},
{
"role": "user",
"content": "怎么去重庆"
},
{
"role": "system",
"content": "可以坐火车、做高铁"
},
{
"role": "user",
"content": "我不想用那样的交通工具"
},
],
"model": "4.0Ultra"
}
data["stream"] = True
header = {
"Authorization": "Bearer 你的api密钥"
}
response = requests.post(url, headers=header, json=data, stream=True)
# 流式响应解析示例
response.encoding = "utf-8"
for line in response.iter_lines(decode_unicode="utf-8"):
print(line)这里,我自己构造了一段对话,模型说"可以做火车、高铁去重庆",我说"我不想用那样的交通工具",运行代码后,模型果真给出了不坐火车、高铁去重庆的几种方法:
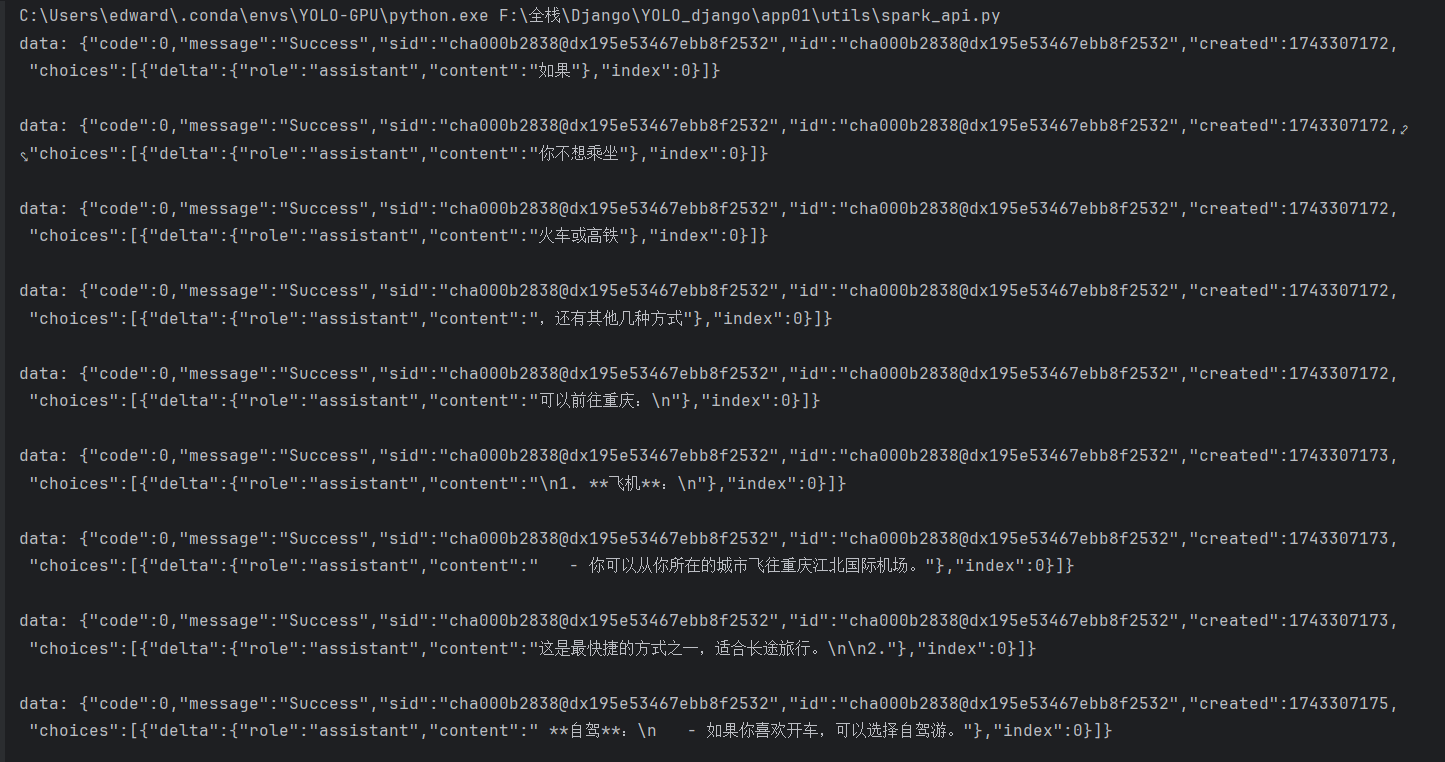

在对话的过程中,对话信息存储在 message中,然后传参给模型,模型自适应调参,输出更加靠近正确答案的结果。
接入Django
上诉对话可接入 Django 中,实现 web端人机交互。
首先得改造 Spark 函数,让其 message参数通过函数参数传递,而不是在函数内自行设置:
python
messages = [
{
"role": "system",
"content": "你好,我是讯飞大模型",
},
{
"role": "user",
"content": "怎么去重庆",
},
{
"role": "system",
"content": "可以坐火车、做高铁",
},
{
"role": "user",
"content": "我不想用那样的交通工具",
},
]
Spark_AI(messages)这样,就能通过视图函数,传递 message 对话参数给该函数,该函数再将构造好的结果字符串返回给 Django。
定义路径:
python
path('detect/spark/', views.detect_spark),定义视图函数:
python
from app01.utils.spark_api import Spark_AI
def detect_spark(request):
messages = [
{
"role": "system",
"content": "你好,我是讯飞大模型",
},
{
"role": "user",
"content": "怎么去重庆",
},
{
"role": "system",
"content": "可以坐火车、做高铁",
},
{
"role": "user",
"content": "我不想用那样的交通工具",
},
]
contents = Spark_AI(messages)
return render(request,"spark.html",{"contents":contents})html页面:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<p>{{ contents }}</p>
</div>
</body>
</html>运行结果:

扩展建议
当然,还要很多优化的地方,大家可以自己做做优化,我这儿提供几点建议:
1、页面做美观,识别换行符等等。
2、上下文在web端输入,每次给出答复后,视图函数会通过数据库或者列表存储上一次的对话内容,作为下一次对话的参数传递给模型。
3、新建对话功能,用于清除或者新建 message 参数数据库或者列表,使得新对话不受之前对话的影响。
4、本方法虽然获取到的数据是一行一行获取,但是处理数据得一下全部处理完,然后才能返回给页面,web 端等待时间很长,可以考虑 websockt 等实时通信手段。
感谢您的观看!!!