系列文章目录
第五章 1:Gated RNN(门控RNN)
第五章 2:梯度消失和LSTM
第五章 3:LSTM的实现
第五章 4:使用LSTM的语言模型
第五章 5:进一步改进RNNLM(以及总结)
文章目录
前言
本节我们先针对当前的RNNLM说明3点需要改进的地方,然后实施 这些改进,并评价最后精度提高了多少。
**一、**LSTM层的多层化
在使用RNNLM创建高精度模型时,加深LSTM层(叠加多个LSTM 层)的方法往往很有效。之前我们只用了一个LSTM层,通过叠加多个层,可以提高语言模型的精度。例如,在下图中,RNNLM使用了两个LSTM层:
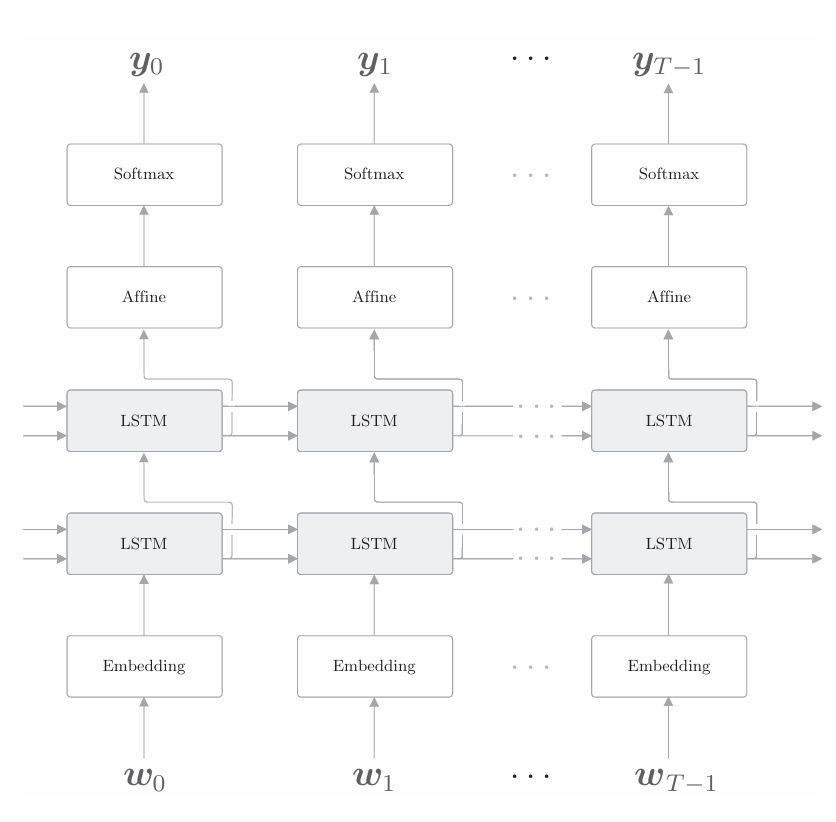
上图显示了叠加两个LSTM层的例子。此时,第一个LSTM层的隐藏状态是第二个LSTM层的输入 。按照同样的方式,我们可以叠加多个LSTM层,从而学习更加复杂的模式,这和前馈神经网络时的层加深是一样的。那么,应该叠加几个层呢?这其实是一个关于超参数的问题。因为层数是超参数,所以需要根据要解决的问题的复杂程度、能给到的训练数据的规模来确定。顺便说一句,在PTB数据集上学习语言模型的情况下,当 LSTM的层数为2~4时,可以获得比较好的结果。
(据报道,谷歌翻译中使用的GNMT模型是叠加了8层LSTM的网络。如该例所示,如果待解决的问题很难,又能准备大量的训练数据, 就可以通过加深LSTM层来提高精度。)
二、基于Dropout抑制过拟合
通过叠加LSTM层,可以期待能够学习到时序数据的复杂依赖关系。 换句话说,通过加深层,可以创建表现力更强的模型,但是这样的模型往往 会发生过拟合 (overfitting)。更糟糕的是,RNN比常规的前馈神经网络更容易发生过拟合,因此RNN的过拟合对策非常重要。
抑制过拟合已有既定的方法:一是增加训练数据;二是降低模型的复杂度。 我们会优先考虑这两个方法。除此之外,对模型复杂度给予惩罚的正则化也很有效。比如,L2正则化会对过大的权重进行惩罚。
此外,像Dropout这样,在训练时随机忽略层的一部分(比如 50%)神经元,也可以被视为一种正则化(如下图)。本节我们将仔细研究Dropout,并将其应用于RNN。

如上图所示,Dropout随机选择一部分神经元,然后忽略它们,停止向前传递信号。这种"随机忽视"是一种制约,可以提高神经网络的泛化能力。
当时我们给出了在激活函数后插入 Dropout 层的示例,并展示了它有助于抑制过拟合。(如下图)
那么,在使用RNN的模型中,应该将Dropout层插入哪里呢?首先可以想到的是插入在LSTM层的时序方向上,如下图所示。不过答案是, 这并不是一个好的插入方式。
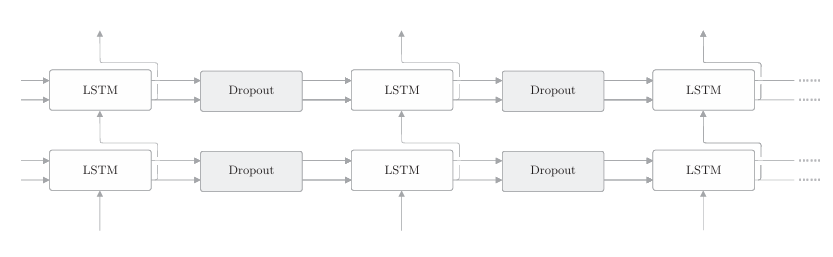
如果在时序方向上插入Dropout,那么当模型学习时,随着时间的推移,信息会渐渐丢失。也就是说,因Dropout产生的噪声会随时间成比例地积累。考虑到噪声的积累,最好不要在时间轴方向上插入Dropout。因 此,如下图所示,我们在深度方向(垂直方向)上插入Dropout层。
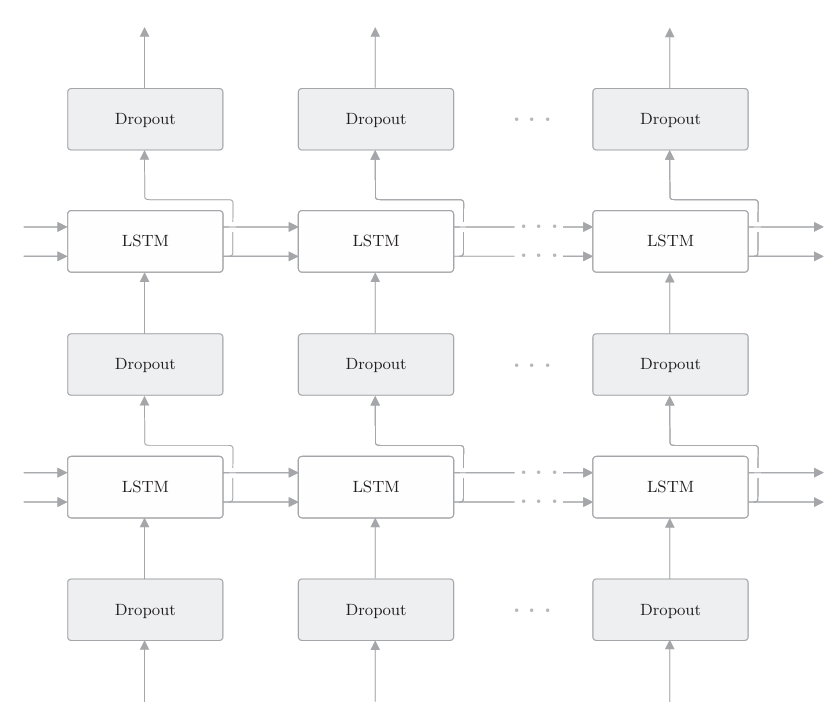
这样一来,无论沿时间方向(水平方向)前进多少,信息都不会丢失。 Dropout与时间轴独立,仅在深度方向(垂直方向)上起作用。
如前所述,"常规的Dropout"不适合用在时间方向上。But ,最近的研究提出了多种方法来实现时间方向上的RNN正则化。比如,由 Diederik P. Kingma 等人在2015年的论文《Variational Dropout and the Local Reparameterization Trick》中提出的"变分Dropout"( variational dropout)就被成功地应用在了时间方向上。
除了深度方向,变分Dropout也能用在时间方向上,从而进一步提高语言模型的精度。如下图所示,它的机制是同一层的Dropout使用相同的mask。这里所说的mask是指决定是否传递数据的随机布尔值。

如下图所示,通过同一层的Dropout共用mask,mask被"固定"。 如此一来,信息的损失方式也被"固定",所以可以避免常规Dropout发生的指数级信息损失。
三、权重共享
改进语言模型有一个非常简单的技巧,那就是权重共享(weight tying)。 weight tying 可以直译为"权重绑定"。如下图所示,其含义就是共享权重
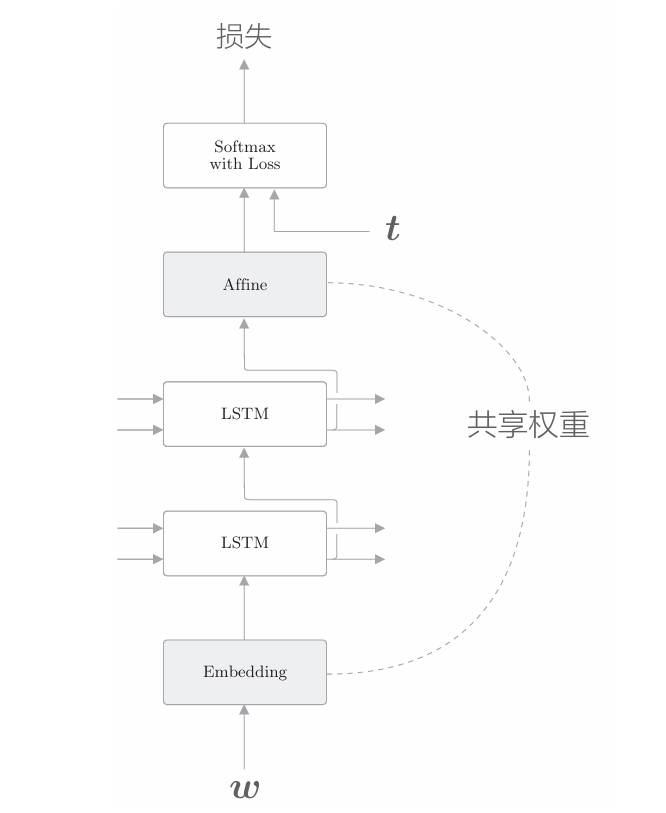
如上图所示,绑定(共享)Embedding层和Affine层的权重的技巧在于权重共享。通过在这两个层之间共享权重,可以大大减少学习的参数数量。尽管如此,它仍能提高精度。真可谓一石二鸟! 现在,我们来考虑一下权重共享的实现。这里,假设词汇量为V, LSTM的隐藏状态的维数为H,则Embedding层的权重形状为V×H, Affine 层的权重形状为H×V。此时,如果要使用权重共享,只需将 Embedding 层权重的转置设置为Affine层的权重。这个非常简单的技巧可以带来出色的结果。
(为什么说权重共享是有效的呢?直观上,共享权重可以减少需要学 习的参数数量,从而促进学习。另外,参数数量减少,还能收获抑 制过拟合的好处。)
四、更好的RNNLM的实现
至此,我们介绍了RNNLM的3点有待改进的地方。接下来,我们来看一下这些技巧会在多大程度上有效。这里,将下图的层结构实现为 BetterRnnlm 类
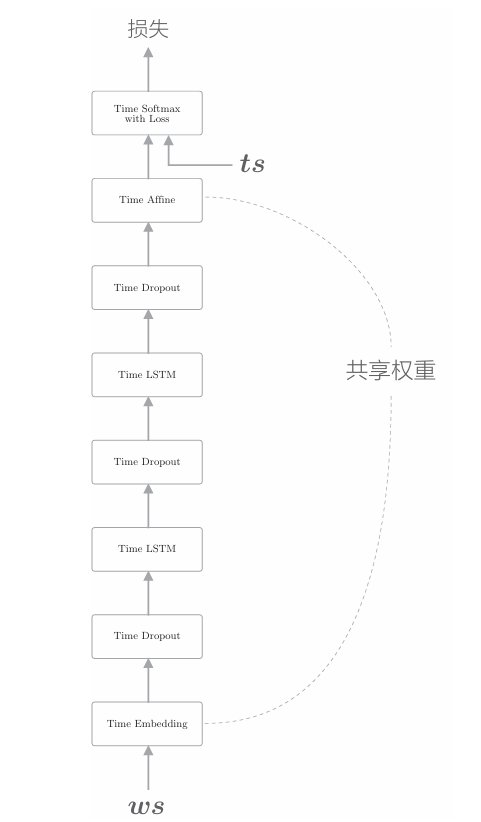
如上图所示,改进的3点如下:
• LSTM层的多层化(此处为2层)
• 使用Dropout(仅应用在深度方向上)
• 权重共享(Embedding层和Affine层的权重共享)
现在,我们来实现进行了这3点改进的BetterRnnlm类,如下所示
python
import sys
import cupy.random # 其实没必要用cupy,直接np.random ,你把这行注释掉
sys.path.append('..')
from common.time_layers import *
import numpy as np
from common.base_model import BaseModel
from common import config # 这里的路径可能要修改,你最好修改成你的项目下的绝对路径,
class BetterRnnlm(BaseModel):
'''
利用2个LSTM层并在各层使用Dropout的模型
基于[1]提出的模型,利用weight tying[2][3]
[1] Recurrent Neural Network Regularization (https://arxiv.org/abs/1409.2329)
[2] Using the Output Embedding to Improve Language Models (https://arxiv.org/abs/1608.05859)
[3] Tying Word Vectors and Word Classifiers (https://arxiv.org/pdf/1611.01462.pdf)
'''
def __init__(self, vocab_size=10000, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# rn = cupy.random.randn() if config.GPU else np.random.randn # 原始代码这里cupy不太好用而且安装有问题,因此注释掉了,直接修改成上面就行了,
# if config.GPU:
# rn = cupy.random.randn
# else:
# rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
# ---------------------------------------
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b) # weight tying!!
]
# ----------------------------------------
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state()代码中"----"之间的就是刚才所说的改进的地方,具体而言,叠加两个 Time LSTM 层,使用Time Dropout 层,并在Time Embedidng 层和 Time Affine 层之间共享权重。
下面进行改进过的BetterRnnlm类的学习。在这之前,我们稍微改动一 下将要执行的学习代码。这个改动是,针对每个epoch使用验证数据评价困 惑度,在值变差时,降低学习率。这是一种在实践中经常用到的技巧,并且往往能有好的结果。这里的实现参考了PyTorch的语言模型的实现示例, 学习代码如下所示
python
import sys
sys.path.append('..')
from common import config
# 在用GPU运行时,请打开下面的注释(需要cupy)# 建议不要用,咱们只需要理解代码就行,我测试过,不太好弄
# ==============================================
# config.GPU = True
# ==============================================
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity, to_gpu
from dataset import ptb
from better_rnnlm import BetterRnnlm
# import cupy
# 设定超参数
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 20.0
max_epoch = 40
max_grad = 0.25
dropout = 0.5
batch_size = 64
# 读入训练数据
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_val, _, _ = ptb.load_data('val')
corpus_test, _, _ = ptb.load_data('test')
# if config.GPU:
# corpus = to_gpu(corpus)
# corpus_val = to_gpu(corpus_val)
# corpus_test = to_gpu(corpus_test)
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus_val)
print('valid perplexity: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params()
else:
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)这里针对每个epoch使用验证数据评价困惑度,当它比之前的困惑度 (best_ppl)低时,将学习率乘以1/4。为此,我们用for循环反复执行以下 处理:通过RnnlmTrainer类的fit()方法进行一个epoch的学习,然后使用验证数据评价困惑度。现在让我们运行一下学习代码。
(这个学习需要相当长的时间。在用CPU运行的情况下,需要2天左右;而如果用GPU运行,则能在5小时左右完成,但是我们只需要理解就行了,让其能运行就OK了)
执行上面的代码,困惑度平稳下降,最终在测试数据上获得了困惑度为 75.76 的结果(每次运行结果不同)。考虑到改进前的RNNLM的困惑度约为136,这个结果可以说提升很大。通过LSTM的多层化提高表现力,通过Dropout 提高泛化能力,通过权重共享有效利用权重,从而实现了精度的大幅提高。
总结
本章的主题是Gated RNN,我们指出了上一章的简单RNN中存在的梯度消失(或梯度爆炸)问题,说明了作为替代层的Gated RNN(具体指 LSTM和GRU等)的有效性。这些层使用门这一机制,能够更好地控制数据和梯度的流动。 另外,本章使用LSTM层创建了语言模型,并在PTB数据集上进行了学习,评价了困惑度。另外,通过LSTM的多层化、Dropout和权重共享等技巧,成功地大幅提高了精度。这些技巧也被实际用在了2017年的最前沿研究中。 下一章我们将使用语言模型生成文本。之后,像机器翻译一样,我们将仔细考察一个将某种语言转换为另一种语言的模型。