目录
[JVM 运行流程](#JVM 运行流程)
[JVM 执行流程](#JVM 执行流程)
[JVM 运行时数据区(面试重点)](#JVM 运行时数据区(面试重点))
[JVM 类加载](#JVM 类加载)
1) 加载 加载)
2) 验证 验证)
3) 准备 准备)
4) 解析 解析)
5) 初始化 初始化)
JVM 运行流程
JVM 是 Java 运行的基础,也是实现一次编译到处执行的关键,那么 JVM 是如何执行的呢?
JVM 执行流程
程序在执行之前先要把java代码转换成字节码(class文件) ,JVM 首先需要把字节码通过一定的方式类加载器(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area) ,而字节码文件是JVM 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine) 将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口本地库接口(Native Interface) 来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。

总结来看, JVM 主要通过分为以下 4 个部分,来执行 Java 程序的,它们分别是:
-
类加载器(ClassLoader)
-
运行时数据区(Runtime Data Area)
-
执行引擎(Execution Engine)
-
本地库接口(Native Interface)
JVM 运行时数据区(面试重点)
JVM 运行时数据区域也叫内存布局,但需要注意的是它和 Java 内存模型((Java Memory Model,简称 JMM)完全不同,属于完全不同的两个概念,它由以下 5 大部分组成:
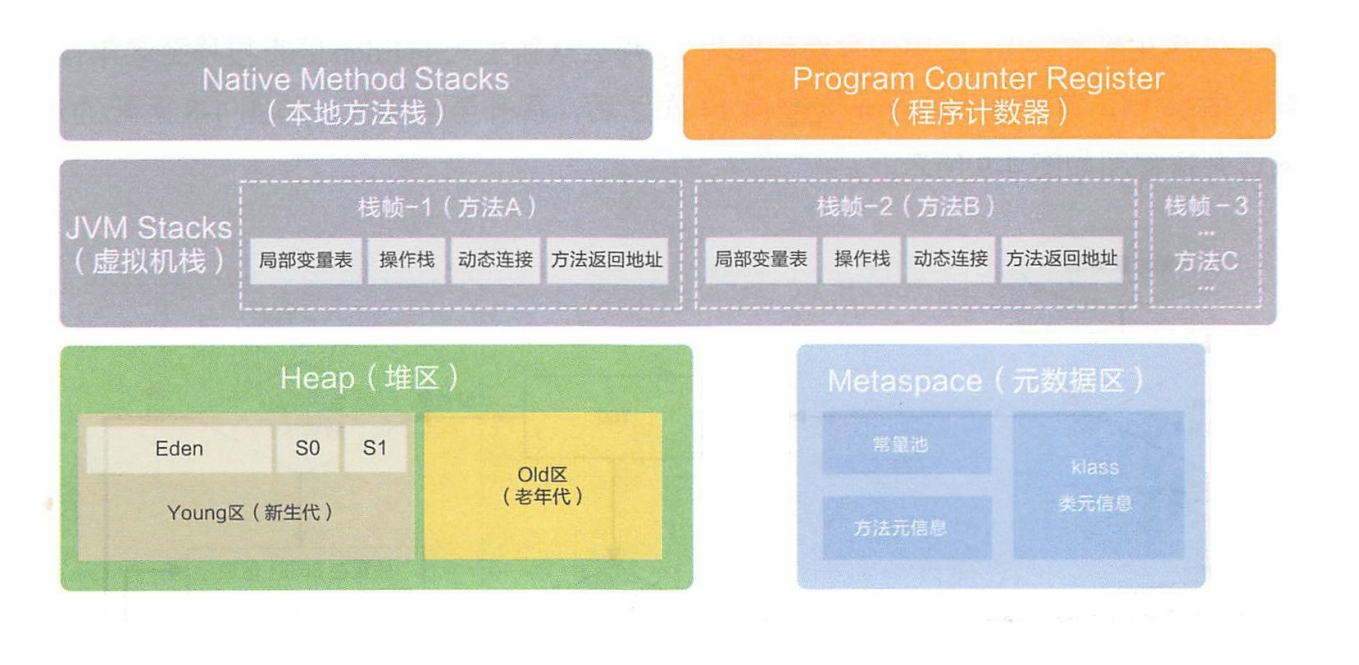
堆(线程共享)
1. 堆(Heap)的作用
堆是 JVM 内存管理中最大的一块区域 ,用于存放所有对象实例和数组。它的主要作用是:
-
存储对象实例 (几乎所有
new关键字创建的对象都会存放在堆中)。 -
垃圾回收的主要管理区域(垃圾回收器会在堆上进行内存回收)。
-
线程共享(堆是 JVM 运行时数据区中所有线程共享的内存区域)。
2. 堆主要存放的是:
-
对象实例 (如 **
new**创建的对象)。 -
数组(JVM 在堆中分配数组对象)。
-
对象的成员变量 (除
static变量外的成员变量)。 -
运行时常量池(存储编译期确定的常量)。
-
类元数据(方法区的一部分) (如
Class对象的实例)
Java虚拟机栈(线程私有)
Java 虚拟机栈的作用:Java 虚拟机栈的生命周期和线程相同,Java 虚拟机栈描述的是 Java 方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈。

-
局部变量表 : 存放了编译器可知的各种基本数据类型(8大基本数据类型)、对象引用。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在执行期间不会改变局部变量表大小。简单来说就是存放方法参数和局部变量。
-
操作栈 :每个方法会生成一个先进后出的操作栈(用于执行方法时的中间计算 ,类似于 CPU 的寄存器)
-
动态链接:指向运行时常量池 的方法引用。
-
方法返回地址:记录方法调用完成后,应该返回的地址,即调用方法的下一条指令地址
本地方法栈(线程私有)
本地方法栈和虚拟机栈类似,只不过 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的。
程序计数器(线程私有)
程序计数器的作用 :用来记录当前线程执行的行号的。
程序计数器是一块比较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器。
如果当前线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址 ;
如果正在执行的是一个Native方法,这个计数器值为空。
程序计数器内存区域是唯一一个在JVM规范中没有规定任何OOM情况的区域!
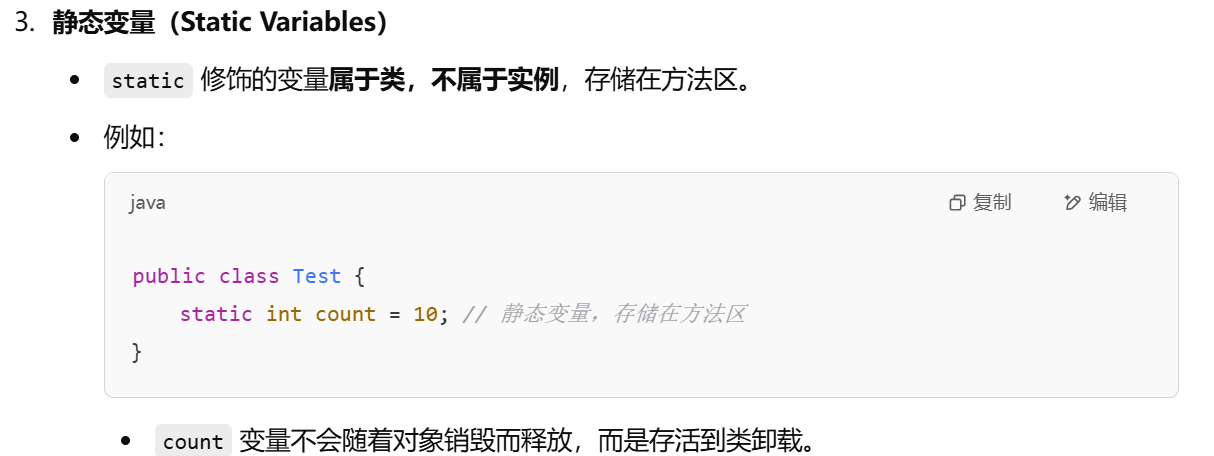
方法区(线程共享)
方法区的作用:用来存储被虚拟机加载的类信息 、常量 、静态变量、即时编译器编译后的代码等数据的。
运行时常量池
运行时常量池是方法区的一部分,存放字面量 与符号引用 。
字面量 : 字符串(JDK 8 移动到堆中) 、final常量、基本数据类型的值。
符号引用 : 类和结构的完全限定名、字段的名称和描述符、方法的名称和描述符
方法区存储的内容:



实战(面试类型)
题型:给出一个代码,问你哪个变量,事处于内存中那个位置?
示例代码:
java
class Test{
public int n = 100;
pubilc static int a = 10;
}
void main(){
Test t = new Test();
}1.new Test(): 这个对象是new出来的,所以这个变量在堆中。
2.n: n这个变量是被包含在new Test()中的,所以也在堆中。
3.t: 但是t这个变量并不是对象,它是一个局部变量 ,所以存储在栈帧 中的局部变量表 中,因此t是存储在栈中。
4.a :a这个变量是类中 的静态变量 ,存储在元数据区 的类元信 息中,也就是在方法区中。
总结:局部变量处于栈中;成员变量处于堆中;静态变量处在方法区
JVM 类加载
类加载过程(背)
对于类加载来说总共分为以下几个步骤:
1) 加载
加载:找到**.class文件**,打开文件,读取文件的内容

2) 验证
验证:.class文件是一个二进制的格式.(某个字节都是有某些特殊含义的),就需要验证你当前读到的这个格式是否符合要求。

3) 准备
准备:给类对象分配一个内存空间(最终目标,是要构造出类对象)【这里只是分配内存空间,还没开始初始化.此时这个空间上的内存数值,就全是0(此时如果尝试打印类的static成员,就全是0的)】
4) 解析
解析:针对类对象中包含的字符串常量进行处理,进行一些初始化的操作。【Java代码中用到的字符串常量,在编译之后,也会进入到.class文件中。】

final String s = "test";如上代码,.class文件的二进制指令中,也会有一个s这样的引用被创建出来。但是由于引用本质保存的是一个变量的地址,在.class文件中,这是文件,是不涉及到内存地址的。因此在.class文件中,s的初始化语句,就会先被设置成一个"文件偏移量",通过偏移量,就能找到"test"这个字符串所在的位置。当我们这个类真正得被加载带内存中的时候,再把这个偏移量替换回真正的内存空间。
5) 初始化
初始化:针对类对象进行初始化,把类对象中需要的各个属性都设置好【需要初始化好static成员,需要执行静态代码块,加载父类(可能)】
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
双亲委派模型(优先级)
双亲委派模型是属于**"类加载"**中的一个环节"加载"过程中,其中的一个环节,负责根据全限定类名,找到.class文件。
类加载器(JVM中的一个模块):
1.BootStrap ClassLoader(爷)
2.Extension ClassLoader(父)
3.Application ClassLoader(子)
类加载的过程(找.class文件的过程):
1.给定一个类的全限类名,形如java.lang.String
2.从BootStrap ClassLoader作为入口,开始执行查找的逻辑
3.Application ClassLoade r,不会立即区扫描自己负责的目录(负责的是搜索项目当前目录的第三方库对应的目录),而是查找的任务交给它的父亲,Extension ClassLoader
4.Extension ClassLoader,也不会立即区扫描自己负责的目录(负责的是JDK中一些扩展的库,对应的目录),而是把查找的任务交给它的父亲BootStrap ClassLoader。
5.BootStrap ClassLoader (,也不想立即扫描自己负责的目录(负责的是标准库的目录),也想把他的任务交给它的父亲,结果发现自己没有父亲。因此BootStrap ClassLoader(只能亲自负责扫描标准库的目录。
像java.lang.String 这种能在标准库中找到对应的.class文件,就可以进行打开文件,读取文件...此时查找.class文件的过程就结束了。但是,如果给定的类不是标准库的类,任务仍然会被交给孩子来执行。
6.没有扫描到,就会回到Extension ClassLoader ,Extension ClassLoader 就会扫描负责的扩展库的目录。如果找到,就执行后续的类加载操作,此时加载过程就结束了。如果没有找到,还是把这个任务交给孩子来执行。
7.如果没有扫描到,就会回到Application ClassLoade r,Application ClassLoade r就会负责扫描当前项目和第三库的目录。如果找到就执行后续的类加载操作。如果没有找到,就会抛出一个ClassNotFoundException。
垃圾回收相关(GC)
GC回收的目标其实就是内存中的对象 【在Java中,即为new出来的这些对象】
而栈里的局部变量 ,是跟随着栈帧的生命周期走的.(方法执行结束,栈帧销毁,内存自然释放)
静态变量 ,生命周期就是整个程序。这和始终存在就意味着静态变量是无需释放的。
因此,真正需要GC释放 的就是堆上的对象。
两大步骤:
如果问"请你介绍垃圾回收",那么你就可以介绍引用计数。如果让你介绍"Java的垃圾回收"就不需要介绍引用计数了。
1.找到垃圾
1)引用计数【Python、PHP】
new出来的对象,单独安排一块空间,来保存一个计数器。保存引用计数,描述这个对象有几个引用指向它。【在Java中,使用对象,必须依靠引用】如果一个对象,没有引用指向了,就可以视为垃圾了(即引用计数为0);
存在问题:
1.比较浪费内存
2.引用技术机制,存在**"循环引用"**问题
2)可达性分析【Java】
可达性分析本质上是时间换空间这样子的手段,有一个/一组线程,周期性扫描我们代码中的所有对象 。从一些特定的对象出发,尽可能得进行访问得遍历,把所有能够访问到得对象,都标记成**"可达"** ,反之,经过扫描之后,未被标记得对象就是**"垃圾"**了。
可达性分析的出发点 有很多,不仅仅是所有的局部变量,还有常量池中引用的对象,还有方法区中的静态引用的变量......这些都统称为GCRoots;
2.释放垃圾
三种基本的思路
1.标记清除: 比较简单粗暴的释放方式(但是会产生很多内存碎片)
【释放内存 目的是为了让别的代码能够申请,申请内存就是申请到"连续"的内存空间】
**2.复制算法:**通过复制的方式,把有效的对象,归类到一起,再统一释放剩下的空间.
缺点:
1)内存要浪费一半,利用率不高
2)如果有效的对象非常多,拷贝开销就会很大
**3.标记整理:**既能够解决内存碎片的问题,又能处理复制算法中利用率 的问题
类似于顺序表 删除元素的搬运操作
缺点:搬运的开销还是很大
实际上,JVM采取的释放思路,是上述基础思路的结合体。
**4.分代算法:**分代算法是通过区域划分,实现不同区域和不同的垃圾回收策略,从而实现更好的垃圾回收。这就好比中国的一国两制方针一样,对于不同的情况和地域设置更符合当地的规则,从而实现更好的管理,这就时分代算法的设计思想。
当前 JVM 垃圾收集都采用的是"分代收集(Generational Collection)"算法,这个算法并没有新思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代。在新生代中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法;而老年代中对象存活率高、没有额外空间对它进行分配担保,就必须采用"标记-清理"或者"标记-整理"算法。

面试题 : 请问了解Minor GC和Full GC么,这两种GC有什么不一样吗?
