文章目录
- 一、执行计划和Profile相关脚本
- 二、如何分析查询
-
- 1、概念了解
- [2、Query Plan](#2、Query Plan)
-
- [①查看 Query Plan](#①查看 Query Plan)
- [②分析 Query Plan](#②分析 Query Plan)
- [3、Query hint](#3、Query hint)
- [4、Query Profile](#4、Query Profile)
-
- [①启用 Query Profile](#①启用 Query Profile)
- [②查看 Query Profile](#②查看 Query Profile)
- [③分析 Query Profile](#③分析 Query Profile)
一、执行计划和Profile相关脚本
| 命令 | 功能 |
|---|---|
| ANALYZE PROFILE | 以 Fragment 为单位分析指定 Query Profile,并以树形结构展示。更多信息,参考 Query Profile 概述。 |
| EXPLAIN | 显示输入查询语句的逻辑或物理执行计划。关于如何分析查询计划,请参考 分析 Query Plan。 |
| EXPLAIN ANALYZE | 执行指定 SQL,并显示相应的 Query Profile 文件。更多信息,参考 Query Profile 概述。 |
| SHOW PROFILELIST | 列出 StarRocks 集群中缓存的 Query Profile 记录。更多信息,参考 Query Profile 概述。 |
更多详情点击进入官网学习查看: https://docs.mirrorship.cn/zh/docs/category/sql-statements/
二、如何分析查询
1、概念了解
StarRocks 每个查询对应一个 QueryID。您可以在日志或者页面中查找到查询对应的 Query Plan 和 Profile。Query Plan 是 FE 通过解析 SQL 生成的执行计划,而 Profile 是 BE 执行查询后的结果,包含了每一步的耗时和数据处理量等数据。
2、Query Plan
SQL 语句在 StarRocks 中的生命周期可以分为查询解析(Query Parsing)、规划(Query Plan)、执行(Query Execution)三个阶段。
决定 StarRocks 中查询性能的关键就在于查询规划(Query Plan)和查询执行(Query Execution),二者的关系可以描述为 Query Plan 负责组织算子(Join/Order/Aggregation)之间的关系,Query Execution 负责执行具体算子。
Query Plan 可以为数据库管理者提供一个宏观的视角,从而获取查询执行的相关信息。优秀的 Query Plan 很大程度上决定了查询的性能,所以数据库管理者需要频繁查看 Query Plan,以确保其是否生成得当。
①查看 Query Plan
sql
EXPLAIN sql_statement;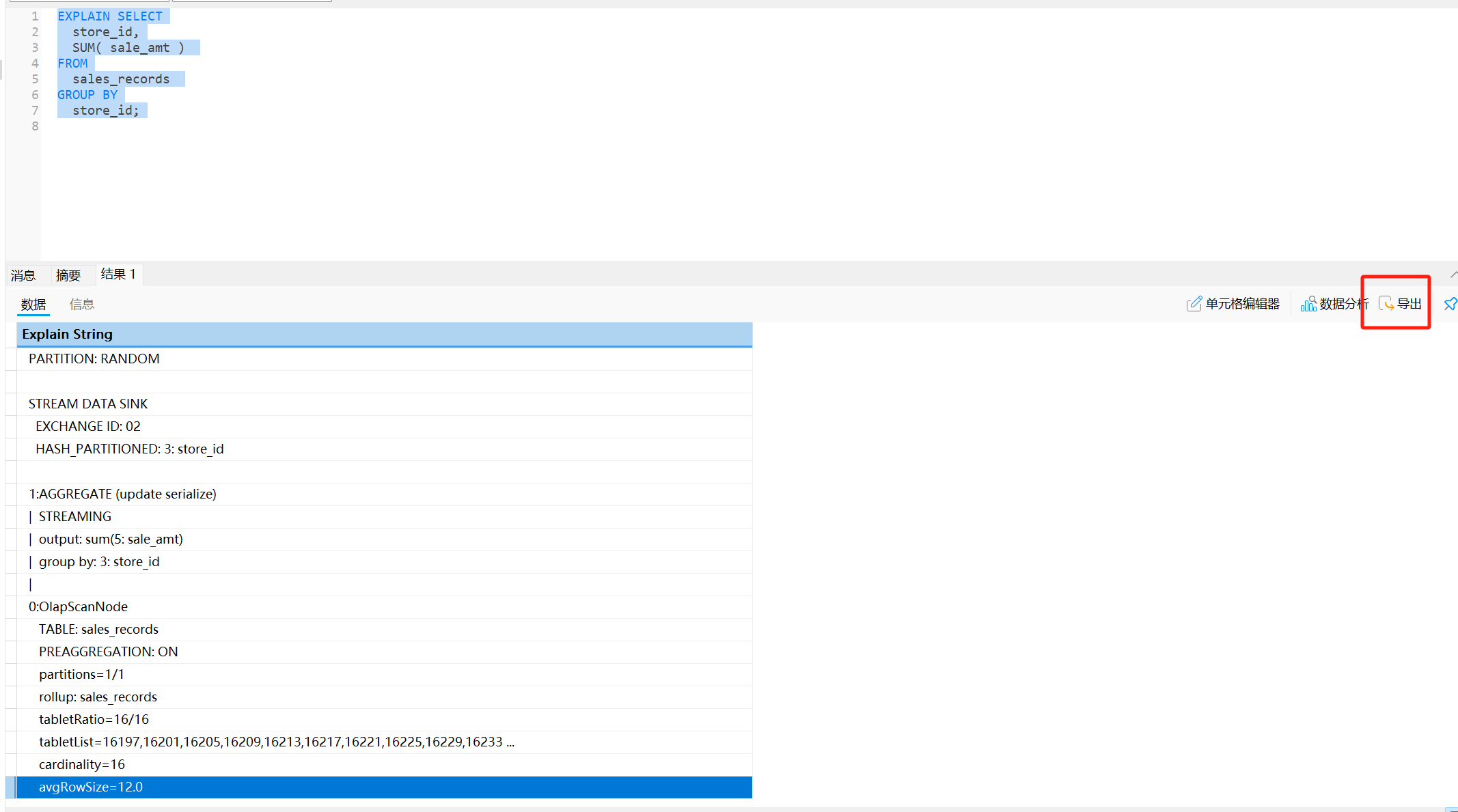
sql
"Explain String"
"PLAN FRAGMENT 0"
" OUTPUT EXPRS:3: store_id | 6: sum"
" PARTITION: UNPARTITIONED"
""
" RESULT SINK"
""
" 4:EXCHANGE"
""
"PLAN FRAGMENT 1"
" OUTPUT EXPRS:"
" PARTITION: HASH_PARTITIONED: 3: store_id"
""
" STREAM DATA SINK"
" EXCHANGE ID: 04"
" UNPARTITIONED"
""
" 3:AGGREGATE (merge finalize)"
" | output: sum(6: sum)"
" | group by: 3: store_id"
" | "
" 2:EXCHANGE"
""
"PLAN FRAGMENT 2"
" OUTPUT EXPRS:"
" colocate exec groups: ExecGroup{groupId=1, nodeIds=[0, 1]}"
" PARTITION: RANDOM"
""
" STREAM DATA SINK"
" EXCHANGE ID: 02"
" HASH_PARTITIONED: 3: store_id"
""
" 1:AGGREGATE (update serialize)"
" | STREAMING"
" | output: sum(5: sale_amt)"
" | group by: 3: store_id"
" | "
" 0:OlapScanNode"
" TABLE: sales_records"
" PREAGGREGATION: ON"
" partitions=1/1"
" rollup: sales_records"
" tabletRatio=16/16"
" tabletList=16197,16201,16205,16209,16213,16217,16221,16225,16229,16233 ..."
" cardinality=16"
" avgRowSize=12.0"②分析 Query Plan
| 名称 | 解释 |
|---|---|
| avgRowSize | 扫描数据行的平均大小。 |
| cardinality | 扫描表的数据总行数。 |
| colocate | 表是否采用了 Colocate 形式。 |
| numNodes | 扫描涉及的节点数。 |
| rollup | 物化视图。 |
| preaggregation | 预聚合。 |
| predicates | 谓词,也就是查询过滤条件。 |
| partitions | 分区。 |
| table | 表。 |
3、Query hint
如果需要指定创建物化视图的子查询执行超时时间,可以在 SELECT 子句中使用 SET_VAR hint 设置系统变量 query_timeout。
sql
CREATE MATERIALIZED VIEW mv
PARTITION BY dt
DISTRIBUTED BY HASH(`key`)
BUCKETS 10
REFRESH ASYNC
AS SELECT /*+ SET_VAR(query_timeout=500) */ * from dual;4、Query Profile
①启用 Query Profile
sql
SET enable_profile = true;通过设置变量 big_query_profile_threshold 设置超过 30 秒的查询会启用 Query Profile 功能。这样既保证了系统性能,又能有效监控到慢查询。
sql
-- 30 seconds
SET global big_query_profile_threshold = '30s';
-- 500 milliseconds
SET global big_query_profile_threshold = '500ms';
-- 60 minutes
SET global big_query_profile_threshold = '60m';Query Profile 启用时,Runtime Query Profile会自动启用,默认的上报时间间隔为 10 秒。您可以通过修改变量 runtime_profile_report_interval 来调整对应的时间间隔:
sql
SET runtime_profile_report_interval = 30;②查看 Query Profile
sql
SHOW PROFILELIST;
SHOW PROFILELIST LIMIT 5;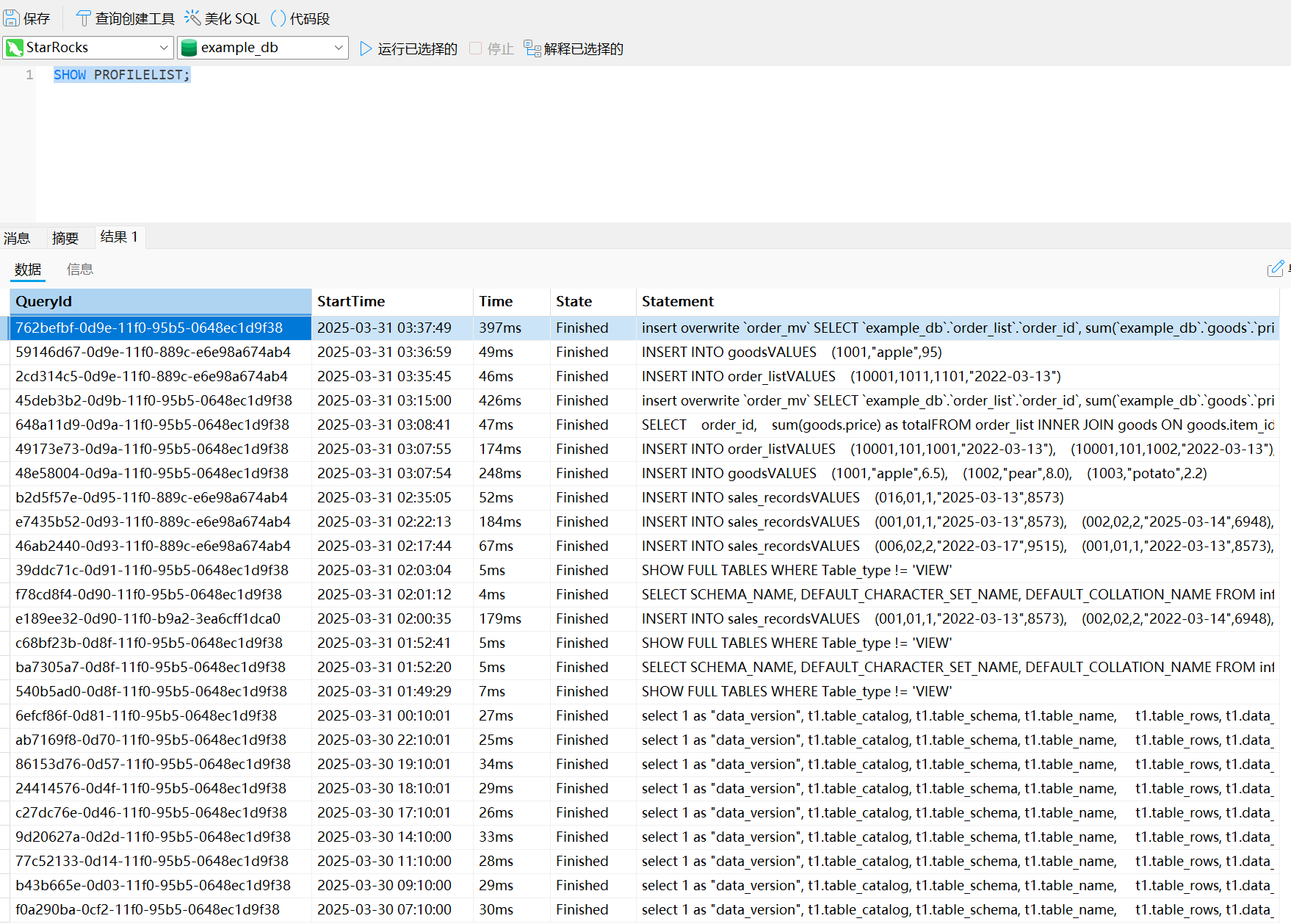
取得 Query ID 后,您可以通过 ANALYZE PROFILE 语句对 Query Profile 进行下一步的分析,其语法如下:
sql
ANALYZE PROFILE FROM '<Query_ID>' [, <Node_ID> [, ...] ]
ANALYZE PROFILE FROM '762befbf-0d9e-11f0-95b5-0648ec1d9f38';