引言
AI技术在今天已经是我们工作生活中不可或缺的工具,很多小伙伴也在致力于训练AI模型。高质量的数据是训练强大AI模型的核心驱动力,无论是自然语言处理、计算机视觉还是推荐系统,数据的规模、多样性和准确性直接决定了模型的性能和泛化能力。然而,在实际的数据采集过程中,往往面临着目标网站限制、IP封锁、数据碎片化等挑战,导致数据获取效率低下,甚至影响模型训练效果。
要解决这些问题,IP代理服务无疑是最佳选择。通过专业的代理IP服务配合高效的数据采集工具,能够为AI大模型训练提供稳定、可靠且合规的数据支持。亮数据作为全球领先的代理服务与数据采集解决方案提供商,覆盖195个国家/地区,提供海量优质IP资源,同时配备智能化的数据采集工具和丰富的现成数据集。无论是数据采集新手还是资深开发者,都能快速上手,高效获取所需数据。接下来,我们将通过两个实际案例,分别体验亮数据的抓取浏览器和AI训练数据集,看看它们如何简化数据采集流程,助力AI模型训练。
使用抓取浏览器采集ebay商品页面
在数据采集过程中,许多开发者常常遇到令人头疼的反爬机制问题。验证码拦截、动态数据加载、内容隐藏等技术手段让不少小伙伴束手无策,一旦遇到这些阻碍,整个数据采集工作就会陷入停滞。针对这些痛点,亮数据的抓取浏览器提供了完美的解决方案。通过内置的智能算法,抓取浏览器会模拟真实用户行为,自动处理各种反爬挑战,最终将完整的页面内容以HTML格式返回,我们在这个结果上继续操作即可,是不是很简单呢?
接下来我们一起配置一下抓取浏览器服务。登录之后,在控制面板中选择抓取浏览器,开始配置亮数据抓取浏览器。
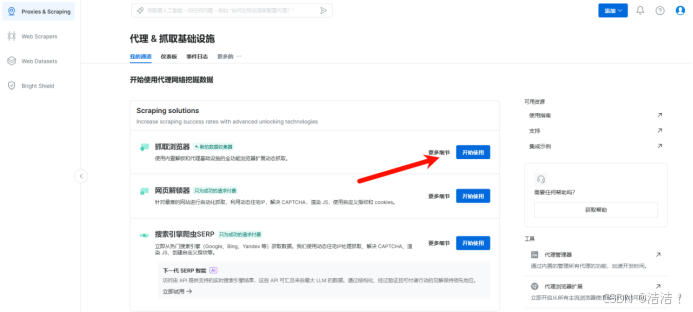
对于普通的网站,只需要配置名字即可,而对于一些保护机制比较复杂的网站则需要选购高级域名。
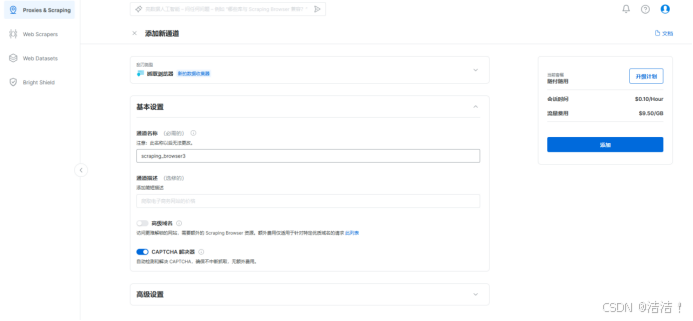
确定之后,就得到了访问抓取浏览器的参数,包括主机名、端口号、用户名和密码,后面需要用这些参数连接浏览器。注意这里一定要将自己的本机IP添加到白名单。

之后就可以通过抓取浏览器访问网站,并将结果发送至本地。接下来我们来编写爬虫程序。首先,我们定义AUTH变量,用来存储了身份验证凭据,并通过该凭据构造SBR_WS_CDP,它用于连接到一个远程的Scraping Browser代理。将目标爬取的网址保存在url中,并留出查询关键词的空位。
python
AUTH = 'brd-customer-hl_a0a48734-zone-scraping_browser3:jt4e2m7roz4f'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
url = f'https://www.ebay.com/sch/i.html?_nkw='之后,在run函数中,使用async_playwright连接到远程的Scraping Browser,创建一个新的浏览器页面,并导航到指定的URL。之后,获取网页的内容并返回。最后浏览器会在操作完成后关闭,以释放资源。
python
async def run(pw, url):
print('Connecting to Scraping Browser...')
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to webpage')
await page.goto(url)
html = await page.content()
return html finally:
await browser.close()再之后定义parse_page函数,目的是解析获取到的HTML内容。它使用lxml库来解析网页,并试图提取包含商品信息的li元素列表。在每个li元素中提取商品的图片链接、标题和价格,并将它们存储到一个字典列表中作为结果返回。
python
def parse_page(html):
root = etree.parse(html)
lis = root.xpath('//ul[@class="srp-list"/li')
result = []
for li in lis:
img = li.xpath('.//div[@class="s-item__image"]/a/div/img/@src]')
title = li.xpath('.//div[@class="s-item__title"]/span/text()')
price = li.xpath('.//span[@class="s-item__price"]/text()')
result.append({"img": img, "title": title, "price": price})
return result最后定义整个程序的入口点。先使用async_playwright进行异步处理,并将url变量添加一个关键词"电脑",用来搜索eBay上的相关产品。然后,调用run函数获取网页内容,并使用parse_page解析页面数据。解析后的数据被写入本地文件。
python
async def main():
global url async with async_playwright() as playwright:
url += '电脑' page = await run(playwright, url)
r = parse_page(page)
with open('电脑.txt', 'w') as f:
f.write(str(r))完整代码如下:
python
import asyncio from playwright.async_api import async_playwright from lxml import etree
AUTH = 'brd-customer-hl_a0a48734-zone-scraping_browser3:jt4e2m7roz4f' SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222' url = f'https://www.ebay.com/sch/i.html?_nkw='
async def run(pw, url):
print('Connecting to Scraping Browser...')
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to webpage')
await page.goto(url)
html = await page.content()
return html finally:
await browser.close()
def parse_page(html):
root = etree.parse(html)
lis = root.xpath('//ul[@class="srp-list"/li')
result = []
for li in lis:
img = li.xpath('.//div[@class="s-item__image"]/a/div/img/@src]')
title = li.xpath('.//div[@class="s-item__title"]/span/text()')
price = li.xpath('.//span[@class="s-item__price"]/text()')
result.append({"img": img, "title": title, "price": price})
return result
async def main():
global url async with async_playwright() as playwright:
url += '电脑' page = await run(playwright, url)
r = parse_page(page)
with open('电脑.txt', 'w') as f:
f.write(str(r))
if __name__ == '__main__':
asyncio.run(main())选购亮数据AI训练数据
在AI模型训练过程中,数据采集往往是最耗时耗力的环节。不同网站采用不同的技术架构和反爬策略,开发者需要针对每个网站单独编写采集脚本,处理各种异常情况,整个过程既复杂又低效。针对这一痛点,亮数据创新性地推出了预置数据集服务,为AI开发者提供了开箱即用的数据解决方案。亮数据的数据集市场汇集了全球主流网站的结构化数据,覆盖电商、社交媒体、新闻资讯等12个垂直领域。所有数据都经过专业的清洗和结构化处理,确保可直接用于模型训练,大幅提升AI项目的开发效率。
接下来我们一起选购AI数据集。登录后在控制面板选择网页数据集,即可进入数据集市场,这里有120个域名超过200种数据集可以直接使用。
比如说我们选择youtube评论数据,可以在过滤器中设置条件筛选数据集。这里我们选择最近一个月的数据。
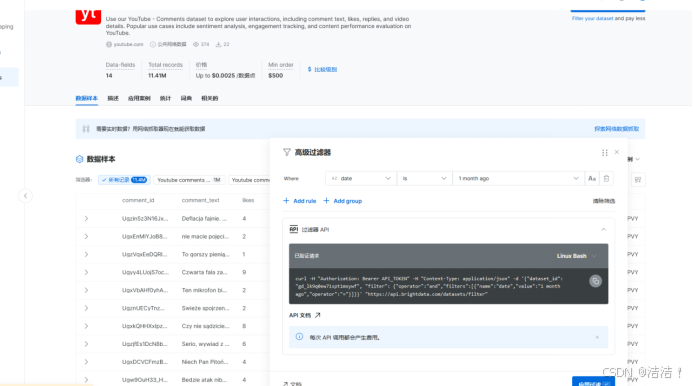
配置好之后点击右上角就可以购买,当然也可以下载一个样本先看一下是否符合我们的要求。
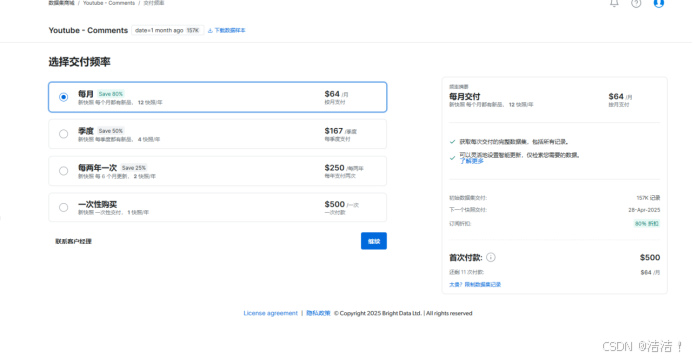
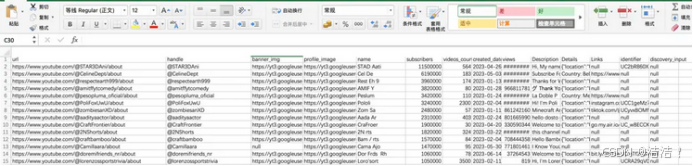
数据以CSV或JSON格式交付,可以看到还是比较全面的。
总结
本文通过两个具体案例展示了亮数据的实际应用:一是利用抓取浏览器动态采集eBay商品数据,从配置到代码实现全程演示;二是直接选购YouTube评论数据集,快速获取结构化数据。这两种方式各具优势,既能满足个性化需求,又能提供开箱即用的高质量数据。未来,随着AI技术的不断发展,对数据规模和质量的要求将愈发严格。亮数据这类专业服务商的出现,不仅解决了数据采集的技术难题,更为AI研发者提供了更多可能性。无论是学术研究还是商业应用,高效合规的数据采集工具都将成为推动AI进步的重要助力。现在亮数据还有一系列免费试用的活动,欢迎大家注册。