一、MySQL中统计查询结果行数的三种方法以及区别
1.1 【统计查询结果行数的方式】
在MySQL中统计查询结果行数,最常采用的方式有三种:count(*)、count(1)或者count(column)。这三种是最常用的count聚合函数使用方式。很多人其实对这三者之间是区分不清的。本文会从执行的结果,查询的效率,使用的场景等方面来分析三者的区别。
1.2 【先说结论】
select COUNT(*):统计表中所有行的数量,无论列是否为 NULL。select COUNT(*):统计所有行 ,这里的1是一个常数表达式,表示每一行都会被计数- select COUNT(colom)
1.3 【实例论证】
(1) 新建测试表,初始化数据
新建测试表

初始化测试数据

(2) 无null值的统计结果

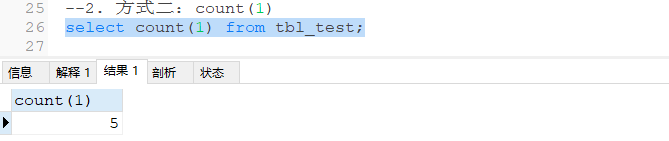
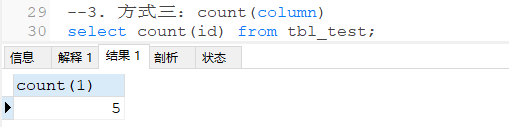
(3) 有null值情况下统计查询结果
模拟null值插入

整体表数据
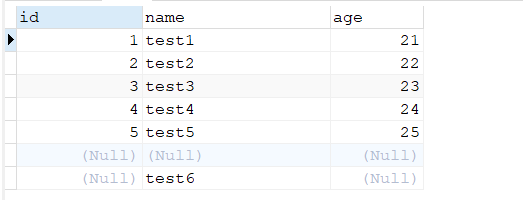
统计结果

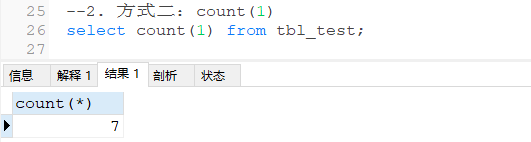

明显发现:count(colnum)统计的查询结果是不包含null的行
二、三种统计查询结果行数的方法的查询效率
经常会看到一些所谓的优化建议不使用count(* )而是使用count(1),从而可以提升性能,给出的理由是count( *)会带来全表扫描。实际情况是如何写count**查询效率一样**,它们三个在底层原理上并不会带来效率质的区别。
上述判断的理由是:通过查看sql执行计划,它们的执行计划没有太大差别

特殊情况:在某些极端情况下,可能会有一些微小的差别:
- 在某些存储引擎中(如
MyISAM),COUNT(*)可能会直接读取存储的行数统计信息,而COUNT(1)也可能会利用同样的优化机制
三、三种统计查询结果行数的方法使用场景
COUNT(*): 一般情况下,推荐使用COUNT(*),因为它的语义更清晰,更容易让其他开发者理解查询的意图。- *
COUNT(1):*在一些旧版本的数据库系统中,可能更倾向于使用COUNT(1),但如今这种差异已经不明显。如果需要统计行数,但希望保持代码的一致性,可以使用COUNT(1),尤其是在代码中已经大量使用这种形式的情况下 - *
COUNT(CLOUMN):*如果明确想统计数据库某个列的查询结果,并且想排除该列值为空的情况