🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
需求定制化开发
源码提供与讲解
技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
🍅 ↓↓主页获取源码联系↓↓🍅
基于大数据的中风患者数据可视化分析系统-功能介绍
本系统是一个基于大数据技术的中风患者数据可视化分析平台,旨在通过高效的数据处理与直观的图表展示,深度挖掘中风患者数据背后的潜在规律与风险因素。系统后端采用Hadoop构建分布式存储环境,利用Spark作为核心计算引擎,实现对海量医疗数据的快速清洗、转换与分析。开发语言选用Python,借助其强大的数据科学生态库,如Pandas与NumPy,进行精细化的数据预处理。系统功能全面,覆盖了从患者群体基础画像(如性别、年龄、职业分布)到核心健康指标(如高血压、血糖、BMI)的统计分析,再到中风风险因素的多维度关联与交叉钻取。通过对年龄、吸烟史、既往病史等变量与中风率的关联计算,系统能够精准定位高风险人群特征。最终,所有分析结果通过Vue前端框架与Echarts可视化组件,以动态交互图表的形式呈现,将复杂的数据转化为易于理解的洞察,为中风病的预防与研究提供数据支持。
基于大数据的中风患者数据可视化分析系统-选题背景意义
选题背景 随着社会生活节奏的加快和人口老龄化趋势的显现,中风已经成为威胁公众健康的主要疾病之一,其高发病率、高致残率和高死亡率的特点,给无数家庭和社会带来了沉重的负担。在临床实践中,医院和医疗机构积累了海量的患者电子病历数据,这些数据中蕴含着关于疾病成因、发展规律和风险因素的宝贵信息。然而,这些数据往往体量巨大、结构复杂且分散在不同系统中,传统的数据分析工具和方法难以有效处理和深度挖掘,导致大量有价值的信息被"淹没"。如何利用新兴的大数据技术,对这些庞大的医疗数据进行系统性的整合与分析,从中发现隐藏的关联模式,从而为中风病的早期预警和精准预防提供科学依据,便成了一个具有重要现实意义的课题。 选题意义 这个课题的意义可以从几个方面来看。对于医疗领域的研究者来说,本系统提供了一个快速、多维度的数据分析工具,能够帮助他们验证一些关于中风风险的假设,比如不同生活习惯或基础疾病组合对中风概率的影响,为更深入的流行病学研究提供了方向和初步的数据参考。从公共卫生的角度看,通过系统分析得出的高风险人群画像,可以帮助卫生部门更有针对性地开展健康教育和预防干预活动,比如向特定年龄段和有特定生活习惯的群体推送预防知识,提升整个社会的预防意识。对于我们计算机专业的学生而言,这个项目是一次将大数据理论技术与实际应用场景紧密结合的绝佳实践,完整地走过了从数据采集、存储、清洗、分析到可视化的全流程,锻炼了解决复杂问题的能力,虽然只是一个毕业设计,但希望能为智慧医疗领域的发展提供一个微小的技术探索样本。
基于大数据的中风患者数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的中风患者数据可视化分析系统-视频展示
基于大数据的中风患者数据可视化分析系统-图片展示

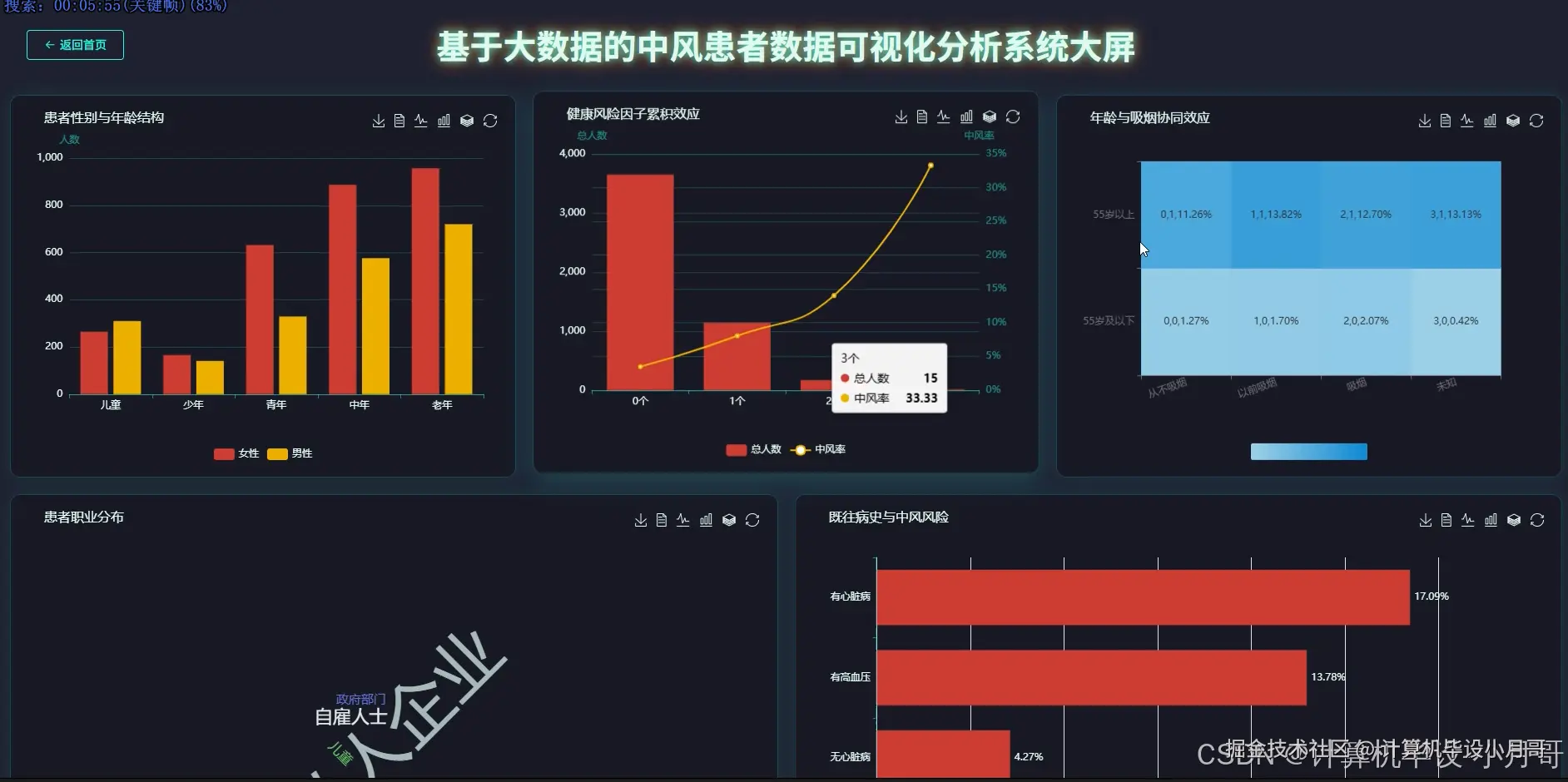
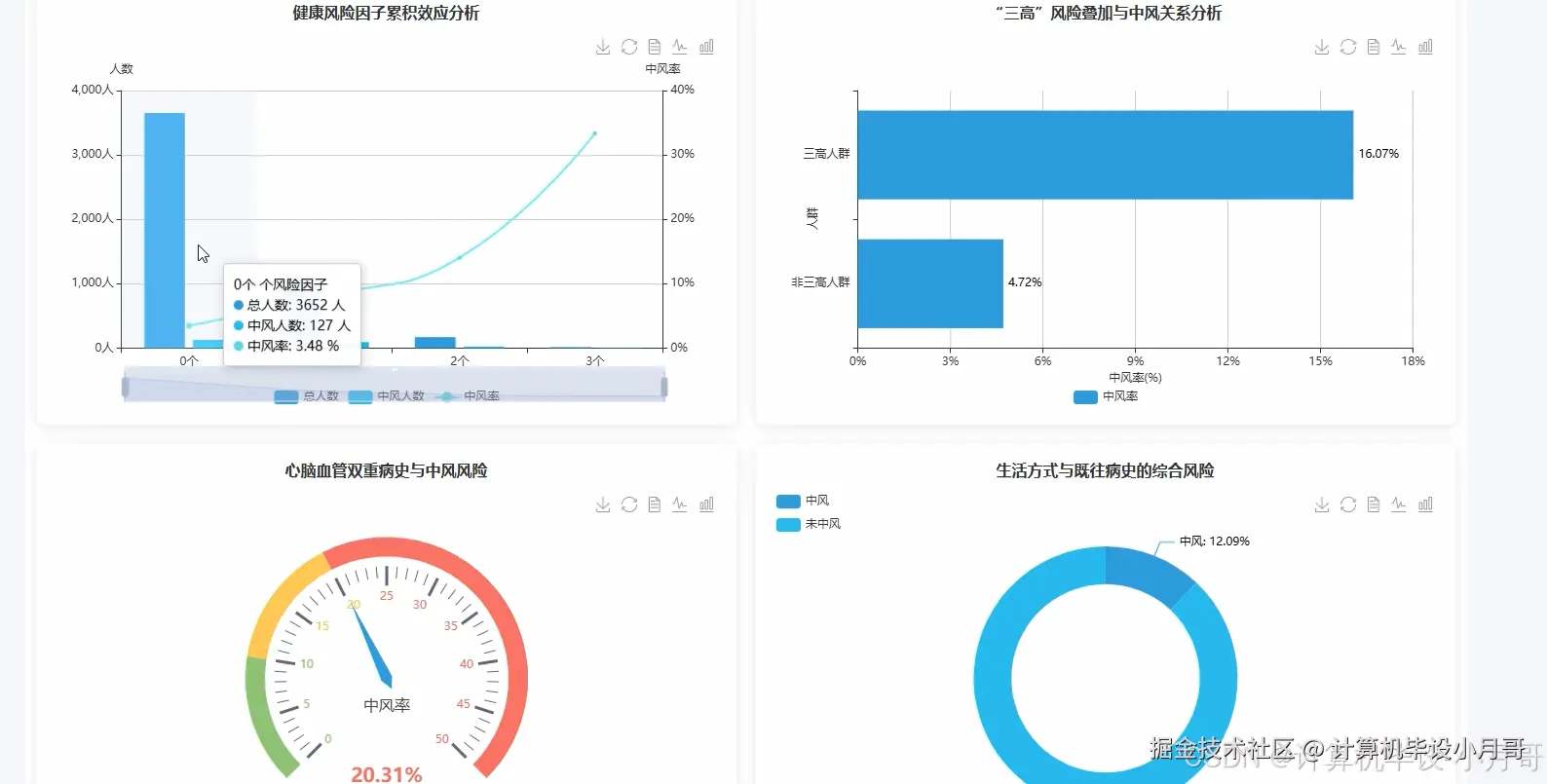
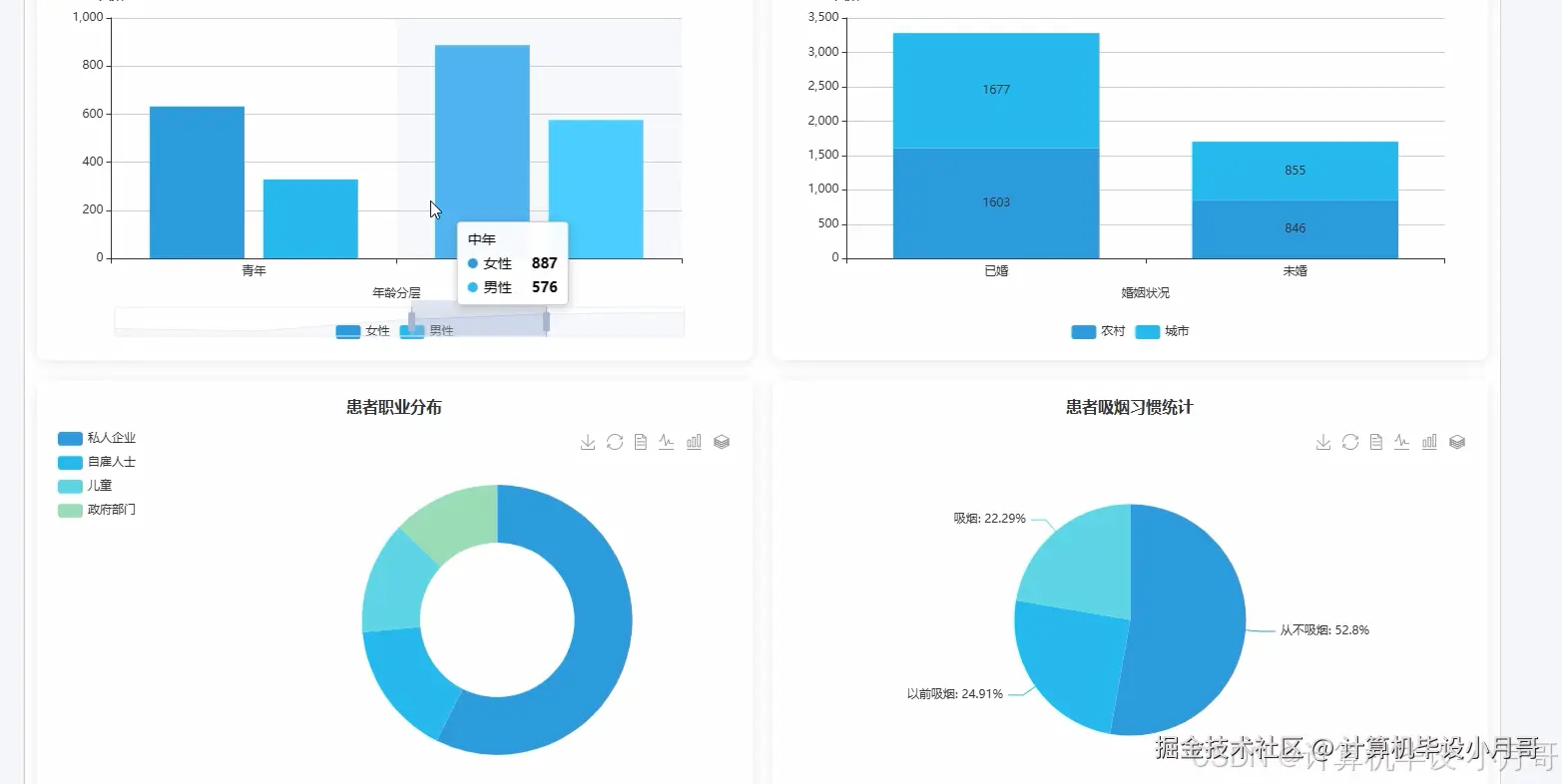
基于大数据的中风患者数据可视化分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, count, avg, sum as spark_sum
spark = SparkSession.builder.appName("StrokeAnalysis").getOrCreate()
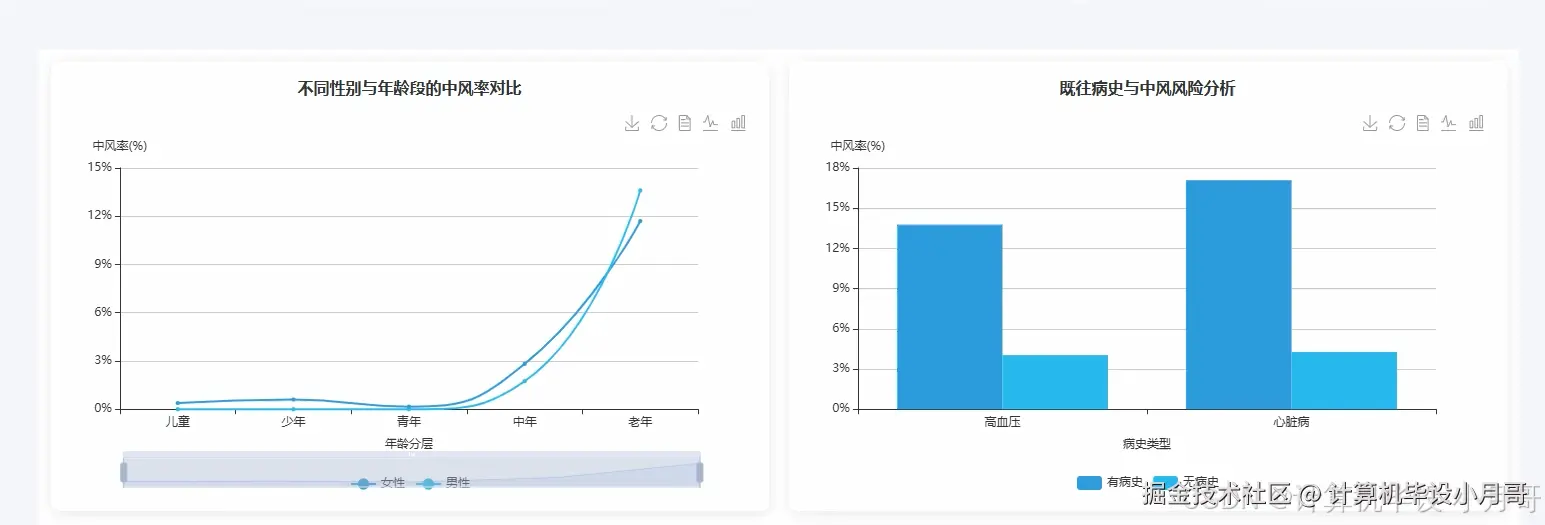
# 核心功能1: 不同性别与年龄段的中风率对比分析 (对应维度3.1)
def analyze_stroke_rate_by_age_gender(df):
df.createOrReplaceTempView("stroke_data")
result_df = spark.sql("""
SELECT
gender,
CASE
WHEN age < 30 THEN '青年'
WHEN age BETWEEN 30 AND 50 THEN '中年'
WHEN age > 50 THEN '老年'
ELSE '未知'
END AS age_group,
COUNT(*) AS total_count,
SUM(CASE WHEN stroke = 1 THEN 1 ELSE 0 END) AS stroke_count,
AVG(stroke) AS stroke_rate
FROM stroke_data
GROUP BY gender, age_group
ORDER BY gender, age_group
""")
result_df.show()
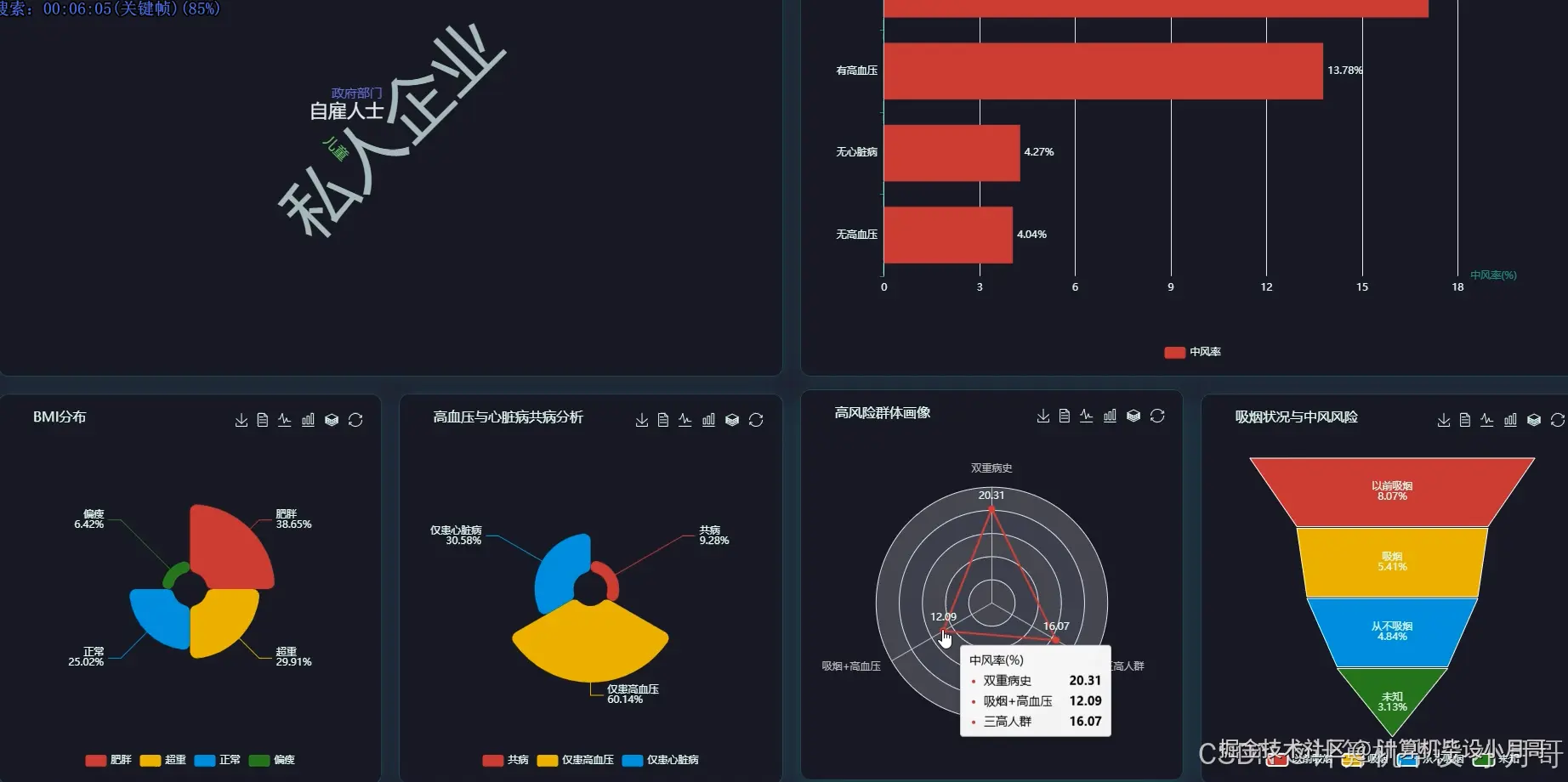
# 核心功能2: 健康风险因子累积效应分析 (对应维度5.1)
def analyze_cumulative_risk_effect(df):
risk_df = df.withColumn("risk_count",
spark_sum(when(col("hypertension") == 1, 1).otherwise(0) +
when(col("heart_disease") == 1, 1).otherwise(0) +
when(col("smoking_status") == "smokes", 1).otherwise(0))
).groupBy("risk_count")
.agg(
count("*").alias("patient_count"),
avg("stroke").alias("stroke_rate")
)
.orderBy("risk_count")
risk_df.show()
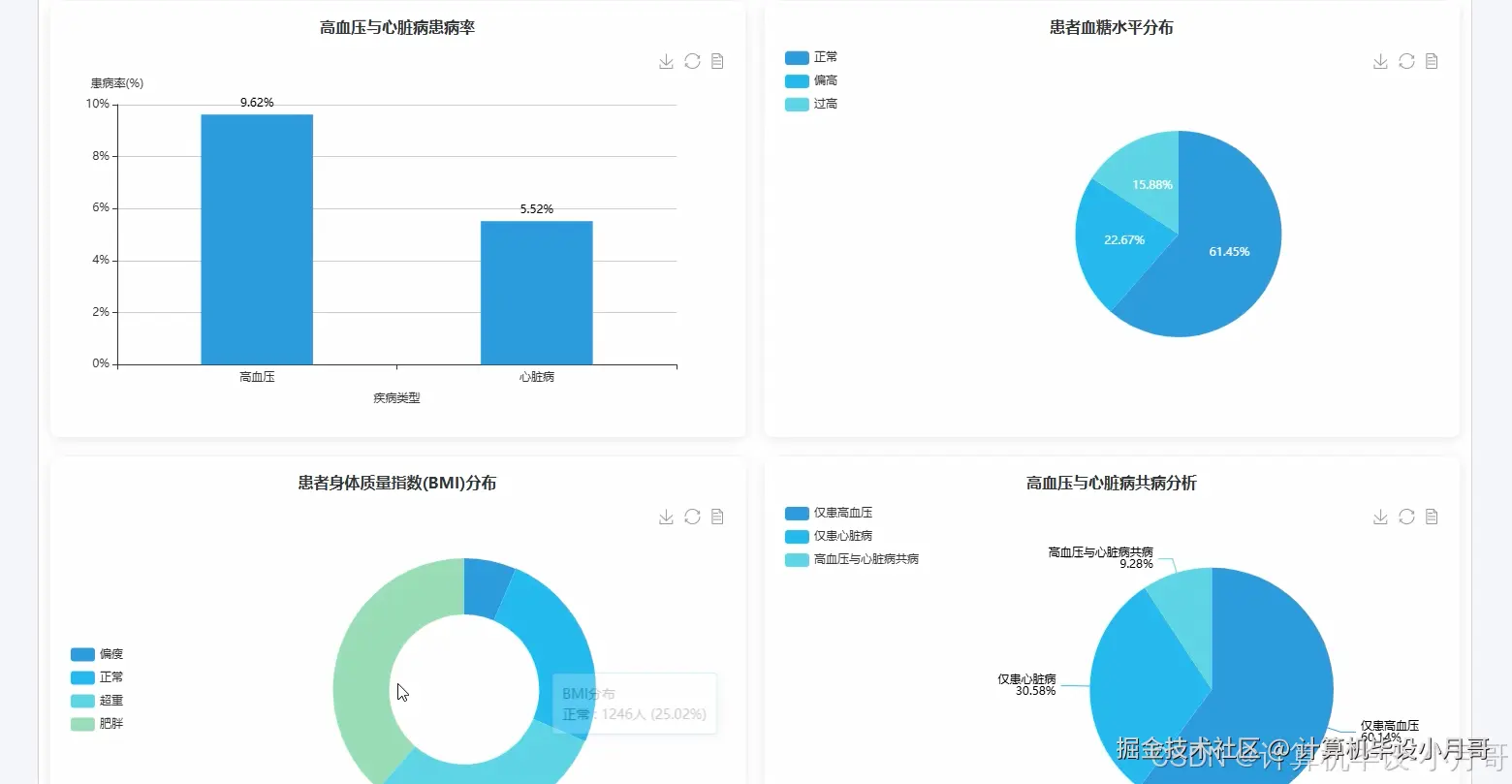
# 核心功能3: 患者血糖水平分布分析 (对应维度2.2)
def analyze_glucose_level_distribution(df):
glucose_binned_df = df.withColumn("glucose_level_category",
when(col("avg_glucose_level") < 90, "正常血糖")
.when((col("avg_glucose_level") >= 90) & (col("avg_glucose_level") < 126), "血糖偏高")
.otherwise("高血糖风险")
).groupBy("glucose_level_category")
.agg(
count("*").alias("patient_count")
)
.orderBy(col("patient_count").desc())
glucose_binned_df.show()基于大数据的中风患者数据可视化分析系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
🍅 ↓↓主页获取源码联系↓↓🍅