听说这里是目录哦
- [ssh登录Permission denied, please try again💩](#ssh登录Permission denied, please try again💩)
- [centos7 yum报错:cannot find a valid baseurl for repo:base/7/x86_64💩](#centos7 yum报错:cannot find a valid baseurl for repo:base/7/x86_64💩)
- FinalShell重连失效💩
- [ssh免密登录显示 No route to host💩](#ssh免密登录显示 No route to host💩)
- [免密登录时显示 Connection refused💩](#免密登录时显示 Connection refused💩)
- 用mv命令移动JDK时显示没有那个文件或目录💩
- 用tar命令解压上传的JDK时显示没有那个文件或目录💩
- [test1: WARNING: /export/servers/hadoop-3.3.0/logs does not exist. Creating.💩](#test1: WARNING: /export/servers/hadoop-3.3.0/logs does not exist. Creating.💩)
- [多次格式化导致secondary namenode等丢失(jps时看不到)💩](#多次格式化导致secondary namenode等丢失(jps时看不到)💩)
- 能量站😚
不知道手机的会不会不一样,电脑里的这坨小便便真的很可爱呀哈哈哈哈~

ssh登录Permission denied, please try again💩
密码正确,但是报错Permission denied, please try again。
原因是远程的服务器,禁用了root账户可以被远程访问的权限。开启操作如下:
- 编辑配置文件
java
vi /etc/ssh/sshd_config- 文件中找到
PermitRootLogin,把PermitRootLogin without-password这行改成PermitRootLogin yes(需要连接的每一台机子都要更改!!!)

如果你是配置了集群的,集群里的机子都改好上述文件后,直接在主节点里start-all.sh开集群就行了,然后jps出来的是下面这样就可以了。

要发癫🥲
如果是HY【懂的都懂,伤心的事就不说了呜呜呜呜】那个实验平台,想要实验二的截图的话,就直接在第一个实验里完成最后一个实验的操作,最后一个实验的环境不行(第二个实验平台没法用上面的步骤jps出正确的东西)💩
解决办法:在第一个实验平台里按照上面的步骤jps出上述图片里的东西以后,就直接执行实验二里的步骤就行了。
补充:可以复制粘贴的,只不过到命令窗口里的粘贴不能使用快捷键Ctrl+v,而是需要右键点击粘贴选项。
 分屏,在两个网页都登录,一个操作,一个看步骤:
分屏,在两个网页都登录,一个操作,一个看步骤:
centos7 yum报错:cannot find a valid baseurl for repo:base/7/x86_64💩
我直接用国内资源,不在谷歌下载。
- 检查网络连接 ,
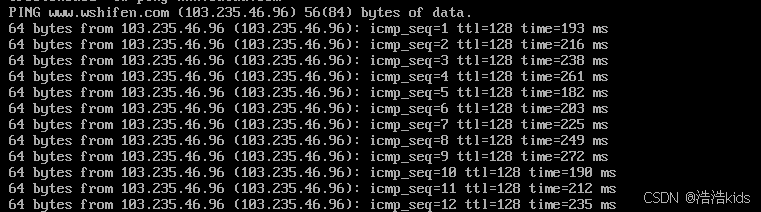
ping www.baidu.com看一下能不能成功。下面这个图就是成功了,你Ctrl+c停止就行。
- 更新YUM仓库源为阿里云镜像源 ,
vi /etc/yum.repos.d/CentOS-Base.repo将内容替换为以下内容:
java
[base]
name=CentOS-$releasever - Base - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[updates]
name=CentOS-$releasever - Updates - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[extras]
name=CentOS-$releasever - Extras - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[centosplus]
name=CentOS-$releasever - Plus - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7- 清理并重建缓存
java
yum clean all
yum makecache
yum updateFinalShell重连失效💩
这种情况是虚拟机的网络连接断了,解决办法如下:
1.关闭NetworkManager
systemctl stop NetworkManagersystemctl status NetworkManager
2.开启network服务
systemctl restart networksystemctl status network
3.检查一下
ip addr

ssh免密登录显示 No route to host💩
没开虚拟机,找不到路径,把虚拟机开了就行。
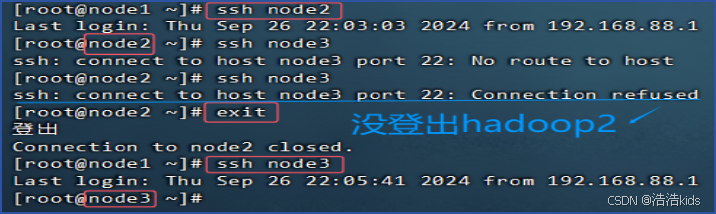
免密登录时显示 Connection refused💩
因为没登出上一台虚拟机,exit登出一下就可以了。(图里蓝色的应该是node2)
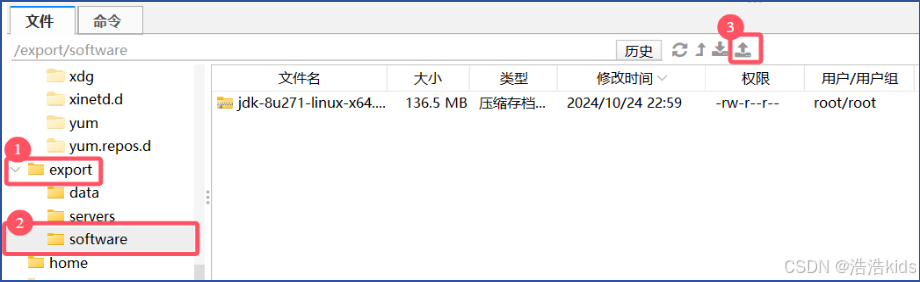
用mv命令移动JDK时显示没有那个文件或目录💩
解决办法:在上传的时候就打开到所需文件夹,在该界面上传时会直接上传到这个文件夹

用tar命令解压上传的JDK时显示没有那个文件或目录💩
解决办法:先cd到存放了JDK的目录,再用ll查看。(即使刷新了FinalShell也不行,要在虚拟机里查看了,懵懵的虚拟机宝宝才能感觉到这个文件的位置,宠着吧,我自己的宝宝,这跟用什么身份解压没关系)
我的安装包是放在/export/software里的。

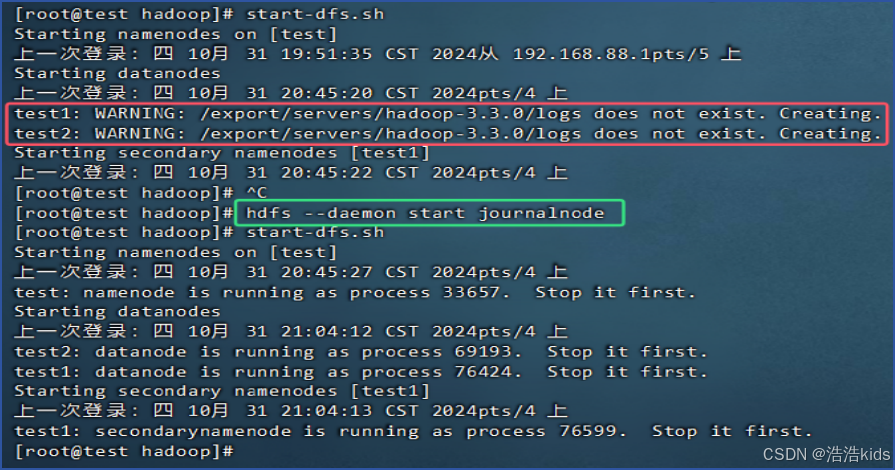
test1: WARNING: /export/servers/hadoop-3.3.0/logs does not exist. Creating.💩
这里是以test为主结点、test1和test2为从结点。
解决办法:在三个节点上启动journalnode,命令是hdfs --daemon start journalnode,就是三台虚拟机都需要执行这个命令。



多次格式化导致secondary namenode等丢失(jps时看不到)💩
解决办法:
- 关闭集群
stop-all.sh - 删除集群产生的缓存文件(三台机子都要!!!)
(一)/export/data的hadoop文件夹(三台机子都要)【我的文件夹存放目录可看Hadoop•安装JDK,可以帮助理解为什么是这个路径】

(二)删除/export/servers/hadoop-3.1.4/logs(三台机子都要)
也是先刷新哦,然后整个文件夹直接删掉,格式化后它会自己创建的
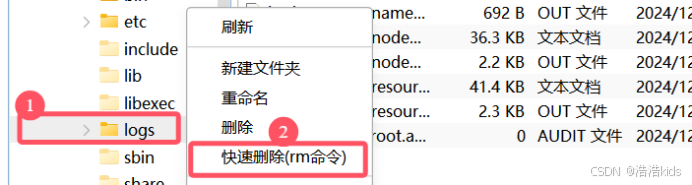
- 重新格式化
hdfs namenode -format
这个警告没事⬇️

能量站😚
有人说哭不能解决问题,但没有人哭是为了解决问题,眼泪自由。

❤️你很好❤️