目录
设计思路
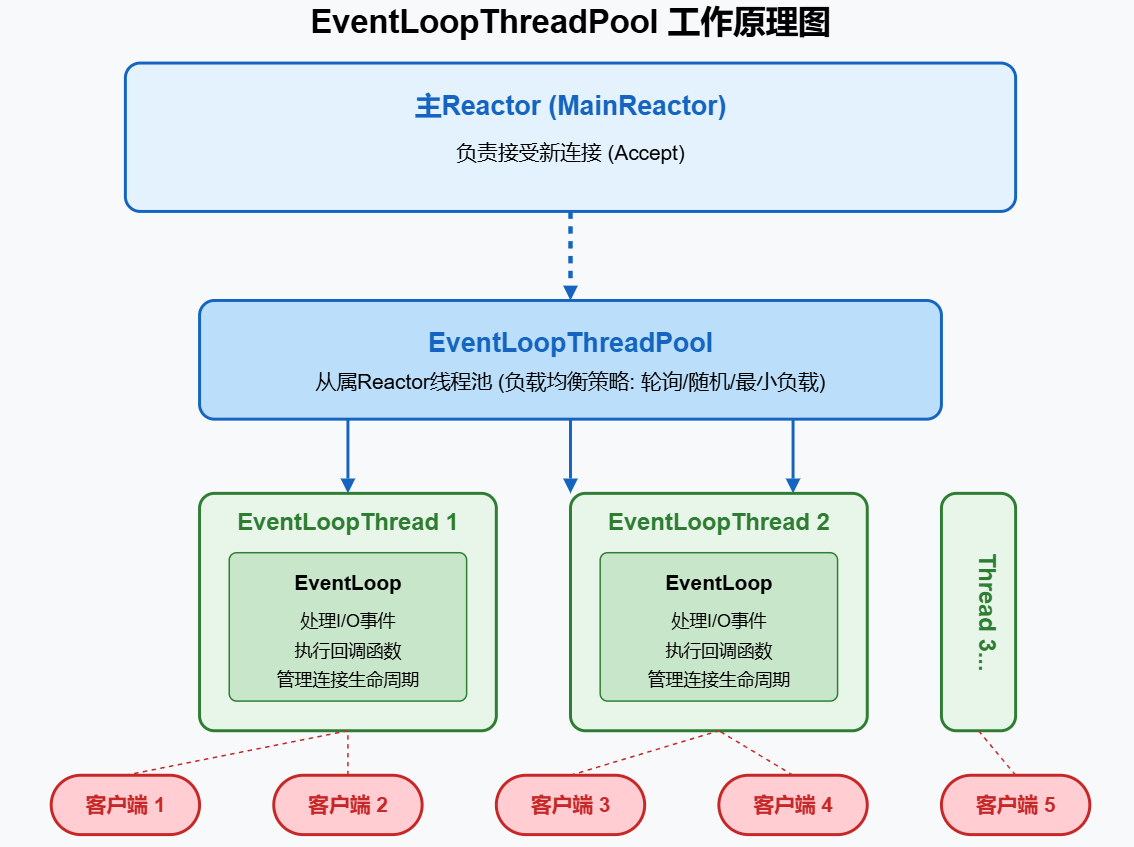
在多Reactor模式中, 通常有一个主Reactor(MainReactor)负责接受连接,然后有多个从属Reactor(SubReactor)负责处理已建立连接的I/O事件。EventLoopThreadPool 就是管理这些SubReactor线程的线程池。
首先确定EventLoopThreadPool需要实现的核心功能:
- 创建和管理多个事件循环线程
- 为新连接分配事件循环(EventLoop)
- 控制线程池的启动和停止
- 支持不同的负载均衡策略
类的设计
那么这个模块内需要哪些成员呢?
既然是管理从属Reactor的线程池,那该怎么管理呢?那当然是要把这从属线程池的对象保存起来 ,所以需要一个vector来保存这些对象,其次还需要一个变量用来统计这些从属线程的数量。同时对于上层来说,未来我们的TcpServer需要获取到从属线程的EventLoop*指针,
TcpServer为什么要获取这个EventLoop指针呢?
- 连接分发:当新连接到来时,TcpServer需要将这个连接分配给某个SubReactor处理。为了实现这一点,它必须获取一个具体的EventLoop*指针,以便将连接相关的操作派发到该线程中。
- 线程安全操作:在多线程环境中,直接操作其他线程的资源可能导致竞态条件。通过获取EventLoop*指针,TcpServer可以使用该EventLoop的runInLoop()或queueInLoop()方法,将操作安全地派发到对应的线程中执行,避免线程安全问题。
- 生命周期管理:连接的创建和销毁应该在同一个线程中进行。当连接建立时,TcpServer会记住为该连接分配的EventLoop*,以便在连接关闭时,能将清理操作派发到正确的线程。
而我们也知道,要从EventLoopThread中获取这个指针需要加锁,如果每一次获取的时候都加锁获取,那么效率不够高,所以我们可以直接用一个vector将所有的从属线程的EventLoop的指针保存起来。
当一些连接到来的时候,该怎么把这个连接分配到线程中呢,我们能不能任意的说,你们去线程一吧,你们去线程二吧,然后这样很随意的把连接分配上去了吗?
这样当然是不行的,TcpServer只负责EventLoopThreadPool中获取一个指针分配给新连接,不会关心负载均衡的问题,所以在EventLoopThreadPool中我们需要完成负载均衡****的工作,最简单的就是使用一个变量作为下一次返回的EventLoop在vector中的下标,每次获取之后都进行++,那么就相当于使用轮转的方式保证了负载均衡。
会不会有一些极端的情况呢,一个从属线程也没有?
那么此时也就是成了单Reactor模型,也就是一个Reactor线程处理所有的操作,那么这时候也需要一个主Reactor线程对应的EventLoop对象,所以我们还需要一个主Reactor线程的指针。这个主Reactor其实就是我们的主线程。
cpp
std::vector<EventLoop*> _loops; // 存储所有从属Reactor线程的EventLoop指针,用于任务分配
std::vector<EventLoopThread*> _threads; // 存储所有从属Reactor线程对象,负责线程的创建和管理
int _thread_cnt; // 从属Reactor线程的总数量,在初始化时设置
int _nextloop_index; // 轮询负载均衡策略中下一个要分配的EventLoop索引
EventLoop* _main_loop; // 主Reactor线程的EventLoop指针,在线程池为空时使用这里注意的一个细节就是,我们存储的线程对象,并不是存储对象本身,而是存储他的指针,未来在开始创建线程的时候才会真正创建对象。 因为存储对象本身的话,未来在resize的时候,时会有问题的,EventLoopThread中的成员都是不可拷贝的。
那么他需要提供哪些接口呢?
首先,需要提供接口用于设置从属线程数量。 其次,需要提供接口启动线程池 。还需要一个接口用于分配EventLoop ,也就是**返回一个EventLoop***给TcpServer用于给新连接绑定EventLoop对象。
cpp
public:
EventLoopThreadPool();
void SetThreadCount(); //设置从属线程数量
void Start(); //启动线程池
EventLoop* GetEventLoop(); //分配从属EventLoop*模块实现
首先还是先进行构造函数
cpp
EventLoopThreadPool(EventLoop* mainloop)
,_thread_cnt(0)
,_nextloop_index(0)
,_main_loop(nullptr)
{}注意这个主Reactor线程是在TcpServe创建的,后续在构造EventLoopThreadPool中传入进来作为基础的EventLoop。
然后就是设置线程数量
这个看一眼就明白了,一笔带过了
cpp
void SetThreadCount(int count) //设置线程的数量
{
_thread_cnt = count;
}接着就是获取EventLoop指针,供上层使用
为新连接分配一个EventLoop(从属Reactor线程)。它使用轮询(Round-Robin)策略来均衡地分配连接
先进行单Reactor模式检查 ,然后进行轮询负载均衡 ,使用取模运算实现循环轮询。每次调用此方法时,**_nextloop_index都会自增1,**然后对线程总数取模,确保索引在有效范围内循环。这样就实现了连接在所有从属线程间的均匀分配。返回轮询选出的EventLoop指针,上层代码(通常是TcpServer)将使用这个EventLoop来处理新连接的所有后续I/O事件。
cpp
EventLoop *GetEventLoop()
{
if(_thread_cnt ==0)
{
return _main_loop;
}
_nextloop_index = (_nextloop_index + 1) % _thread_cnt;
return _loops[_nextloop_index];
}最后就是进行启动了
cpp
void Start() //它负责初始化和启动线程池中的所有从属Reactor线程。
{
if(_thread_cnt > 0)
{
//先进行扩容
_threads.resize(_thread_cnt);
_loops.resize(_thread_cnt);
//创建线程,再获取loop
for(int i = 0; i < _thread_cnt; i++)
{
_threads[i] = new LoopThread;
_loops[i] = _threads[i] ->GetEventLoop();
}
}
return;
}1.条件检查 :首先检查 _thread_cnt是否大于0,也就是判断用户是否配置了至少一个从属Reactor线程。如果没有配置从属线程(即 _thread_cnt为0),就直接返回,此时线程池退化为单Reactor模式,所有工作都由主Reactor线程完成。
2.容器扩容 :**_threads.resize(_thread_cnt);_loops.resize(_thread_cnt);**这两行代码为线程指针数组和EventLoop指针数组分配空间,确保它们有足够的容量来存储所有将要创建的线程和EventLoop对象。
3.线程创建与初始化:
- 为每个线程索引创建一个新的LoopThread对象
- 调用每个LoopThread的GetEventLoop()方法获取其内部的EventLoop指针
- 将这些LoopThread指针和EventLoop指针分别存储在
_threads和_loops数组中
这样,当**Start()**方法执行完成后,线程池就创建并启动了所有配置的从属Reactor线程,每个线程都运行着自己的EventLoop事件循环,准备处理分配给它的连接。
从实现上看,这里使用了常见的"延迟创建"模式------线程对象直到 **Start()**被调用时才真正创建,而不是在构造函数中就创建好,这给了用户配置线程池的机会。
疑惑点
std::vector<EventLoop*> _loops; 为啥还需要这个?不能直接去从属reactor线程对象里面去找吗 ?不是一个线程里面创建一个EventLoop吗?

EventLoopThread中的成员都是不可拷贝的。怎么理解不可拷贝呢?
