Auto-Encoding Variational Bayes
- 文章概括
- 摘要
- [1 引言](#1 引言)
- [2 方法](#2 方法)
-
- [2.1 问题场景](#2.1 问题场景)
- [2.2 变分下界](#2.2 变分下界)
- [2.3 SGVB估计器与AEVB算法](#2.3 SGVB估计器与AEVB算法)
- [2.4 重参数化技巧](#2.4 重参数化技巧)
- [3 示例:变分自编码器(Variational Auto-Encoder)](#3 示例:变分自编码器(Variational Auto-Encoder))
- [4 相关工作](#4 相关工作)
- [5 实验](#5 实验)
- [6 结论](#6 结论)
- [7 未来工作](#7 未来工作)
文章概括
引用:
bash
@misc{kingma2013auto,
title={Auto-encoding variational bayes},
author={Kingma, Diederik P and Welling, Max and others},
year={2013},
publisher={Banff, Canada}
}
markup
Kingma, D.P. and Welling, M., 2013. Auto-encoding variational bayes [online]原文:
代码、数据和视频:
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
摘要
我们如何在具有连续潜变量的、有向概率模型中进行高效的推断与学习,同时应对后验分布不可解的情况与大规模数据集?我们提出了一种随机变分推断与学习算法(stochastic variational inference and learning algorithm),该算法能够扩展至大规模数据集,并且在满足一些温和的可微性条件下,即使在后验分布不可解的情况下也能正常工作。我们的贡献是双重的。首先,我们展示了对变分下界进行重参数化后,可以得到一个下界估计器,该估计器可以直接使用标准的随机梯度方法进行优化。其次,对于具有每个数据点都包含连续潜变量的 i.i.d. 数据集,我们展示了如何通过使用所提出的下界估计器来拟合一个近似推断模型(也称为识别模型)以逼近不可解的后验分布,从而使得后验推断变得特别高效。理论上的优势也体现在实验结果中。
1 引言
我们如何在具有连续潜变量和/或参数,其后验分布不可解的有向概率模型中,进行高效的近似推断与学习?变分贝叶斯(Variational Bayesian, VB)方法的思路是对不可解的后验分布进行近似,并优化该近似。然而,常见的平均场(mean-field)方法需要对近似后验进行期望的解析求解,而在一般情况下这些期望也是不可解的。我们展示了通过对变分下界进行重参数化,可以得到一个简单的、可微的、无偏的下界估计器;该SGVB(Stochastic Gradient Variational Bayes)估计器可以用于几乎任意具有连续潜变量和/或参数的模型中的高效近似后验推断,并且可以使用标准的随机梯度上升方法直接优化。
针对 i.i.d. 数据集以及每个数据点对应连续潜变量的情况,我们提出了自编码变分贝叶斯(Auto-Encoding VB, AEVB)算法 。在AEVB算法中,我们通过使用SGVB估计器优化一个识别模型,从而使推断与学习变得尤其高效。该识别模型使我们能够使用简单的祖先采样进行高效的近似后验推断,进而使我们能够高效地学习模型参数,而无需每个数据点都使用代价昂贵的迭代推断方法(如MCMC)。学习得到的近似后验推断模型也可以用于识别、去噪、表示和可视化等多种任务。当识别模型使用神经网络实现时,我们就得到了变分自编码器(variational auto-encoder)。
2 方法
本节中的策略可用于为多种具有连续潜变量的有向图模型推导一个下界估计器(即一个随机目标函数)。我们在此将讨论范围限制在一个常见情形:我们有一个 i.i.d. 数据集,每个数据点都对应一个潜变量,并希望对(全局)参数进行最大似然(ML)或最大后验(MAP)推断,同时对潜变量进行变分推断。例如,将该情形扩展为对全局参数也进行变分推断是直接可行的;该算法放在附录中,但我们将这部分实验工作留待今后进行。请注意,我们的方法也可以应用于在线、非平稳环境(例如流数据),但为了简化讨论,我们在此假设数据集是固定的。
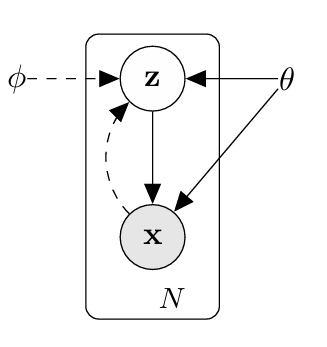 图1说明: 所考虑的有向图模型类型。实线表示生成模型 p θ ( z ) p θ ( x ∣ z ) p_{\theta}(z)p_{\theta}(x|z) pθ(z)pθ(x∣z),虚线表示对不可解后验 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)的变分近似 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x)。变分参数 ϕ \phi ϕ与生成模型参数 θ \theta θ是联合学习的。
图1说明: 所考虑的有向图模型类型。实线表示生成模型 p θ ( z ) p θ ( x ∣ z ) p_{\theta}(z)p_{\theta}(x|z) pθ(z)pθ(x∣z),虚线表示对不可解后验 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)的变分近似 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x)。变分参数 ϕ \phi ϕ与生成模型参数 θ \theta θ是联合学习的。
2.1 问题场景
我们考虑某个数据集 X = { x ( i ) } i = 1 N X=\{x^{(i)}\}{i=1}^N X={x(i)}i=1N,它由 N N N个某个连续或离散变量 x x x的 i.i.d. 样本组成。我们假设这些数据是由某个随机过程生成的,该过程涉及一个不可观测的连续随机变量 z z z。这个过程包含两个步骤:(1)从某个先验分布 p θ ∗ ( z ) p{\theta^{*}}(z) pθ∗(z)中生成一个取值 z ( i ) z^{(i)} z(i);(2)从某个条件分布 p θ ∗ ( x ∣ z ) p_{\theta^{*}}(x|z) pθ∗(x∣z)中生成一个取值 x ( i ) x^{(i)} x(i)。我们假设先验 p θ ∗ ( z ) p_{\theta^{*}}(z) pθ∗(z)与似然 p θ ∗ ( x ∣ z ) p_{\theta^{*}}(x|z) pθ∗(x∣z)都来自于某些参数化的分布族 p θ ( z ) p_{\theta}(z) pθ(z)和 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z),并且它们的概率密度函数在几乎所有关于参数 θ \theta θ和 z z z的点上都是可微的。不幸的是,该生成过程的很多部分我们无法观测:真实的参数 θ ∗ \theta^* θ∗以及潜变量 z ( i ) z^{(i)} z(i)的取值对我们来说都是未知的。
非常重要的是,我们不对边缘分布或后验分布作常见的简化假设 。相反,我们在此关注的是一个通用算法,即使在以下情况中也能高效运行:
-
不可解性 :即边缘似然 p θ ( x ) = ∫ p θ ( z ) p θ ( x ∣ z ) d z p_{\theta}(x)=\int p_{\theta}(z)p_{\theta}(x|z)dz pθ(x)=∫pθ(z)pθ(x∣z)dz 的积分是不可解的(因此我们无法计算或对边缘似然进行求导);真实的后验密度 p θ ( z ∣ x ) = p θ ( x ∣ z ) p θ ( z ) p θ ( x ) p_{\theta}(z|x)=\frac{p_{\theta}(x|z)p_{\theta}(z)}{p_{\theta}(x)} pθ(z∣x)=pθ(x)pθ(x∣z)pθ(z)也是不可解的(因此无法使用EM算法);而任何合理的平均场变分贝叶斯算法中所需的积分也同样不可解。这类不可解性在实际中非常常见,特别是当似然函数 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z)稍微复杂一些时,例如包含非线性隐藏层的神经网络。
-
数据集规模巨大:我们拥有的数据过多,以致于批量优化的代价过高;我们希望能够通过小批量甚至单个数据点来更新参数。基于采样的解决方案,例如蒙特卡洛EM,通常会太慢,因为它通常需要对每个数据点进行代价高昂的采样循环。
我们关注并提出了解决上述场景中三个相关问题的方法:
-
参数 θ \theta θ的高效近似最大似然(ML)或最大后验(MAP)估计。参数本身可能就是我们关注的对象,例如在分析某个自然过程时。它们还可以帮助我们模拟隐藏的随机过程,并生成与真实数据相似的人工数据。
-
在给定观测值 x x x和一组参数 θ \theta θ的条件下,对潜变量 z z z进行高效的近似后验推断。这在编码或数据表示任务中非常有用。
-
对变量 x x x进行高效的近似边缘推断 。这使我们能够执行各种推理任务,其中需要对 x x x施加先验。在计算机视觉中的常见应用包括图像去噪、修复和超分辨率等。
为了解决上述问题,我们引入一个识别模型 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x),它是对不可解的真实后验 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)的近似。需要注意的是,与平均场变分推断中的近似后验不同, q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x)不一定是因子化的,并且其参数 ϕ \phi ϕ不是通过某种封闭形式的期望计算得出的。相反,我们将引入一种方法,用于联合学习识别模型参数 ϕ \phi ϕ与生成模型参数 θ \theta θ。
从编码理论的角度来看,未观测变量 z z z可以被解释为一种潜在表示或"编码"。因此,在本文中我们也将识别模型 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x)称为概率编码器 ,因为它在给定一个数据点 x x x的情况下,会输出一个关于潜在编码 z z z的分布(例如高斯分布),从中可以生成该数据点 x x x。类似地,我们将 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z)称为概率解码器 ,因为在给定一个编码 z z z的情况下,它会输出关于对应 x x x值的一个分布。
2.2 变分下界
边缘似然由每个数据点的边缘似然之和构成:
log p θ ( x ( 1 ) , ⋯ , x ( N ) ) = ∑ i = 1 N log p θ ( x ( i ) ) , \log p_\theta(x^{(1)}, \cdots, x^{(N)}) = \sum_{i=1}^N \log p_\theta(x^{(i)}), logpθ(x(1),⋯,x(N))=i=1∑Nlogpθ(x(i)),
其中每一项都可以重写为:
log p θ ( x ( i ) ) = D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ∣ x ( i ) ) ) + L ( θ , ϕ ; x ( i ) ) (1) \log p_\theta(x^{(i)}) = D_{KL}(q_\phi(z|x^{(i)})||p_\theta(z|x^{(i)})) + \mathcal{L}(\theta, \phi; x^{(i)}) \tag{1} logpθ(x(i))=DKL(qϕ(z∣x(i))∣∣pθ(z∣x(i)))+L(θ,ϕ;x(i))(1)
右侧的第一个项是近似后验与真实后验之间的KL散度。由于该KL散度非负,右侧的第二项 L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta, \phi; x^{(i)}) L(θ,ϕ;x(i))被称为数据点 i i i的边缘似然的(变分)下界,并可以写作:
log p θ ( x ( i ) ) ≥ L ( θ , ϕ ; x ( i ) ) = E q ϕ ( z ∣ x ) − log q ϕ ( z ∣ x ) + log p θ ( x , z ) (2) \log p_\theta(x^{(i)}) \geq \mathcal{L}(\theta, \phi; x^{(i)}) = \mathbb{E}{q\phi(z|x)}-\\log q_\\phi(z\|x) + \\log p_\\theta(x, z) \tag{2} logpθ(x(i))≥L(θ,ϕ;x(i))=Eqϕ(z∣x)−logqϕ(z∣x)+logpθ(x,z)(2)
该下界也可以重写为:
L ( θ , ϕ ; x ( i ) ) = − D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ) ) + E q ϕ ( z ∣ x ( i ) ) log p θ ( x ( i ) ∣ z ) (3) \mathcal{L}(\theta, \phi; x^{(i)}) = -D_{KL}(q_\phi(z|x^{(i)})||p_\theta(z)) + \mathbb{E}{q\phi(z|x^{(i)})}\\log p_\\theta(x\^{(i)}\|z) \tag{3} L(θ,ϕ;x(i))=−DKL(qϕ(z∣x(i))∣∣pθ(z))+Eqϕ(z∣x(i))logpθ(x(i)∣z)(3)
我们希望对变分下界 L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta, \phi; x^{(i)}) L(θ,ϕ;x(i))分别关于变分参数 ϕ \phi ϕ和生成模型参数 θ \theta θ求导并进行优化。然而,这个下界关于 ϕ \phi ϕ的梯度存在一些问题。对于这类问题,通常的(朴素)蒙特卡洛梯度估计器是:
∇ ϕ E q ϕ ( z ) f ( z ) = E q ϕ ( z ) f ( z ) ∇ q ϕ ( z ) log q ϕ ( z ) ≈ 1 L ∑ l = 1 L f ( z ) ∇ q ϕ ( z ( l ) ) log q ϕ ( z ( l ) ) \nabla_\phi \mathbb{E}{q\phi(z)}f(z) = \mathbb{E}{q\phi(z)}\left f(z)\\nabla_{q_\\phi(z)}\\log q_\\phi(z) \\right \approx \frac{1}{L} \sum_{l=1}^L f(z)\nabla_{q_\phi(z^{(l)})}\log q_\phi(z^{(l)}) ∇ϕEqϕ(z)f(z)=Eqϕ(z)f(z)∇qϕ(z)logqϕ(z)≈L1l=1∑Lf(z)∇qϕ(z(l))logqϕ(z(l))
其中 z ( l ) ∼ q ϕ ( z ∣ x ( i ) ) z^{(l)}\sim q_\phi(z|x^{(i)}) z(l)∼qϕ(z∣x(i))。然而,这种梯度估计器的方差非常高(参见如BJP12),因此在我们的目的中并不实用。
变分下界(ELBO)的详细推导
1. 边缘似然的分解
我们从单数据点 x ( i ) x^{(i)} x(i) 的边缘似然 log p θ ( x ( i ) ) \log p_\theta(x^{(i)}) logpθ(x(i)) 出发,通过引入变分分布 q ϕ ( z ∣ x ( i ) ) q_\phi(z|x^{(i)}) qϕ(z∣x(i)) 进行分解:
log p θ ( x ( i ) ) = D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ∣ x ( i ) ) ) + L ( θ , ϕ ; x ( i ) ) (1) \log p_\theta(x^{(i)}) = D_{KL}\left(q_\phi(z|x^{(i)}) \| p_\theta(z|x^{(i)})\right) + \mathcal{L}(\theta, \phi; x^{(i)}) \tag{1} logpθ(x(i))=DKL(qϕ(z∣x(i))∥pθ(z∣x(i)))+L(θ,ϕ;x(i))(1)
推导步骤
- 引入变分分布 :对任意分布 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),有: log p θ ( x ) = log ∫ p θ ( x , z ) d z \log p_\theta(x) = \log \int p_\theta(x,z) dz logpθ(x)=log∫pθ(x,z)dz
- 分子分母技巧 : log p θ ( x ) = log ∫ q ϕ ( z ∣ x ) p θ ( x , z ) q ϕ ( z ∣ x ) d z \log p_\theta(x) = \log \int q_\phi(z|x) \frac{p_\theta(x,z)}{q_\phi(z|x)} dz logpθ(x)=log∫qϕ(z∣x)qϕ(z∣x)pθ(x,z)dz
- 期望的积分形式 E q ϕ ( z ∣ x ) f ( z ) = ∫ f ( z ) q ϕ ( z ∣ x ) d z \mathbb{E}{q\phi(z|x)} f(z) = \int f(z) q_\phi(z|x) dz Eqϕ(z∣x)f(z)=∫f(z)qϕ(z∣x)dz
- 应用琴生不等式 (Jensen's Inequality) f ( x ) f(x) f(x)需要为凹函数: log E q ϕ ( z ∣ x ) p θ ( x , z ) q ϕ ( z ∣ x ) ≥ E q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) \log \mathbb{E}{q\phi(z|x)} \left\\frac{p_\\theta(x,z)}{q_\\phi(z\|x)}\\right \geq \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(x,z)}{q_\\phi(z\|x)}\\right logEqϕ(z∣x)qϕ(z∣x)pθ(x,z)≥Eqϕ(z∣x)logqϕ(z∣x)pθ(x,z) 因此: log p θ ( x ) ≥ E q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) ≜ L ( θ , ϕ ; x ) \log p_\theta(x) \geq \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(x,z)}{q_\\phi(z\|x)}\\right \triangleq \mathcal{L}(\theta, \phi; x) logpθ(x)≥Eqϕ(z∣x)logqϕ(z∣x)pθ(x,z)≜L(θ,ϕ;x)
≜ \triangleq ≜: "被定义为"的意思(公式2)。- 定义KL散度 : D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) = E q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p θ ( z ∣ x ) D_{KL}\left(q_\phi(z|x) \| p_\theta(z|x)\right) = \mathbb{E}{q\phi(z|x)} \left\\log \\frac{q_\\phi(z\|x)}{p_\\theta(z\|x)}\\right DKL(qϕ(z∣x)∥pθ(z∣x))=Eqϕ(z∣x)logpθ(z∣x)qϕ(z∣x)
- 结合贝叶斯定理 :
6.1 贝叶斯定理的表达式 :
p θ ( z ∣ x ) = p θ ( x , z ) p θ ( x ) p_\theta(z|x) = \frac{p_\theta(x,z)}{p_\theta(x)} pθ(z∣x)=pθ(x)pθ(x,z)
即联合分布 p θ ( x , z ) p_\theta(x,z) pθ(x,z) 可写为:
p θ ( x , z ) = p θ ( z ∣ x ) ⋅ p θ ( x ) p_\theta(x,z) = p_\theta(z|x) \cdot p_\theta(x) pθ(x,z)=pθ(z∣x)⋅pθ(x)
6.2. 代入变分下界 :
变分下界的定义为:
L ( θ , ϕ ; x ) = E q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) \mathcal{L}(\theta, \phi; x) = \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(x,z)}{q_\\phi(z\|x)}\\right L(θ,ϕ;x)=Eqϕ(z∣x)logqϕ(z∣x)pθ(x,z)
将联合分布 p θ ( x , z ) p_\theta(x,z) pθ(x,z) 替换为贝叶斯定理的形式:
L ( θ , ϕ ; x ) = E q ϕ ( z ∣ x ) log p θ ( z ∣ x ) ⋅ p θ ( x ) q ϕ ( z ∣ x ) \mathcal{L}(\theta, \phi; x) = \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(z\|x) \\cdot p_\\theta(x)}{q_\\phi(z\|x)}\\right L(θ,ϕ;x)=Eqϕ(z∣x)logqϕ(z∣x)pθ(z∣x)⋅pθ(x)
6.3. 拆分对数项 : L ( θ , ϕ ; x ) = E q ϕ ( z ∣ x ) log p θ ( x ) + log p θ ( z ∣ x ) q ϕ ( z ∣ x ) \mathcal{L}(\theta, \phi; x) = \mathbb{E}{q\phi(z|x)} \left\\log p_\\theta(x) + \\log \\frac{p_\\theta(z\|x)}{q_\\phi(z\|x)}\\right L(θ,ϕ;x)=Eqϕ(z∣x)logpθ(x)+logqϕ(z∣x)pθ(z∣x) 由于 log p θ ( x ) \log p_\theta(x) logpθ(x) 不依赖 z z z,期望结果为: L ( θ , ϕ ; x ) = log p θ ( x ) + E q ϕ ( z ∣ x ) log p θ ( z ∣ x ) q ϕ ( z ∣ x ) \mathcal{L}(\theta, \phi; x) = \log p_\theta(x) + \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(z\|x)}{q_\\phi(z\|x)}\\right L(θ,ϕ;x)=logpθ(x)+Eqϕ(z∣x)logqϕ(z∣x)pθ(z∣x)
6.4. 引入KL散度 : E q ϕ ( z ∣ x ) log p θ ( z ∣ x ) q ϕ ( z ∣ x ) = − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(z\|x)}{q_\\phi(z\|x)}\\right = -D_{KL}\left(q_\phi(z|x) \| p_\theta(z|x)\right) Eqϕ(z∣x)logqϕ(z∣x)pθ(z∣x)=−DKL(qϕ(z∣x)∥pθ(z∣x)) 因此: L ( θ , ϕ ; x ) = log p θ ( x ) − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) \mathcal{L}(\theta, \phi; x) = \log p_\theta(x) - D_{KL}\left(q_\phi(z|x) \| p_\theta(z|x)\right) L(θ,ϕ;x)=logpθ(x)−DKL(qϕ(z∣x)∥pθ(z∣x)) 移项即得: log p θ ( x ) = D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) + L ( θ , ϕ ; x ) \log p_\theta(x) = D_{KL}\left(q_\phi(z|x) \| p_\theta(z|x)\right) + \mathcal{L}(\theta, \phi; x) logpθ(x)=DKL(qϕ(z∣x)∥pθ(z∣x))+L(θ,ϕ;x)
log p θ ( x ) = E q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) + D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) \log p_\theta(x) = \mathbb{E}{q\phi(z|x)} \left\\log \\frac{p_\\theta(x,z)}{q_\\phi(z\|x)}\\right + D_{KL}\left(q_\phi(z|x) \| p_\theta(z|x)\right) logpθ(x)=Eqϕ(z∣x)logqϕ(z∣x)pθ(x,z)+DKL(qϕ(z∣x)∥pθ(z∣x)) 即公式 (1)。
核心公式 :
log p ( x ) = D K L ( q ∥ p ) ⏟ ≥ 0 + L ⏟ 可优化项 \log p(x) = \underbrace{D_{KL}(q \| p)}{\geq 0} + \underbrace{\mathcal{L}}{\text{可优化项}} logp(x)=≥0 DKL(q∥p)+可优化项 L
- KL散度非负性 :保证 L \mathcal{L} L 是 log p ( x ) \log p(x) logp(x) 的下界。
- 变分推断的目标 :最大化 L \mathcal{L} L,间接最小化 D K L D_{KL} DKL。
2. 变分下界 L \mathcal{L} L 的两种形式形式1:原始定义(公式2) L ( θ , ϕ ; x ( i ) ) = E q ϕ ( z ∣ x ) − log q ϕ ( z ∣ x ) + log p θ ( x , z ) \mathcal{L}(\theta, \phi; x^{(i)}) = \mathbb{E}{q\phi(z|x)} \left-\\log q_\\phi(z\|x) + \\log p_\\theta(x,z)\\right L(θ,ϕ;x(i))=Eqϕ(z∣x)−logqϕ(z∣x)+logpθ(x,z)
形式2:分解为KL散度与重构项(公式3) L ( θ , ϕ ; x ( i ) ) = − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) + E q ϕ ( z ∣ x ( i ) ) log p θ ( x ( i ) ∣ z ) \mathcal{L}(\theta, \phi; x^{(i)}) = -D_{KL}\left(q_\phi(z|x^{(i)}) \| p_\theta(z)\right) + \mathbb{E}{q\phi(z|x^{(i)})} \left\\log p_\\theta(x\^{(i)}\|z)\\right L(θ,ϕ;x(i))=−DKL(qϕ(z∣x(i))∥pθ(z))+Eqϕ(z∣x(i))logpθ(x(i)∣z)
推导步骤
- 展开联合分布 :将 p θ ( x , z ) p_\theta(x,z) pθ(x,z) 分解为似然和先验: log p θ ( x , z ) = log p θ ( x ∣ z ) + log p θ ( z ) \log p_\theta(x,z) = \log p_\theta(x|z) + \log p_\theta(z) logpθ(x,z)=logpθ(x∣z)+logpθ(z)
- 代入形式1 : L = E q ϕ ( z ∣ x ) − log q ϕ ( z ∣ x ) + log p θ ( x ∣ z ) + log p θ ( z ) \mathcal{L} = \mathbb{E}{q\phi(z|x)} \left-\\log q_\\phi(z\|x) + \\log p_\\theta(x\|z) + \\log p_\\theta(z)\\right L=Eqϕ(z∣x)−logqϕ(z∣x)+logpθ(x∣z)+logpθ(z)
- 重组项 : L = E q ϕ ( z ∣ x ) log p θ ( x ∣ z ) + E q ϕ ( z ∣ x ) log p θ ( z ) − log q ϕ ( z ∣ x ) \mathcal{L} = \mathbb{E}{q\phi(z|x)} \left\\log p_\\theta(x\|z)\\right + \mathbb{E}{q\phi(z|x)} \left\\log p_\\theta(z) - \\log q_\\phi(z\|x)\\right L=Eqϕ(z∣x)logpθ(x∣z)+Eqϕ(z∣x)logpθ(z)−logqϕ(z∣x)
- 定义KL散度 : E q ϕ ( z ∣ x ) log p θ ( z ) − log q ϕ ( z ∣ x ) = − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ) ) \mathbb{E}{q\phi(z|x)} \left\\log p_\\theta(z) - \\log q_\\phi(z\|x)\\right = -D_{KL}\left(q_\phi(z|x) \| p_\theta(z)\right) Eqϕ(z∣x)logpθ(z)−logqϕ(z∣x)=−DKL(qϕ(z∣x)∥pθ(z)) 最终得到公式 (3)。
3. 梯度估计器的高方差问题目标:计算 ∇ ϕ L \nabla_\phi \mathcal{L} ∇ϕL 假设 L \mathcal{L} L 包含期望项:
L = E q ϕ ( z ∣ x ) f ( z ) \mathcal{L} = \mathbb{E}{q\phi(z|x)} \leftf(z)\\right L=Eqϕ(z∣x)f(z) 我们需要计算 ∇ ϕ E q ϕ ( z ∣ x ) f ( z ) \nabla_\phi \mathbb{E}{q\phi(z|x)} f(z) ∇ϕEqϕ(z∣x)f(z)。写出期望的积分:
E q ϕ ( z ∣ x ) f ( z ) = ∫ f ( z ) q ϕ ( z ∣ x ) d z \mathbb{E}{q\phi(z|x)} f(z) = \int f(z) q_\phi(z|x) dz Eqϕ(z∣x)f(z)=∫f(z)qϕ(z∣x)dz步骤1:对 ϕ \phi ϕ 求导 ∇ ϕ E q ϕ ( z ∣ x ) f ( z ) = ∇ ϕ ∫ f ( z ) q ϕ ( z ∣ x ) d z \nabla_\phi \mathbb{E}{q\phi(z|x)} f(z) = \nabla_\phi \int f(z) q_\phi(z|x) dz ∇ϕEqϕ(z∣x)f(z)=∇ϕ∫f(z)qϕ(z∣x)dz
步骤2:在温和条件下(如积分和导数均收敛),可以交换: ∇ ϕ ∫ f ( z ) q ϕ ( z ∣ x ) d z = ∫ f ( z ) ∇ ϕ q ϕ ( z ∣ x ) d z \nabla_\phi \int f(z) q_\phi(z|x) dz = \int f(z) \nabla_\phi q_\phi(z|x) dz ∇ϕ∫f(z)qϕ(z∣x)dz=∫f(z)∇ϕqϕ(z∣x)dz
步骤3:对数导数技巧 :对任何概率密度 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),有:
∇ ϕ q ϕ ( z ∣ x ) = q ϕ ( z ∣ x ) ⋅ ∇ ϕ log q ϕ ( z ∣ x ) \nabla_\phi q_\phi(z|x) = q_\phi(z|x) \cdot \nabla_\phi \log q_\phi(z|x) ∇ϕqϕ(z∣x)=qϕ(z∣x)⋅∇ϕlogqϕ(z∣x)步骤4:将步骤3的结果代入步骤2的积分:
∫ f ( z ) ∇ ϕ q ϕ ( z ∣ x ) d z = ∫ f ( z ) ⋅ q ϕ ( z ∣ x ) ⋅ ∇ ϕ log q ϕ ( z ∣ x ) d z \int f(z) \nabla_\phi q_\phi(z|x) dz = \int f(z) \cdot q_\phi(z|x) \cdot \nabla_\phi \log q_\phi(z|x) dz ∫f(z)∇ϕqϕ(z∣x)dz=∫f(z)⋅qϕ(z∣x)⋅∇ϕlogqϕ(z∣x)dz这等价于:
∫ f ( z ) ⋅ q ϕ ( z ∣ x ) ⋅ ∇ ϕ log q ϕ ( z ∣ x ) d z = ∫ q ϕ ( z ∣ x ) ⋅ f ( z ) ⋅ ∇ ϕ log q ϕ ( z ∣ x ) d z = E q ϕ ( z ∣ x ) f ( z ) ∇ ϕ log q ϕ ( z ∣ x ) \int f(z) \cdot q_\phi(z|x) \cdot \nabla_\phi \log q_\phi(z|x) dz = \int q_\phi(z|x) \cdot f(z) \cdot \nabla_\phi \log q_\phi(z|x) dz = \mathbb{E}{q\phi(z|x)} \left f(z) \\nabla_\\phi \\log q_\\phi(z\|x) \\right ∫f(z)⋅qϕ(z∣x)⋅∇ϕlogqϕ(z∣x)dz=∫qϕ(z∣x)⋅f(z)⋅∇ϕlogqϕ(z∣x)dz=Eqϕ(z∣x)f(z)∇ϕlogqϕ(z∣x)因此朴素蒙特卡洛梯度估计器 :
∇ ϕ E q ϕ ( z ∣ x ) f ( z ) = E q ϕ ( z ∣ x ) f ( z ) ∇ ϕ log q ϕ ( z ∣ x ) \nabla_\phi \mathbb{E}{q\phi(z|x)} f(z) = \mathbb{E}{q\phi(z|x)} \left f(z) \\nabla_\\phi \\log q_\\phi(z\|x) \\right ∇ϕEqϕ(z∣x)f(z)=Eqϕ(z∣x)f(z)∇ϕlogqϕ(z∣x)这是基于评分函数估计器(Score Function Estimator)。
蒙特卡洛近似 : 采样 z ( l ) ∼ q ϕ ( z ∣ x ) z^{(l)} \sim q_\phi(z|x) z(l)∼qϕ(z∣x),估计梯度: ∇ ϕ L ≈ 1 L ∑ l = 1 L f ( z ( l ) ) ∇ ϕ log q ϕ ( z ( l ) ∣ x ) \nabla_\phi \mathcal{L} \approx \frac{1}{L} \sum_{l=1}^L f(z^{(l)}) \nabla_\phi \log q_\phi(z^{(l)}|x) ∇ϕL≈L1l=1∑Lf(z(l))∇ϕlogqϕ(z(l)∣x)
高方差的原因
- 评分函数的性质 : ∇ ϕ log q ϕ ( z ∣ x ) \nabla_\phi \log q_\phi(z|x) ∇ϕlogqϕ(z∣x) 的幅度与概率密度成反比。当 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 接近0时,梯度会剧烈震荡。
数学原理
设变分分布为 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),其评分函数(Score Function)定义为对数概率密度的梯度: ∇ ϕ log q ϕ ( z ∣ x ) \nabla_\phi \log q_\phi(z|x) ∇ϕlogqϕ(z∣x) 对任意分布,以下等式成立:
∇ ϕ q ϕ ( z ∣ x ) = q ϕ ( z ∣ x ) ⋅ ∇ ϕ log q ϕ ( z ∣ x ) \nabla_\phi q_\phi(z|x) = q_\phi(z|x) \cdot \nabla_\phi \log q_\phi(z|x) ∇ϕqϕ(z∣x)=qϕ(z∣x)⋅∇ϕlogqϕ(z∣x)因此: ∇ ϕ log q ϕ ( z ∣ x ) = ∇ ϕ q ϕ ( z ∣ x ) q ϕ ( z ∣ x ) \nabla_\phi \log q_\phi(z|x) = \frac{\nabla_\phi q_\phi(z|x)}{q_\phi(z|x)} ∇ϕlogqϕ(z∣x)=qϕ(z∣x)∇ϕqϕ(z∣x) 显然,当 q ϕ ( z ∣ x ) → 0 q_\phi(z|x) \to 0 qϕ(z∣x)→0 时,分母趋近于零,梯度幅度 ∥ ∇ ϕ log q ϕ ( z ∣ x ) ∥ \|\nabla_\phi \log q_\phi(z|x)\| ∥∇ϕlogqϕ(z∣x)∥ 会急剧增大。
直观解释
以高斯分布 q ϕ ( z ∣ x ) = N ( z ; μ , σ 2 ) q_\phi(z|x) = \mathcal{N}(z; \mu, \sigma^2) qϕ(z∣x)=N(z;μ,σ2) 为例:
- 概率密度函数 : q ( z ) = 1 2 π σ e − ( z − μ ) 2 2 σ 2 q(z) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(z-\mu)^2}{2\sigma^2}} q(z)=2π σ1e−2σ2(z−μ)2
- 评分函数 (对 μ \mu μ 求导): ∇ μ log q ( z ) = z − μ σ 2 \nabla_\mu \log q(z) = \frac{z-\mu}{\sigma^2} ∇μlogq(z)=σ2z−μ
关键观察:
- 当 z z z 远离均值 μ \mu μ(即处于分布尾部)时, q ( z ) q(z) q(z) 的值很小(概率密度低),但评分函数的值 z − μ σ 2 \frac{z-\mu}{\sigma^2} σ2z−μ 会很大。
- 极端情况 :若 z z z 距离 μ \mu μ 非常远(如 z = μ + 10 σ z = \mu + 10\sigma z=μ+10σ),则 q ( z ) ≈ 0 q(z) \approx 0 q(z)≈0,但评分函数值为 10 / σ 10/\sigma 10/σ。此时梯度幅度极大,导致采样估计的剧烈震荡。
- 乘积项的方差 : f ( z ) ∇ ϕ log q ϕ ( z ∣ x ) f(z) \nabla_\phi \log q_\phi(z|x) f(z)∇ϕlogqϕ(z∣x) 的乘积会放大采样噪声。
数学原理
梯度估计器的形式为: ∇ ϕ L ≈ 1 L ∑ l = 1 L f ( z ( l ) ) ∇ ϕ log q ϕ ( z ( l ) ∣ x ) \nabla_\phi \mathcal{L} \approx \frac{1}{L} \sum_{l=1}^L f(z^{(l)}) \nabla_\phi \log q_\phi(z^{(l)}|x) ∇ϕL≈L1l=1∑Lf(z(l))∇ϕlogqϕ(z(l)∣x) 其中 z ( l ) ∼ q ϕ ( z ∣ x ) z^{(l)} \sim q_\phi(z|x) z(l)∼qϕ(z∣x)。
方差来源:
- f ( z ) f(z) f(z) 的波动 :若 f ( z ) f(z) f(z) 在不同样本 z z z 上差异较大(如某些区域 f ( z ) f(z) f(z) 值很大),会直接放大梯度的波动。
- 评分函数的波动 :如前述,评分函数在低概率区域会产生极大值。
两者的乘积会导致方差叠加,进一步放大噪声。
- 直观案例 :
- 假设 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 是高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2),则:
∇ μ log q ϕ ( z ∣ x ) = z − μ σ 2 \nabla_\mu \log q_\phi(z|x) = \frac{z-\mu}{\sigma^2} ∇μlogqϕ(z∣x)=σ2z−μ- 当 σ → 0 \sigma \to 0 σ→0 时,梯度项 ( z − μ ) / σ 2 (z-\mu)/\sigma^2 (z−μ)/σ2 的方差趋于无穷大。
总结
- 变分下界的推导 :
- 通过引入变分分布和KL散度,将边缘似然分解为下界和KL项。
- 下界可进一步分解为负KL散度和重构期望。
- 梯度估计问题 :
- 评分函数估计器理论上可行,但因依赖概率密度的倒数,导致高方差。
- 解决方案:使用重参数化技巧(Reparameterization Trick),将随机性转移到外部变量,降低方差。
2.3 SGVB估计器与AEVB算法
在本节中,我们引入一个下界及其关于参数导数的实用估计器。我们假设近似后验为 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)的形式,但请注意,该技术同样适用于 q ϕ ( z ) q_\phi(z) qϕ(z)的情形,即我们不对 x x x进行条件化的情形。关于对参数进行后验推断的完全变分贝叶斯方法已在附录中给出。
在某些温和条件下(见第2.4节),对于选定的近似后验 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),我们可以使用某个可微变换 g ϕ ( ϵ , x ) g_\phi(\epsilon, x) gϕ(ϵ,x)对随机变量 z ~ ∼ q ϕ ( z ∣ x ) \tilde{z}\sim q_\phi(z|x) z~∼qϕ(z∣x)进行重参数化 ,其中 ϵ \epsilon ϵ是一个(辅助的)噪声变量,满足:
z ~ = g ϕ ( ϵ , x ) , ϵ ∼ p ( ϵ ) (4) \tilde{z} = g_\phi(\epsilon, x),\quad \epsilon \sim p(\epsilon) \tag{4} z~=gϕ(ϵ,x),ϵ∼p(ϵ)(4)
关于如何选择合适的分布 p ( ϵ ) p(\epsilon) p(ϵ)和函数 g ϕ ( ϵ , x ) g_\phi(\epsilon, x) gϕ(ϵ,x)的通用策略,见第2.4节。我们现在可以如下方式对关于 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)的某函数 f ( z ) f(z) f(z)的期望值进行蒙特卡洛估计:
E q ϕ ( z ∣ x ( i ) ) f ( z ) = E p ( ϵ ) f ( g ϕ ( ϵ , x ( i ) ) ) ≈ 1 L ∑ l = 1 L f ( g ϕ ( ϵ ( l ) , x ( i ) ) ) , ϵ ( l ) ∼ p ( ϵ ) (5) \mathbb{E}{q\phi(z|x^{(i)})}f(z) = \mathbb{E}{p(\epsilon)}f(g_\\phi(\\epsilon, x\^{(i)})) \approx \frac{1}{L} \sum{l=1}^L f(g_\phi(\epsilon^{(l)}, x^{(i)})),\quad \epsilon^{(l)} \sim p(\epsilon) \tag{5} Eqϕ(z∣x(i))f(z)=Ep(ϵ)f(gϕ(ϵ,x(i)))≈L1l=1∑Lf(gϕ(ϵ(l),x(i))),ϵ(l)∼p(ϵ)(5)
我们将此技术应用于变分下界(公式(2)),从而得到了我们通用的随机梯度变分贝叶斯(Stochastic Gradient Variational Bayes, SGVB)估计器 L ~ A ( θ , ϕ ; x ( i ) ) \tilde{\mathcal{L}}^A(\theta, \phi; x^{(i)}) L~A(θ,ϕ;x(i)),它近似于 L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta, \phi; x^{(i)}) L(θ,ϕ;x(i)):
L ~ A ( θ , ϕ ; x ( i ) ) = 1 L ∑ l = 1 L log p θ ( x ( i ) , z ( i , l ) ) − log q ϕ ( z ( i , l ) ∣ x ( i ) ) (6) \tilde{\mathcal{L}}^A(\theta, \phi; x^{(i)}) = \frac{1}{L} \sum_{l=1}^L \left\\log p_\\theta(x\^{(i)}, z\^{(i,l)}) - \\log q_\\phi(z\^{(i,l)}\|x\^{(i)})\\right \tag{6} L~A(θ,ϕ;x(i))=L1l=1∑Llogpθ(x(i),z(i,l))−logqϕ(z(i,l)∣x(i))(6)
其中 z ( i , l ) = g ϕ ( ϵ ( i , l ) , x ( i ) ) z^{(i,l)} = g_\phi(\epsilon^{(i,l)}, x^{(i)}) z(i,l)=gϕ(ϵ(i,l),x(i)),且 ϵ ( l ) ∼ p ( ϵ ) \epsilon^{(l)} \sim p(\epsilon) ϵ(l)∼p(ϵ)。
通常,公式(3)中的KL散度项 D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ) ) D_{KL}(q_\phi(z|x^{(i)})||p_\theta(z)) DKL(qϕ(z∣x(i))∣∣pθ(z))可以解析地计算(见附录B),因此仅有期望重构误差 E q ϕ ( z ∣ x ( i ) ) log p θ ( x ( i ) ∣ z ) \mathbb{E}{q\phi(z|x^{(i)})}\\log p_\\theta(x\^{(i)}\|z) Eqϕ(z∣x(i))logpθ(x(i)∣z)需要通过采样进行估计。此时,KL散度项可以被解释为对 ϕ \phi ϕ的正则化,鼓励近似后验靠近先验 p θ ( z ) p_\theta(z) pθ(z)。这就得到了SGVB估计器的第二个版本 L ~ B ( θ , ϕ ; x ( i ) ) ≈ L ( θ , ϕ ; x ( i ) ) \tilde{\mathcal{L}}^B(\theta, \phi; x^{(i)})\approx\mathcal{L}(\theta, \phi; x^{(i)}) L~B(θ,ϕ;x(i))≈L(θ,ϕ;x(i)),它对应于公式(3),并且通常比通用估计器具有更小的方差:
如果我们回到公式(3) 的形式: L ( θ , ϕ ; x ) = − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ) ) ⏟ 常能解析 + E q ϕ ( z ∣ x ) log p θ ( x ∣ z ) ⏟ 需要采样估计 , \mathcal{L}(\theta, \phi; x) = -\underbrace{D_{KL}\big(q_\phi(z|x)\|p_\theta(z)\big)}{\text{常能解析}} + \underbrace{\mathbb{E}{q_\phi(z|x)}\big\\log p_\\theta(x\|z)\\big}_{\text{需要采样估计}}, L(θ,ϕ;x)=−常能解析 DKL(qϕ(z∣x)∥pθ(z))+需要采样估计 Eqϕ(z∣x)logpθ(x∣z),
第一项 KL 散度在许多情况下(例如高斯分布)是可以解析地计算 的;只有第二项 E q ϕ ( z ∣ x ) log p θ ( x ∣ z ) \mathbb{E}{q\phi(z|x)}\\log p_\\theta(x\|z) Eqϕ(z∣x)logpθ(x∣z) 需要用采样来近似。
L ~ B ( θ , ϕ ; x ( i ) ) = − D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ) ) + 1 L ∑ l = 1 L ( log p θ ( x ( i ) ∣ z ( i , l ) ) ) (7) \tilde{\mathcal{L}}^B(\theta, \phi; x^{(i)}) = -D_{KL}(q_\phi(z|x^{(i)})||p_\theta(z)) + \frac{1}{L} \sum_{l=1}^L (\log p_\theta(x^{(i)}|z^{(i,l)})) \tag{7} L~B(θ,ϕ;x(i))=−DKL(qϕ(z∣x(i))∣∣pθ(z))+L1l=1∑L(logpθ(x(i)∣z(i,l)))(7)
其中 z ( i , l ) = g ϕ ( ϵ ( i , l ) , x ( i ) ) z^{(i,l)} = g_\phi(\epsilon^{(i,l)}, x^{(i)}) z(i,l)=gϕ(ϵ(i,l),x(i)),且 ϵ ( l ) ∼ p ( ϵ ) \epsilon^{(l)} \sim p(\epsilon) ϵ(l)∼p(ϵ)。
- 第一项 D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ) ) D_{KL}(q_\phi(z|x)\|p_\theta(z)) DKL(qϕ(z∣x)∥pθ(z)) 直接计算;
- 第二项 log p θ ( x ∣ z ) \log p_\theta(x|z) logpθ(x∣z) 用采样近似 (因为要对 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 取期望)。
这样做的方差通常更低,因为你不再需要用采样去近似那一坨 KL 散度。
对于一个包含 N N N个数据点的数据集 X X X,我们可以基于小批量构造整个数据集边缘似然下界的估计器:
L ( θ , ϕ ; X ) ≈ L ~ M ( θ , ϕ ; X M ) = N M ∑ i = 1 M L ~ ( θ , ϕ ; x ( i ) ) (8) \mathcal{L}(\theta, \phi; X) \approx \tilde{\mathcal{L}}^M(\theta, \phi; X^M) = \frac{N}{M} \sum_{i=1}^M \tilde{\mathcal{L}}(\theta, \phi; x^{(i)}) \tag{8} L(θ,ϕ;X)≈L~M(θ,ϕ;XM)=MNi=1∑ML~(θ,ϕ;x(i))(8)
其中,小批量 X M = { x ( i ) } i = 1 M X^M = \{x^{(i)}\}_{i=1}^M XM={x(i)}i=1M是从整个包含 N N N个数据点的数据集 X X X中随机抽取的 M M M个数据点。在我们的实验中发现,如果小批量大小 M M M足够大(例如 M = 100 M=100 M=100),则每个数据点的采样数 L L L可以设置为1。
可以对 ∇ θ , ϕ L ~ ( θ ; X M ) \nabla_{\theta,\phi}\tilde{\mathcal{L}}(\theta; X^M) ∇θ,ϕL~(θ;XM)关于 θ \theta θ和 ϕ \phi ϕ求导,得到的梯度可结合随机优化方法使用,例如SGD或Adagrad DHS10。计算随机梯度的基本方法见算法1。

初始化参数
- 先随机初始化 θ \theta θ 和 ϕ \phi ϕ。
- θ \theta θ 通常对应解码器 网络的参数, ϕ \phi ϕ 对应编码器网络的参数。
循环训练(Repeat)
从完整数据集中随机抽取一个小批量(minibatch)
- 设数据集大小为 N N N,每次抽取 M M M 个数据点(例如 M = 100 M=100 M=100)。
- 记这个小批量为 X M = { x ( 1 ) , x ( 2 ) , ... , x ( M ) } X^M = \{x^{(1)}, x^{(2)}, \ldots, x^{(M)}\} XM={x(1),x(2),...,x(M)}。
- 这样做的好处是可以用小批量来近似全数据集的目标函数,减少计算量。
从噪声分布 p ( ϵ ) p(\epsilon) p(ϵ) 中采样 ϵ \epsilon ϵ
- 在 VAE 中,通常取 p ( ϵ ) p(\epsilon) p(ϵ) 为标准正态 N ( 0 , I ) \mathcal{N}(0,I) N(0,I)。
- 这些噪声样本会用来做重参数化 : z ~ = g ϕ ( ϵ , x ) \tilde{z} = g_\phi(\epsilon,x) z~=gϕ(ϵ,x)。
- 如果你只做一次采样(即 L = 1 L=1 L=1),就意味着每个数据点 x ( i ) x^{(i)} x(i) 只对应一个 ϵ ( i ) \epsilon^{(i)} ϵ(i) 和一个 z ~ ( i ) \tilde{z}^{(i)} z~(i)。
计算小批量下界的梯度
- 用公式(8)那样,把变分下界 L ( θ , ϕ ; X ) \mathcal{L}(\theta,\phi; X) L(θ,ϕ;X) 用小批量+采样来近似:
L ~ M ( θ , ϕ ; X M ) = N M ∑ i = 1 M L ~ ( θ , ϕ ; x ( i ) ) , \tilde{\mathcal{L}}^M(\theta,\phi; X^M) = \frac{N}{M} \sum_{i=1}^M \tilde{\mathcal{L}}(\theta,\phi; x^{(i)}), L~M(θ,ϕ;XM)=MNi=1∑ML~(θ,ϕ;x(i)),
其中 L ~ \tilde{\mathcal{L}} L~ 可以是公式(6) (通用版本)或公式(7)(KL 项可解析时的版本)。- 然后对这个小批量近似下界,计算关于 θ \theta θ 和 ϕ \phi ϕ 的梯度:
g = ∇ θ , ϕ L ~ M ( θ , ϕ ; X M ) . g = \nabla_{\theta,\phi} \, \tilde{\mathcal{L}}^M(\theta,\phi; X^M). g=∇θ,ϕL~M(θ,ϕ;XM).更新参数 θ \theta θ 和 ϕ \phi ϕ
- 使用随机梯度下降(SGD)、Adagrad、Adam等方法,根据上一步的梯度 g g g 来更新参数:
θ ← θ + α ⋅ g θ , ϕ ← ϕ + α ⋅ g ϕ . \theta \leftarrow \theta + \alpha \cdot g_\theta, \quad \phi \leftarrow \phi + \alpha \cdot g_\phi. θ←θ+α⋅gθ,ϕ←ϕ+α⋅gϕ.- 其中 α \alpha α 是学习率,或由自适应算法(如 Adam)自动调整。
直到收敛
- 不断重复上述"小批量采样 + 噪声采样 + 计算梯度 + 参数更新"步骤,直到损失不再显著下降或达到预设的迭代次数。
- 训练结束后,得到学习到的 θ \theta θ(解码器)和 ϕ \phi ϕ(编码器)。
当我们观察公式(7)中给出的目标函数时,它与自编码器的联系就变得清晰 。第一项(近似后验与先验之间的KL散度)作为一个正则项,而第二项是一个期望的负重构误差。函数 g ϕ ( ⋅ ) g_\phi(\cdot) gϕ(⋅)被选择为将数据点 x ( i ) x^{(i)} x(i)和一个随机噪声向量 ϵ ( l ) \epsilon^{(l)} ϵ(l)映射为该数据点近似后验的一个样本: z ( i , l ) = g ϕ ( ϵ ( l ) , x ( i ) ) z^{(i,l)} = g_\phi(\epsilon^{(l)}, x^{(i)}) z(i,l)=gϕ(ϵ(l),x(i)),其中 z ( i , l ) ∼ q ϕ ( z ∣ x ( i ) ) z^{(i,l)} \sim q_\phi(z|x^{(i)}) z(i,l)∼qϕ(z∣x(i))。随后,这个样本 z ( i , l ) z^{(i,l)} z(i,l)被输入到函数 log p θ ( x ( i ) ∣ z ( i , l ) ) \log p_\theta(x^{(i)}|z^{(i,l)}) logpθ(x(i)∣z(i,l))中,该函数表示在给定 z ( i , l ) z^{(i,l)} z(i,l)的情况下数据点 x ( i ) x^{(i)} x(i)在生成模型下的概率密度(或概率质量)。这一项在自编码器术语中就是一个负的重构误差。
2.4 重参数化技巧
为了解决我们的问题,我们采用了一种从 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)中生成样本的替代方法。这个关键的重参数化技巧 其实非常简单。设 z z z为一个连续随机变量,且 z ∼ q ϕ ( z ∣ x ) z\sim q_\phi(z|x) z∼qϕ(z∣x)是某个条件分布。通常我们可以将随机变量 z z z表示为一个确定性变量 z = g ϕ ( ϵ , x ) z=g_\phi(\epsilon, x) z=gϕ(ϵ,x),其中 ϵ \epsilon ϵ是一个具有独立边缘分布 p ( ϵ ) p(\epsilon) p(ϵ)的辅助变量,而 g ϕ ( ⋅ ) g_\phi(\cdot) gϕ(⋅)是一个由 ϕ \phi ϕ参数化的向量值函数。
这种重参数化对我们的问题非常有用,因为它可以将关于 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)的期望重写成关于 p ( ϵ ) p(\epsilon) p(ϵ)的期望,使得对该期望的蒙特卡洛估计对 ϕ \phi ϕ是可微的。证明如下:
给定确定性映射 z = g ϕ ( ϵ , x ) z=g_\phi(\epsilon, x) z=gϕ(ϵ,x),我们知道 q ϕ ( z ∣ x ) ∏ i d z i = p ( ϵ ) ∏ i d ϵ i q_\phi(z|x)\prod_i dz_i = p(\epsilon)\prod_i d\epsilon_i qϕ(z∣x)∏idzi=p(ϵ)∏idϵi。因此(注意,我们采用的微分记号约定是 d z = ∏ i d z i dz = \prod_i dz_i dz=∏idzi):
∫ q ϕ ( z ∣ x ) f ( z ) d z = ∫ p ( ϵ ) f ( z ) d ϵ = ∫ p ( ϵ ) f ( g ϕ ( ϵ , x ) ) d ϵ \int q_\phi(z|x)f(z)dz = \int p(\epsilon)f(z)d\epsilon = \int p(\epsilon)f(g_\phi(\epsilon, x))d\epsilon ∫qϕ(z∣x)f(z)dz=∫p(ϵ)f(z)dϵ=∫p(ϵ)f(gϕ(ϵ,x))dϵ
于是可以构造出一个可微的估计器:
∫ q ϕ ( z ∣ x ) f ( z ) d z ≈ 1 L ∑ l = 1 L f ( g ϕ ( x , ϵ ( l ) ) ) , ϵ ( l ) ∼ p ( ϵ ) \int q_\phi(z|x)f(z)dz \approx \frac{1}{L} \sum_{l=1}^L f(g_\phi(x, \epsilon^{(l)})),\quad \epsilon^{(l)} \sim p(\epsilon) ∫qϕ(z∣x)f(z)dz≈L1l=1∑Lf(gϕ(x,ϵ(l))),ϵ(l)∼p(ϵ)
我们在第2.3节中将该技巧应用于变分下界的估计,从而获得了一个可微的估计器。
举一个例子,考虑一维高斯情形:设 z ∼ p ( z ∣ x ) = N ( μ , σ 2 ) z\sim p(z|x)=\mathcal{N}(\mu, \sigma^2) z∼p(z∣x)=N(μ,σ2)。在这种情况下,一个有效的重参数化是 z = μ + σ ϵ z=\mu+\sigma\epsilon z=μ+σϵ,其中 ϵ \epsilon ϵ是辅助噪声变量, ϵ ∼ N ( 0 , 1 ) \epsilon\sim\mathcal{N}(0,1) ϵ∼N(0,1)。因此,
E N ( z ; μ , σ 2 ) f ( z ) = E N ( ϵ ; 0 , 1 ) f ( μ + σ ϵ ) ≈ 1 L ∑ l = 1 L f ( μ + σ ϵ ( l ) ) , ϵ ( l ) ∼ N ( 0 , 1 ) \mathbb{E}{\mathcal{N}(z;\mu,\sigma^2)}f(z) = \mathbb{E}{\mathcal{N}(\epsilon;0,1)}f(\\mu+\\sigma\\epsilon) \approx \frac{1}{L} \sum_{l=1}^L f(\mu+\sigma\epsilon^{(l)}),\quad \epsilon^{(l)} \sim \mathcal{N}(0,1) EN(z;μ,σ2)f(z)=EN(ϵ;0,1)f(μ+σϵ)≈L1l=1∑Lf(μ+σϵ(l)),ϵ(l)∼N(0,1)
对于哪些 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),我们可以选择这样的可微变换 g ϕ ( ⋅ ) g_\phi(\cdot) gϕ(⋅)和辅助变量 ϵ ∼ p ( ϵ ) \epsilon\sim p(\epsilon) ϵ∼p(ϵ)呢?以下是三种基本方法:
-
可解的逆累积分布函数(inverse CDF) 。在这种情况下,令 ϵ ∼ U ( 0 , I ) \epsilon \sim \mathcal{U}(0, I) ϵ∼U(0,I),并令 g ϕ ( ϵ , x ) g_\phi(\epsilon, x) gϕ(ϵ,x)为 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)的逆累积分布函数。例子包括:指数分布、柯西分布、逻辑斯蒂分布、瑞利分布、帕累托分布、韦布尔分布、倒数分布、戈莫珀兹分布、古贝尔分布以及厄兰分布。
-
类似于高斯分布的情形,对于任意"位置-尺度(location-scale)"分布族 ,我们可以选择标准分布(即位置为0,尺度为1)作为辅助变量 ϵ \epsilon ϵ,并令 g ( ⋅ ) = location + scale ⋅ ϵ g(\cdot)=\text{location}+\text{scale}\cdot\epsilon g(⋅)=location+scale⋅ϵ。例子包括:拉普拉斯分布、椭圆分布、Student's t分布、逻辑斯蒂分布、均匀分布、三角分布以及高斯分布。
-
复合变换:通常可以将随机变量表示为对辅助变量的不同变换。例子包括:对数正态分布(对正态分布变量取指数)、Gamma分布(对若干指数分布变量求和)、Dirichlet分布(Gamma变量的加权和)、Beta分布、卡方分布和F分布。
当以上三种方法都不可行时,仍存在对逆CDF的良好近似,这些近似的计算复杂度与PDF相当(具体方法可参见Dev86)。
3 示例:变分自编码器(Variational Auto-Encoder)
在本节中,我们将给出一个示例,其中我们使用神经网络作为概率编码器 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)(对生成模型 p θ ( x , z ) p_\theta(x,z) pθ(x,z)的后验的近似),并使用AEVB算法对参数 ϕ \phi ϕ和 θ \theta θ进行联合优化。
设潜变量的先验为中心各向同性多维高斯分布 p θ ( z ) = N ( z ; 0 , I ) p_\theta(z)=\mathcal{N}(z;0,I) pθ(z)=N(z;0,I)。注意,在这种情况下,先验不包含任何参数。我们设 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z)为一个多维高斯分布(对于实值数据)或伯努利分布(对于二值数据),其分布参数由一个多层感知机(MLP,即具有单隐藏层的全连接神经网络,见附录C)从 z z z中计算得到。注意,此时真实后验 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)是不可解的。
虽然 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)的形式具有很大自由度,但我们假设真实(但不可解)的后验可以被近似为一个协方差近似对角的高斯分布。在这种情况下,我们可以将变分近似后验设为一个具有对角协方差结构的多维高斯分布(请注意这只是一个简化选择,而不是我们方法的限制):
log q ϕ ( z ∣ x ( i ) ) = log N ( z ; μ ( i ) , σ 2 ( i ) I ) (9) \log q_\phi(z|x^{(i)}) = \log \mathcal{N}(z; \mu^{(i)}, \sigma^{2(i)}I) \tag{9} logqϕ(z∣x(i))=logN(z;μ(i),σ2(i)I)(9)
其中近似后验的均值 μ ( i ) \mu^{(i)} μ(i)和标准差 σ ( i ) \sigma^{(i)} σ(i)是编码器MLP的输出,即数据点 x ( i ) x^{(i)} x(i)和变分参数 ϕ \phi ϕ的非线性函数(见附录C)。
如第2.4节所述,我们通过如下方式从后验中采样: z ( i , l ) ∼ q ϕ ( z ∣ x ( i ) ) z^{(i,l)} \sim q_\phi(z|x^{(i)}) z(i,l)∼qϕ(z∣x(i)),使用
z ( i , l ) = g ϕ ( x ( i ) , ϵ ( l ) ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) z^{(i,l)} = g_\phi(x^{(i)}, \epsilon^{(l)}) = \mu^{(i)} + \sigma^{(i)} \odot \epsilon^{(l)} z(i,l)=gϕ(x(i),ϵ(l))=μ(i)+σ(i)⊙ϵ(l)
其中 ϵ ( l ) ∼ N ( 0 , I ) \epsilon^{(l)} \sim \mathcal{N}(0,I) ϵ(l)∼N(0,I), ⊙ \odot ⊙表示按元素乘法。
在该模型中,先验 p θ ( z ) p_\theta(z) pθ(z)和 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)都是高斯分布;在这种情况下,我们可以使用公式(7)中的估计器,此时KL散度可以直接解析计算与求导(见附录B)。该模型对数据点 x ( i ) x^{(i)} x(i)的估计器如下:
L ( θ , ϕ ; x ( i ) ) ≈ 1 2 ∑ j = 1 J 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 + 1 L ∑ l = 1 L log p θ ( x ( i ) ∣ z ( i , l ) ) \mathcal{L}(\theta, \phi; x^{(i)}) \approx \frac{1}{2} \sum_{j=1}^J \left1 + \\log((\\sigma_j\^{(i)})\^2) - (\\mu_j\^{(i)})\^2 - (\\sigma_j\^{(i)})\^2\\right + \frac{1}{L} \sum_{l=1}^L \log p_\theta(x^{(i)}|z^{(i,l)}) L(θ,ϕ;x(i))≈21j=1∑J1+log((σj(i))2)−(μj(i))2−(σj(i))2+L1l=1∑Llogpθ(x(i)∣z(i,l))
其中
z ( i , l ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) , ϵ ( l ) ∼ N ( 0 , I ) (10) z^{(i,l)} = \mu^{(i)} + \sigma^{(i)} \odot \epsilon^{(l)}, \quad \epsilon^{(l)} \sim \mathcal{N}(0,I) \tag{10} z(i,l)=μ(i)+σ(i)⊙ϵ(l),ϵ(l)∼N(0,I)(10)
如上文与附录C所述,解码项 log p θ ( x ( i ) ∣ z ( i , l ) ) \log p_\theta(x^{(i)}|z^{(i,l)}) logpθ(x(i)∣z(i,l))是一个伯努利或高斯MLP,具体取决于我们所建模的数据类型。
4 相关工作
据我们所知,Wake-Sleep算法 HDFN95 是文献中唯一另一种可应用于同一类连续潜变量模型的在线学习方法。与我们的方法类似,Wake-Sleep算法也使用一个识别模型来近似真实后验。然而,Wake-Sleep算法的一个缺点是,它需要对两个目标函数进行同时优化,而这两个目标函数的联合优化并不等价于对边缘似然(或其下界)的优化。Wake-Sleep算法的一个优点是它也适用于具有离散潜变量的模型。Wake-Sleep在每个数据点上的计算复杂度与AEVB相同。
近年来,随机变分推断(Stochastic Variational Inference) HBWP13 逐渐受到越来越多的关注。BJP12 最近提出了一种控制变量(control variate)方案,用于减少第2.1节中讨论的朴素梯度估计器的高方差,并将其应用于指数族后验的近似。在 RGB13 中,提出了一些通用方法(如控制变量方案),用于减少原始梯度估计器的方差。在 SK13 中,采用了与本文类似的重参数化方法,用于高效版本的随机变分推断算法,以学习指数族近似分布的自然参数。
AEVB算法揭示了有向概率模型(以变分目标训练)与自编码器之间的联系 。早在之前就已知,线性自编码器与某类生成式线性高斯模型之间存在联系。在 Row98 中,被证明主成分分析(PCA)等价于一个特定线性高斯模型的最大似然(ML)解,该模型的先验为 p ( z ) = N ( 0 , I ) p(z)=\mathcal{N}(0,I) p(z)=N(0,I),条件分布为 p ( x ∣ z ) = N ( x ; W z , ϵ I ) p(x|z)=\mathcal{N}(x;Wz,\epsilon I) p(x∣z)=N(x;Wz,ϵI),特别是在 ϵ \epsilon ϵ趋于无穷小的情况下。
在关于自编码器的相关近期研究中,VLL+10 证明了非正则化自编码器的训练准则等价于最大化输入 X X X与潜在表示 Z Z Z之间互信息的下界(参见信息最大化原理Lin89)。最大化互信息(关于参数)等价于最大化条件熵,而条件熵的下界是自编码模型下数据的期望对数似然 VLL+10,也就是负重构误差。然而,人们已经充分认识到,仅靠重构误差本身并不足以学习有用的表示 BCV13。因此,已经提出了各种正则化技术来使自编码器学习出有用的表示,例如去噪、收缩、稀疏自编码器等变体 BCV13。
SGVB的目标函数中包含一个由变分下界决定的正则项(例如公式(10)),因此无需引入额外的超参数用于正则化来学习有用的表示。此外,与我们相关的还有编码器-解码器架构,如预测稀疏分解(Predictive Sparse Decomposition, PSD) KRL08,我们从中汲取了一些灵感。另一个相关方向是最近提出的生成随机网络(Generative Stochastic Networks) BTL13,其中噪声自编码器被用来学习一个马尔可夫链的转移算子,以从数据分布中采样。在 SL10 中,也使用了一个识别模型以便高效地训练深度玻尔兹曼机(Deep Boltzmann Machines)。这些方法通常用于非规范化模型(例如无向模型,如玻尔兹曼机)或仅限于稀疏编码模型,这与我们所提出的用于训练一般有向概率模型的算法不同。
最近提出的DARN方法 GMW13 同样使用自编码结构来学习一个有向概率模型,然而他们的方法仅适用于二值潜变量。更近一些的工作 RMW14 同样将自编码器、有向概率模型与使用我们在本文中描述的重参数化技巧的随机变分推断联系起来。他们的工作是独立于我们进行的,为AEVB提供了另一种视角。
5 实验
我们对MNIST和Frey Face图像数据集训练了生成模型(数据集可从:http://www.cs.nyu.edu/~roweis/data.html 获取),并就变分下界和估计的边缘似然对不同的学习算法进行了比较。
我们使用了第3节中所述的生成模型(解码器)和变分近似模型(编码器),其中编码器和解码器具有相同数量的隐藏单元。由于Frey Face数据是连续的,我们使用了具有高斯输出的解码器,其结构与编码器相同,只是在解码器的输出端使用了S型激活函数将均值限制在区间 ( 0 , 1 ) (0,1) (0,1)。请注意,这里所说的"隐藏单元"是指编码器与解码器神经网络中的隐藏层。
参数通过随机梯度上升进行更新,梯度由下界估计器 ∇ θ , ϕ L ( θ , ϕ ; X ) \nabla_{\theta,\phi}\mathcal{L}(\theta, \phi; X) ∇θ,ϕL(θ,ϕ;X)(见算法1)计算,并添加了一个小的权重衰减项,对应于先验 p ( θ ) = N ( 0 , I ) p(\theta)=\mathcal{N}(0,I) p(θ)=N(0,I)。对该目标的优化等价于近似的最大后验(MAP)估计,其中似然项的梯度由下界的梯度进行近似。
我们将AEVB算法的性能与Wake-Sleep算法 HDFN95 进行了比较。我们为Wake-Sleep算法和变分自编码器使用了相同的编码器(也称为识别模型)。所有变分参数和生成参数均通过从 N ( 0 , 0.01 ) \mathcal{N}(0,0.01) N(0,0.01)中随机采样初始化,并基于MAP准则进行联合的随机优化。步长使用Adagrad DHS10 进行自适应调整;Adagrad的全局步长参数从 { 0.01 , 0.02 , 0.1 } \{0.01, 0.02, 0.1\} {0.01,0.02,0.1}中选取,依据训练集前几轮迭代中的性能表现来确定。我们使用了大小为 M = 100 M=100 M=100的小批量,每个数据点采样数为 L = 1 L=1 L=1。
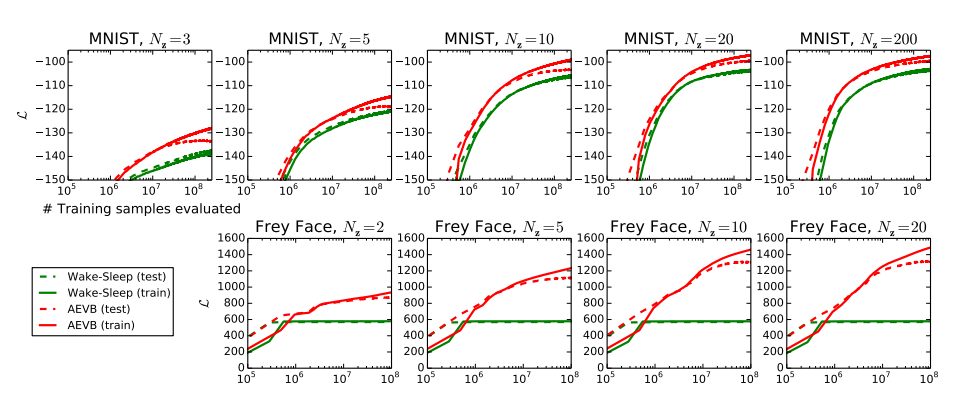 图2说明: 我们将AEVB方法与Wake-Sleep算法在优化下界方面的表现进行了比较,实验中考虑了不同潜在空间维度 N z N_z Nz的情形。我们的算法在所有实验中收敛更快,且获得了更好的解。非常有趣的是,潜变量数量的增加并未导致更多的过拟合,这可以用变分下界带来的正则化效应来解释。纵轴表示:每个数据点的估计平均变分下界。由于估计器方差很小(<1),因此在图中省略。横轴表示:已评估的训练点数量。在一台运行于40 GFLOPS的Intel Xeon CPU上,计算每百万训练样本大约耗时20-40分钟。
图2说明: 我们将AEVB方法与Wake-Sleep算法在优化下界方面的表现进行了比较,实验中考虑了不同潜在空间维度 N z N_z Nz的情形。我们的算法在所有实验中收敛更快,且获得了更好的解。非常有趣的是,潜变量数量的增加并未导致更多的过拟合,这可以用变分下界带来的正则化效应来解释。纵轴表示:每个数据点的估计平均变分下界。由于估计器方差很小(<1),因此在图中省略。横轴表示:已评估的训练点数量。在一台运行于40 GFLOPS的Intel Xeon CPU上,计算每百万训练样本大约耗时20-40分钟。
似然下界
我们分别训练了生成模型(解码器)和对应的编码器(即识别模型),在MNIST数据集上使用了500个隐藏单元,在Frey Face数据集上使用了200个隐藏单元(为了防止过拟合,因为该数据集规模明显更小)。隐藏单元数的选择基于自编码器的相关文献,并且不同算法的相对性能对这些选择并不敏感。图2展示了比较下界的结果。有趣的是,多余的潜变量并未导致过拟合,这可以通过变分下界的正则化性质来解释。
边缘似然
对于非常低维的潜在空间,我们可以使用MCMC估计器来估计所学习的生成模型的边缘似然。关于边缘似然估计器的更多信息见附录。对于编码器和解码器,我们再次使用神经网络,这次设置为100个隐藏单元和3个潜变量;对于更高维的潜在空间,估计变得不可靠。我们仍然使用MNIST数据集。将AEVB方法与Wake-Sleep方法和蒙特卡洛EM(MCEM)进行了比较,MCEM中采用了Hybrid Monte Carlo (HMC) 采样器 DKPR87;具体细节见附录。我们比较了三种算法在小训练集和大训练集规模下的收敛速度,结果见图3。
高维数据的可视化
如果我们选择一个低维潜在空间(例如二维),就可以使用训练好的编码器(识别模型)将高维数据投影到一个低维流形上。MNIST和Frey Face数据集中二维潜在流形的可视化结果见附录A。
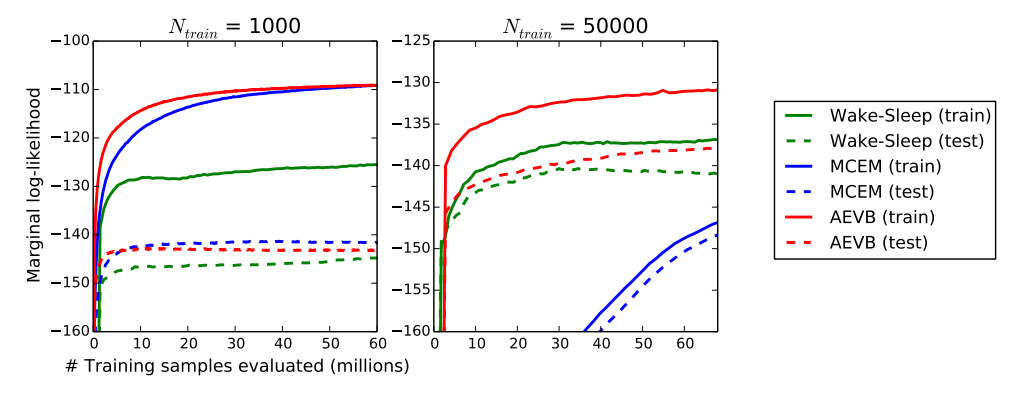 图3说明: 比较AEVB方法、Wake-Sleep算法和蒙特卡洛EM在不同训练数据量下的边缘似然估计性能 。蒙特卡洛EM不是一个在线算法,并且(与AEVB和Wake-Sleep方法不同)无法高效地应用于完整的MNIST数据集。
图3说明: 比较AEVB方法、Wake-Sleep算法和蒙特卡洛EM在不同训练数据量下的边缘似然估计性能 。蒙特卡洛EM不是一个在线算法,并且(与AEVB和Wake-Sleep方法不同)无法高效地应用于完整的MNIST数据集。
6 结论
我们提出了一种新颖的变分下界估计器------随机梯度变分贝叶斯(Stochastic Gradient VB, SGVB) ,用于在具有连续潜变量的情形下进行高效的近似推断。所提出的估计器可以直接使用标准的随机梯度方法进行求导和优化。针对i.i.d.数据集以及每个数据点包含连续潜变量的情况,我们提出了一种高效的推断与学习算法------自编码变分贝叶斯(Auto-Encoding VB, AEVB),它通过SGVB估计器来学习一个近似推断模型。该方法的理论优势在实验结果中得到了体现。
7 未来工作
由于SGVB估计器和AEVB算法几乎可以应用于任何包含连续潜变量的推断与学习问题,因此未来的研究方向非常广泛:(i)学习具有层次结构的生成模型 ,使用深度神经网络(例如卷积网络)作为编码器与解码器,并与AEVB联合训练;(ii)时间序列模型 (即动态贝叶斯网络);(iii)将SGVB应用于全局参数的推断 ;(iv)带有潜变量的监督模型,这对学习复杂的噪声分布非常有用。