和 DeepSeek-R1 一样强调 RL 的作用,但更强调 prompt 的重要性。
整体 RL 架构:

整体训练流程:

RL
prompt
进行了 prompt 多样性、难度评估、随机猜测答案 三个方面进行了优化。
‒ 多样性:关注覆盖。
‒ 难度:用同一参数+高温度系数进行采样,评估 prompt 的难度。
‒ 正确性:删除一些容易猜对的答案
Cot SFT
拒绝采样来生成长 CoT 数据用于模型监督微调,并用四方面的内容强化模型:
‒ 规划:执行前先规划步骤
‒ 评估:不断规划评估中间步骤
‒ 检查:重新思考并改进回答
‒ 探索:鼓励进行替代方案的搜索
通过这些长 CoT 作冷启动,模型内化了这些能力。
RL 算法
基础目标是最大化回答的收益: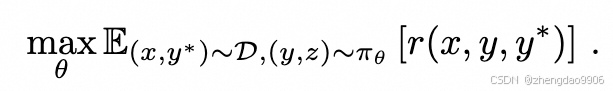
x 为 prompt,y* 为标准答案,πθ 是 LLM 网络参数, z 为中间规划的步骤,y~πθ(·|x,z),r 为奖励函数计算方法;
注意到这里 z 其实是一个两阶段采样,先根据 prompt 采样出完成任务的计划,再根据提示词和计划,采样得到答案。实际测试中, 再简单的问题都要经历这两步采样过程。
为了确保收敛的效果,使用 PG 时引入了 reference model 并用 KL 散度进行约束:

理想情况下,最优策略 π*应当满足: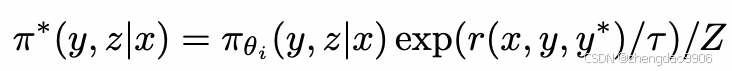
其中 Z 为归一化参数: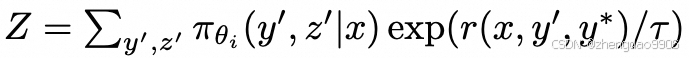
两边取对数: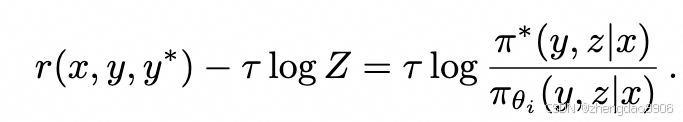
如此就可以定义 L2 损失函数: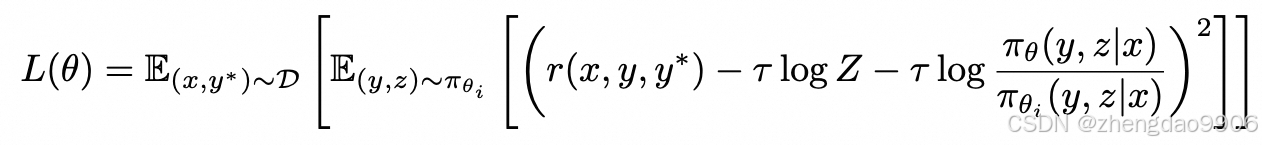
问题是中间项难以计算,于是进行 K 次不同的采样,来实现对 Z 的近似。并且为了训练时的稳定性,将 K 次采样的奖励 r 作平均,得到了作为奖励函数的 baseline。
对 L(θ) 求梯度,就得到了最终的策略梯度:

其它技术
长度惩罚
为了避免像 Qwen 和 DeepSeek-R1 那样,随着训练模型输出结果越来越长,Kimi 引入了长度惩罚来减少成本。对于一个问题的 k 次答案正确的采样,计算每一个回答的长度,并给回答正确的答案增加一个长度正则:
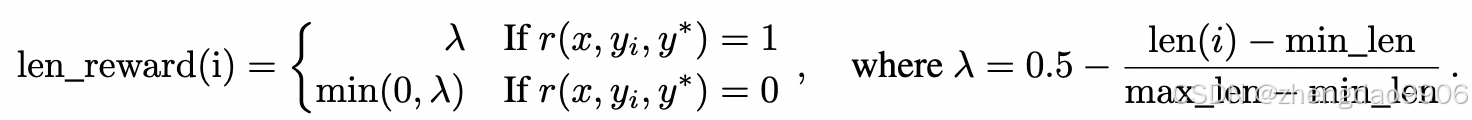
当 len(i)= min_len 时,奖励为 0.5;当 len(i)=max_len 时,奖励为-0.5。整体而言,该奖励函数鼓励模型输出较短的回答。
采样策略
‒ 课程采样:采样那些当前模型难度适中的 prompt。从简单的任务开始训练,然后逐渐进入更有挑战性的任务。
‒ 错题优先:跟踪每个问题i的成功率si和与1 - si成比例的样本问题,以便成功率较低的问题获得较高的采样概率。
Long2Short
压缩模型输出长度的技术
‒ 模型合并:将长 Cot 和短 Cot 模型直接混合
‒ 最短拒绝采样:生成 8 次答案,选择其中答案最短的那条进行监督微调
‒ DPO:将短且正确的答案作为正样本,长、或者错误的答案作为负样本
‒ 长度惩罚,即之前提到的 λ