MultiSFL: Towards accurate split federated learning via multi-model aggregation and knowledge replay
| 名称 | MultiSFL: Towards accurate split federated learning via multi-model aggregation and knowledge replay |
|---|---|
| 会议 | Proceedings of the AAAI Conference on Artificial Intelligence |
| 作者 | Zeke Xia, Ming Hu, Dengke Yan, Ruixuan Liu, Anran Li, Xiaofei Xie, Mingsong Chen* |
| DOI | 10.1609/aaai.v39i1.32076 |
TLDR
为解决分割联邦学习面对数据异质性和灾难性遗忘的不足,本文呢提出了一种新的 SFL 方法MultiSFL,该方法采用:i)有效的多模型聚合机制,以缓解由异质数据引起的梯度偏差;ii)新颖的知识回放策略,以应对灾难性遗忘问题。
背景
现有的联邦学习方法在部署于大规模人工智能物联网 (AIoT)应用时,往往会面临训练性能较低的问题。这主要是因为异构人工智能物联网设备的能力差异(例如内存、计算能力)可能不可避免地导致其所承载的深度神经网络(DNN)模型规模受限。
与传统的联邦学习方法不同,SFL将每个参与的深度神经网络模型分为两部分,即客户端部分 和服务器端 部分,并分别部署在两个云服务器上,即联邦服务器和主服务器。但是SFL在面对数据异质性 和灾难性遗忘时同样脆弱,尤其在non-IID数据时,SFL会出现"梯度发散"问题,导致全局模型性能下降。
灾难性遗忘(Catastrophic Forgetting)特指当神经网络在多个任务上按顺序进行训练时发生的现象。在这种情况下,当前任务的最优参数可能在先前任务的目标上表现不佳 。联邦学习(FL)中已有许多算法被提出以缓解遗忘问题。然而,由于对完整模型的严格要求,FL方法无法应用于分割式联邦学习(SFL)。据我们所知,MultiSFL 是首个在 SFL 中采用多模型训练 与知识重放的创新方法,以同时提升模型精度和训练稳定性。
分割式联邦学习(SFL)结合了联邦学习(FL)和分割学习(SL)的优点。在 SFL 中,完整模型被划分为两部分:客户端模型部分 和服务器端模型部分 。每个客户端与主服务器和聚合服务器进行通信。在每一轮 SFL 中,客户端并行地与主服务器交互以执行 SL 过程。随后,客户端将更新后的客户端模型部分发送至聚合服务器进行聚合。聚合服务器对所有客户端模型进行聚合,并将聚合后的模型同步给所有客户端。然而,与 FL 类似,SFL 仍然存在推理精度较低的问题。SFL 的目标是在 N N N 个客户端的训练数据集合上最小化损失函数,即:
min w F ( w ) = ∑ k = 1 N ∣ D k ∣ ∣ D ∣ F k ( w ) \min_{w}F(w)=\sum_{k=1}^N\frac{|D_k|}{|D|}F_k(w) wminF(w)=k=1∑N∣D∣∣Dk∣Fk(w)其中, w = w c ⊕ w s w = w^c \oplus w^s w=wc⊕ws 表示由客户端模型 w c w^c wc 与服务器端模型 w s w^s ws 组合而成, N N N 表示参与本地训练的客户端数量, D k D_k Dk 表示第 k k k 个客户端的数据集, F k ( w ) = 1 ∣ D k ∣ ∑ j ∈ D k f j ( w ) F_k(w) = \frac{1}{ |D_k|} \sum_{j \in D_k} f_j(w) Fk(w)=∣Dk∣1∑j∈Dkfj(w) 表示客户端 k k k 上数据样本的经验损失目标函数。
MultiSFL
图 2 展示了 MultiSFL 的框架和工作流程。
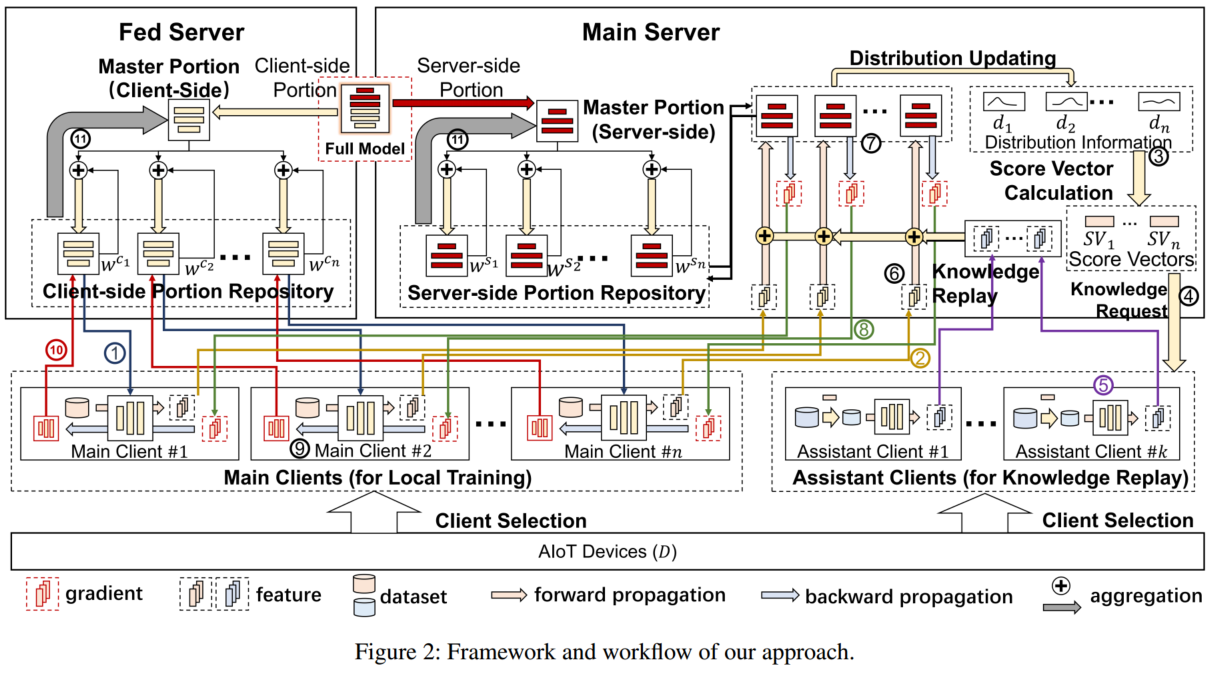
与传统的 SFL 类似,MultiSFL 由两个服务器(即联邦服务器 和 主服务器 )以及多个 AIoT 设备组成。在 MultiSFL 中,完整模型被划分为两个部分,即客户端部分和服务器端部分。如图 2 所示,为了解决由 non-IID 数据引起的梯度发散问题,MultiSFL 采用多个分支模型进行本地训练。
为了实现基于多模型的联邦学习训练,联邦服务器维护一个客户端部分仓库 ,用于存储客户端分支模型;主服务器维护一个服务器端部分仓库 ,用于存储服务器端分支模型。需要注意的是,与某个分支模型对应的服务器端部分和客户端部分在各自的仓库中被分配相同的索引。为了实现分支模型之间的知识共享,每个服务器都维护一个主模型,该主模型由其仓库中所有分支模型聚合而成。
为缓解灾难性遗忘,在每一轮 SFL 训练中,主服务器为每个分支模型计算一个评分向量,该向量的元素数量等于分类类别的数量。每个元素的取值根据累积的训练数据分布计算,其中较新的训练数据分布对评分向量的计算影响更大。主服务器根据评分向量选择多个未激活客户端作为辅助客户端,并请求辅助客户端提供特定类别的特征,以协助服务器端分支模型的训练。
在 MultiSFL 中,每个中间模型的训练流程包括以下十一步:
- 步骤 1(模型分发) :联邦服务器随机选择 n n n 个客户端作为主客户端,并将客户端分支模型分发给主客户端进行本地训练。
- 步骤 2(特征上传) :每个主客户端使用其数据执行前向传播过程,并将其客户端分支模型的输出特征上传至主服务器。
- 步骤 3(评分向量计算):对于每个分支模型,主服务器根据其当前和历史训练数据分布计算一个评分向量。
- 步骤 4(知识请求) :随后,主服务器随机选择 k k k 个未激活客户端作为辅助客户端,将计算得到的评分向量分发给辅助客户端,并请求联邦服务器将客户端分支模型分发给相应的辅助客户端。
- 步骤 5(知识提取):辅助客户端根据接收到的评分向量从其数据中选择样本,并使用所选样本执行前向传播。然后,它们将输出特征上传至主服务器。需要注意的是,如果主服务器收集的特征不足,将重复步骤 4-5 以请求更多知识。
- 步骤 6(知识重放):主服务器将从主客户端和辅助客户端收集的特征一并输入到相应的服务器端分支模型中进行前向传播,并计算损失值。
- 步骤 7(服务器模型反向传播):主服务器执行反向传播过程以更新相应的服务器端分支模型,并获取主客户端上传特征的梯度。
- 步骤8(梯度分发):主服务器将梯度发送给对应的主客户端。
- 步骤9(客户端模型反向传播):每个主客户端使用接收到的梯度更新客户端部分模型。
- 步骤10(模型上传):每个主客户端将其客户端部分模型上传至联邦服务器。
- 步骤11(模型库更新):联邦服务器聚合所有客户端分支模型以生成新的客户端主模型,然后通过将客户端主模型与各客户端分支模型聚合来更新每个客户端分支模型。同样地,主服务器聚合所有服务器端分支模型以生成新的服务器端主模型,然后通过将新的服务器端主模型与各服务器端分支模型聚合来更新每个服务器端分支模型。
算法1 描述了 MultiSFL 的具体实现:
假设在每轮 SFL 通信中有 n n n 个激活客户端作为主要客户端参与。
第 1 行初始化客户端分支模型库 W c W^c Wc 及其对应的服务器端分支模型库 W s W^s Ws。
第 2 行初始化模型累计数据分布和采样比例。
第 3-25 行展示了整体 SFL 训练过程:
在第 4 行,随机选择 n n n 个客户端作为主要客户端进行本地训练。
第 7-22 行展示了每个客户端分支模型与其对应服务器端模型的协同训练过程。
在第 7 行,主要客户端 S i Si Si 使用其本地数据进行前向传播并获得中间特征 f c f_c fc。
第 8 行表示主服务器更新 w r s i w_r^{s_i} wrsi 的数据分布。
第 9 行,主服务器基于历史数据分布计算得分向量 s v i sv^i svi 。
第 10 行,主服务器根据 s v i sv^i svi 计算每个数据类别的采样数量 q i q^i qi。
第 11-17 行展示了采样特征的过程。
首先,主服务器初始化总采样供给量 l ′ l^{\prime} l′ 和总采样特征 f h f_h fh(第 11 行)。
主服务器随机选择一个能够满足或部分满足当前知识请求的空闲客户端 d e v a dev_a deva 作为辅助客户端,联邦服务器将客户端模型 w r c i w_r^{c_i} wrci 发送给 d e v a dev_a deva (第 13 行)。
d e v a dev_a deva 接收到 w r c i w_r^{c_i} wrci 后,根据当前知识请求 q i − l ′ q^i − l^{\prime} qi−l′ 使用 w r c i w_r^{c_i} wrci 对其本地数据进行采样,并发送采样数据的特征(第 14 行)。
主服务器接收到特征 f a f_a fa 后,更新总采样供给量 l ′ l^{\prime} l′ 和总采样特征 f h f_h fh(第 15-16 行)。
在第 18 行,主服务器将 f c f_c fc 和 f h f_h fh 合并得到 f s f_s fs。
在第 19-20 行,主服务器使用 f s f_s fs 更新服务器端分支模型,并将 f c f_c fc 的梯度发送回客户端 S i Si Si ,使客户端 S i Si Si 更新客户端分支模型 w r c i w_r^{c_i} wrci 。
第 22 行表示联邦服务器调整下一轮的采样比例。
在第 23 行,联邦服务器和主服务器分别聚合所有客户端分支模型和服务器端分支模型,以更新 w r + 1 c w_{r+1}^{c} wr+1c 和 w r + 1 s w_{r+1}^s wr+1s 。
在第 24-26 行,联邦服务器和主服务器在模型库与全局模型之间进行聚合,并更新模型库。

知识重放策略
为解决灾难性遗忘问题,MultiSFL 采用了一种知识重放策略,该策略要求未激活的客户端为每个完整分支模型上传在近期训练数据中分布较少类别的特征,并利用这些特征训练对应的服务器端分支模型。如算法 1 所示,MultiSFL 的知识重放策略包括三个关键过程,即分数向量计算 、知识请求 和 知识提取。
分数向量计算(SVCalculate(·))
该过程用于评估完整分支模型 w i w^i wi 对每个类别所学习到的知识,其中向量中的元素数量等于类别数量 ,并且在某一特定类别上使用更多数据进行训练的模型,会在该类别上被分配更高的得分值。为缓解灾难性遗忘问题,在得分向量计算中,对当前训练数据赋予更高的权重,而对历史数据赋予较低的权重 。对于每个分支模型 w r i w_r^i wri ,其得分值 s v i sv_i svi 的计算方式如下:
s v i = ∑ j = 0 r γ r − j L i j ∑ j = 0 r γ r − j sv_i=\frac{\sum_{j=0}^r \gamma^{r-j}L_ij}{\sum_{j=0}^r \gamma^{r-j}} svi=∑j=0rγr−j∑j=0rγr−jLij
其中, γ \gamma γ 是小于 0 的衰减因子, l j l_j lj 表示在第 r r r 轮训练中 w r i w_r^i wri 的本地数据分布。需要注意的是,由于 MultiSFL 仅在服务器端分支模型 w s i w^{s_i} wsi 上执行知识重放,因此在计算 s v i sv_i svi 时无需考虑知识重放。
没太看懂这句话。。。
知识请求(KnowledgeRequest(·))
该过程根据分数向量计算每个类别需要选择的数据样本数量,以便进行知识重放。
主服务器首先计算评分向量的平均分值。当某一类别对应的分值小于平均分值时,
说明该类别在最近出现的少,这里论文原文写错了
主服务器倾向于选择该类别的数据。对于每个数据类别 c c c,按如下方式计算其优先级值 p r i o r c i prior_c^i priorci:
p r i o r c i = m a x ( 0 , m e a n ( s v i ) − s v i c ) prior_c^i = max(0,\ mean(sv_i)-sv_ic) priorci=max(0, mean(svi)−svic)
注意,数据类别 c c c 的累计数据量越少,其优先级越高。利用优先级数值,可以计算数据类别 c c c 的采样数据数量如下:
q c i = ∣ D i ∣ × p r × p r i o r c i ∑ c p r i o r c i q_c^i = \frac{|D_i| \times p_r \times prior_c^i}{\sum_{c}prior_c^i} qci=∑cpriorci∣Di∣×pr×priorci
其中, p r p_r pr 是第 r r r 轮的采样比例, ∣ D i ∣ |D_i| ∣Di∣ 是为模型 w r i w_r^i wri 选定的主客户端的本地数据规模。
知识提取(KnowledgeExtr(·))
在接收到 w r c i w_r^{c_i} wrci 后,辅助客户端根据计算出的采样数据数量随机选择其本地数据进行前向传播,并将中间特征上传至主服务器。此外,MultiSFL 会重复知识提取过程,直到满足由知识请求过程计算出的请求为止。
请注意,在 SFL 中传输中间特征所造成的通信开销远大于传输模型所造成的通信开销。因此,将模型发送至辅助客户端所带来的额外通信开销可以忽略不计。
采样比例的自适应调整
在 MultiSFL 的知识回放策略中,采样比例 p r p_r pr 是一个显著影响 MultiSFL 性能的关键参数。
具体而言,随着采样比例 p r p_r pr 的增加,主服务器会请求更多数据来训练服务器端的分支模型,这能够显著提升各分支模型的精度,尤其是在 non-IID 场景下。
然而,较大的 p r p_r pr 不可避免地会导致通信开销的大幅增加。为了在模型精度与通信开销之间取得平衡, MultiSFL 提出了一种动态采样比例调整机制。 MultiSFL 倾向于在 CLP 阶段选择更多数据,而在其他训练轮次选择较少数据。
先前的研究观察到,当损失函数的曲面在某一点 w w w 处的曲率较大时,模型训练处于关键学习期(Critical Learning Period, CLP)。
MultiSFL 使用联邦梯度范数(Federated Gradient Norm, FGN)来近似训练过程中某一点 w w w 的损失曲面曲率。第 r r r 轮的 FGN 可定义如下:
F G N ( r ) = ∑ i = 1 n − η ∥ g ( w r i , ξ ) ∥ 2 n FGN(r) = \frac{\sum_{i=1}^n - \eta \left \| g(w_r^i,\xi) \right \|^2}{n} FGN(r)=n∑i=1n−η g(wri,ξ) 2
其中 g ( w i r , ξ ) g(w_{ir}, \xi) g(wir,ξ) 表示在 x i x_i xi 上计算得到的损失函数梯度。基于 FGN,对下一轮的采样比例 p t + 1 p_{t+1} pt+1 进行如下调整:
p r + 1 = F G N ( r ) − F G N ( r − 1 ) F G N ( r − 1 ) × p r p_{r+1} = \frac{FGN(r) - FGN(r-1)}{FGN(r-1)} \times p_r pr+1=FGN(r−1)FGN(r)−FGN(r−1)×pr