你遇到的大部分ubuntu中配置hadoop的问题这里都有解决方法!!!(近10000字)
概要
在Docker虚拟容器环境下,进行Hadoop-3.2.2分布式集群环境的配置与安装,完成基于Yarn模式的一个Master节点、两个Slaver(Worker)节点的配置。
1.主要步骤
- 安装配置启动Docker虚拟容器
- 配置主机名
- 配置自动时钟同步
- 配置hosts列表
- 配置免密码登录
- 安装JDK(在三台节点分别操作此步骤)
- 安装部署Hadoop集群
2、实验环境
虚拟机数量:3
系统版本:Centos Stream/Ubuntu 20.4(18.4)
Hadoop版本:Apache Hadoop 3.2.2(3.2.1)
3、相关技能
熟悉Linux操作系统
Hadoop原理
4、知识点
常见Linux命令的使用
linux系统基础配置
配置JDK
配置Hadoop的相关参数
掌握Hadoop操作指令
在安装Docker之前安装一些必要的依赖包:
sudo apt install apt-transport-https ca-certificates curl software-properties-common添加 Docker 的官方 GPG 密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -添加 Docker 的 APT 源
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"更新 APT 包索引
sudo apt update安装 Docker CE
sudo apt install docker-ce安装完成后,您可以通过运行以下命令来验证 Docker 是否成功安装:
sudo systemctl status docker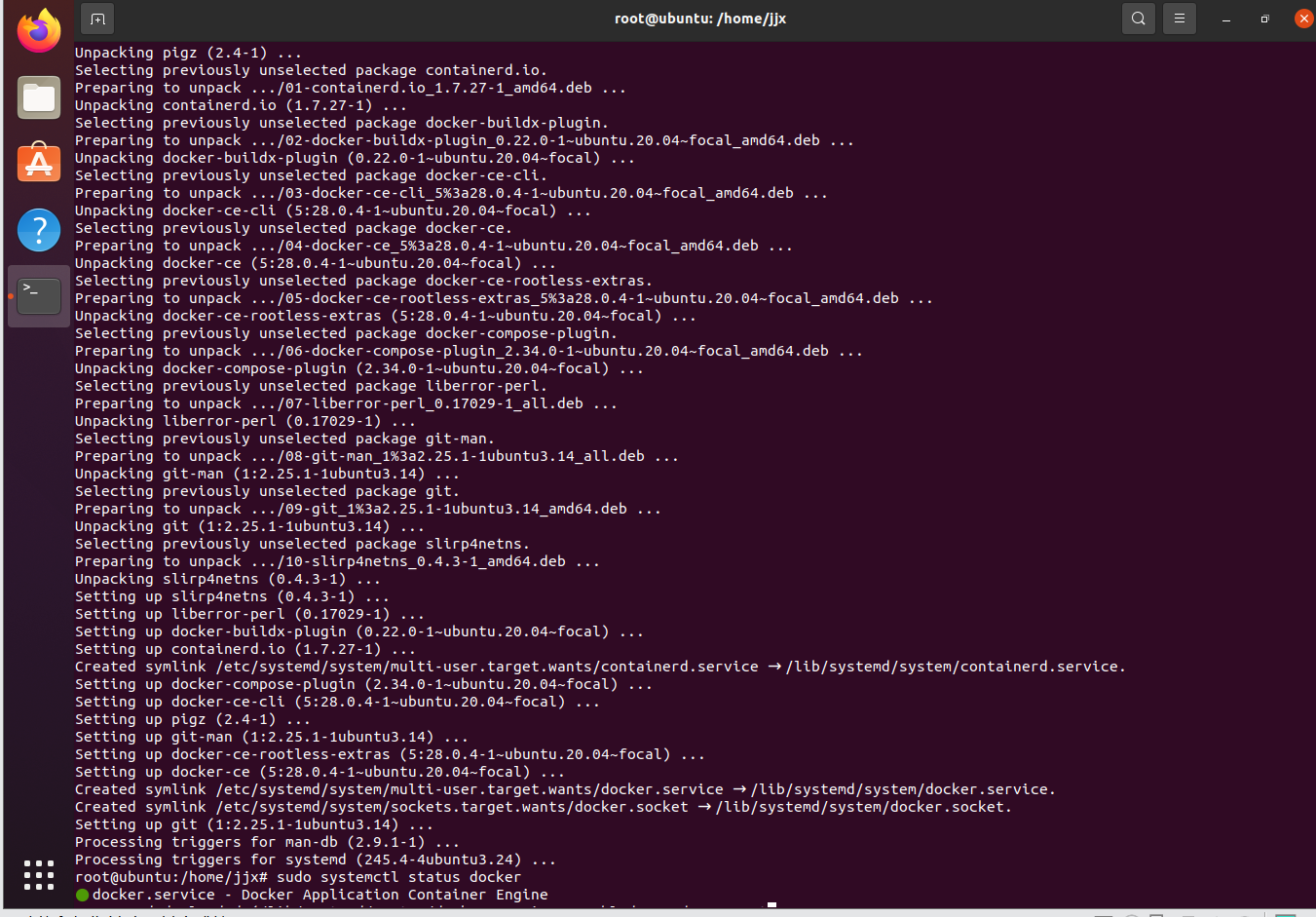
下载Docker compose
sudo apt update
sudo apt install docker-compose
docker-compose version 创建Docker-compose.yml

将以下内容放入yml:
version: "3"
services:
master:
image: ubuntu:latest
container_name: masternode
privileged: true
networks:
hadoop:
ipv4_address: 10.10.0.11
ports:
- 9870:9870
- 9000:9000
- 18040:18040
- 18030:18030
- 18025:18025
- 18141:18141
- 18088:18088
- 50070:50070
- 60000:60000
- 16000:16000
- 8080:8080
volumes:
- hadoop:/hadoop/master
- ./Files:/Files
environment:
- CLUSTER_NAME=hadoop_cluster_simple
stdin_open: true
tty: true
slave01:
image: ubuntu:latest
container_name: slave01node
privileged: true
networks:
hadoop:
ipv4_address: 10.10.0.12
volumes:
- hadoop:/hadoop/slave01
- ./Files:/Files
environment:
- CLUSTER_NAME=hadoop_cluster_simple
stdin_open: true
tty: true
slave02:
image: ubuntu:latest
container_name: slave02node
privileged: true
networks:
hadoop:
ipv4_address: 10.10.0.13
volumes:
- hadoop:/hadoop/slave02
- ./Files:/Files
environment:
- CLUSTER_NAME=hadoop_cluster_simple
stdin_open: true
tty: true
slave03:
image: ubuntu:latest
container_name: slave03node
privileged: true
networks:
hadoop:
ipv4_address: 10.10.0.14
volumes:
- hadoop:/hadoop/slave03
- ./Files:/Files
environment:
- CLUSTER_NAME=hadoop_cluster_simple
stdin_open: true
tty: true
volumes:
hadoop:
networks:
hadoop:
driver: bridge
ipam:
driver: default
config:
- subnet: "10.10.0.0/24" 在docker镜像地址中有已无法进入的地址,需要换源,具体看:完美解决Docker pull时报错:https://registry-1.docker.io/v2/-CSDN博客
启动Docker虚拟容器
sudo docker-compose -f docker-compose.yml up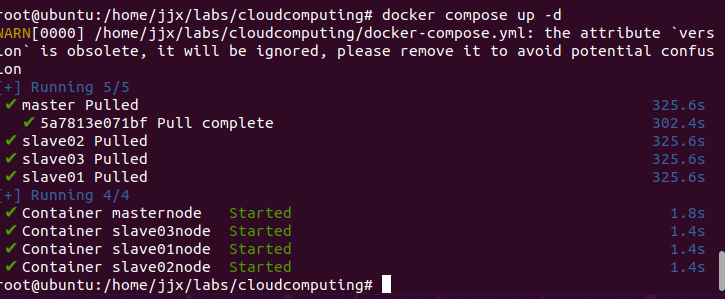
打开三个新的终端窗口,分别登录master、slave01和slave02节点(按下 ctrl + d 可以从各节点退出 )
sudo docker exec -it masternode /bin/bash
sudo docker exec -it slave01node /bin/bash
sudo docker exec -it slave02node /bin/bash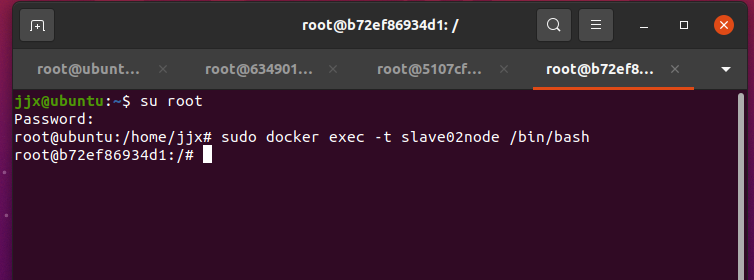
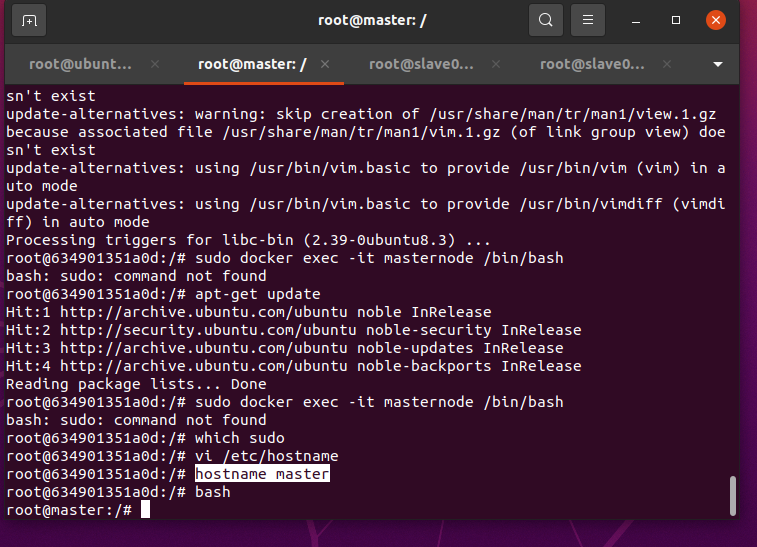
使用vim编辑masternode主机名
vi /etc/hostnamedocker容器中没有vim包需要下载:
apt-get update
apt-get install -y vim同理将slave01和slave02也改好
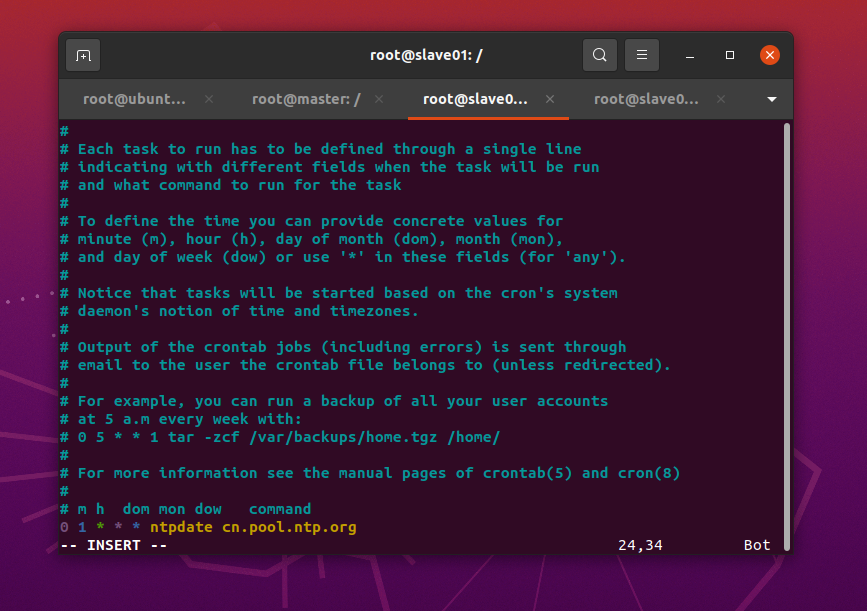
使用Linux命令crontab配置定时任务进行自动时钟同步(分别进入三个节点)
apt install -y cron
crontab -e按"i "键,进入INSERT模式;输入下面的内容(星号之间和前后都有空格)
0 1 * * * ntpdate cn.pool.ntp.org按Esc键退出INSERT模式,按下"shift+:"键,输入wq保存修改并退出
手动同步时间,直接在Terminal运行下面的命令
apt install -y ntpdate
ntpdate cn.pool.ntp.org
分别在三个节点 配置hosts列表
在各虚拟机中运行ifconfig命令,获得当前节点的ip地址
apt install -y net-tools
ifconfig分别获得三个结点的ip地址
编辑主机名列表文件
vi /etc/hosts将下面三行添加到/etc/hosts文件中,保存退出
#master节点对应IP地址是10.10.0.11,slave01对应的IP是10.10.0.12,slave02对应的IP是10.10.0.13
10.10.0.11 master
10.10.0.12 slave01
10.10.0.13 slave02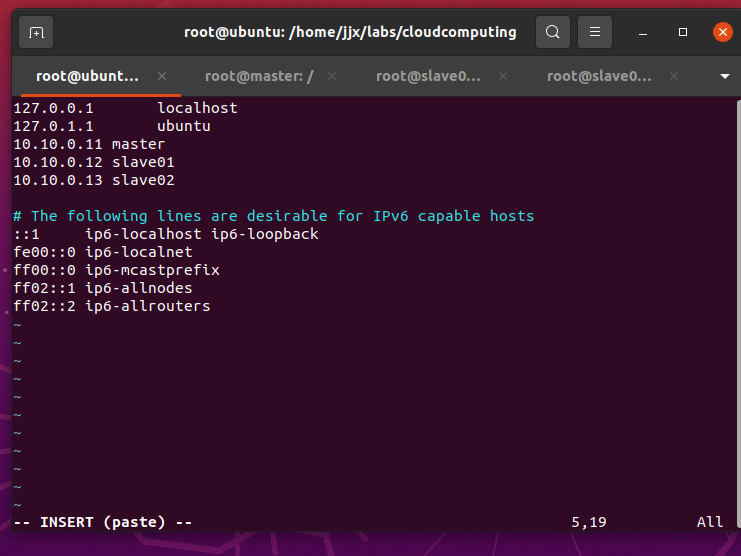
Ping主机名,按"Ctrl+C"终止命令
ping master
ping slave01
ping slave02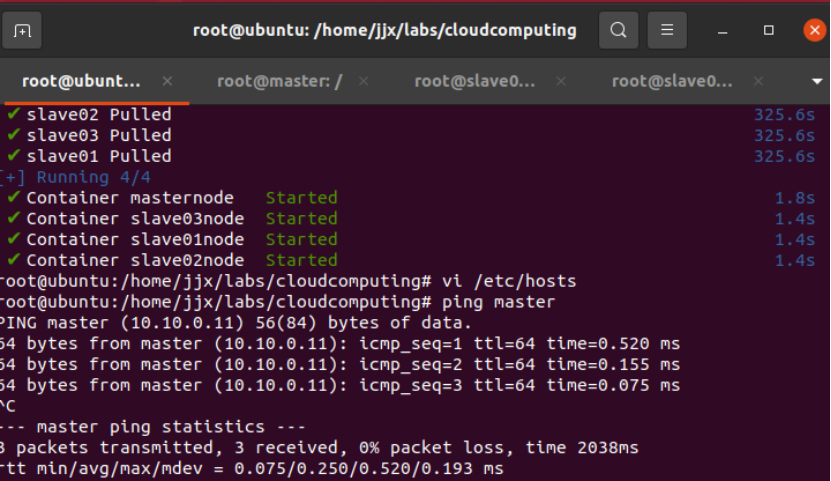
三个虚拟节点的免密码登录配置
先在master节点上进行配置,生成rsa的SSH公钥
apt install -y openssh-client
ssh-keygen -t rsa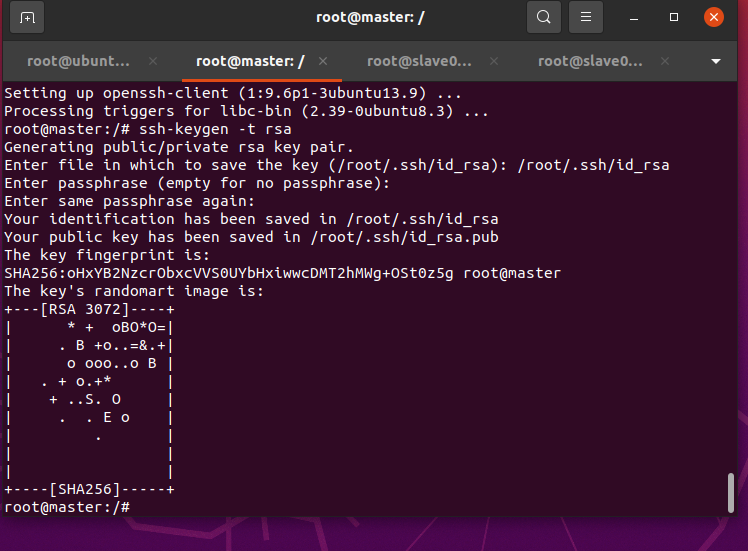
生成的密钥在用户根目录中的.ssh子目录中,进入.ssh目录,查看目录文件
cd ~/.ssh/
ls
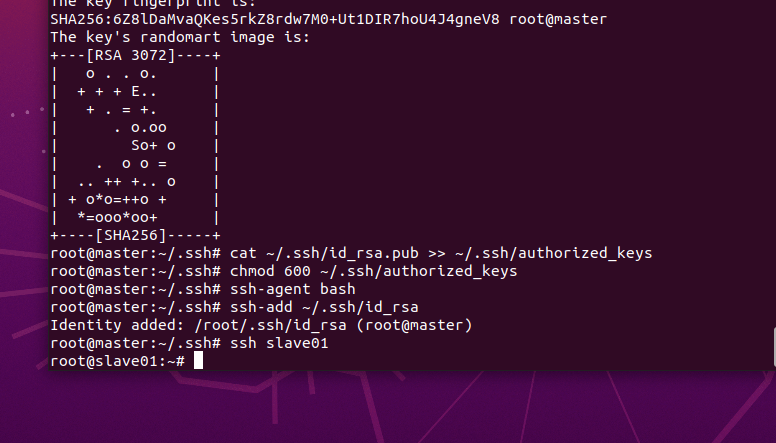
将id_rsa.pub 文件追加 到authorized_keys文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys修改authorized_keys文件的权限,命令如下:
chmod 600 ~/.ssh/authorized_keys将专用密钥添加到 ssh-agent 的高速缓存中
ssh-agent bash
ssh-add ~/.ssh/id_rsa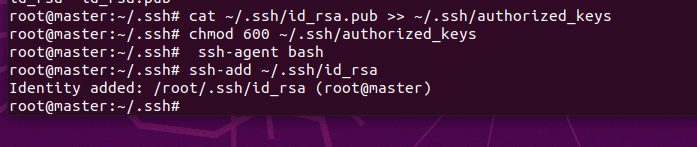
将authorized_keys文件复制到slave01、slave02节点root用户的根目录,命令(在宿主机终端下执行 )如下:
sudo docker cp masternode:/root/.ssh/authorized_keys .
sudo docker cp authorized_keys slave01node:/root/.ssh/
sudo docker cp authorized_keys slave02node:/root/.ssh/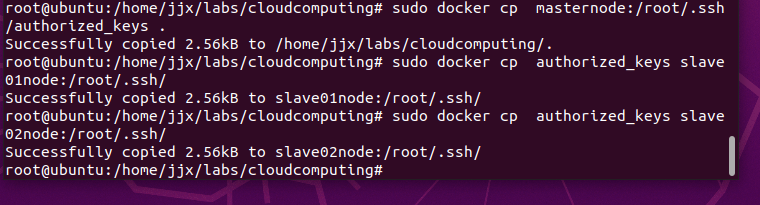
打开主机和三个节点的防火墙
apt install ufw -y验证免密登陆
ssh slave01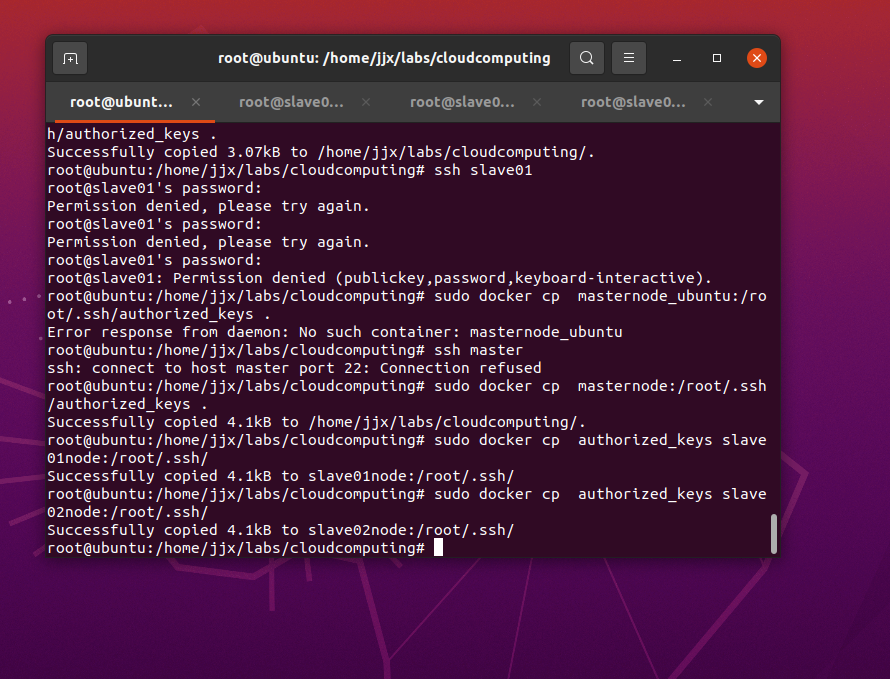
退出slave01远程登录
exit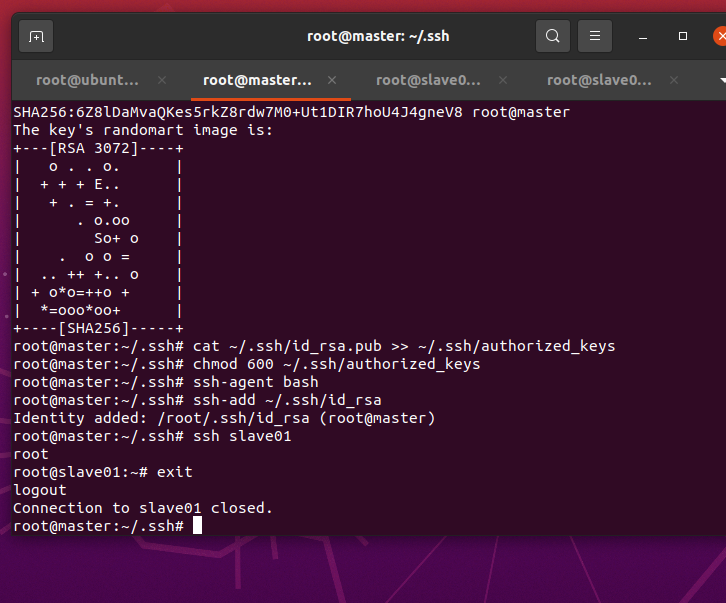
通过apt-get安装JDK
apt-get install openjdk-8-jdk使用vim修改".bashrc"
vi ~/.bashrc 复制粘贴以下内容添加到到上面vim打开的文件中:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=JAVA_HOME/bin:PATH
使环境变量生效,查看Java版本
source ~/.bashrc
java -version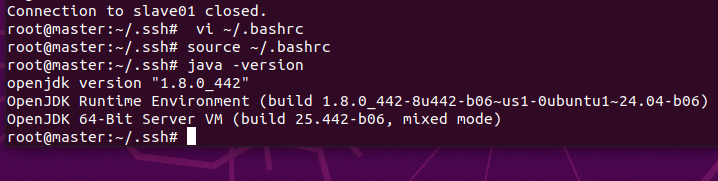
安装部署Hadoop集群
说明:每个节点上的Hadoop配置基本相同,在master节点操作,然后复制到slave01、slave02两个节点。
hadoop用Ubuntu自带的火狐浏览器下载,镜像地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/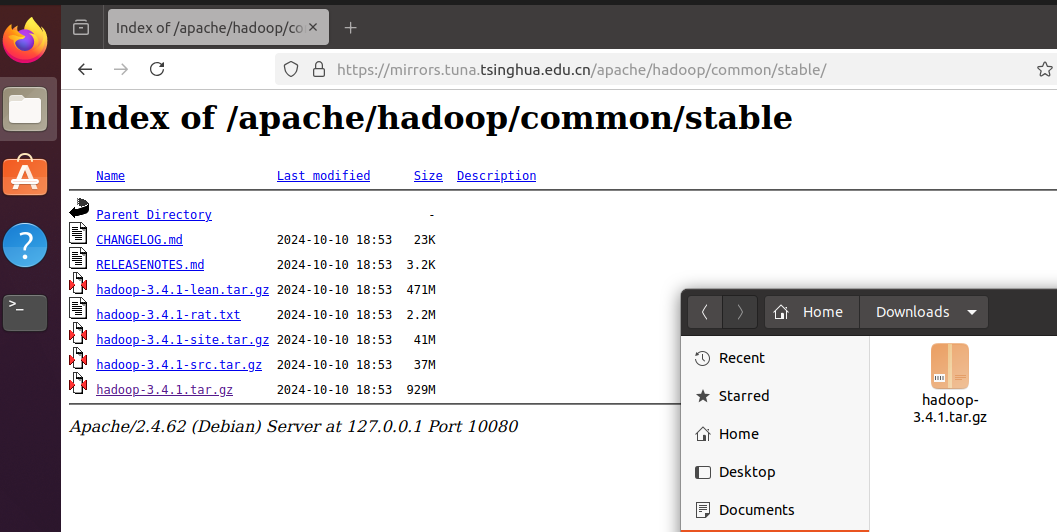
将/目录下的hadoop-3.4.1.tar.gz压缩包解压到/hadoop-3.4.1目录下:
sudo tar -zxf /home/Downloads/hadoop-3.4.1.tar.gz -C /usr/local-zxf后面的是刚才下载的压缩包路径,如果没安装输入法打不了中文的可以直接找到刚才下载的那个压缩包点复制然后粘贴到命令行就是路径了
配置hadoop-env.sh文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/hadoop-env.sh在hadoop-env.sh文件中添加JAVA环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
配置yarn-env.sh文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/yarn-env.sh在yarn-env.sh文件中添加JAVA环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
配置core-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/core-site.xml复制粘贴以下内容,添加到上面vim打开的core-site.xml 文件中:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
</configuration>配置hdfs-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/hdfs-site.xml复制粘贴以下内容,添加到到上面vim打开的hdfs-site.xml 文件中:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>配置yarn-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/yarn-site.xml复制粘贴以下内容,添加到到上面vim打开的yarn-site.xml 文件中:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>配置mapred-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/mapred-site.xml复制粘贴以下内容,添加到到上面vim打开的mapred-site.xml 文件中:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置workers 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/workers复制粘贴以下内容,添加到到上面vim打开的workers文件中:
slave01
slave02
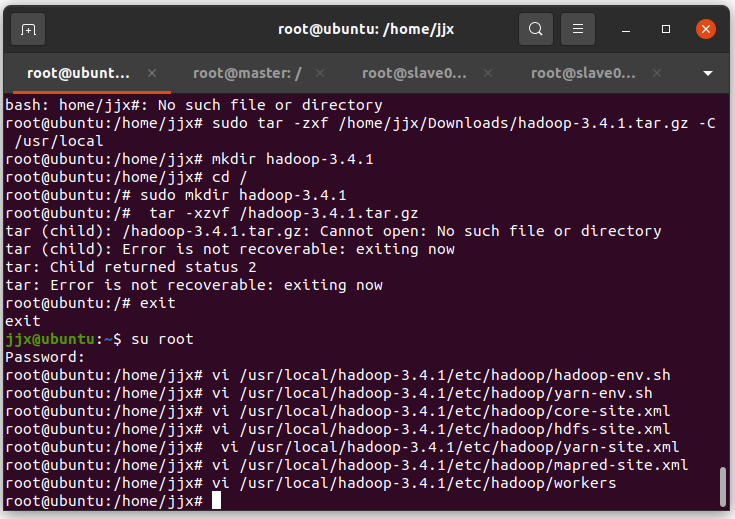
将配置好的hadoop-3.4.1文件夹复制到从节点
scp -r /usr/local/hadoop-3.4.1/ root@master:/
scp -r /usr/local/hadoop-3.4.1/ root@slave01:/
scp -r /usr/local/hadoop-3.4.1/ root@slave02:/如果输入密码错误:需要在从节点用 passwd root命令设置密码
如果显示无法连接错误:
安装 OpenSSH 服务端
apt update && apt install -y openssh-server启动 SSH 服务
service ssh start 配置 SSH
vi /etc/ssh/sshd_config添加:
PermitRootLogin yes # 允许 root 登录(仅测试环境)
PasswordAuthentication yes重启ssh服务:
service ssh restart 结果如下:
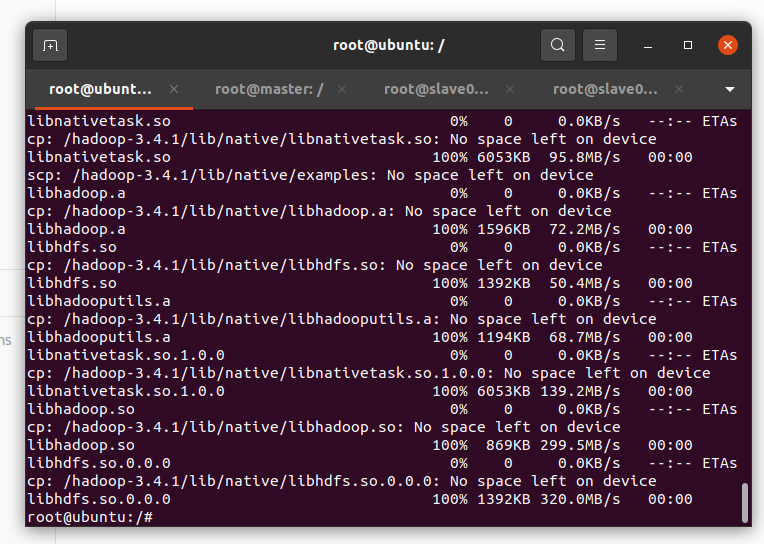
配置Hadoop环境变量(在三台节点分别操作此步骤)
vi ~/.bashrc在.bashrc末尾添加如下内容:
##HADOOP
export HADOOP_HOME=/hadoop-3.4.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH使环境变量生效
source ~/.bashrc 格式化Hadoop文件目录(在master上执行)
说明:格式化后首次执行此命令,提示输入y/n时,输入y。
hdfs namenode -format 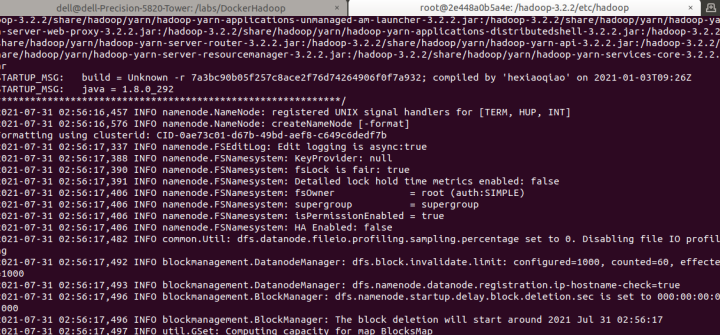
启动Hadoop集群(在master上执行):
start-all.sh查看Hadoop进程是否启动,在master的终端执行jps命令,出现下图效果
jps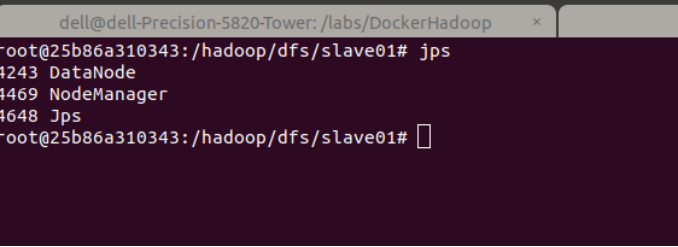
浏览器地址栏中输入http://127.0.0.1:9870/,检查namenode 和datanode 是否正常,如下图所示:
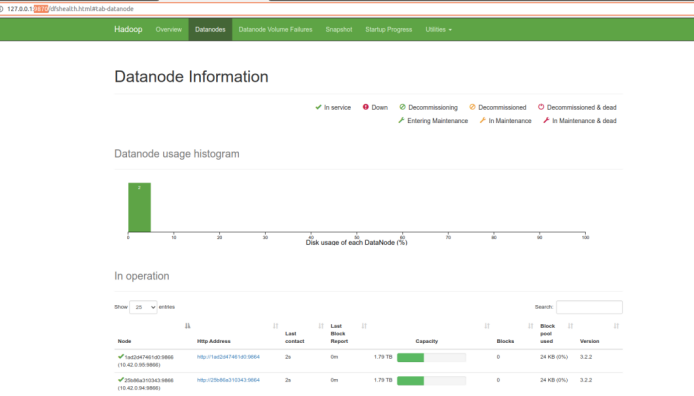
在浏览器地址栏中输入http://127.0.0.1:18088/,检查Yarn是否正常,如下图所示:
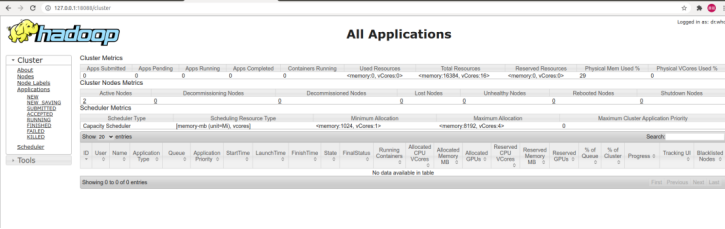
运行PI实例检查集群是否成功,成功如下图所示:
hadoop jar /hadoop-3.4.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar pi 10 10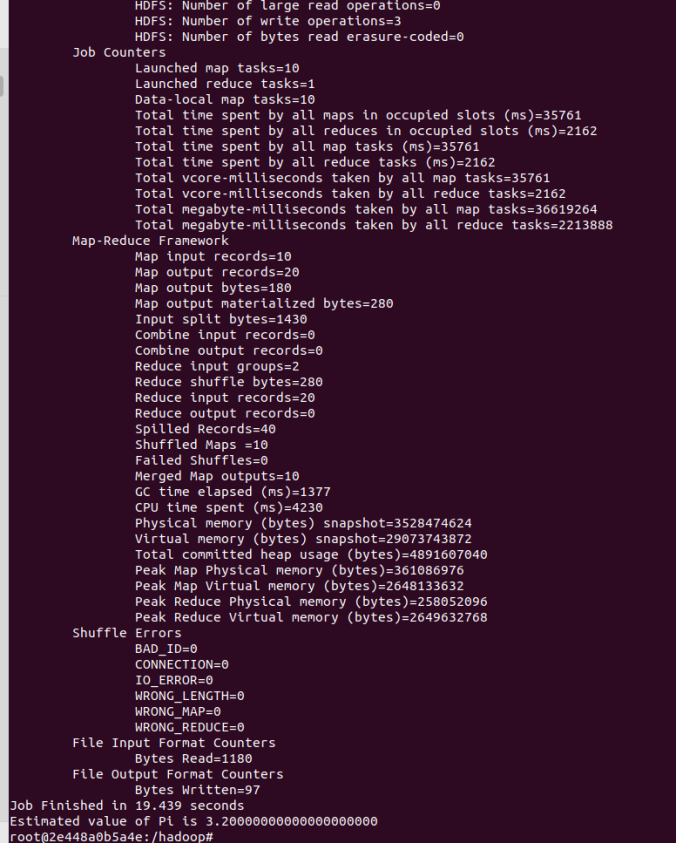
其他细节事项:
首先打开VMware虚拟机,进入Ubuntu操作系统,进入终端:
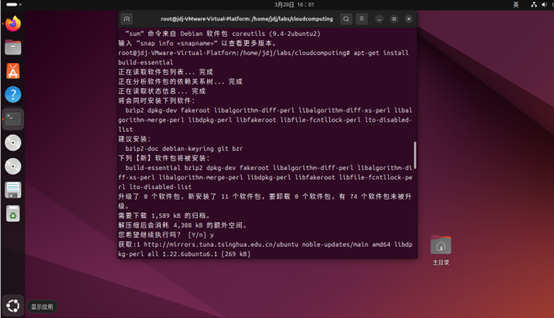
然后在终端切换到root用户:
设置 root 用户的密码:
sudo passwd root输入密码后切换到root模式:
su root在Linux安装软件时需要用到yum命令,也可以是apt-get命令,以下介绍如何在ubtuntu中安装配置yum
接下来是安装build-essential程序包和yum:
apt-get install build-essential
apt-get install yum在安装yum后可能会遇到以下报错:
E: Unable to locate package yum
这时候需要手动下载yum:
-
备份sources.list文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup
2.更换源
sudo vim /etc/apt/sources.list如果这个时候报错无法发现vim
sudo apt-get update
sudo apt-get install vim按照上述方式下载vim
3.vim编辑
接下来会进入到sources.list的内容里进行编辑
- 点击insert进入编辑模式
- 将下面网站文本复制粘贴并覆盖,粘贴的命令是 shift + insert。记得选择相应的Linux版本,此处为Ubuntu 20.04
在第一行添加镜像源如下:
deb http://archive.ubuntu.com/ubuntu/ trusty main universe restricted multiverse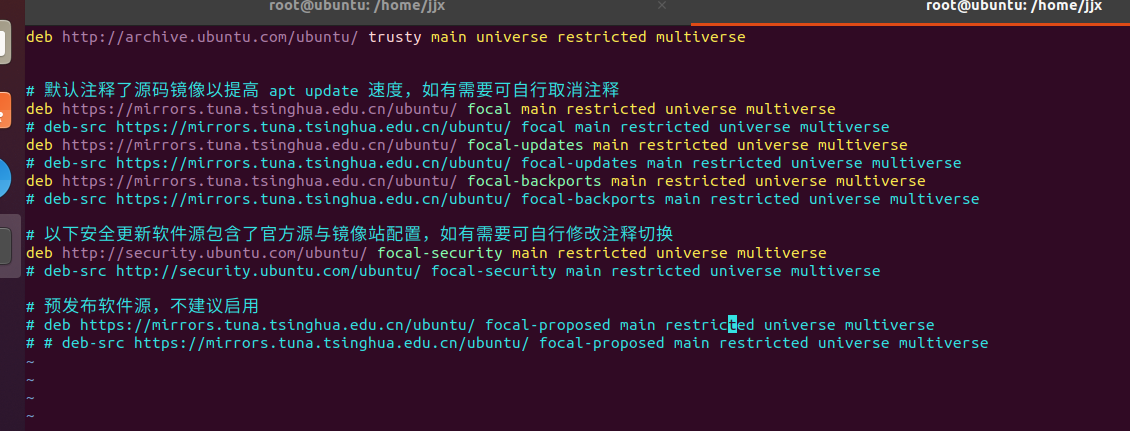
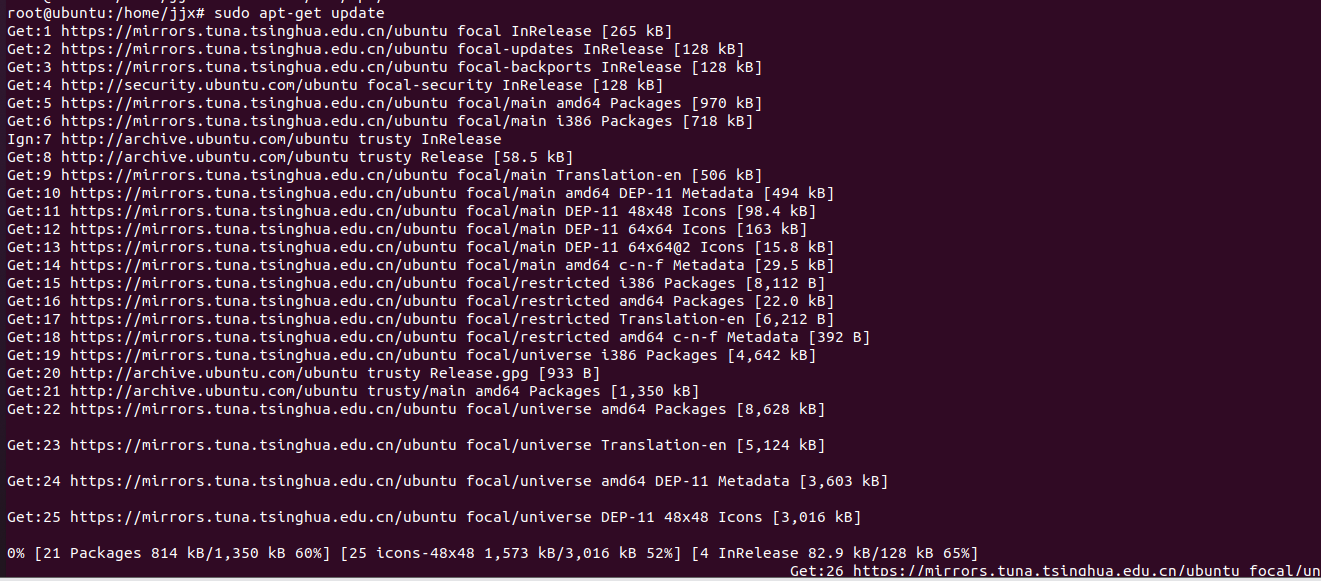 4.更新源
4.更新源
sudo apt-get update5.安装yum
sudo apt-get install yum然后如果有以下提示:
The following packages have unmet dependencies:
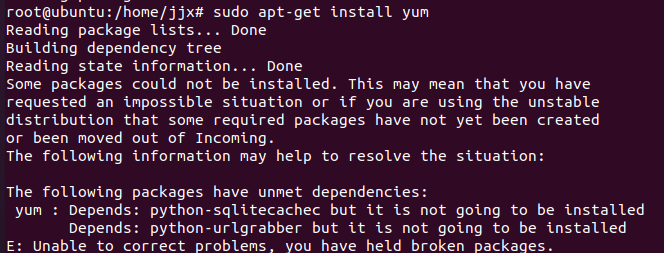
按照提示逐一安装依赖:
sudo apt-get install python-sqlitecachec
sudo apt-get install python-pycurl
sudo apt-get install python-urlgrabber再次安装yum:
sudo apt-get install yum 安装yum成功:
yum --version
最后将自己配置的repo文件用yum-config-manager进行yum软件源添加:
yum-config-manager --add-repo /etc/yum.repo.d/my.repo 通过使用yum repolist命令查看时,由于刚下载yum,显示库的软件信息为0
这时需要配置yum源
参考这篇博主的文章:
好了之后就可以安装了
yum upgrade
yum install net-tools设置root密码
在docker容器内,初始化root密码,用于下一步的登录。
passwd root