TPAMI---BEV感知综述
- 一、文章基本信息
- 二、背景介绍
-
- [1. 3D感知](#1. 3D感知)
- [2. BEV感知](#2. BEV感知)
- [3. 常用数据集与评价指标](#3. 常用数据集与评价指标)
- 三、方法介绍
-
- [1. BEV Camera](#1. BEV Camera)
- [2. BEV LiDAR](#2. BEV LiDAR)
- [3. BEV Fusion](#3. BEV Fusion)
- [4. 工业界视角](#4. 工业界视角)
- 四、使用指南
-
- [1. 数据增强](#1. 数据增强)
- [2. BEV 编码器](#2. BEV 编码器)
- [3. 损失函数](#3. 损失函数)
- [4. 未来可能的研究方向](#4. 未来可能的研究方向)
- 五、文章总结
一、文章基本信息
| 标题 | Delving into the devils of bird's-eye-view perception: a review, evaluation and recipe^[1](#标题 Delving into the devils of bird’s-eye-view perception: a review, evaluation and recipe1 期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence (IF=20.4) 作者 Hongyang Li; Chonghao Sima; Jiefeng Dai 等 主要单位 Shanghai Artificial Intelligence Laboratory (上海AI Lab) 关键词 3D detection and segmentation; autonomous driving challenge; bird’s-eye-view perception 日期 收稿日期:2022年9月13日;接收日期:2023年11月4日 文章链接 https://ieeexplore.ieee.org/abstract/document/10321736 附录链接 https://ieeexplore.ieee.org/ielx7/34/10461350/10321736/supp1-3333838.pdf?arnumber=10321736)^ |
|---|---|
| 期刊 | IEEE Transactions on Pattern Analysis and Machine Intelligence (IF=20.4) |
| 作者 | Hongyang Li; Chonghao Sima; Jiefeng Dai 等 |
| 主要单位 | Shanghai Artificial Intelligence Laboratory (上海AI Lab) |
| 关键词 | 3D detection and segmentation; autonomous driving challenge; bird's-eye-view perception |
| 日期 | 收稿日期:2022年9月13日;接收日期:2023年11月4日 |
| 文章链接 | https://ieeexplore.ieee.org/abstract/document/10321736 |
| 附录链接 | https://ieeexplore.ieee.org/ielx7/34/10461350/10321736/supp1-3333838.pdf?arnumber=10321736 |

|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 文章摘要: 鸟瞰视图(BEV)强大的学习表征能力已成为感知任务的主流表征视图,并吸引了工业界与学术界的广泛关注。大部分实现自动驾驶目标监测、语义分割、追踪任务的传统算法都是在前向视图或透视试图中进行的。然而,随着传感器的配置越来越复杂,从不同传感器融合多源信息,以及在对不同传感器数据进行统一表征变得越来越重要。BEV感知的本质优点,使得其能直观地表示周围场景、方便多传感器数据融合。此外,在BEV空间中表征目标,能为感知的下游任务------规划和控制提供极大的便利。目前,BEV感知主要需要考虑四个核心问题如下:1) 如何通过从透视视图到BEV视图的视图转换来重建丢失的3D信息 ; 2)如何在BEV网格中获取真实标注数据;3)如何设计标准化流程来融合不同来源和视图的特征;4)如何使算法能够适应不同场景下传感器配置的变化。 在本综述中,作者总结了最近关于BEV感知的很多工作,并且对于不同的解决办法提供了深入的分析。此外,作者也讨论了工业界关于BEV表征的看法及用法。同时,本文还介绍了提升BEV感知任务的性能的实践手册,包括相机、激光雷达以及融合的数据输入。最后,作者们指出了该领域未来可能的方向。 |
二、背景介绍
1. 3D感知
自动驾驶中的感知任务的本质是对物理世界的3D几何信息重建。根据感知任务和传感器的不同,包括:基于单目相机的3D目标检测、基于激光雷达(LiDAR)的3D目标检测与语义分割和多模态传感器融合,三大类方法。
- 基于相机的单目3D检测:主要的挑战在于RGB图像缺乏深度信息,从单一图片估计深度本身就是一个病态问题,所以其性能会劣于基于LiDAR的算法。
- 基于雷达的检测与划分:雷达数据是一系列3D空间中的点,可以捕捉目标的几何信息,尤其是深度信息,能很好地实现自动驾驶目标的3D检测。
- 多模态传感器融合:目前自动驾驶中常用的传感器包括相机、激光雷达、毫米波雷达、IMU、GPS,他们各有优缺点,融合策略综合这些传感器进行互补。
2. BEV感知
随着在自动驾驶汽车上装备的传感器的类型与数量越来越多,在同一个空间表征不同视觉的特征变得越来越重要。被大家所熟知的BEV,能够自然地、直观地表征统一的3D空间,因此成为工业界和学术界的候选视图空间。与在2D视角领域被广泛关注的前向视角和透视视角相比,BEV表征有以下两个主要优点:1)没有2D图像中普遍存在的遮挡和尺度变化问题;2)BEV视图中的物体表征很适合后续模块(P& C)的开发与部署。
基于输入数据,作者将BEV感知分为了三类:
- BEV Camera:指仅通过单个相机视角和以相机视角为中心的算法从多个相机完成3D目标检测和语义分割任务
- BEV LiDAR:指通过点云的输入完成3D目标检测和分割任务
- BEV Fusion:指通过多个传感器(camera, LiDAR, GNSS, odemetry, HD-Map)的输入来完成融合任务
3. 常用数据集与评价指标
作者总结了现有的一些数据集,对于BEV感知任务而言,需要的主要数据集配置包括:1)3D检测框的标注信息;2)3D语义分割的标注信息;3)高精地图。
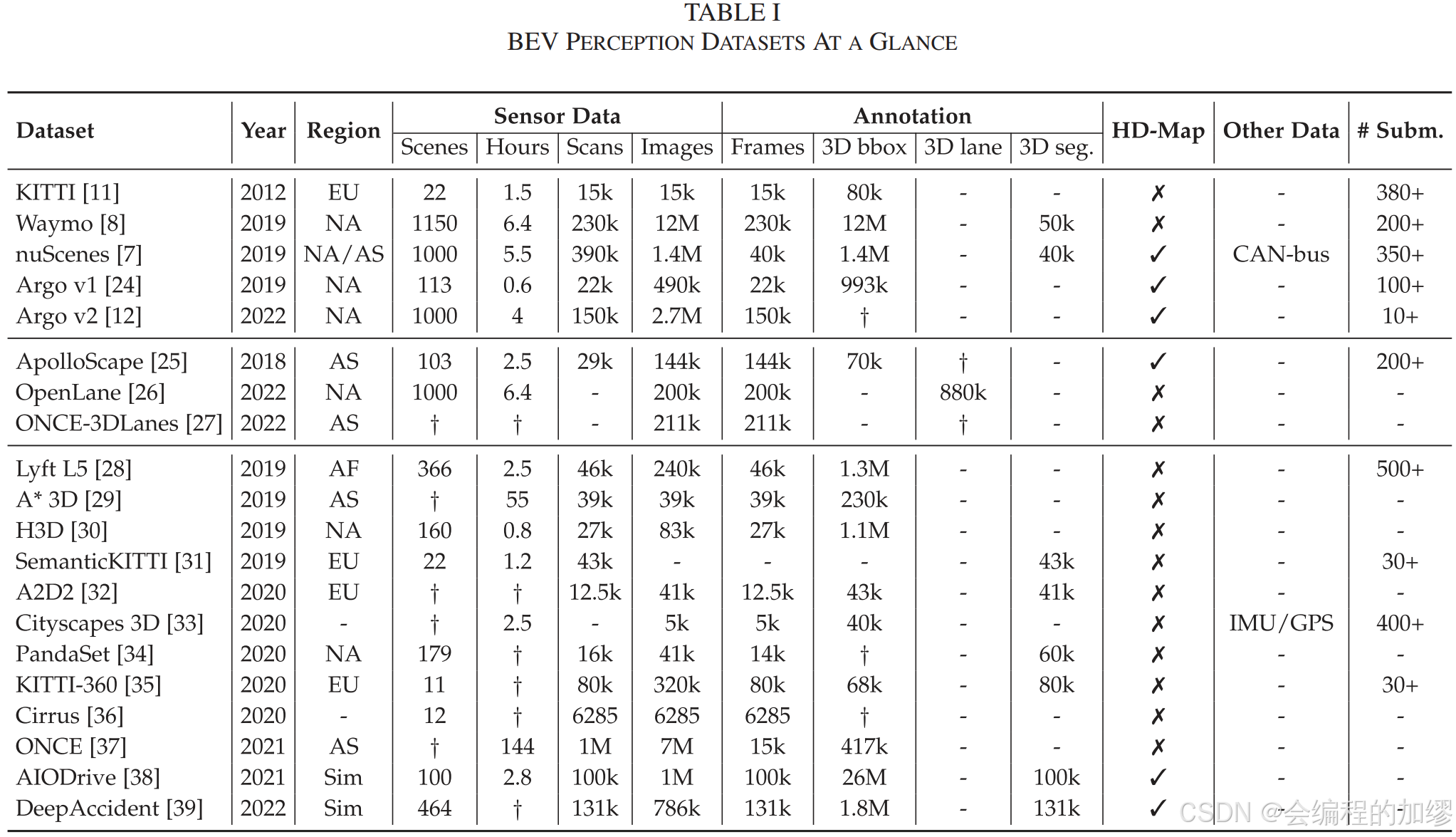
其中,自动驾驶感知任务中,最有名的三个数据集分别是:KITTI[2](#2),Waymo[3](#3) 和 nuScenes[4](#4)(文末给出了3个数据集官网链接,感兴趣的朋友可以去探索!)
值得一提的是2019年发布nuScenes数据集,直接推动了BEV感知的研究发展。最主要的原因在于,nuScenes通过车辆周围的6个相机传感器采集了周围6个方位的图像信息,这使得研究者们思考如何根据6个方位的图片信息构建自动驾驶汽车周围的环境。因此,推动了BEV感知的研究。
BEV感知中常用的几个算法评价指标:
| 评价指标 | 公式 | 说明 |
|---|---|---|
| LET-3D-APL | L E T 3 D A P L = ∫ 0 1 p L ( r ) d r = ∫ 0 1 a l ˉ ⋅ p ( r ) d r LET3DAPL =\int_{0}^{1}p_{L}(r)dr = \int_{0}^{1}\bar{a_l}\cdot p(r)dr LET3DAPL=∫01pL(r)dr=∫01alˉ⋅p(r)dr | 利用坐标类似量化精度来惩罚纵向误差 |
| mAP | m A P = A P 0.5 + A P 1 + A P 2 + A P 4 4 mAP=\frac{AP_{0.5}+AP_{1}+AP_{2}+AP_{4}}{4} mAP=4AP0.5+AP1+AP2+AP4 | AP值是在不同距离阈值下计算的,mAP就是计算不同阈值距离下AP的平均值 |
| NDS | T P s c o r e = m a x ( 1 − T P e r r o r , 0.0 ) TP_{score}=max(1-TP_{error}, 0.0) TPscore=max(1−TPerror,0.0) N D S = 5 ⋅ m A P + ∑ i = 1 5 T P s c o r e i 10 NDS = \frac{5 \cdot mAP+\sum_{i=1}^{5}TP_{score}^{i}}{10} NDS=105⋅mAP+∑i=15TPscorei | NDS是多个指标的联合,mAP、mATE、mASE、mAOE、mAVE、mAAE,其中给mAP的权重为0.5,其余为0.1 |
三、方法介绍
基于不同的输入模态,将BEV感知算法分为了三类,包括BEV Camera (camera-only 3D perception)、BEV LiDAR和BEV Fusion。同时,作者还从工业界的角度详细分析了BEV感知算法的每个模块。
1. BEV Camera
纯视觉的方案最核心的问题在于:2D图像无法获取物体3D信息。因为没有准确的深度信息,这阻碍了精确的目标定位。基于相机的方法可以分为:单目、双目、多相机设置。 多相机设置往往是从单目开始的(如nuScenes)
通用的纯相机检测的流程包括三个部分:2D feature extractor, view transformation moduel (optional) and 3D decoder(解码器)
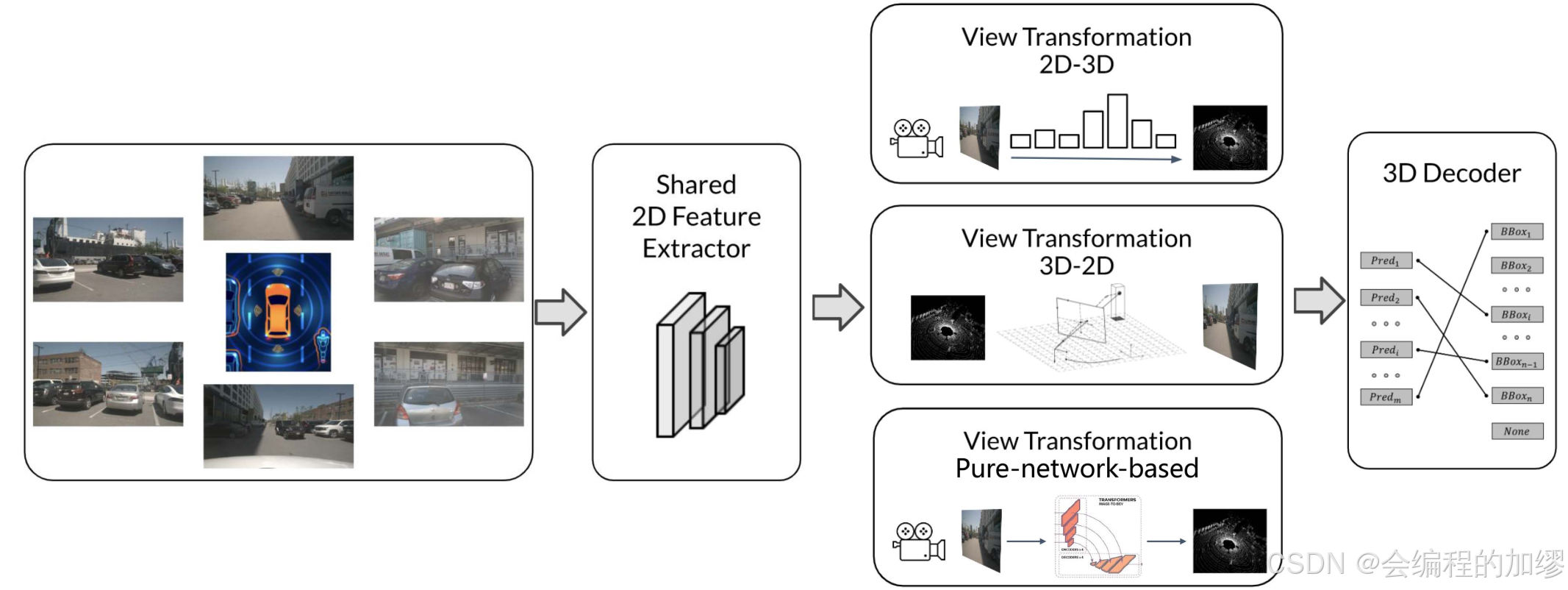
- 2D特征提取器:因为输入和2D目标检测一样,这里可以直接用2D目标检测中的特征提取器来进行2D特征提取;
- ⭐视角转换模块:这一部分与2D目标检测很不同,包括预测像素深度分布、3D-2D反向透视映射和纯神经网络映射三种转换方式。但是并不是所有算法都需要视角转换模块(如SMOKE)
- 3D解码器 :大部分3D解码器主要来源于基于激光雷达的算法,3D解码器接受2D/3D空间的特征,并输出3D感知结果,例如:3D检测框、BEV地图划分、3D车道关键点等等
2. BEV LiDAR
基于LiDAR的方法通过提取点云特征,再转换为BEV的方式获取目标特征, 最后通过检测头生成3D结果。根据特征提取部分位置的不同,分成了Pre-BEV和Post-BEV:
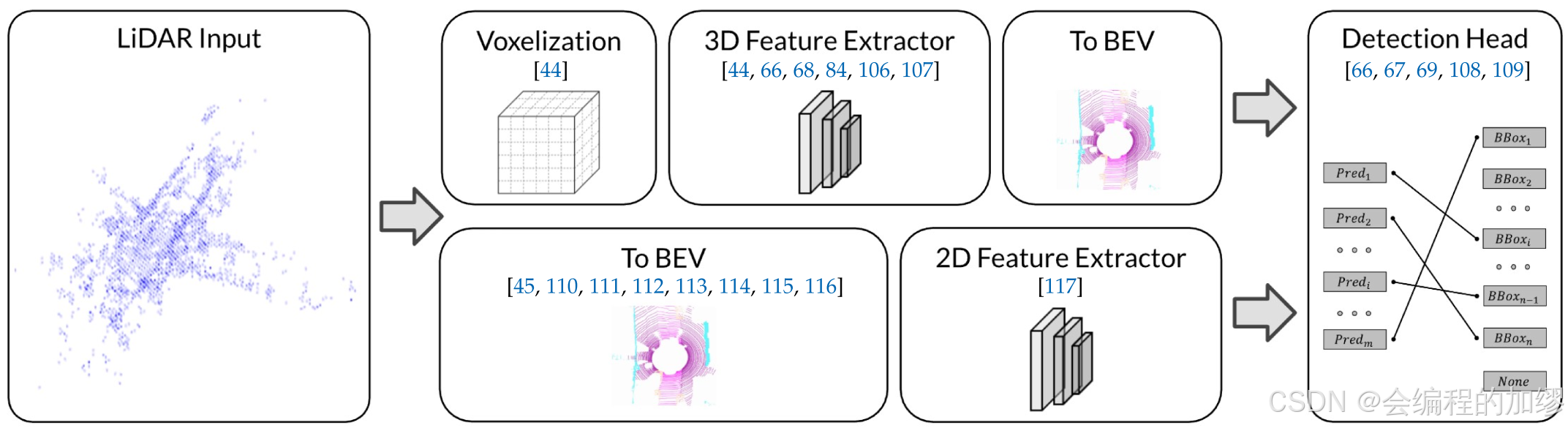
Pre-BEV: 先通过体素化,将连续的3D坐标转换为离散的坐标以增强其表示能力,再通过3D卷积或3D稀疏卷积来提取点云特征,再通过密度增加(densifying)或压缩高度轴来将3D体素特征格式化为2D张量。例如,SECOND算法:
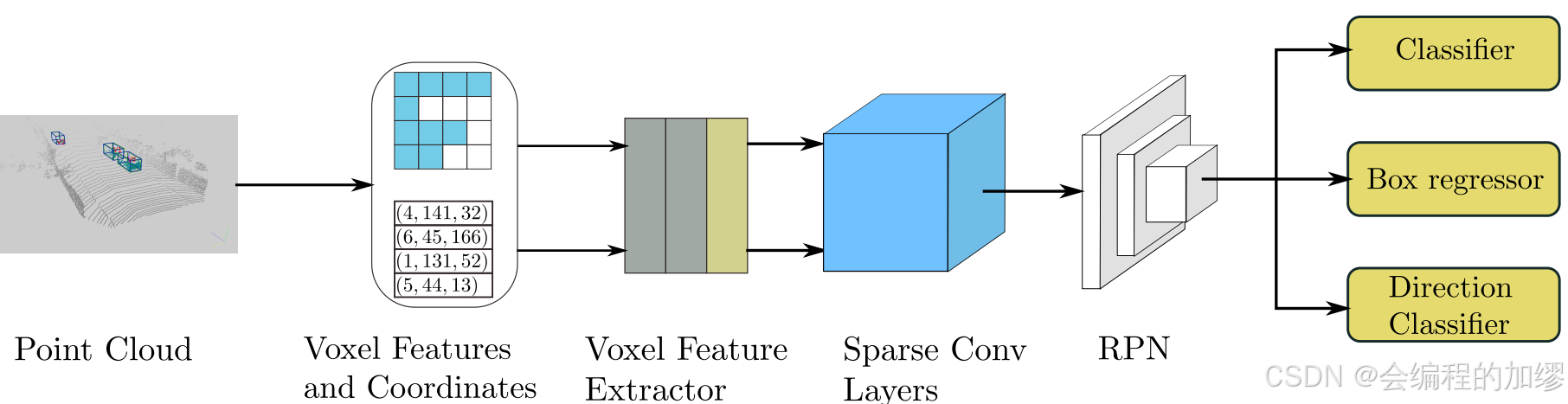
Post-BEV: 体素在3D空间中是稀疏的和不规则的,应用3D卷积效率不高,工业应用中使用3D卷积效率不高,MV3D第一次直接将点云数据转换为BEV特征。还有pointpillars也是采用的类似的设计(Pillar是将点云抽象为一种高度不受限的特殊体素)。其中,poIntpillars算法架构如下:
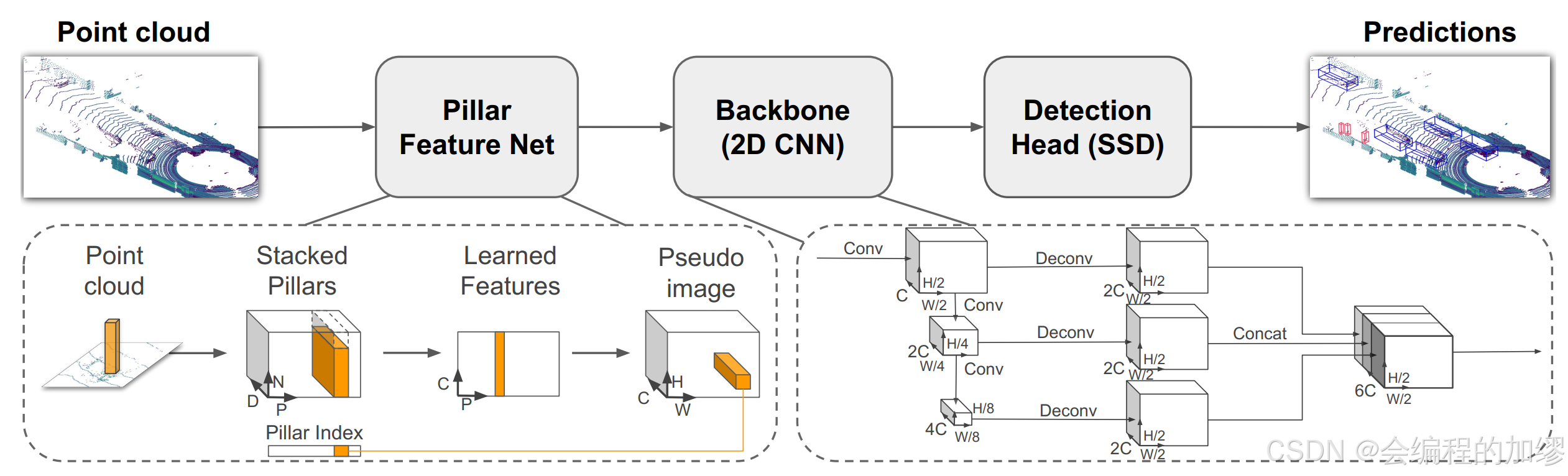
3. BEV Fusion
因为视觉和雷达各有特点,所以有工作考虑将图像和点云数据进行融合,根据融合时间(步骤)的差异分为了两种流程,流程b是较为普遍的方法,现在各自视角下提取BEV特征,然后再将两个的BEV特征融合(我的博客分享的BEVFusion-mit)。
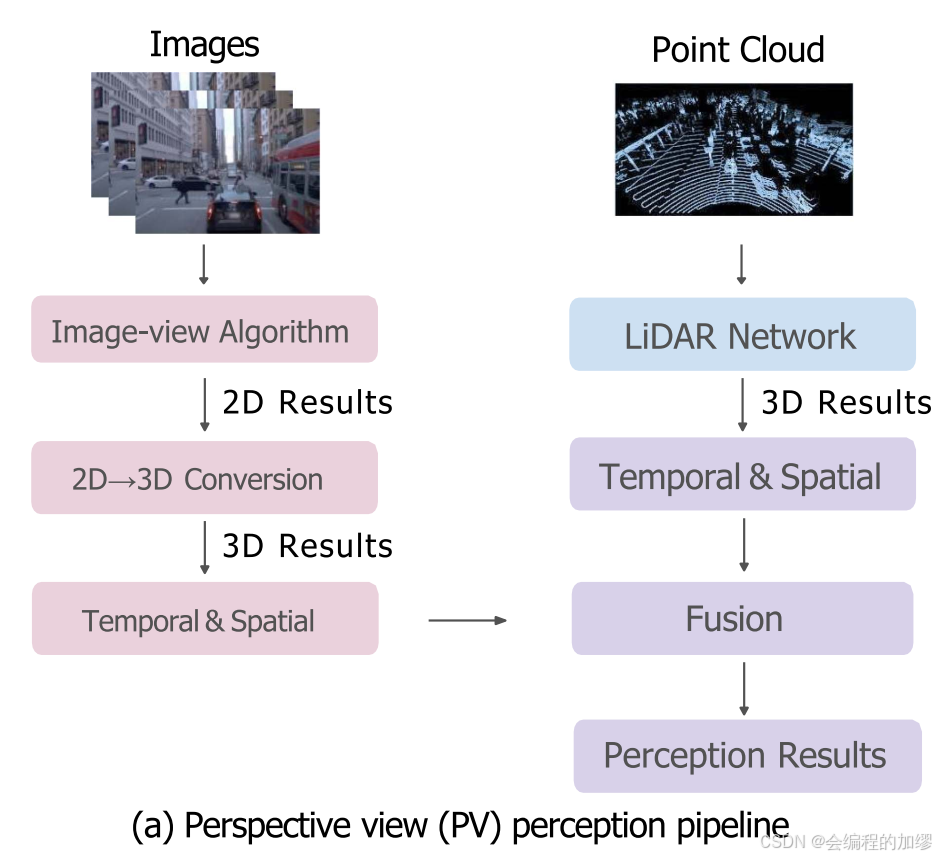
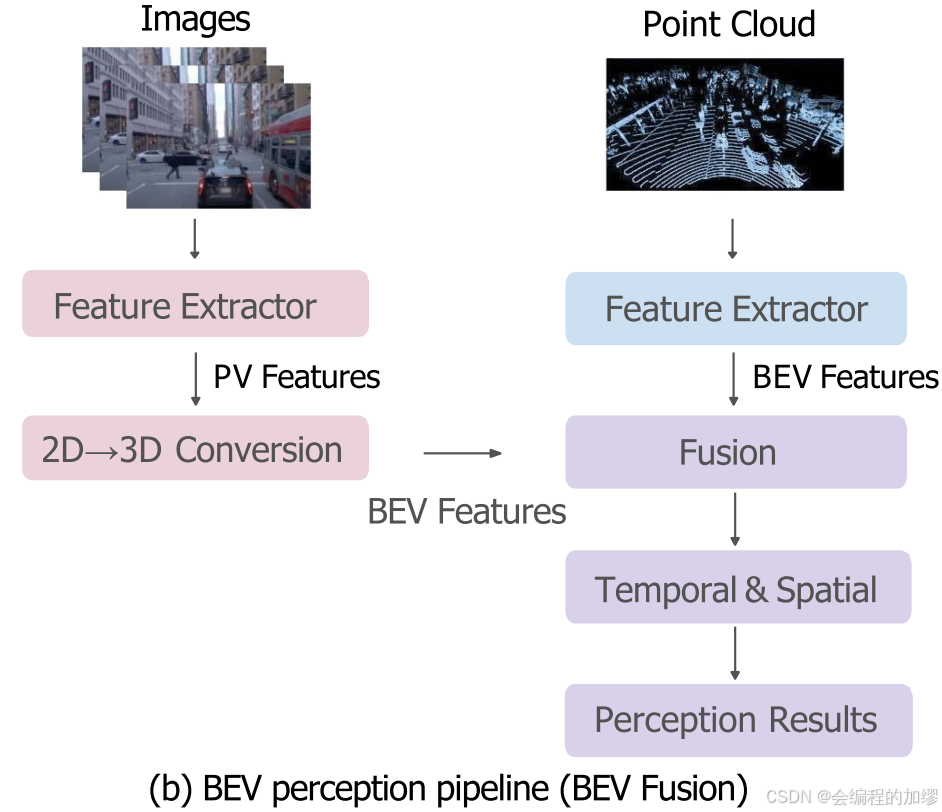
逆透视映射是3D to 2D的方法,尽管因为地平面假设可能不太精确,但它为在BEV空间下融合图像和点云提供了一种可能。LSS是第一个预测图像特征深度的方法,引入了神经网络来解决图像到点云转换的病态问题。其他方法通过不同的方式来进行视角转换。上图展示了两个不同的提取和融合思路。
4. 工业界视角
作者根据现有的工业界的方法,以BEV感知算法的每一个模块为关键点,梳理了目前工业界的常用方法:
- 输入数据: 相机、激光雷达、毫米波雷达、IMU、GPS
- 特征提取器:该模块一般由主干网络和颈部(neck)组成,主干网络包括ResNet等,neck网络包括FPN(特征金字塔网络)等
- 视角转换转换:透视视图转换为BEV视角主要包括四种方法:固定的逆向透视映射(IPM),自适应的逆向透视映射(Adaptive IPM),Transformer,(伪激光雷达)ViDAR
四、使用指南
作者基于他们在Waymo Open challenge 2022的参赛作品BEVFormer++纯视觉的目标检测,和SPVCNN来分析激光雷达语义分割两个项目的经验,来讨论以下几个方面的实践经验:
- Data augmentation
- BEV encoder
- Loss function
1. 数据增强
适合BEV任务的纯视觉图像数据的增强方法:
(一些非仿射变换的方法不适合,如复制粘贴copy-paste、马赛克Mosaic)
| 方法英文 | 中文 | 具体操作 |
|---|---|---|
| color jitter | 颜色抖动 | |
| flip | 翻转 | flipped by a ratio of 0.5 |
| resize | 多尺度缩放 | 放缩因子:0.5~1.2 |
| rotation | 旋转 | |
| crop | 裁剪 | |
| Grid Mask | 网格掩蔽 | 随机遮挡: 全部区域的30% |
雷达数据增强:
| 方法英文 | 中文 | 具体操作 |
|---|---|---|
| random rotation | 随机旋转 | 随机旋转角度选择范围:[0, 2Π) ------旋转是对每一个点运用 |
| scaling | 缩放 | 缩放因子0.9, 1.1------在点云坐标系上多重运用 |
| flipping | 翻转 | 随机翻转运用在X轴/Y轴/XY轴 |
| point translation | 点的平移 | 用均值为0方差为0.1的正态分布来平移 |
2. BEV 编码器
BEV编码器除了有多个卷积结构的注意力编码器层,还有定制的BEV查询、空间交叉注意力和时间自注意力。主要分析了提高BEV编码器质量的三个方面:
- 2D特征提取器
- 视角转换
- 时间维度BEV融合
3. 损失函数
基于相机的目标检测:BEV空间的有点使其不仅可以用2D目标检测的损失函数也可以用3D目标检测的损失函数。同时还有的研究通过深度监督来进行辅助的损失计算,提高了单目相机3D检测的性能,如BEVDepth。
基于激光雷达的语义分割:研究者们在激光雷达语义分割任务中常用的损失函数包括交叉熵损失、Geo损失和Lovasz损失。
4. 未来可能的研究方向
作者通过综述了大量的文章,对未来的研究方向提出了一些参考建议,主要包括四个可能的研究问题:
- 1)如何设计出更精确的深度估计模块?
- 2)如何在一种新颖的融合机制中更好地对齐来自多个传感器的特征表示?
- 3)如何设计一个无参数网络,使得算法性能不受姿态变化或传感器位置的影响,从而在各种场景中实现更好的泛化能力?
- 4)如何整合基础模型中成功的知识来推动鸟瞰视图感知的发展?
五、文章总结
该文章以极其清晰的逻辑和严谨的用词梳理了BEV视图在自动驾驶目标检测中的重要性、现有研究基础及未来研究方向。通过详细的图解示意了BEV Camera, BEV LiDAR和BEV Fusion的具体转换过程,十分有助于读者理解基于BEV的3D目标检测。此外,作者还根据自身实际研究经验,对BEV感知的各个模块进行分析与解读,为学术界和工业界都提供了详细的指导。强烈推荐感兴趣的小伙伴们去阅读原文!
该文章是我最近读过最好的一篇综述!如总结方面有纰漏,欢迎大家交流讨论!