From words to routes: Applying large language models to vehicle routing
https://sites.google.com/view/words-to-routes/
从词汇到路径:大语言模型在车辆路线规划中的应用
1. 研究内容
1.1. 背景
- 大型语言模型(LLMs)在机器人领域的应用:近年来,LLMs在机器人任务(如机械臂操作和导航)中表现出了显著的进步,尤其是在处理自然语言(NL)任务描述时。这种成功促使研究者探索LLMs在解决车辆路径问题(Vehicle Routing Problems, VRPs)中的潜力。
- VRPs的复杂性:VRPs是一类经典的组合优化问题,涉及为车辆规划最优路径以满足特定约束(如时间窗、容量限制等)。传统方法通常依赖数学建模和专用求解器(如Gurobi),但这些方法需要专家知识,难以直接处理自然语言描述的任务。
- 现有研究的局限性:目前针对VRPs使用LLMs的研究非常有限。已有工作通常结合了初始解、启发式算法或额外数据(如XML),而不是仅依赖自然语言描述。此外,这些方法在复杂VRPs(如带时间窗的TSP)上的表现受限,且对初始解的依赖性较强。
- NL描述的挑战:用户提供的自然语言任务描述可能不完整或缺乏细节,这对LLMs的性能有显著影响。如何处理不完整的描述是一个关键问题。
1.2. 研究目标
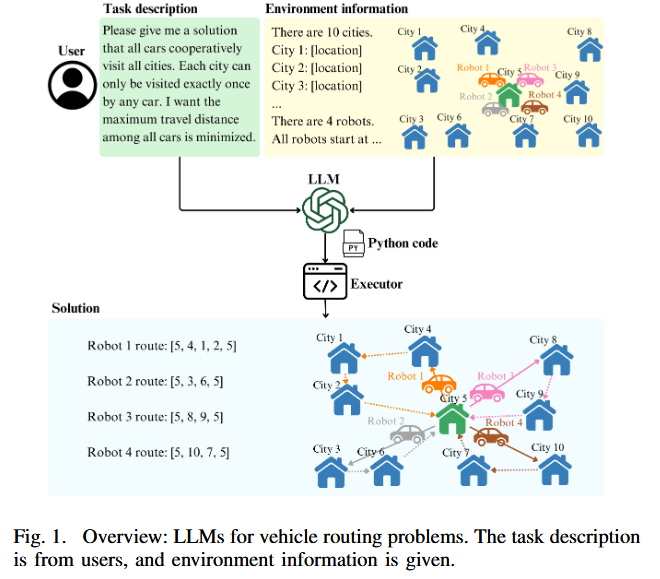
主要目标:
- 探索LLMs在VRPs中的能力 :研究LLMs在仅依赖自然语言任务描述的情况下解决VRPs的能力,具体通过生成Python代码来实现路径规划。
- 构建VRP数据集:创建了一个包含多种VRP变体的基准数据集,包含自然语言任务描述和对应解,用于评估LLMs的性能。
- 提出改进框架:设计了一个框架,通过自我调试和自我验证机制提升LLMs生成代码的质量,特别是在处理复杂VRPs时。
- 研究NL描述的敏感性:分析不完整或缺乏细节的自然语言任务描述对LLMs性能的影响,并提出改进机制以生成更全面的任务描述。
- 比较不同提示范式:评估四种不同的提示范式(prompt paradigms),确定哪种方法最适合LLMs解决VRPs。
具体贡献:
- 构建了一个包含21种VRP变体(10种单车辆、11种多车辆)的数据集。
- 证明直接使用自然语言描述生成Python代码无需微调即可获得最佳性能(GPT-4在数据集上实现56%可行性、40%最优性、53%效率)。
- 提出了一个框架,通过自我调试和验证提升GPT-4性能(可行性+16%、最优性+7%、效率+15%)。
- 提出了一个机制,通过与用户交互生成更详细的自然语言描述,以应对不完整的任务描述。
2. 研究方法
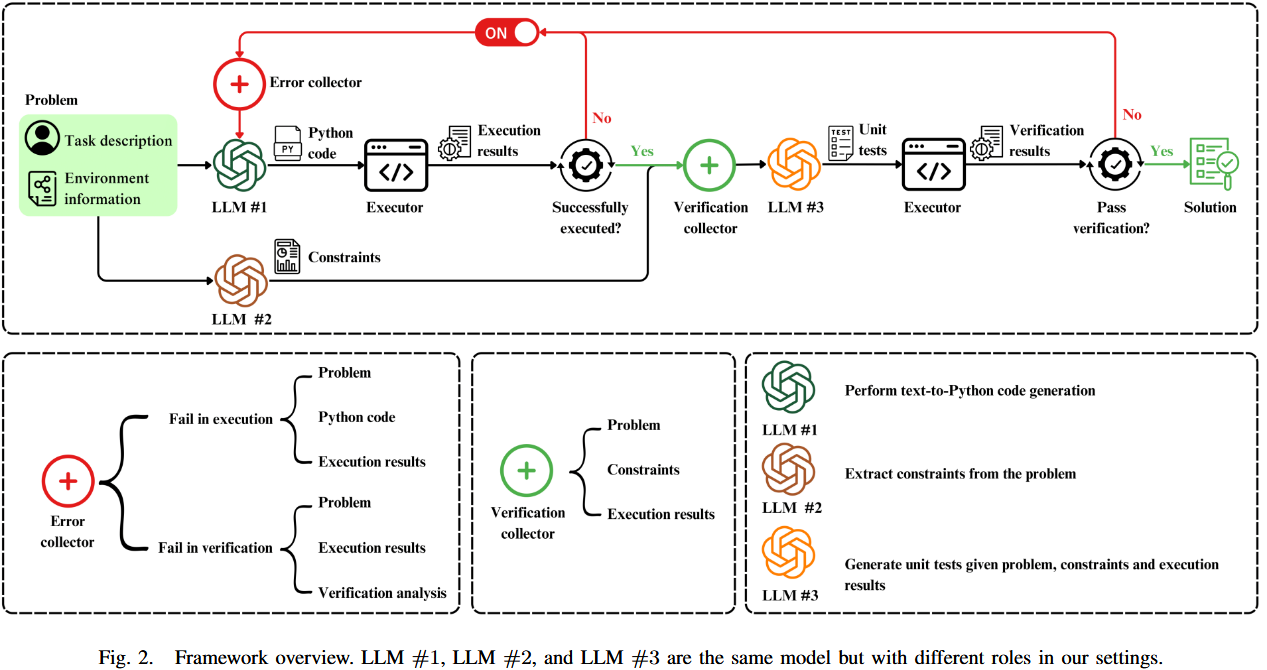
2.1. 方法概述:
论文提出了一种基于LLMs的框架,用于从自然语言描述生成Python代码解决VRPs,并通过自我调试和验证机制改进代码质量。方法分为以下几个部分:
-
四种基本提示范式:
- 范式1:直接从自然语言任务描述生成Python代码。
- 范式2:将自然语言描述翻译成数学公式,然后基于数学公式生成Python代码。
- 范式3:从自然语言描述生成Python代码,同时指定使用外部求解器或库(如Gurobi)。
- 范式4:将自然语言描述翻译成数学公式,基于数学公式生成Python代码,并指定使用外部求解器或库。
- 这些范式的设计源于对人类解决VRPs的思考:人类通常将问题转化为数学公式并使用外部求解器。研究者想探究这些方法是否对LLMs同样有效。
-
自我调试与验证框架:
- 框架概述 :如图2所示,框架涉及三个LLM角色(同一模型不同任务):
- 代码生成:根据自然语言描述生成Python代码。
- 自我调试:如果代码执行失败,结合任务描述、代码和错误追踪(traceback)重新生成代码。
- 自我验证:如果代码执行成功,提取任务描述中的约束,生成单元单元测试验证解的正确性。若测试失败,结合描述、执行结果和验证分析重新生成代码。
- 最大反思次数:最多进行6次代码反思(code reflection)。
- 单元测试生成:从任务描述中提取约束(如"车辆必须恰好访问每个城市一次"),生成单元测试以验证解是否满足约束。
- 框架概述 :如图2所示,框架涉及三个LLM角色(同一模型不同任务):
-
处理不完整NL描述:
- 提出一种机制:通过与用户交互生成更详细的任务描述,弥补不完整描述的不足。
-
数据集构建:
-
单车辆TSP(10种任务,如图3) :
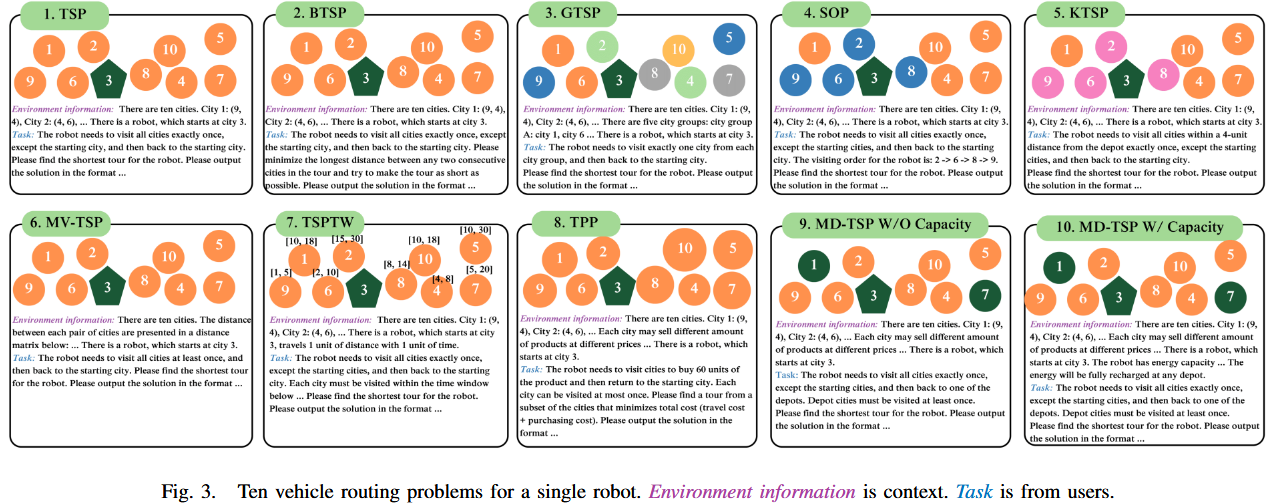
- 包括经典TSP、瓶颈TSP(BTSP)、广义TSP(GTSP)、顺序排序问题(SOP)、K-TSP、多访问TSP(MV-TSP)、带时间窗TSP(TSPTW)、旅行购买问题(TPP)、多仓库TSP(MD-TSP,无容量/有容量)。
-
多车辆TSP(11种任务,如图4) :

- 包括多车辆TSP(MTSP)、瓶颈MTSP(BMTSP)、广义MTSP(GMTSP)、顺序排序问题(MSOP)、K-MTSP、多访问MTSP(MV-MTSP)、带时间窗MTSP(MTSPTW)、旅行购买问题(MTPP)、多仓库MTSP(MD-MTSP,无容量/有容量)、彩色MTSP。
-
数据集包含自然语言任务描述和对应解,用于评估LLMs。
-
3. 实验
3.1. 实验设置:
- 评估指标 :
- 可行性(Feasibility):所有解中可行解的比例。
- 最优性(Optimality):所有解中最优解的比例。
- 效率(Efficiency):所有解的归一化得分平均值(错误解得0,最优解得1)。
- 使用的LLMs :
- GPT-4(gpt-4-0125-preview)。
- Gemini 1.0 Pro(gemini-1.0-pro-001)。
- 实验任务:在包含21种VRP变体的数据集上进行测试,每种任务单独评估10次。
3.2. 实验问题以及结果:
-
哪种提示范式最佳?:
-
实验设计:在不使用框架的情况下,测试四种提示范式对GPT-4和Gemini 1.0 Pro的性能。
-
结果 (如图5):
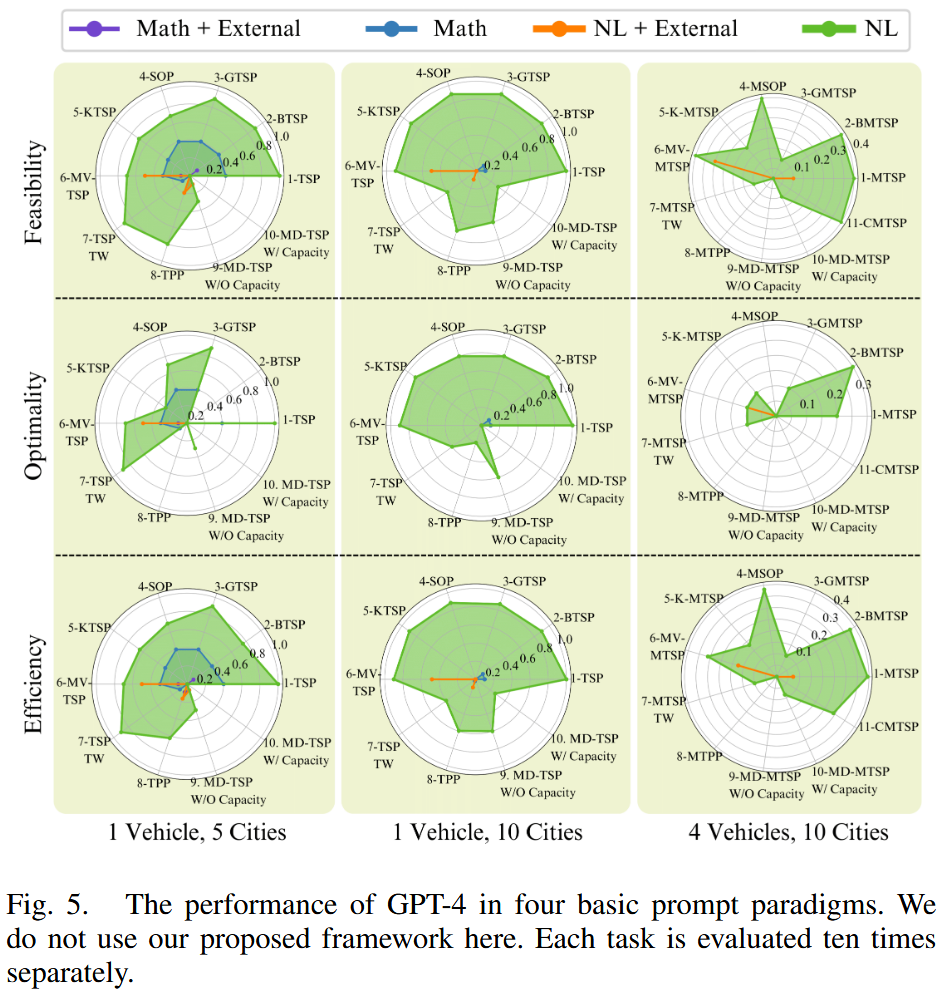
- GPT-4:直接使用自然语言描述(范式1)表现最佳。使用外部求解器(如Gurobi)的范式(3和4)表现较差,因为生成的代码大多有bug且不可执行。基于数学公式的范式(2和4)性能下降,因为GPT-4在翻译自然语言到数学公式时约50%会丢失城市位置信息。
- Gemini 1.0 Pro:90%以上的生成代码有bug且不可执行,剩余代码提供错误解,仅有1%概率生成正确解,表明Gemini 1.0 Pro在初始尝试中无法有效解决VRPs。
-
-
提出的框架性能如何?:
- 实验设计:在四种提示范式下测试提出的框架,最大反思次数设为6。评估GPT-4和Gemini 1.0 Pro的性能。
- 结果 :
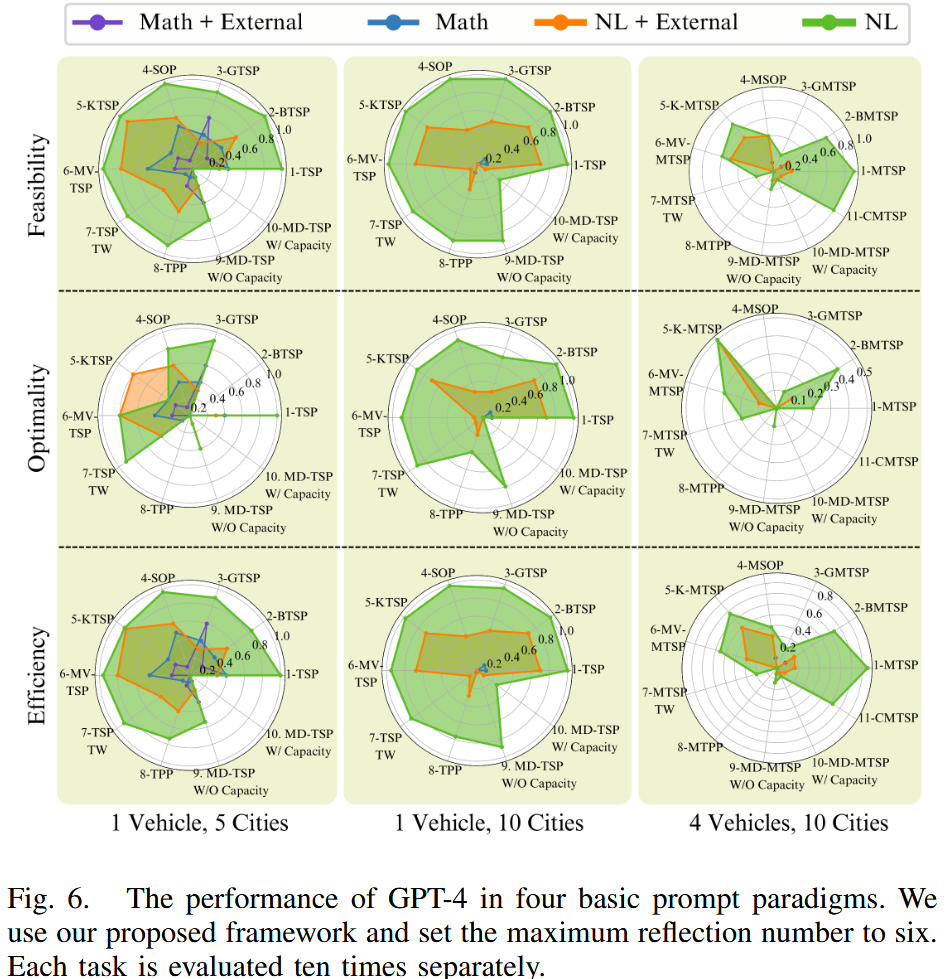
- GPT-4 (如图6):
-
直接使用自然语言描述的范式仍表现最佳。
-
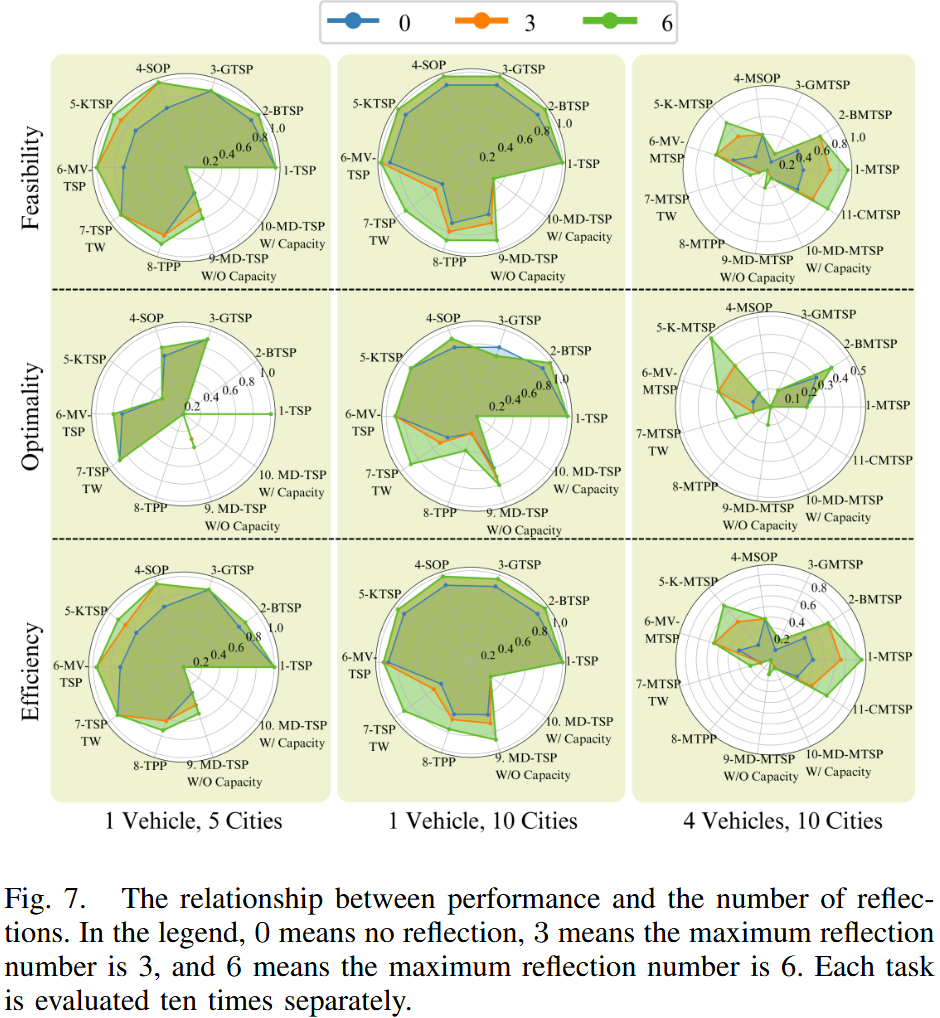
如图7和表I所示,框架随着反思次数增加(0→3→6)显著提升性能:
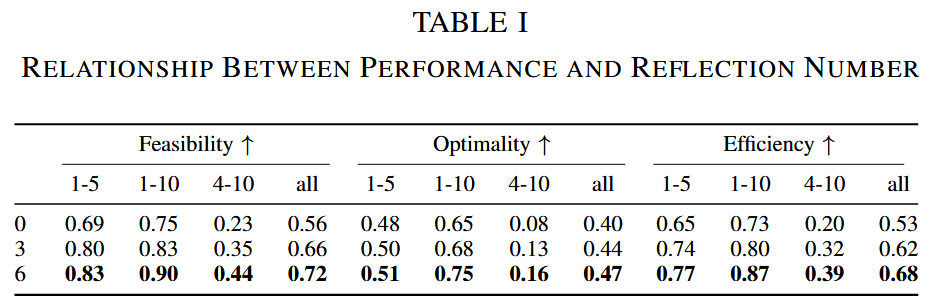
- 反思次数为3时:可行性+10%、最优性+4%、效率+9%。
- 反思次数为6时:可行性+16%、最优性+7%、效率+15%。
-
- Gemini 1.0 Pro:框架未改善性能,表明Gemini 1.0 Pro无法修复代码中的bug或纠正错误解。
- 关键发现 :
- 不一致性:GPT-4在单车辆、五城市环境中的表现不如单车辆、十城市环境,表明性能不稳定。
- 反思的局限性:在GTSP任务中(单车辆、十城市),反思可能导致性能下降,可能是因为生成的单元测试错误地将正确解标记为错误。
- 多车辆挑战:当车辆数增至四辆时,GPT-4性能显著下降,即使使用框架也无法达到单车辆、十城市场景的性能,表明LLMs在复杂任务中存在局限。
-
为任务描述添加更多细节能否提升GPT-4的表现?:
- 实验设计:通过移除任务描述中的细节(保持核心含义不变)创建新数据集,测试GPT-4在该数据集上的性能,使用框架和自然语言提示范式。
- 结果 (如图8比较了GPT-4在有/无细节的任务描述中的性能,表II量化了有/无细节任务描述对GPT-4性能的影响):
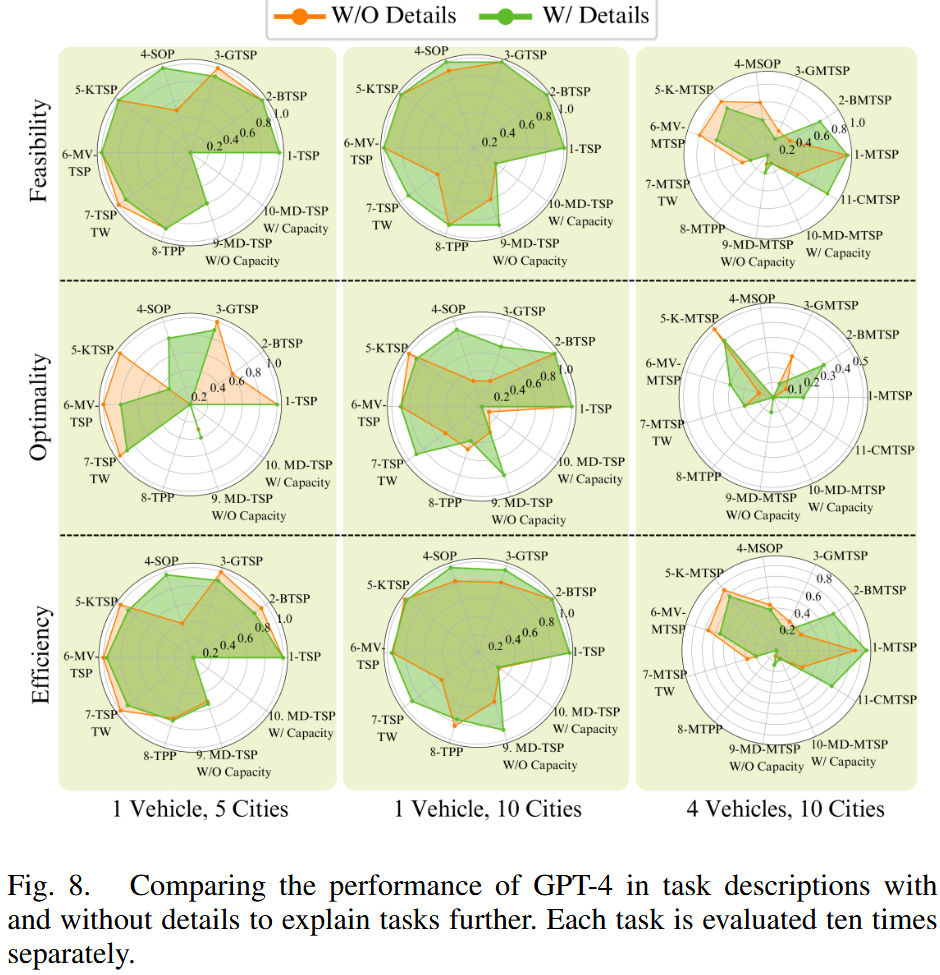
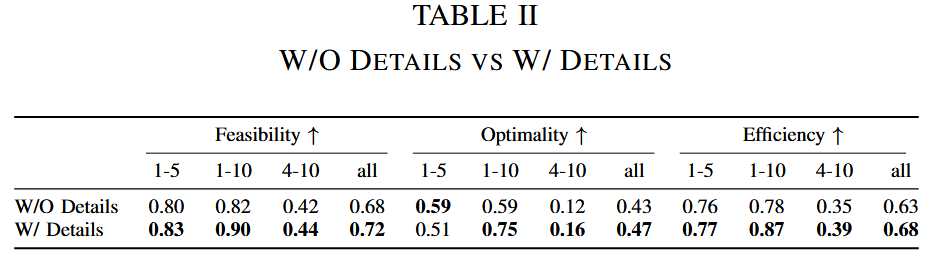
- 移除细节后,GPT-4性能下降:可行性-4%、最优性-4%、效率-5%。
- 图8显示并非所有任务都能从额外细节中受益,某些任务因细节冗余导致性能下降。
-
哪些细节能提升大语言模型的性能?是否存在某种方法能为我们提供帮助?
-
上述问题中,发现进一步解释任务的细节可能会降低大语言模型的性能,也可能不会产生负面影响。然而,要确定在初始任务描述中添加更多信息是否能提升大语言模型的性能,仍是一个具有挑战性的问题。
-
提出一种机制,使大语言模型能够判断任务描述是否完整:若认为描述不够详尽,可向用户发起提问,并通过将用户反馈整合至初始描述中实现任务描述的重新表述。协助请求次数限制为三次。(如图9)
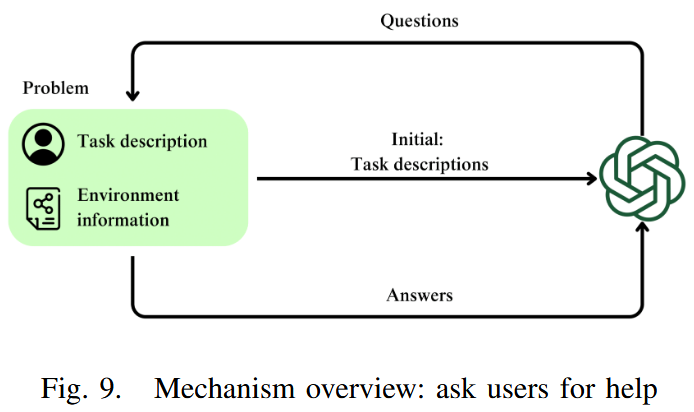
-
实验设计:选取单车辆五城的SOP,单车辆十城的TSPTW,四车辆十城的CMTSP测试了GPT-4
-
结果 :如表III,分析后说明尽管它能意识到任务描述不完整,却无法准确识别所需补充的信息。

-
-
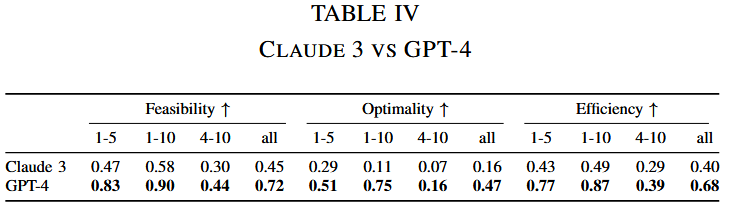
Claude 3在VRPs中的表现如何?
- Claude 3近期展现的卓越性能使我们不禁思考:其在车辆路径问题(VRPs)中的表现如何?其性能是否能够超越GPT-4?
- 实验设计:将Claude 3与论文提出的框架相结合,并通过直接输入自然语言(NL)来评估其性能。实验选用Claude系列中最强大的claude-3-opus-20240229模型。
- 结果 :表IV显示,尽管Claude 3 Opus能够求解VRPs问题,但其表现仍逊色于GPT-4。
4. 结论
4.1. 主要结论:
- LLMs在VRPs中的潜力:GPT-4在仅依赖自然语言描述的情况下,通过生成Python代码能够有效解决VRPs(初始性能:56%可行性、40%最优性、53%效率),无需微调。
- 框架的有效性:提出的自我调试和验证框架显著提升了GPT-4的性能(可行性+16%、最优性+7%、效率+15%),但对Gemini 1.0 Pro无效,表明不同LLMs的能力差异。
- 提示范式的选择:直接使用自然语言描述生成代码的范式表现最佳,数学公式和外部求解器反而降低性能,可能是因为LLMs在翻译或使用外部工具时易出错。
- 任务描述的重要性:不完整的任务描述会导致性能下降(可行性-4%、最优性-4%、效率-5%),但冗余细节也可能适得其反。交互机制可有效生成更详细的描述。
- 局限性 :
- GPT-4在复杂场景(如多车辆)中表现下降,表明LLMs在处理高复杂性任务时的局限。
- 反思机制可能因生成错误单元测试而导致性能下降。
- Gemini 1.0 Pro在VRPs任务中表现较差,显示出模型间的性能差距。
4.2. 未来方向:
- 改进LLMs在复杂VRPs中的表现,特别是在多车辆场景。
- 优化单元测试生成机制,减少错误分类。
- 进一步研究如何设计更有效的自然语言提示,以平衡细节和简洁性。
4.3. 总结
这篇论文系统性地研究了LLMs在解决VRPs中的能力,通过构建数据集、提出框架和测试不同提示范式,展示了GPT-4的潜力及其局限性。实验结果表明,直接使用自然语言描述结合自我调试和验证框架是当前最有效的方法,但复杂任务和模型差异仍需进一步优化。