
🌟 第一部分:深度学习简介(Deep Learning Overview)
什么是深度学习(Deep Learning)?
-
定义:深度学习是机器学习(Machine Learning)中的一个分支,它利用**多层的人工神经网络(Neural Networks)**来模拟人脑的处理方式,自动地从大量数据中提取特征。
-
"深度"含义 :指的是网络中的隐藏层(hidden layers)数量多,比如 5 层、10 层甚至上百层,能够从数据中提取越来越抽象的表示(representation)。
🤖 神经网络的基本单元:神经元(Neuron)
单个神经元模型(Perceptron):
-
输入:x1,x2,...,xn
-
权重:w1,w2,...,wn
-
偏置:b
-
激活函数:f
输出公式:
y=f(w1x1+w2x2+⋯+wnxn+b)
通俗解释:就像一个"打分器",每个输入有个"重要程度"(权重),加起来后决定输出。
🔢 多层感知机(MLP:Multilayer Perceptron)
特点:
-
输入层:接收原始数据。
-
隐藏层:提取中间特征(可能有多个)。
-
输出层:给出预测结果。
为什么要多层?
-
一层感知机只能解决线性可分问题。
-
多层网络可以学习非线性关系(比如图像识别、语言理解等复杂任务)。
📐 激活函数(Activation Functions)
激活函数的作用是引入非线性,让神经网络有能力逼近任何复杂函数。
常见的激活函数:
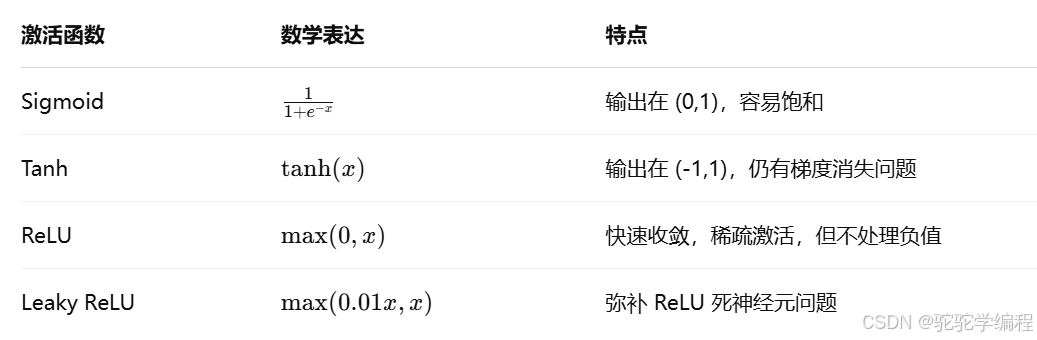
🔎 通俗理解:
-
ReLU 就像一个门:正的放行,负的拦住。
-
Sigmoid/Tanh 是缓慢上升的"S"形曲线。
🔁 反向传播(Backpropagation)
是深度学习中最核心的算法之一,用来训练网络。
基本思想:
-
前向传播:计算输出值。
-
计算损失(Loss):衡量预测与真实差距。
-
反向传播误差:按链式法则传播误差信号,计算每个权重对误差的"责任"。
-
梯度下降更新参数:调整权重让误差变小。
关键公式:
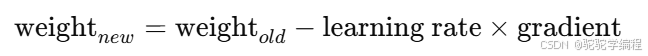
🔎 通俗理解:像是在"爬山"找到最优值,反向传播告诉你往哪个方向走。
📊 损失函数(Loss Function)
用于量化预测结果与实际标签之间的差异。
常见损失函数:
| 类型 | 名称 | 适用任务 |
|---|---|---|
| 回归 | MSE(均方误差) | 连续值预测 |
| 分类 | Cross-Entropy(交叉熵) | 多类分类问题 |
交叉熵损失(分类)公式:
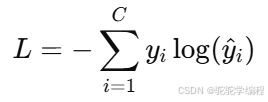
🔎 通俗理解:交叉熵越小,代表预测结果越"接近"真实分类。
🚀 优化算法(Optimizers)
用于在训练过程中寻找最优参数组合。
常见优化器:
-
SGD(随机梯度下降):每次用一小批数据更新。
-
Momentum:记住上一次的梯度方向,让更新更稳定。
-
Adam:综合考虑过去梯度和梯度变化,是最常用的优化器之一。
🔎 类比:
-
SGD 像走一步看一步;
-
Momentum 像滑滑梯带动;
-
Adam 像有记忆和预判能力的走路方式。
🧱 卷积神经网络基础(CNN Basics)
虽然经典 CNN 架构我之前已经讲过了,这里再从基本原理过一遍:
为什么用 CNN?
-
图像有空间结构,CNN 可以利用相邻像素之间的关系。
-
参数量少,计算效率高。
核心构成:
-
卷积层(Convolutional Layer):提取局部特征。
-
激活层(ReLU):增加非线性能力。
-
池化层(Pooling):减少计算量、增强位置不变性。
-
全连接层(Fully Connected Layer):整合特征,输出结果。
🧪 模型训练过程概述
完整训练流程是:
-
数据加载(图像/标签);
-
网络前向传播(输出预测);
-
计算损失(loss);
-
反向传播误差;
-
更新权重;
-
重复上述过程直到收敛。
✅ CNN 架构总览
经典 CNN 架构的发展是逐步加深模型、提升准确率、降低计算成本的过程,关键节点如下:
| 年代 | 网络名称 | 主要贡献 |
|---|---|---|
| 1998 | LeNet-5 | 最早成功用于字符识别的 CNN |
| 2012 | AlexNet | 使用 ReLU,开启深度学习热潮 |
| 2014 | VGG | 简单堆叠卷积,体现深层 CNN 的威力 |
| 2014 | GoogLeNet/Inception | 多尺度特征提取,计算效率高 |
| 2015 | ResNet | 引入残差连接,成功训练超深网络 |
| 2019 | EfficientNet | 自动结构搜索 + 多维缩放 |
| 2020 | ViT | 首次用 Transformer 替代 CNN |
| 2022 | ConvNeXt | 用 ViT 的理念改造 CNN 架构 |
🧠 LeNet-5(1998)
-
应用背景:手写数字识别(如邮政编码)
-
结构特点:
-
输入:32x32 灰度图
-
Conv (5x5) → Pool (2x2) → Conv (5x5) → Pool → FC → FC → 输出
-
-
层数少,总参数约 6 万
-
创新点:提出了 CNN 的基本构成理念
💡 类比:像最早的自动驾驶车辆原型------功能基础但成功运行!
🧠 AlexNet(2012)
-
ImageNet 比赛冠军,误差从 26% 降到 16%
-
输入图像:224x224x3
-
网络结构:
-
5 个卷积层(ReLU 激活)
-
最大池化(Max Pooling)
-
3 个全连接层
-
最终 softmax 输出 1000 类
-
-
技术突破:
-
使用 GPU 训练(提升 10 倍速度)
-
引入 ReLU(解决梯度消失)
-
使用 Dropout(防止过拟合)
-
数据增强(翻转、裁剪)
-
💡 理解技巧:AlexNet 是 CNN 上了"高速公路"的第一辆法拉利!
🧠 VGG(2014)
-
核心思想:用多个 3x3 卷积堆叠替代大卷积核
-
结构例子(VGG-16):
-
13 个卷积层(3x3)+ 3 个全连接层
-
所有卷积步长 stride=1,池化步长=2
-
-
通俗解释:
-
比 7x7 卷积更节省参数、提高非线性表达能力
-
堆叠多个 3x3 就像把一个大窗户分成了多个小窗格,便于捕捉细节
-
💡 注意:VGG 参数非常多(1.38 亿),训练和推理速度慢,适合作为特征提取器(比如迁移学习)。
🧠 GoogLeNet(2014)
-
核心思想:Inception 模块 + 全局平均池化(GAP)
-
Inception 模块:
-
并行使用多个卷积核(1x1, 3x3, 5x5)提取多尺度信息
-
再用 1x1 卷积做降维(减少通道数)
-
-
网络深度:22 层(比 VGG 还深)
-
参数只有 500 万(远少于 VGG)
💡 通俗比喻:Inception 像同时请多个专家用不同视角看图,再综合他们的意见。
🧠 ResNet(2015)
-
革命性创新:Residual Connection(残差连接)
-
标准卷积堆叠为:
x → F(x) → 输出 -
残差连接为:
x → F(x) + x → 输出 -
本质:让网络"至少学不会更差"的变化
-
-
解决深层网络退化问题,成功训练 152 层
-
残差块两种类型:
-
简单加法连接
-
投影连接(用于维度对不上)
-
💡 生活类比:普通人学习新知识是不断忘记和重学,ResNet 会保留原有知识再叠加学习,避免"越学越差"。
🧠 EfficientNet(2019)
-
挑战:CNN 的效率和准确率之间存在平衡
-
核心方法:Compound Scaling
-
同时放大:宽度(通道)、深度(层数)、分辨率(图片大小)
-
比如 EfficientNet-B0 到 B7,不是单一加深
-
-
结构搜索:用 NAS(神经架构搜索)自动发现最优结构
💡 比喻:EfficientNet 就像精打细算的建筑师,在预算内盖出功能最强的房子!
🧠 Vision Transformer (ViT)
-
首次用 Transformer 架构做图像分类
-
核心做法:
-
将图片切成 16x16 patch(共 14x14=196 个)
-
每个 patch 展平后加上位置编码,送入标准 Transformer 编码器
-
使用 CLS token 做分类预测
-
-
优点:
-
更强的建模能力
-
训练速度快
-
-
缺点:
- 对数据量敏感,训练依赖大规模数据
💡 形象理解:CNN 看图像是"局部扫一遍",Transformer 是"把图像当句子来读"。
🧠 ConvNeXt(2022)
-
用 ViT 的理念优化 CNN 架构
-
关键改进:
-
用更大卷积核(7x7 depthwise)
-
LayerNorm 替代 BatchNorm
-
GELU 激活函数替代 ReLU
-
移除冗余的层和分支
-
-
结果:
-
在 ImageNet 上表现比肩 ViT
-
保留 CNN 的高效推理特点
-
💡 总结一句:ConvNeXt 是"现代 CNN",融合 Transformer 优势又保留 CNN 精髓。