目录
[一. 从神经网络的角度理解CNN](#一. 从神经网络的角度理解CNN)
[基于receptive field的优化](#基于receptive field的优化)
[Observation2: 相同的pattern可能出现在不同位置](#Observation2: 相同的pattern可能出现在不同位置)
[二. 从卷积的角度理解CNN](#二. 从卷积的角度理解CNN)
[三. Pooling(池化)](#三. Pooling(池化))
[四. The whole CNN](#四. The whole CNN)
[五. CNN应用实例:AlphaGo](#五. CNN应用实例:AlphaGo)
[六. More Applications](#六. More Applications)
[七. 缺陷](#七. 缺陷)
卷积神经网络(Convolutional Neural Network, CNN)广泛应用于图像识别和视觉任务,是深度学习中的核心模型之一。
预备知识
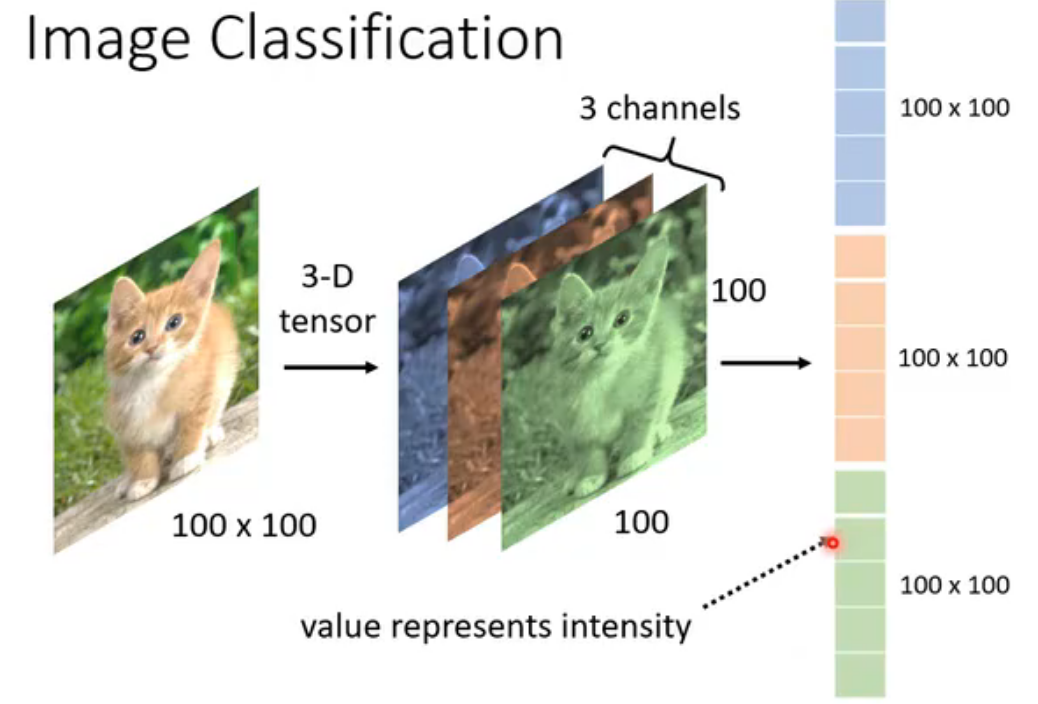
输入:所有影像辨识的模型的接受的所有图片大小(分辨率)相同,所以处理图片时,首先需要rescale。
输出:one-hot vector(分类的任务)
图片由RGB表示(即每个像素有红绿蓝三个数值),是三维的张量,channel = 3。
一. 从神经网络的角度理解CNN
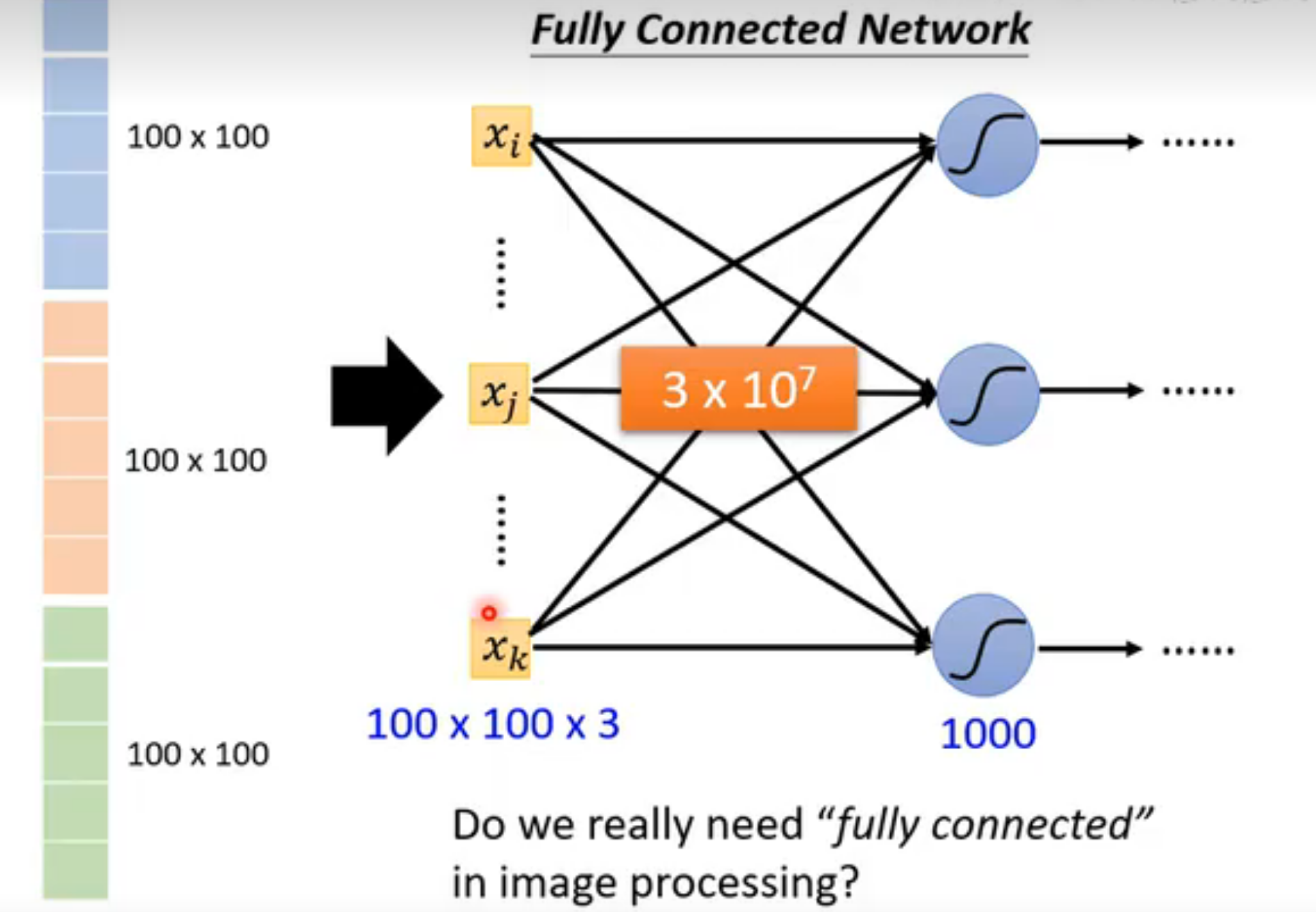
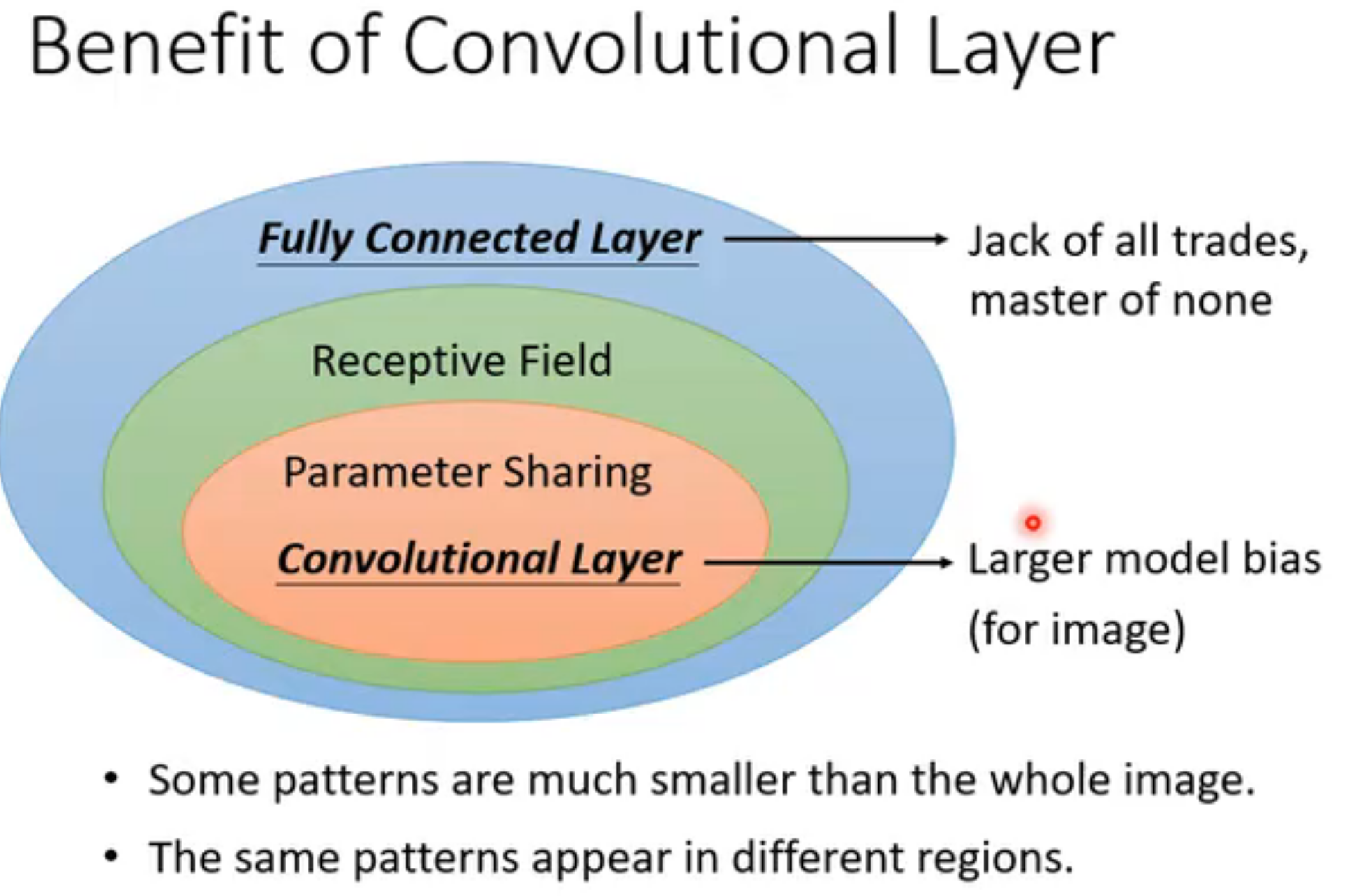
如果使用全连接神经网络,参数量巨大,模型弹性大,容易Overfitting。CNN根据图像的特性对神经网络做了优化与限制。
Observation1:pattern
识别物体的关键之一是找到特定的pattern,所以一个neuron并不需要看完整张图片,只需要关注**receptive field(感受野)**中的部分。
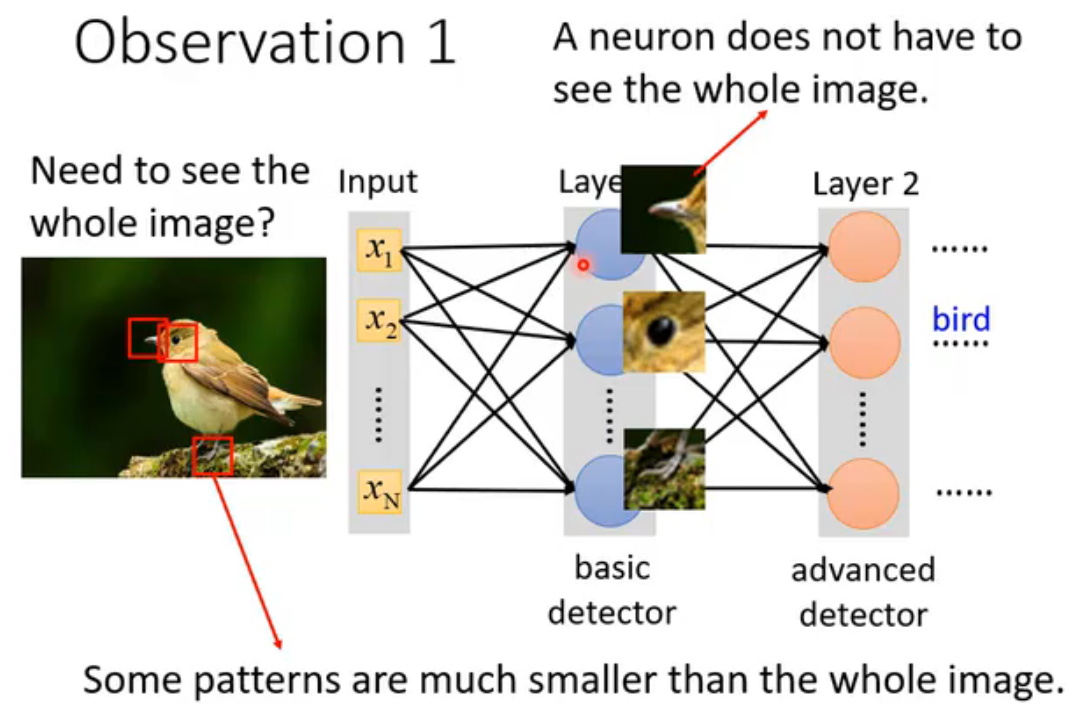
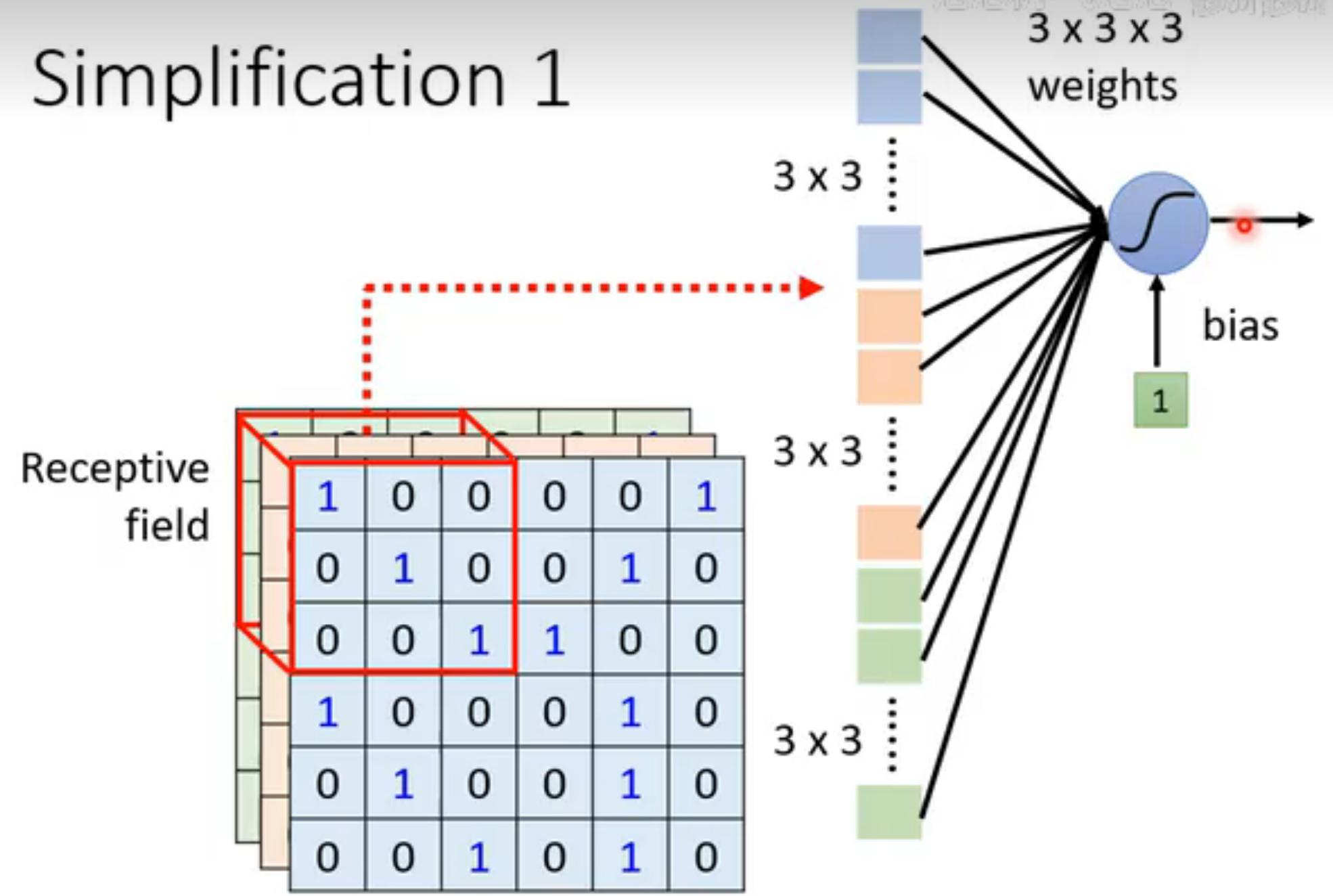
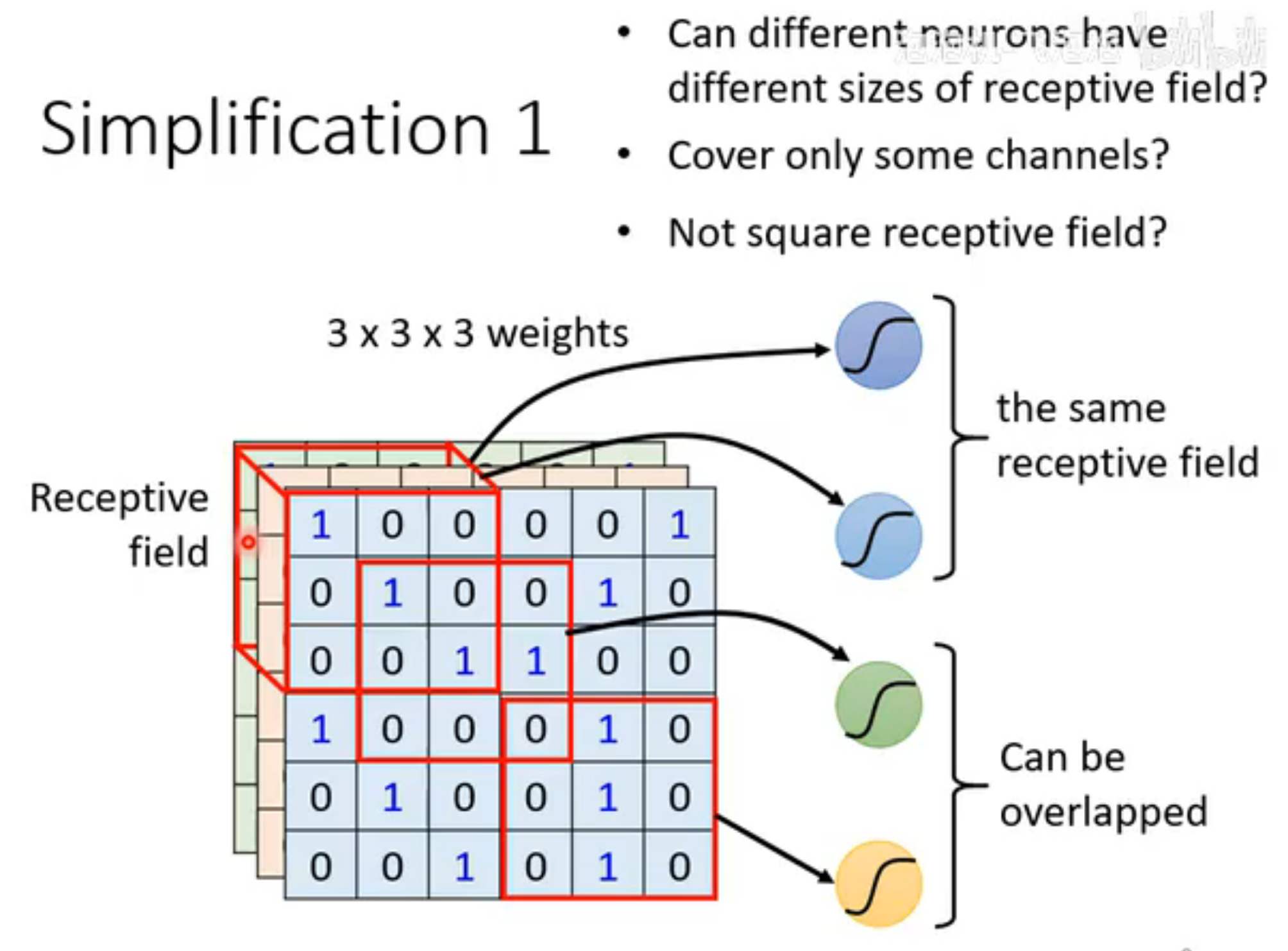
基于receptive field的优化
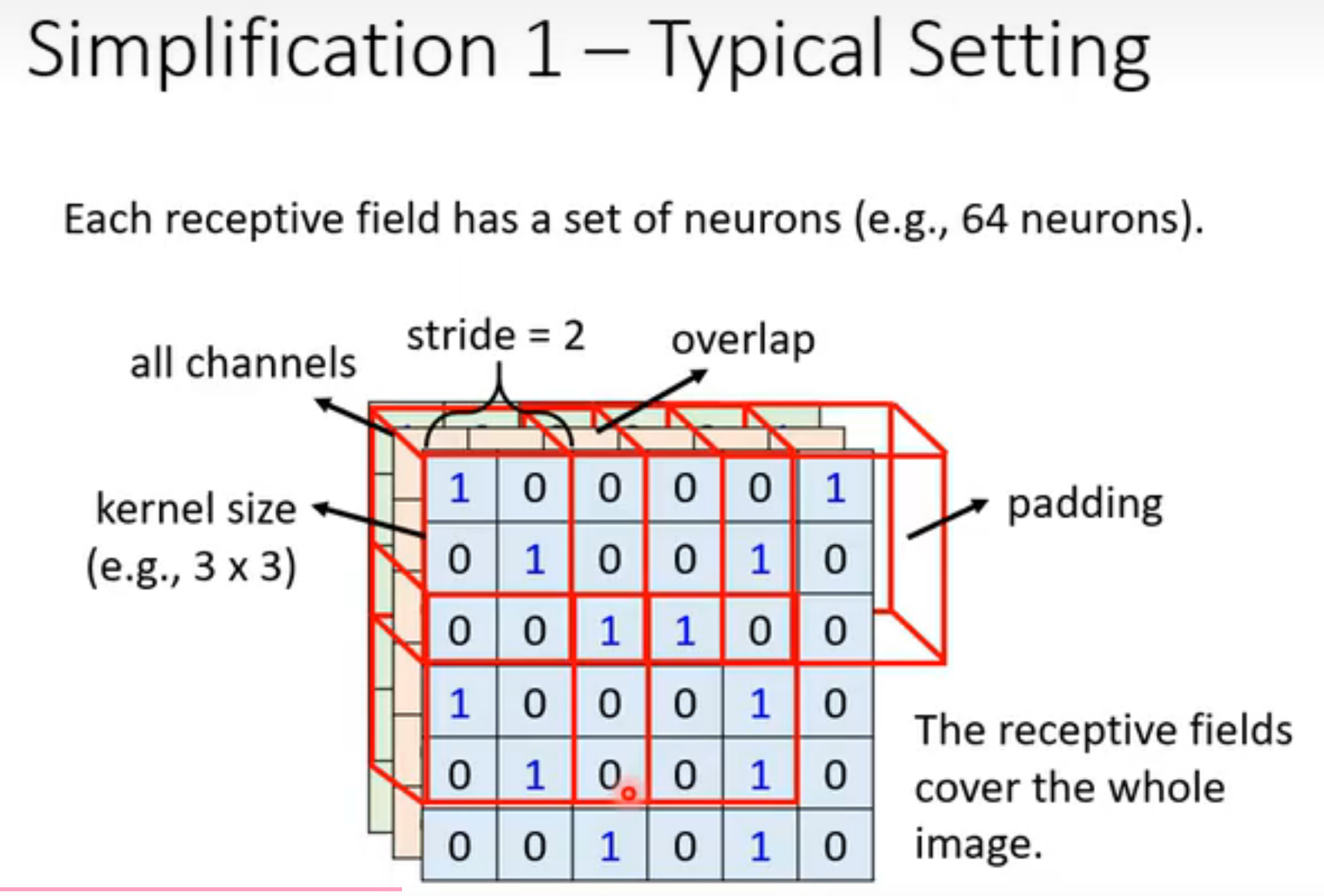
receptive field典型的设计是涵盖所有channel,所以一般只需要讨论长宽,即kernel size (一般设置很小,kernel:卷积核 );stride(步长) 是相邻卷积核的距离,必须有overlap ,否则可能错过某些pattern;对于边缘的部分,需要用**padding(填充)**补成符合卷积核的大小,padding一般是补充0。
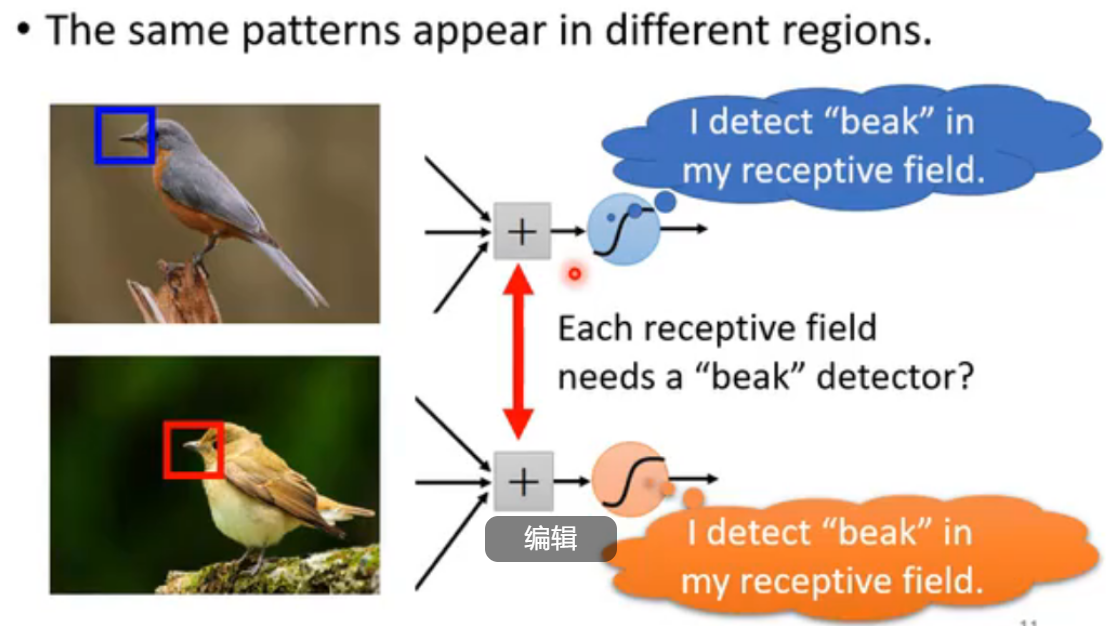
Observation2: 相同的pattern可能出现在不同位置
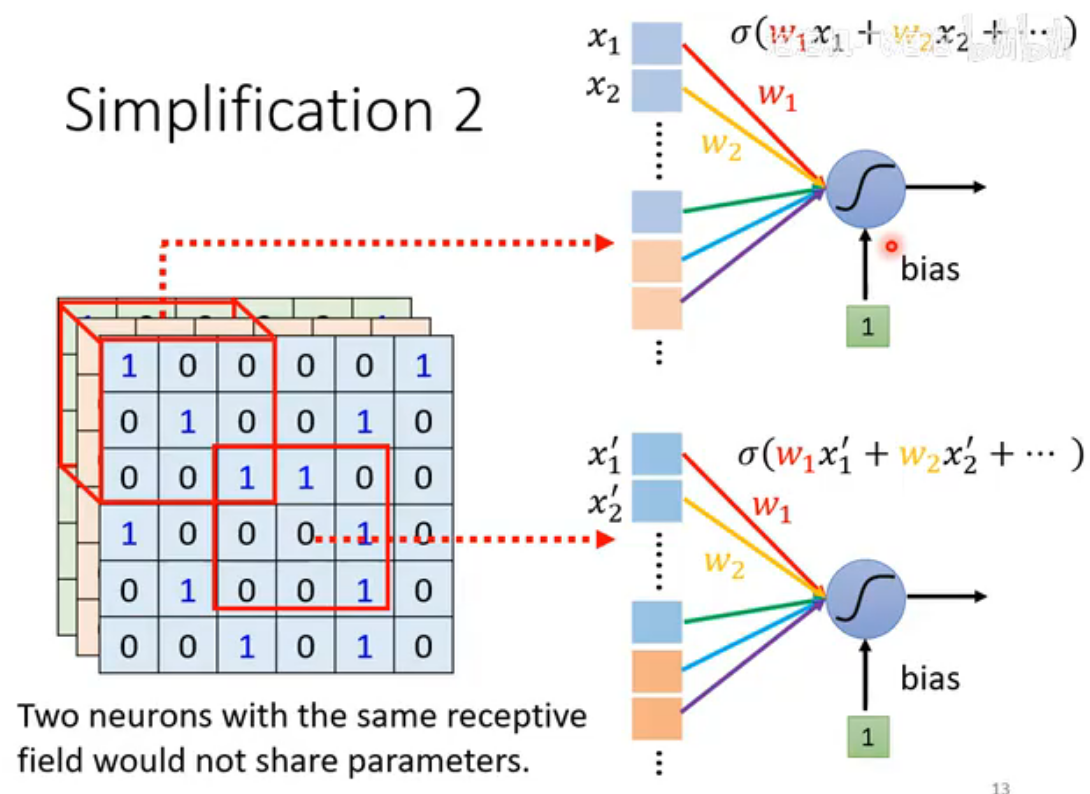
优化2:共享参数
不同的receptive field的neuron共享参数。
常见的设置
不同receptive field使用同一组neuron,每一个neuron称为filter(滤波器/卷积核) 。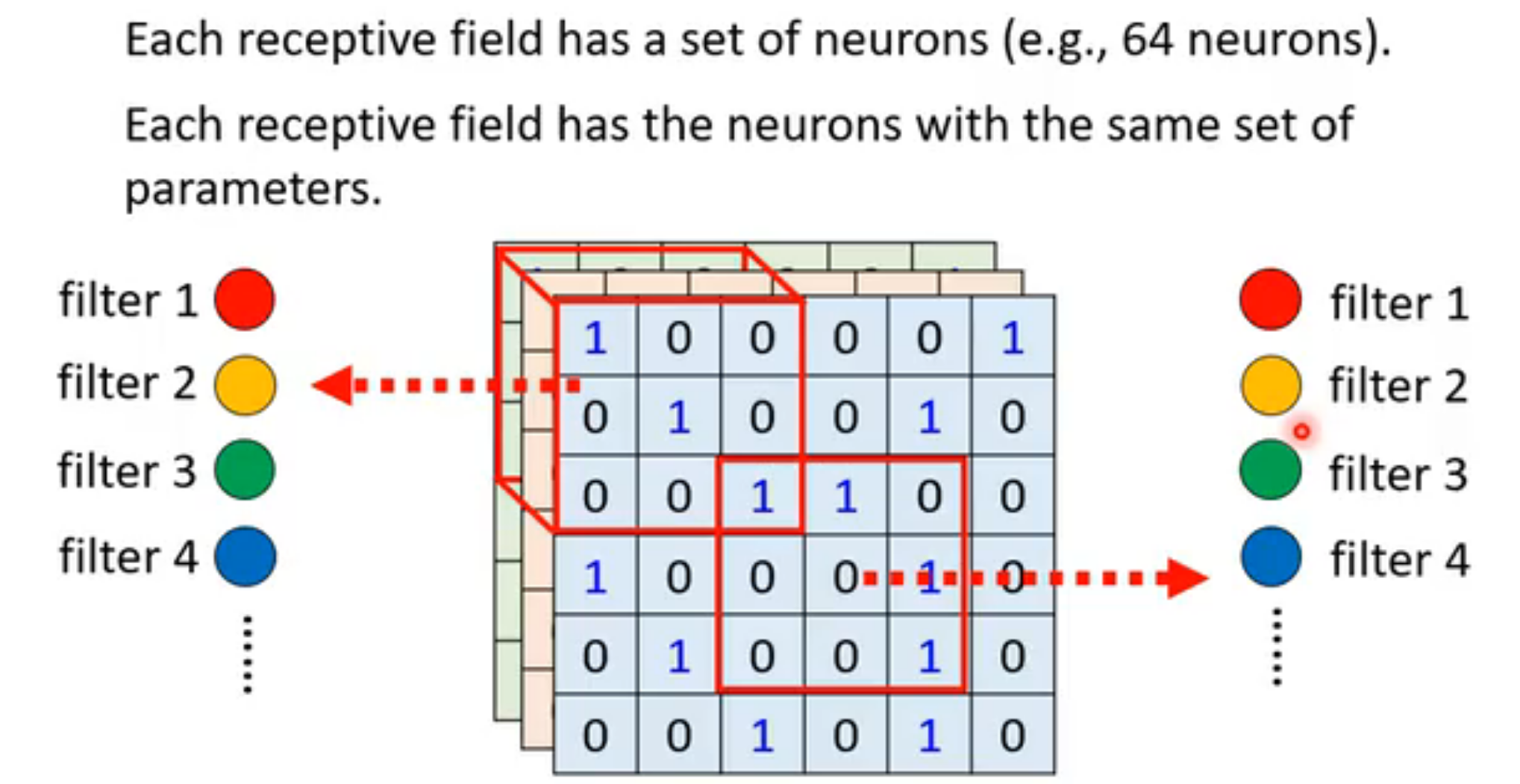
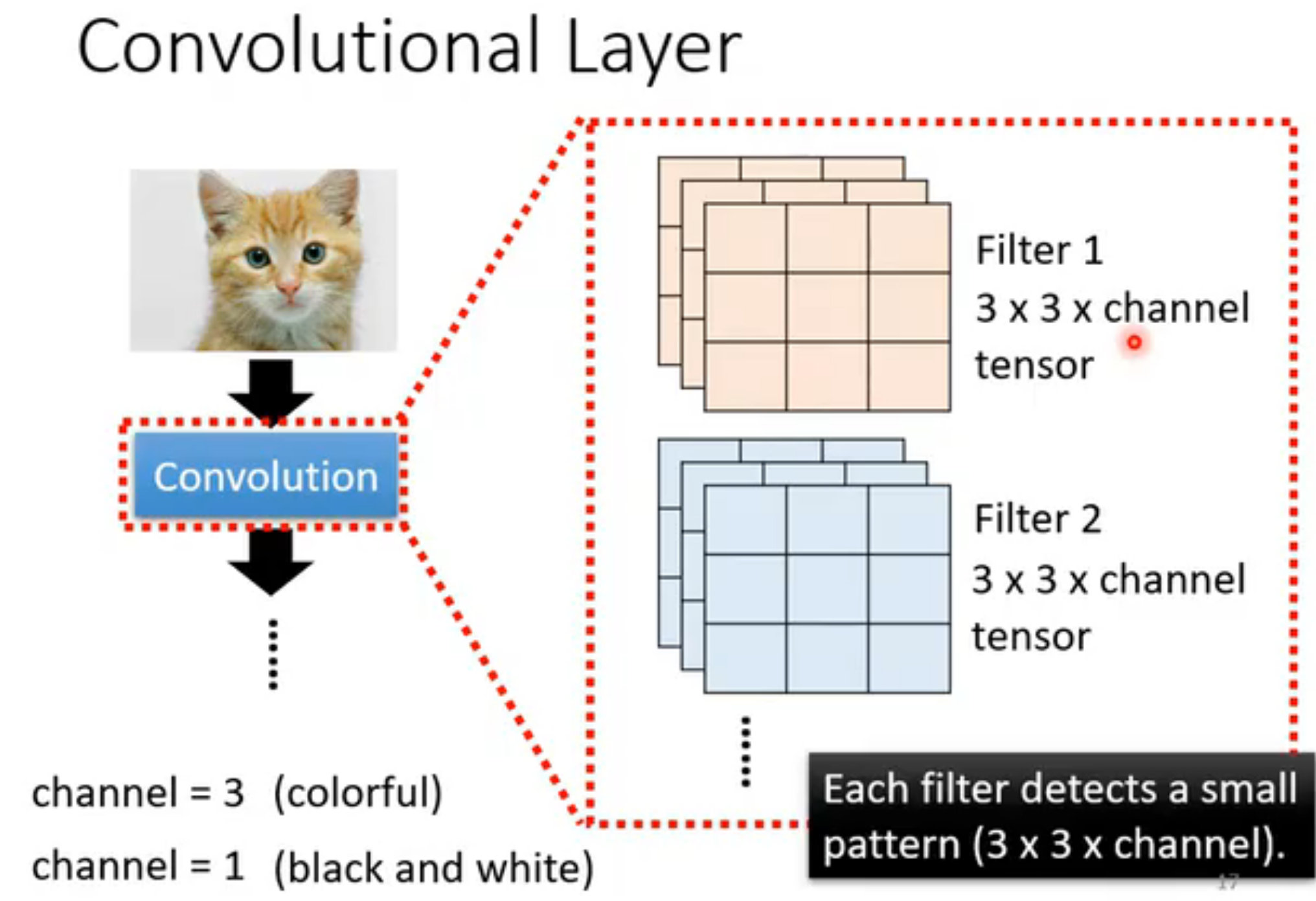
二. 从卷积的角度理解CNN
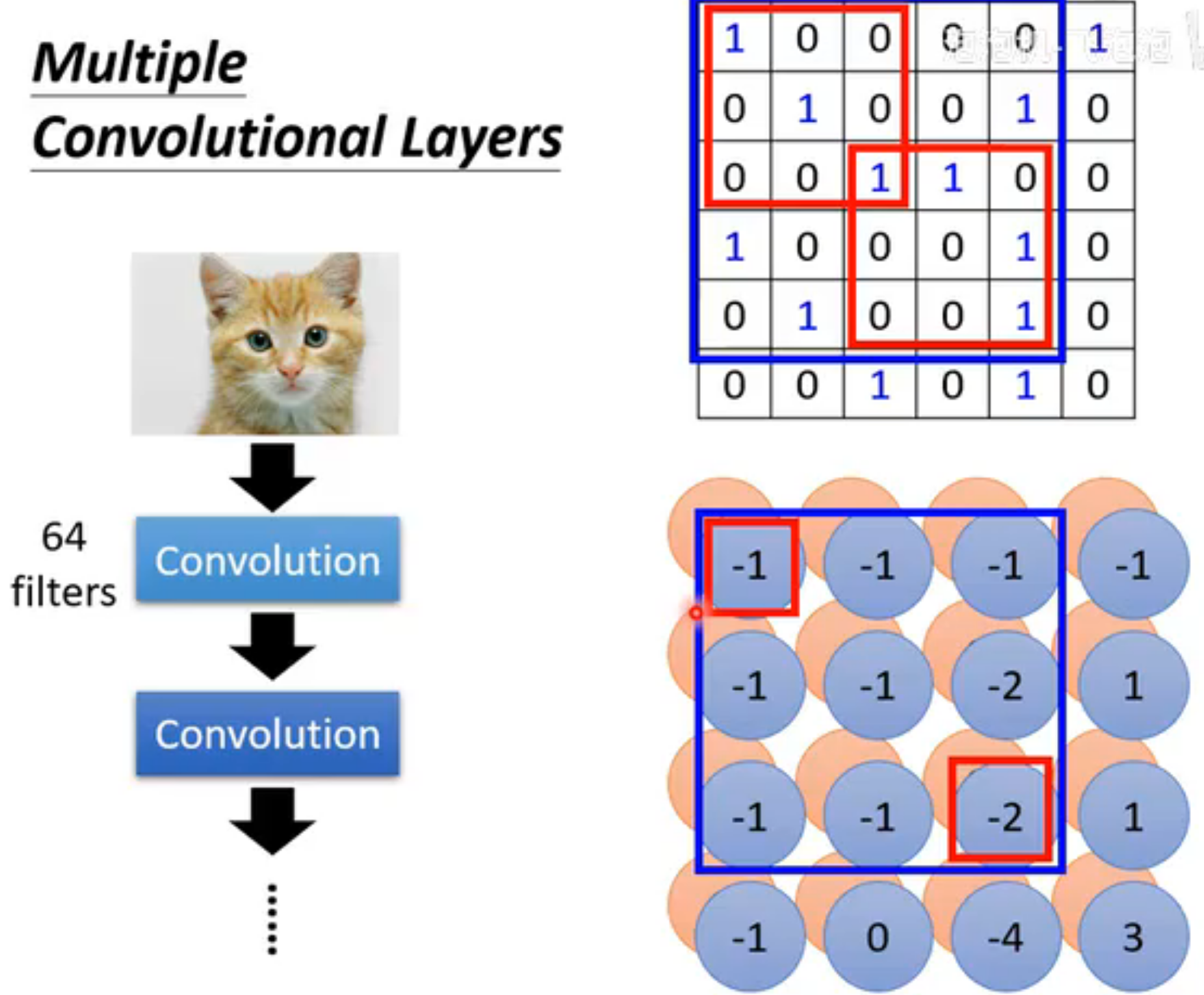
现在换一个角度理解。每个卷积层中有一组filter,每个filter检测不同的pattern。
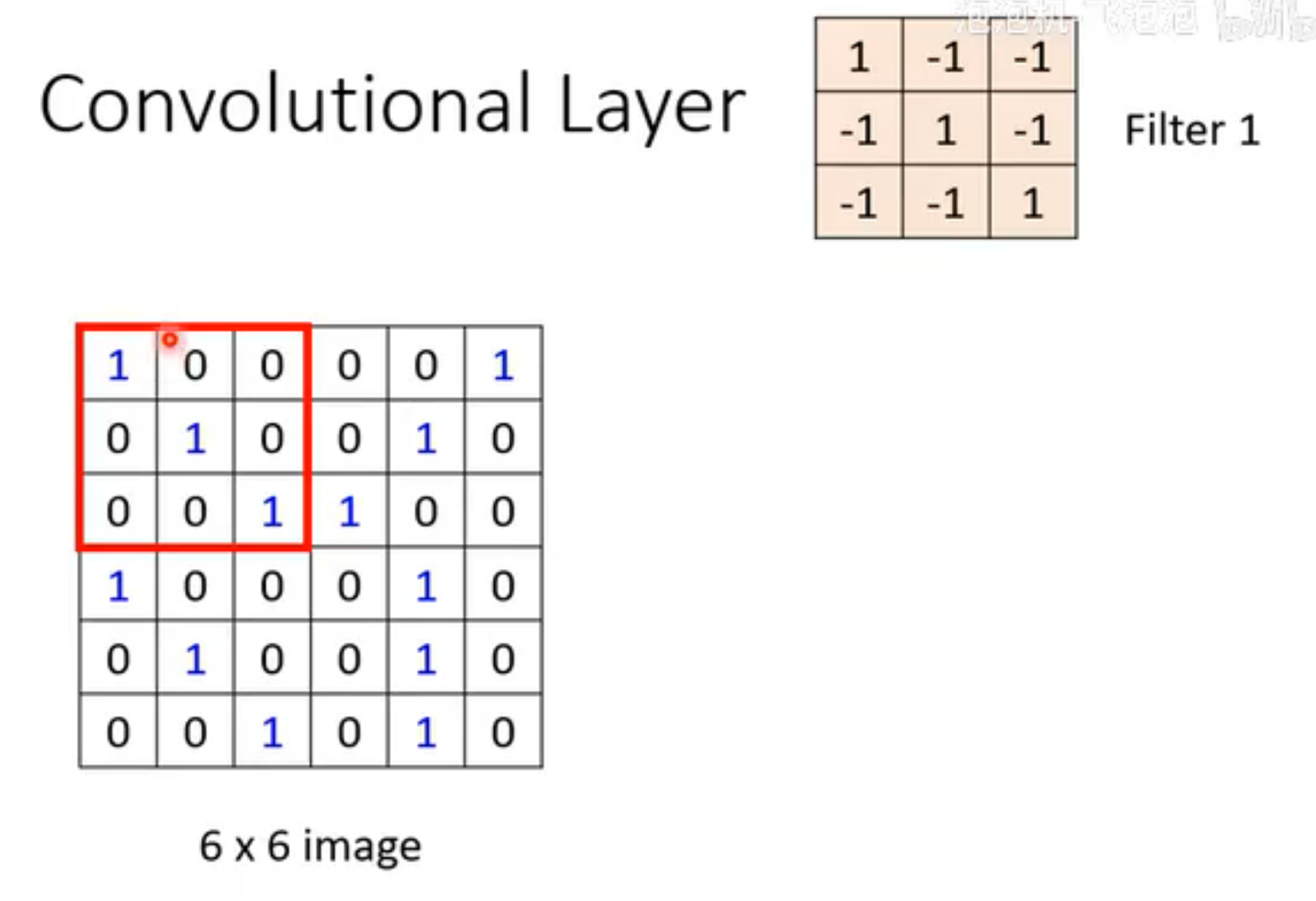
filter作用的过程
首先filter中每个数值与左上角范围对应的九个数值相乘后求和。
接下来filter会滑动 :将这个范围依次向左,然后向下移动stride的距离,作相同运算。最终filter会扫完整张图片。
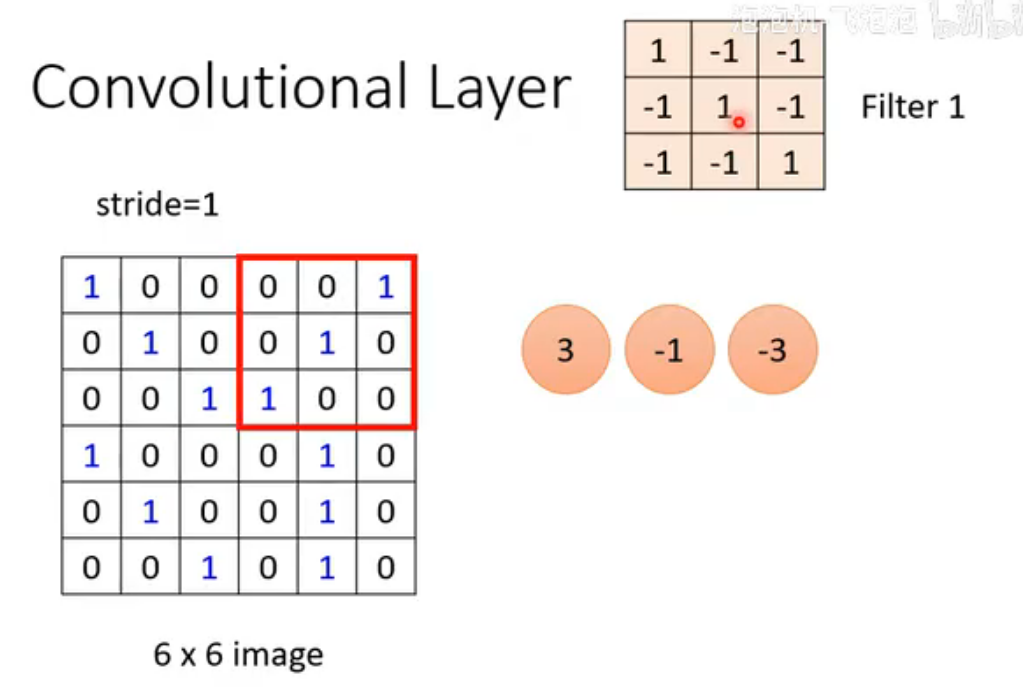
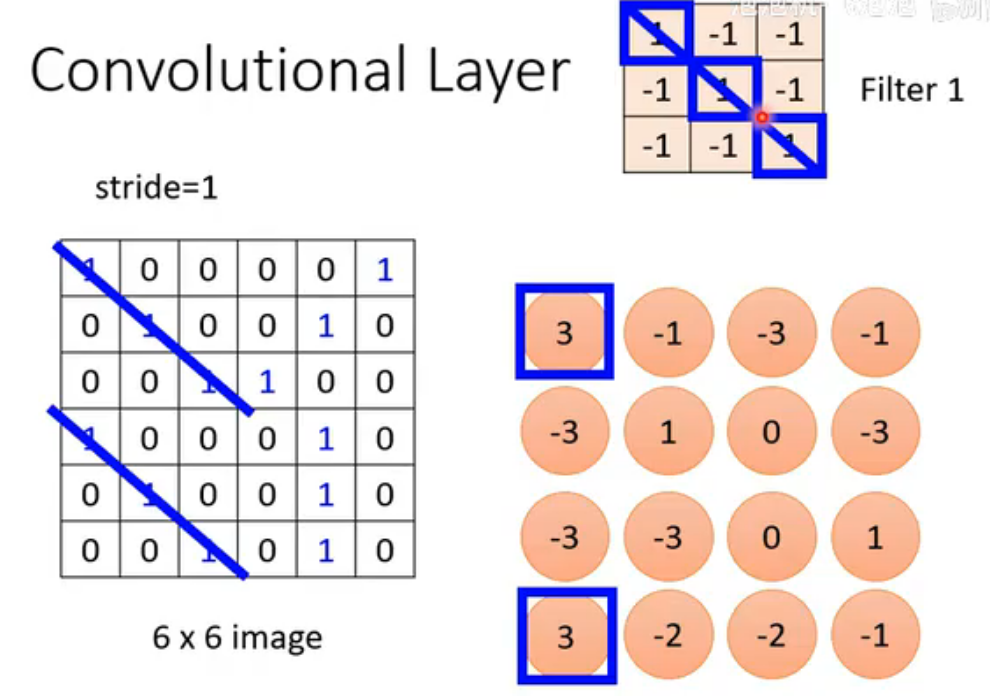
可以看出filter1能检测对角线是否全为1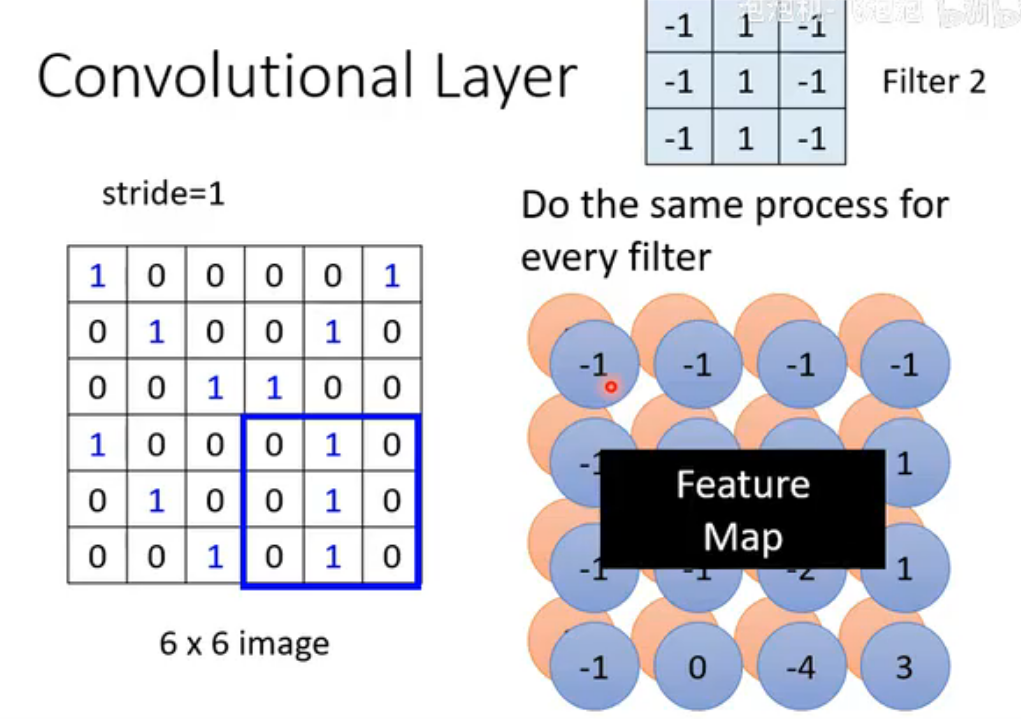
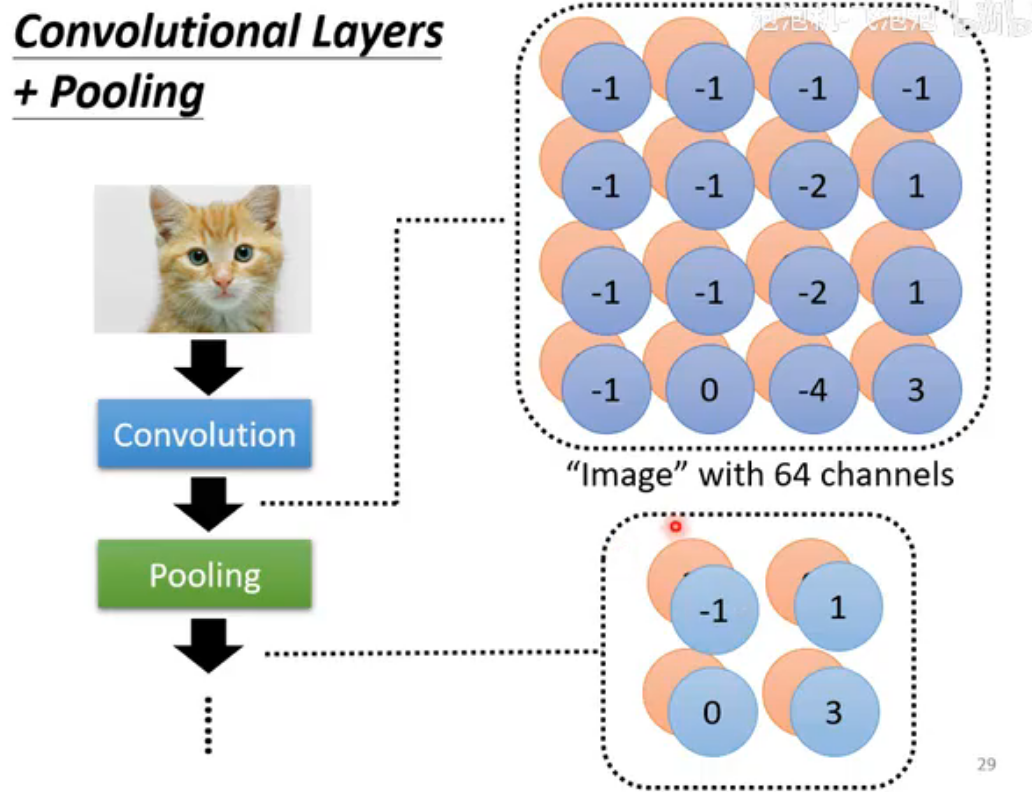
然后将每个filter如此操作,最后得到的结果叫feature map(特征图,表示CNN每层输出的结果)。
可以把这个feature map看为一张channel为64新"图片",下一个卷积层的filter深度需要设为64
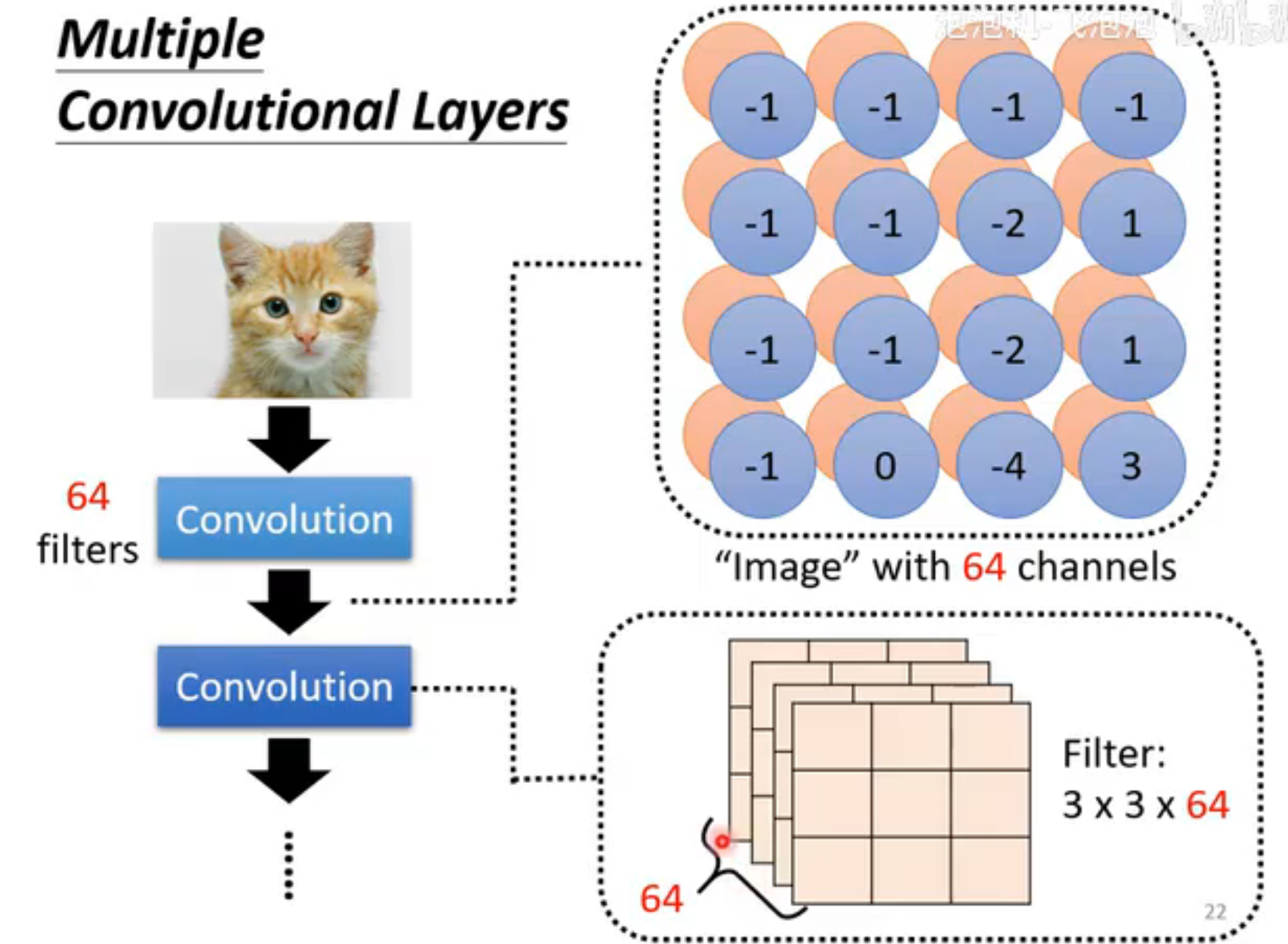
filter不仅限于提取局部pattern
一个常见的误区,是认为既然kernel size这么小,filter只能提取很小范围内的pattern。实则不然,随着卷积层的增加,每个filter能看的范围对应到原图上越来越大。

三. Pooling(池化)
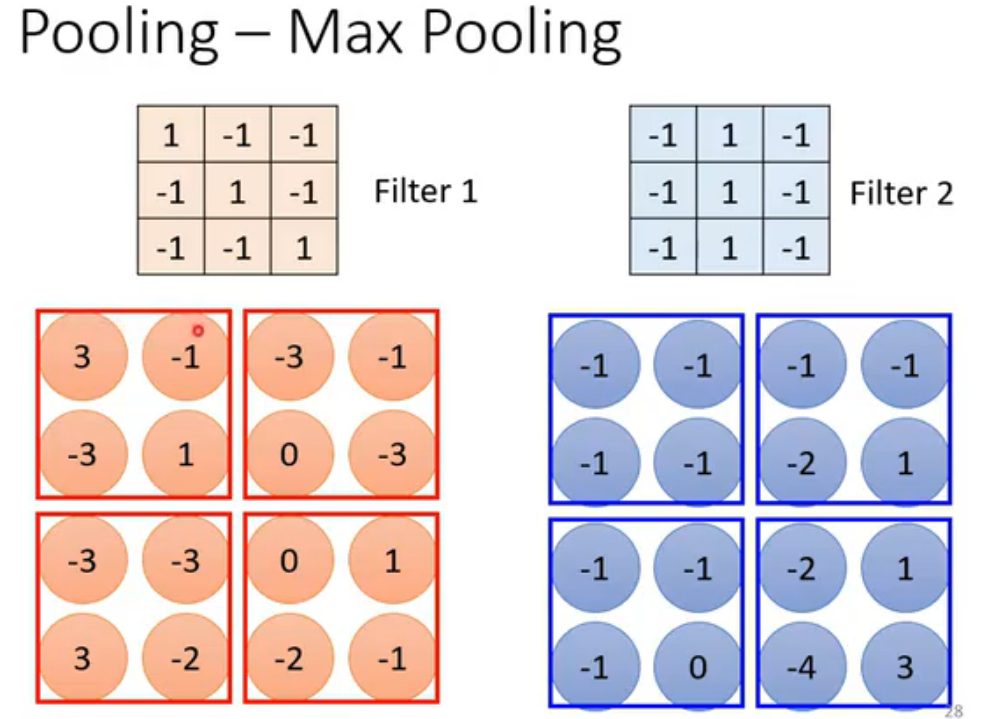
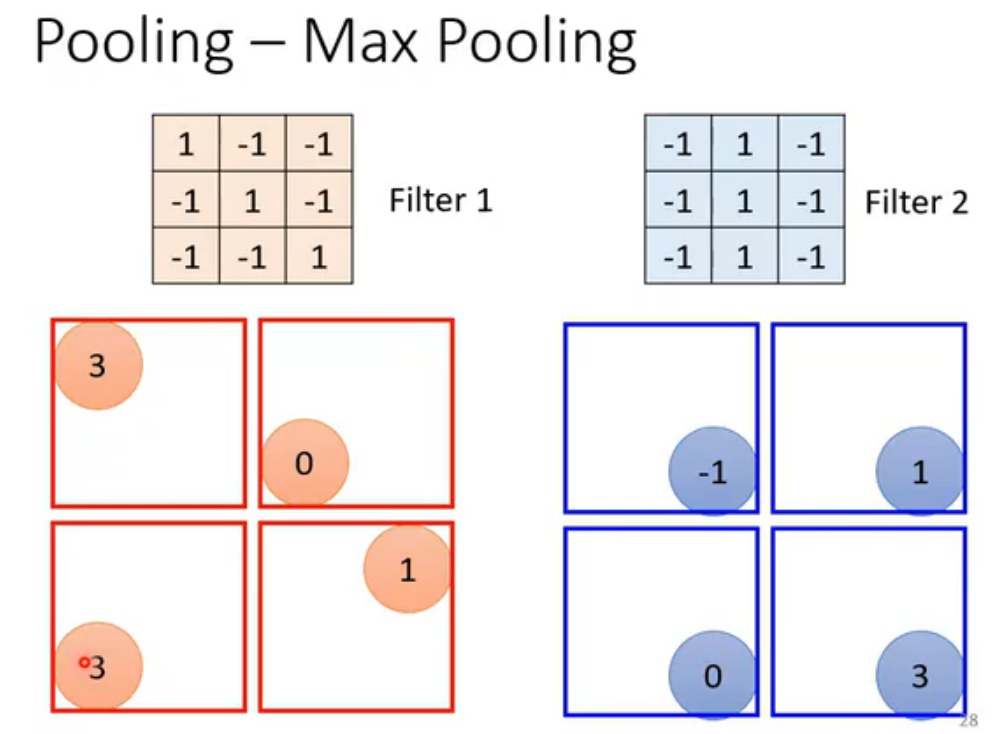
pooling的想法来自于另一个观察:图片subsample(二次抽样)后,比如把偶数行、列全部抽掉,得到的小图片不影响辨识。pooling本身没有参数,不是一个layer,行为是固定好的。

pooling有很多种,max pooling是分组(大小自己决定)后,取最大的值作为代表。
作用与副作用
pooling能减少运算量,不过是以部分精度作为代价(毕竟删除了一些信息),近年来随着算力的提升,许多影像辨识模型往往会舍弃pooling。
四. The whole CNN
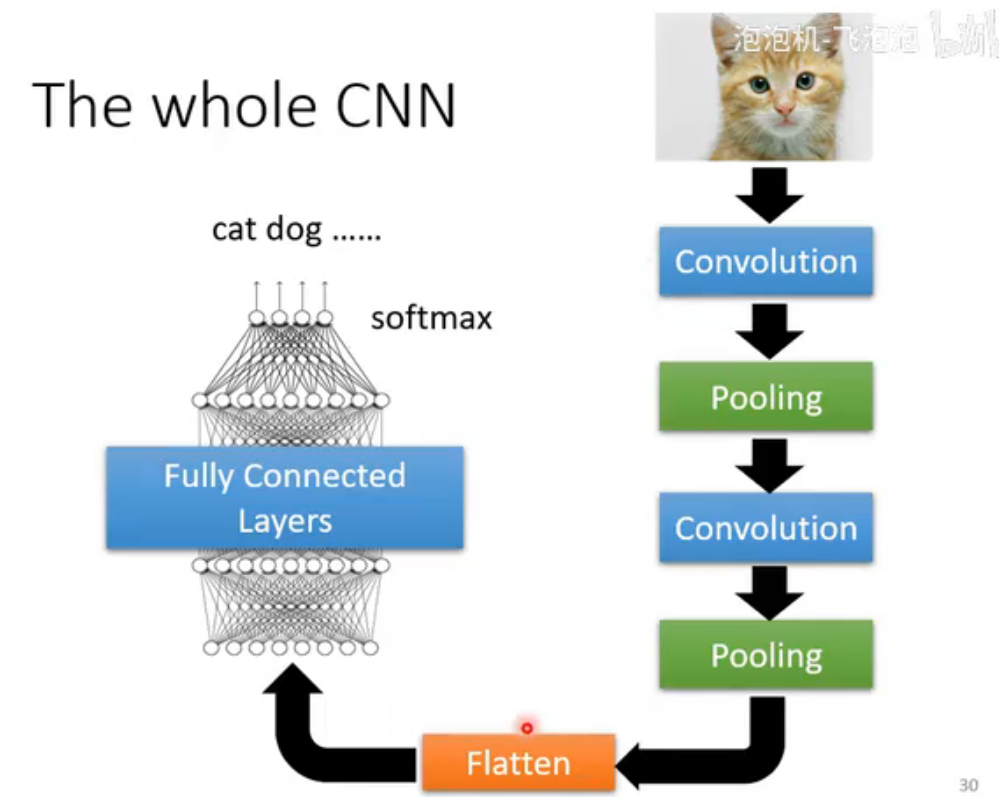
五. CNN应用实例:AlphaGo
下棋可以视为分类问题 ,一个位置表示一个类别。整个棋盘可视为19*19的图片,每个落子的位置视为像素。
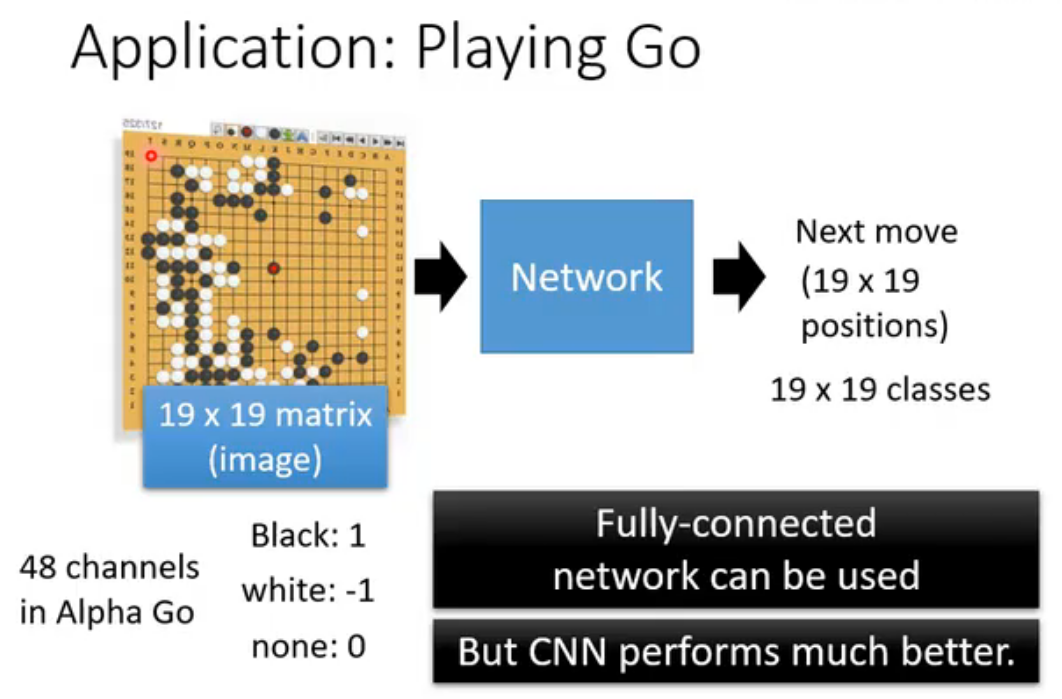

有人会认为CNN必须使用pooling,所以不能用于下棋。实际上AlphaGo没有用pooling。

六. More Applications
CNN可以用于语音和文字处理,但注意不能直接套用上述介绍的针对图像CNN架构,必须根据具体任务做相应调整。

七. 缺陷
CNN无法处理影像放大缩小或旋转的情况,形状一样但是大小不同的物体对CNN来说是不同的东西。所以实际训练时,往往需要data argumentation。
