文章目录
- [1 过拟合](#1 过拟合)
-
- [1.1 过拟合问题](#1.1 过拟合问题)
- [1.2 解决过拟合](#1.2 解决过拟合)
- [2 正则化](#2 正则化)
-
- [2.1 正则化代价函数](#2.1 正则化代价函数)
- [2.2 线性回归的正则化](#2.2 线性回归的正则化)
- [2.3 逻辑回归的正则化](#2.3 逻辑回归的正则化)
1 过拟合
1.1 过拟合问题
-
欠拟合(Underfitting)
模型过于简单,无法捕捉数据中的模式,导致训练误差和测试误差都较高。
也称为高偏差(High Bias),即模型对数据有较强的先入之见(如强行用线性模型拟合非线性数据)。
-
过拟合(Overfitting)
模型过于复杂,过度拟合训练数据(甚至噪声),导致泛化能力差。
也称为高方差(High Variance),即模型对训练数据的微小变化非常敏感。
-
泛化(Generalization)
模型在未见过的数据上表现良好的能力,是机器学习的核心目标。
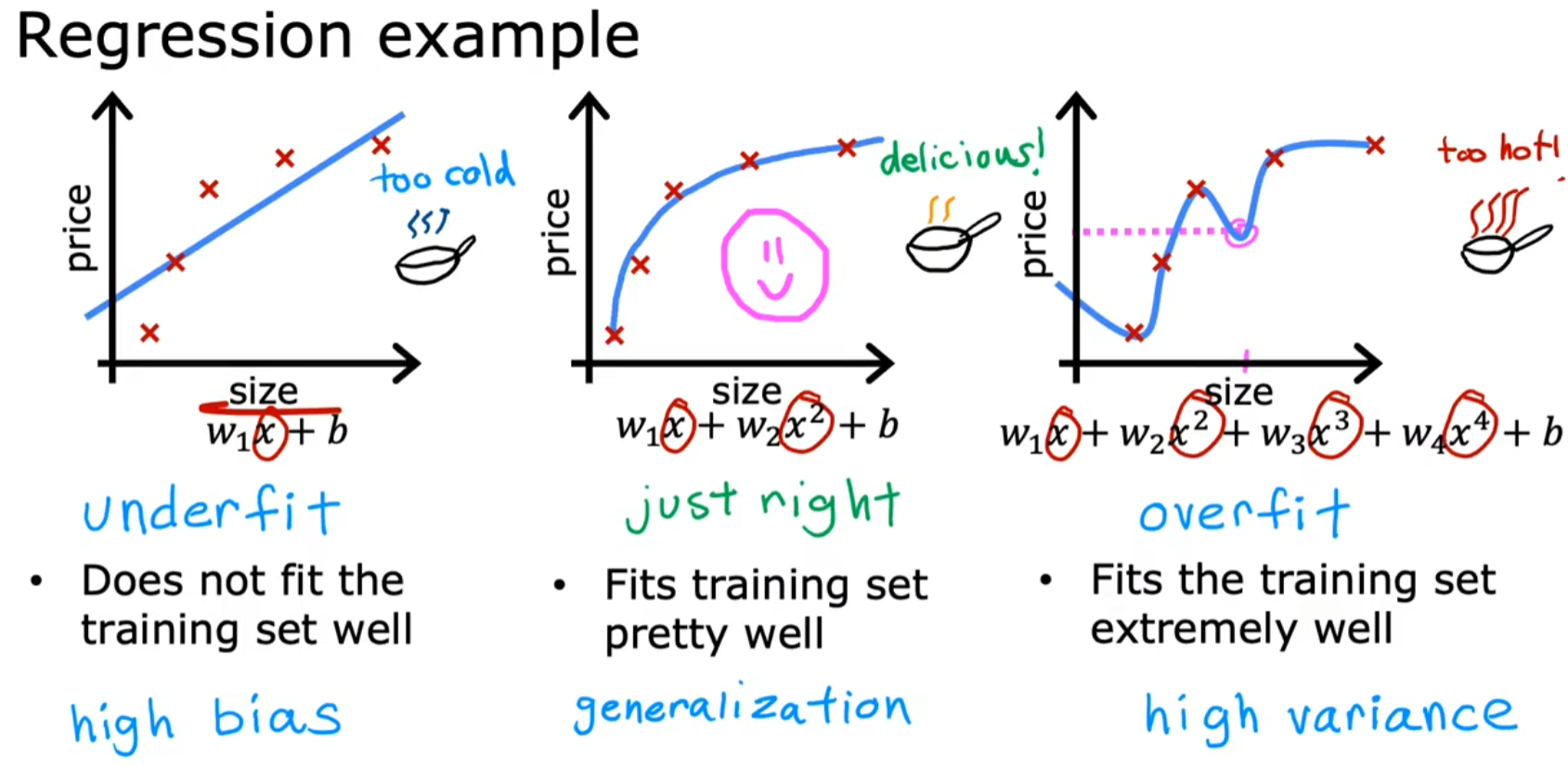
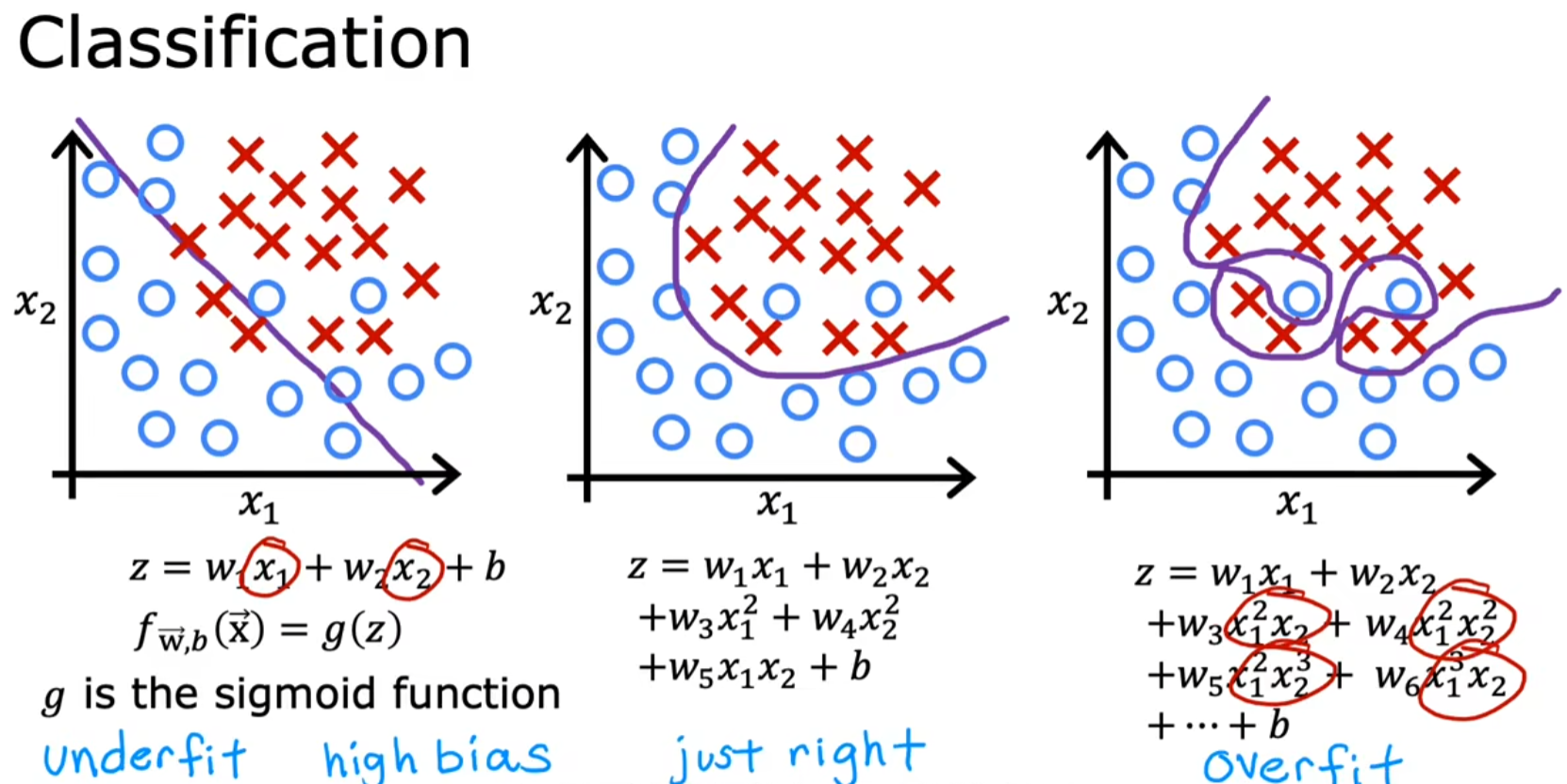
| 模型类型 | 拟合情况 | 问题 |
|---|---|---|
| 线性模型(一次多项式) | 直线拟合数据 | 欠拟合(高偏差),无法反映房价随面积增长而趋于平缓的趋势。 |
| 二次多项式 (加入 x 2 x^2 x2) | 曲线拟合数据 | 恰到好处,能较好捕捉数据趋势,泛化能力强。 |
| 四次多项式 (加入 x 3 , x 4 x^3,x^4 x3,x4) | 曲线完美穿过所有训练点 | 过拟合(高方差),模型波动剧烈,无法合理预测新数据。 |
1.2 解决过拟合
过拟合问题:
- 模型在训练集上表现极好,但在新数据上泛化能力差。
- 特征过多或模型过于复杂时容易发生(如高阶多项式回归)。
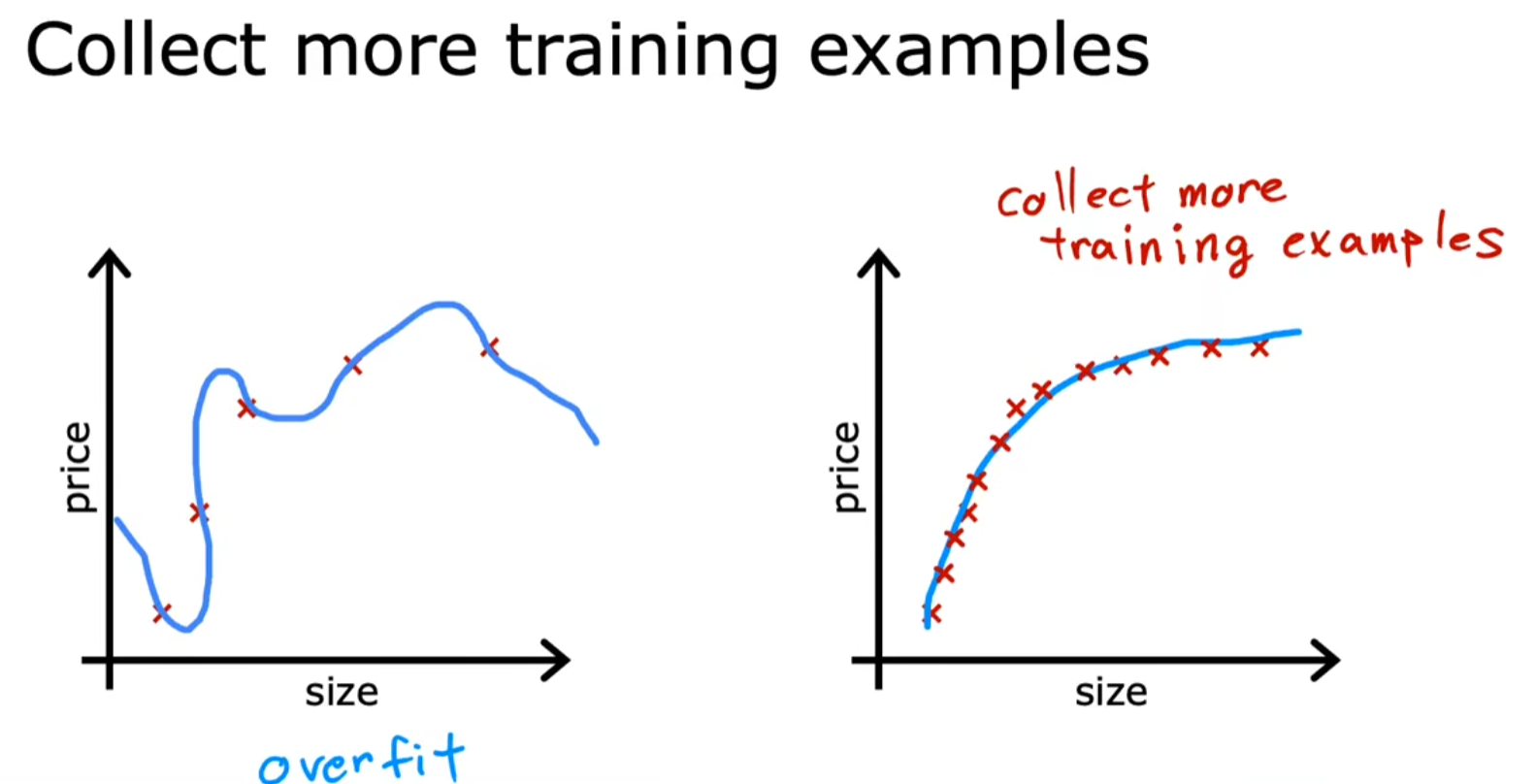
收集更多训练数据
- 原理:更多的数据能帮助模型学习更通用的模式,而非噪声。
- 适用场景:当数据获取成本较低时(如房价预测中新增房屋记录)。
- 局限性:某些领域数据稀缺(如罕见病例诊断)。
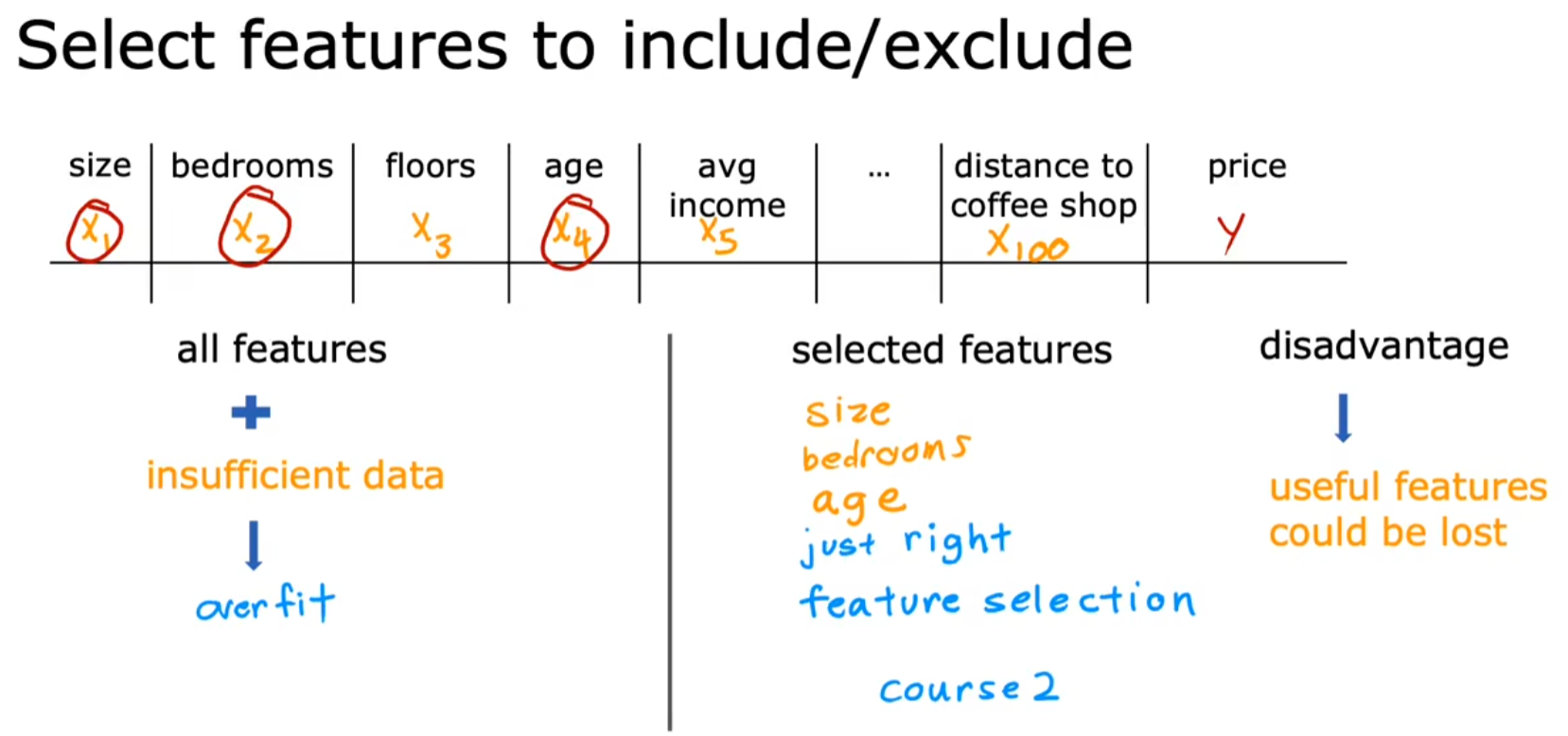
减少特征数量
- 原理:仅保留与目标最相关的特征,降低模型复杂度。
- 例如:房价预测中仅使用面积、卧室数量,而忽略到咖啡店距离等弱相关特征。
- 方法:
- 人工选择:基于领域知识筛选特征。
- 自动选择:后续课程会介绍算法(如递归特征消除)。
- 缺点:可能丢弃有用信息(若所有特征都有贡献)。
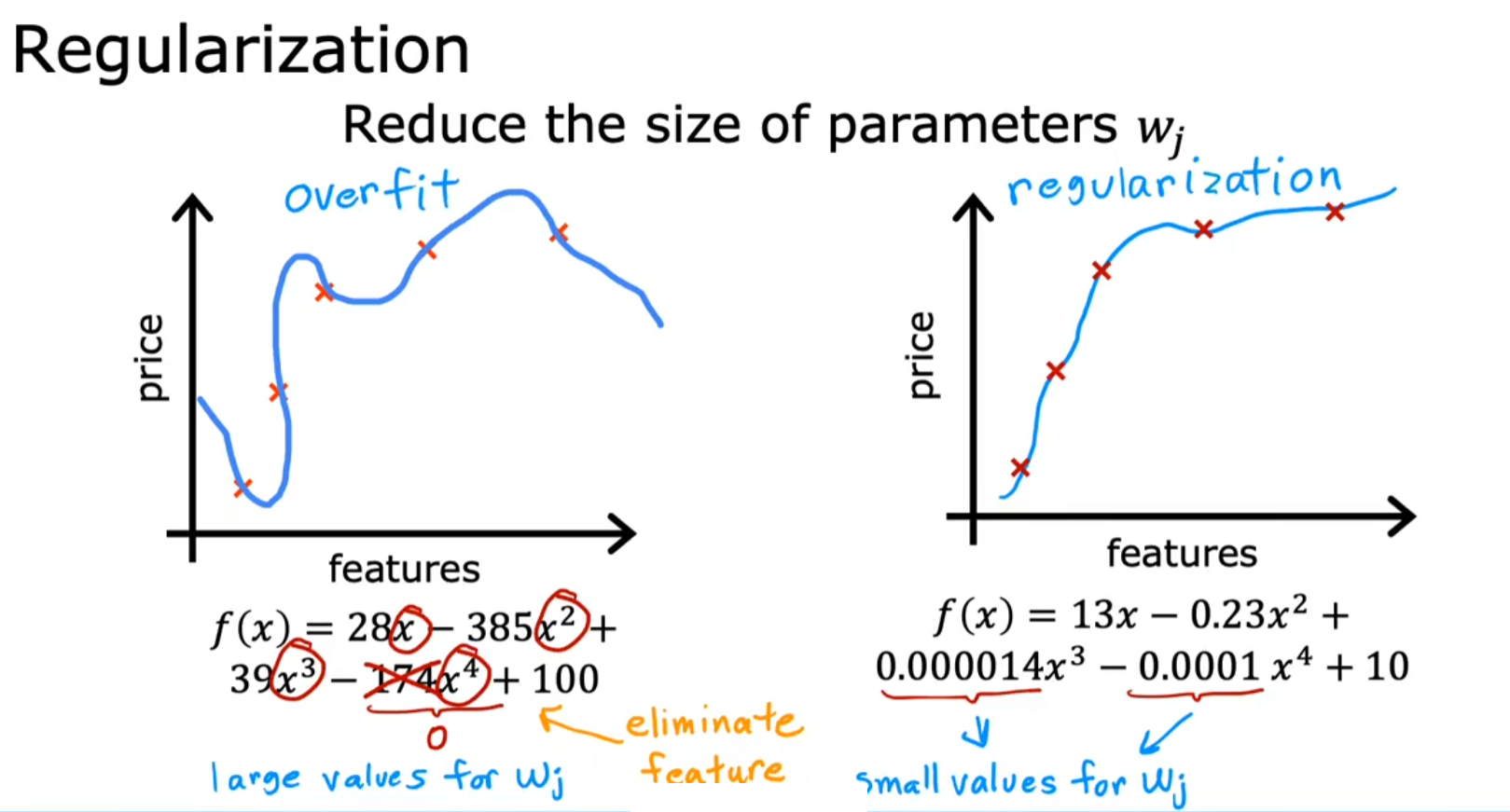
正则化(Regularization)
- 核心思想:不删除特征,而是通过惩罚大参数值( w j w_j wj)来限制模型复杂度。使参数值趋近于0(但不完全为 0),减弱不重要特征的影响。
- 优势:
- 保留所有特征,避免信息丢失。
- 尤其适用于特征多、数据少的场景(如医疗数据)。
- 注意:通常仅正则化权重参数 w 1 , w 2 , ⋯ , w n w_1,w_2,\cdots,w_n w1,w2,⋯,wn,偏置项 b b b 可忽略(对模型复杂度影响小)。
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 收集更多数据 | 直接提升泛化能力 | 成本高或不可行 | 数据易获取时优先使用 |
| 特征选择 | 简化模型,降低计算成本 | 可能丢失有用信息 | 特征间冗余性高时 |
| 正则化 | 保留所有特征,灵活控制复杂度 度) | 需调整超参数(如正则化强) | 最常用,尤其 适合高维数据 |
2 正则化
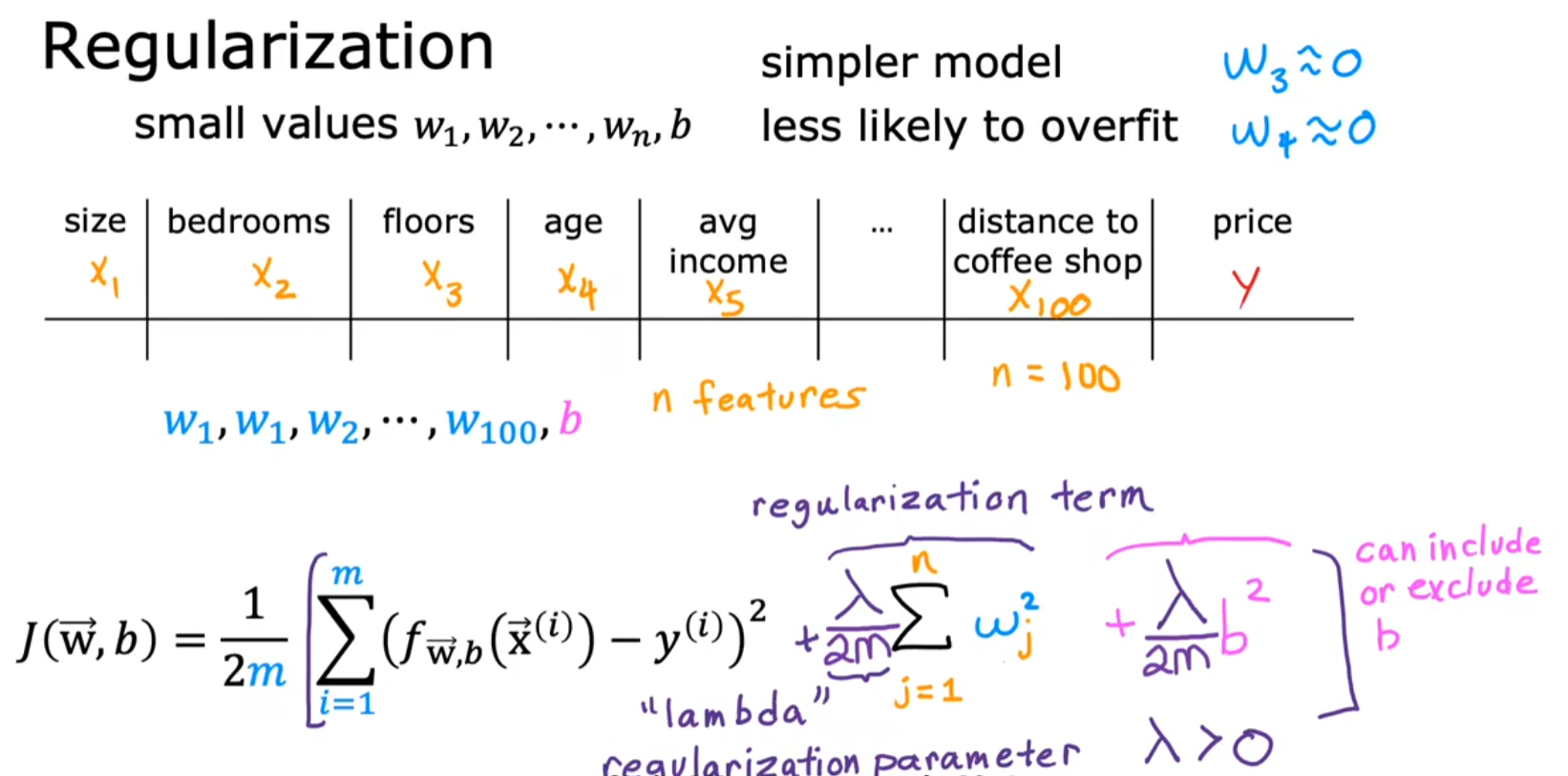
- 目标 :通过限制参数 w j w_j wj 的大小,降低模型复杂度,防止过拟合。
- 方法 :在成本函数中增加惩罚项,迫使算法选择较小的参数值。
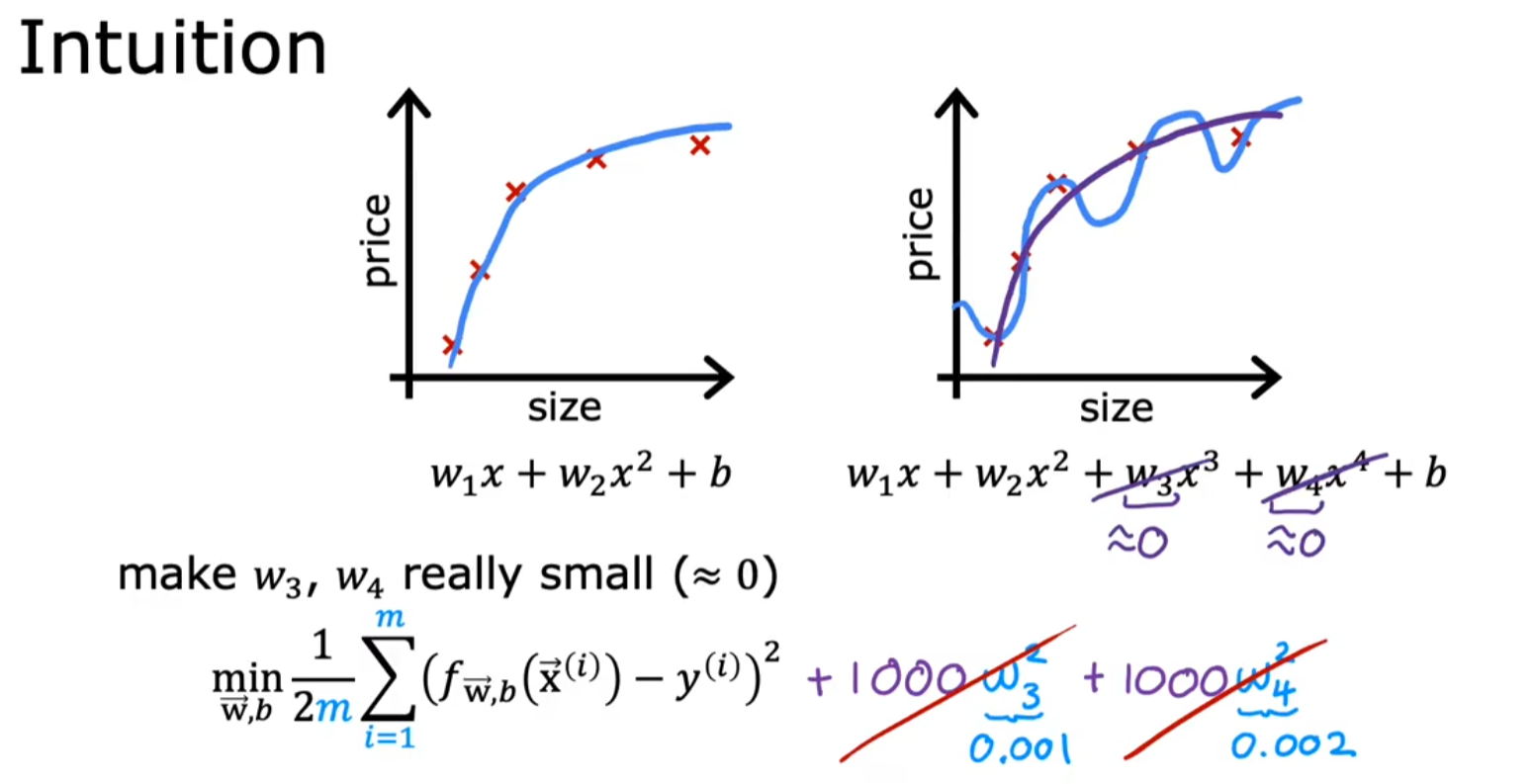
例如:对高阶多项式项(如 w 3 x 3 , w 4 x 4 w_3x^3,w_4x^4 w3x3,w4x4)的参数施加惩罚,使其接近 0,从而近似退化为低阶模型(如二次函数)。
2.1 正则化代价函数
线性回归的原始成本函数:
J ( w ⃗ , b ) = 1 2 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) 2 J(\vec{w},b)=\frac1{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2 J(w ,b)=2m1i=1∑m(fw ,b(x (i))−y(i))2
加入正则化项后:
J reg ( w ⃗ , b ) = 1 2 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J_\text{reg}{(\vec{w},b)}=\frac1{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac\lambda{2m}\sum_{j=1}^nw_j^2 Jreg(w ,b)=2m1i=1∑m(fw ,b(x (i))−y(i))2+2mλj=1∑nwj2
- 第一项:均方误差(拟合训练数据)。
- 第二项 :正则化项(惩罚大参数, λ \lambda λ 控制惩罚强度)。
- 注意 :
- 通常不惩罚偏置项 b b b(对模型复杂度影响极小)。
- 系数 1 2 m \displaystyle\frac{1}{2m} 2m1 用于统一缩放,便于选择 λ \lambda λ。
| λ λ λ 取值 | 影响 | 结果 |
|---|---|---|
| λ = 0 \lambda=0 λ=0 | 无正则化 | 可能过拟合(如高阶多项式完美拟合噪声)。 |
| λ λ λ 适中 | 平衡拟合与简化 | 模型复杂度降低,泛化能力增强(如保留四阶项但参数较小)。 |
| λ λ λ 极大(如 1010) | 过度惩罚 | 所有 w j ≈ 0 w_j\approx0 wj≈0,模型退化为水平线(欠拟合)。 |

2.2 线性回归的正则化
原始线性回归(无正则化)
- 权重 w j w_j wj
w j : = w j − α ∂ J ∂ w j , ∂ J ∂ w j = 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) x j ( i ) w_j:=w_j-\alpha\frac{\partial J}{\partial w_j},\quad\frac{\partial J}{\partial w_j}=\frac1m\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})x_j^{(i)} wj:=wj−α∂wj∂J,∂wj∂J=m1i=1∑m(fw ,b(x (i))−y(i))xj(i)
- 偏置 b b b
b : = b − α ∂ J ∂ b , ∂ J ∂ b = 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) b:=b-\alpha\frac{\partial J}{\partial b},\quad\frac{\partial J}{\partial b}=\frac1m\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}) b:=b−α∂b∂J,∂b∂J=m1i=1∑m(fw ,b(x (i))−y(i))

正则化线性回归
- 权重 w j w_j wj
- 新增项: λ m w j \displaystyle\frac{\lambda}{m}w_j mλwj(来自正则化项的导数)。
- 物理意义:每次迭代时, w j w_j wj 会被额外缩小 α λ m w j \alpha\displaystyle\frac{\lambda}{m}w_j αmλwj。
- 系数 1 − λ m 1-\displaystyle\frac{\lambda}{m} 1−mλ:由于 α \alpha α(学习率)和 λ \lambda λ 通常很小(如 α = 0.01 , λ = 1 \alpha=0.01,\lambda=1 α=0.01,λ=1), 1 − λ m 1-\displaystyle\frac{\lambda}{m} 1−mλ 略小于 1(如 0.9998)。每次迭代时, w j w_j wj 先轻微缩小(如乘以 0.9998),再减去原始梯度。从而逐步压缩参数值 w j w_j wj,防止其过大。
w j : = w j − α 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) x j ( i ) + λ m w j : = w j ( 1 − α λ m ) − α ⋅ (原始梯度项) \begin{aligned} w_j&:=w_j-\alpha\left\\frac1m\\sum_{i=1}\^m(f_{\\vec{w},b}(\\vec{x}\^{(i)})-y\^{(i)})x_j\^{(i)}+\\frac\\lambda mw_j\\right\\ &:=w_j\left(1-\alpha\frac\lambda m\right)-\alpha\cdot\text{(原始梯度项)} \end{aligned} wj:=wj−αm1i=1∑m(fw ,b(x (i))−y(i))xj(i)+mλwj:=wj(1−αmλ)−α⋅(原始梯度项)
- 偏置 b b b(不变)
- 不变原因:正则化通常不惩罚 b b b。
b : = b − α 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) b:=b-\alpha\frac1m\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}) b:=b−αm1i=1∑m(fw ,b(x (i))−y(i))

2.3 逻辑回归的正则化
- 权重 w j w_j wj
- 新增项: λ m w j \displaystyle\frac{\lambda}{m}w_j mλwj(来自正则化项的导数)。
- 物理意义:每次迭代时, w j w_j wj 会被额外缩小 α λ m w j \alpha\displaystyle\frac{\lambda}{m}w_j αmλwj(类似线性回归)。
w j : = w j − α 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) x j ( i ) + λ m w j : = w j ( 1 − α λ m ) − α ⋅ (原始梯度项) \begin{aligned} w_j&:=w_j-\alpha\left\\frac1m\\sum_{i=1}\^m(f_{\\vec{w},b}(\\vec{x}\^{(i)})-y\^{(i)})x_j\^{(i)}+\\frac\\lambda mw_j\\right\\ &:=w_j\left(1-\alpha\frac\lambda m\right)-\alpha\cdot\text{(原始梯度项)} \end{aligned} wj:=wj−αm1i=1∑m(fw ,b(x (i))−y(i))xj(i)+mλwj:=wj(1−αmλ)−α⋅(原始梯度项)
- 偏置 b b b(不变)
- 不变原因:正则化通常不惩罚 b b b。
b : = b − α 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) b:=b-\alpha\frac1m\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}) b:=b−αm1i=1∑m(fw ,b(x (i))−y(i))
