声明:本代码非原创,是博主跟着国外大佬的视频教程编写的,本博客主要为记录学习成果所用。
我们首先开始编写视觉模型这一部分,这一部分的主要功能是接收一个batch的图像,并将其转化为上下文相关的嵌入向量,在这一阶段,我们需要做的事情有以下这些
- 编写一个全局通用的视觉配置类
- 编写用户层的模型调用类
- 将输入图像嵌入为向量
- 通过transformer编码器将图像的嵌入向量进行编码使其上下文相关
我们将一个个地实现这些代码。
视觉 模型 的 配置
视觉模型的配置主要如下:
class` `SiglipVisionConfig:`
`def` `__init__(`
` self,`
` hidden_size=768,`
` num_hidden_layers=12,`
` num_attention_heads=12,`
` intermediate_size=3072,`
` num_channels=3,`
` image_size=224,`
` patch_size=16,`
` attention_dropout=0.0,`
` layer_norm_eps=1e-6,`
` num_image_tokens:` `int` `=` `None,`
`**kwargs`
`):`
`super().__init__(**kwargs)`
` self.hidden_size = hidden_size ## embedding 的维度`
` self.num_hidden_layers = num_hidden_layers ## 隐藏层的数量`
` self.num_attention_heads = num_attention_heads ## 注意力头数量`
` self.intermediate_size = intermediate_size ## 线性层的维度 `
` self.num_channels = num_channels ##图像的RGB通道`
` self.image_size = image_size ## 图像尺寸,任何图像size都会被缩放到这个尺寸`
` self.patch_size = patch_size ## 每个patch的尺寸`
` self.attention_dropout = attention_dropout ## 注意力层dropout`
` self.layer_norm_eps = layer_norm_eps ## 层归一化epsilon`
` self.num_image_tokens = num_image_tokens ## 图像token数量,它实际上是一个固定值`
`为了让各个变量的涵义更加浅显易懂,博主为其增加了中文注释
顶层 模型
随后是用户层模型,用户只需要将一个batch的图像传入,并调用forward函数,即可返回这些图像的上下文相关的embeddings。
代码如下:
class` `SiglipVisionModel(nn.Module):` `## 最顶层的视觉模型,它负责顶层的传入和编码的输出`
`def` `__init__(self, config:SiglipVisionConfig):`
`super().__init__()`
`self.config = config`
`self.vision_model =` `SiglipVisionTransformer(config)`
`def` `forward(self, pixel_values)` `->` `Tuple:`
`# [Batch_size,Channels,Height,Width] -> [Batch_size,Num_Patches(num_image_token),Embedding_size(Hidden_size)]`
`return` `self.vision_model(pixel_values = pixel_values)`
`其中,输入的形状是 ** **Batch_size, Channels, Height, Width , 对应一个图像batch各自的RGB通道的像素值,输出是 ** **Batch_size, Num_Patches, Embedding_size , 对应各个图像的每个分割Patch的嵌入结果。
模型 拆分
我们需要在内部将一次视觉模型的调用拆分成两个模型各自的调用,也就是拆分成嵌入模型和Transformer编码器,这里我们创建了一个SiglipVisionTransformer类,将其分成两个模型的调用:
代码如下:
class` `SiglipVisionTransformer(nn.Module):` `##视觉模型的第二层,将模型的调用分为了图像嵌入模型和transformer编码器模型的调用`
`def` `__init__(self, config:SiglipVisionConfig):`
`super().__init__()`
`self.config = config`
`self.embed_dim = config.hidden_size`
`self.embeddings =` `SiglipVisionEmbeddings(config)` `## 负责将图像嵌入成向量`
`self.encoder =` `SiglipEncoder(config)` `## 负责将向量编码成注意力相关的向量`
`self.post_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)` `## 层归一化`
`def` `forward(self, pixel_values:torch.Tensor)` `-> torch.Tensor:`
`"""`
` pixel_values:` `[Batch_size,Channels,Height,Width]`
`"""`
`## [ Batch_size,Channels,Height,Width] -> [Batch_size,Num_Patches,Embedding_size] `
` hidden_states =` `self.embeddings(pixel_values)` `## 将图像嵌入成向量`
`# [Batch_size,Num_Patches,Embedding_size] -> [Batch_size,Num_Patches,Embedding_size]`
` last_hidden_state =` `self.encoder(hidden_states)` `## 将向量编码成注意力相关的向量`
`# [Batch_size,Num_Patches,Embedding_size] -> [Batch_size,Num_Patches,Embedding_size]`
` last_hidden_state =` `self.post_layer_norm(last_hidden_state)`
`return last_hidden_state`
`嵌入 层 模型
嵌入层模型会将初始的图像像素值初步转换为patch的编码向量list, 同时在此阶段我们也会使用位置编码,位置编码的形式有多种,这里我们采用自学习的嵌入向量,即为每个位置创建一个可以学习的参数向量,形成位置矩阵,使用的时候根据indices从位置矩阵中抽取对应的位置向量即可。
代码:
class SiglipVisionEmbeddings(nn.Module):`
` def __init__(self, config:SiglipVisionConfig):`
` self.config = config`
` self.patch_size = config.patch_size`
` self.image_size = config.image_size`
` self.embed_dim = config.hidden_size`
` self.patch_embedding = nn.Conv2d(`
` in_channels = config.num_channels,`
` out_channels = self.embed_dim,`
` kernel_size = self.patch_size,`
` stride = self.patch_size,`
` padding =` `'valid',` `##不加padding`
`)`
` self.num_patches =` `(self.image_size // self.patch_size)` `**` `2` `## 图像的patch数量 (224 // 16) ** 2 = 196`
` self.num_positions = self.num_patches`
` self.position_embeddings = nn.Embedding(self.num_positions, self.embed_dim)`
` self.register_buffer(`
`"position_ids",`
` torch.arange(self.num_positions).expand((1,` `-1)),` `## 这里expand是为了保持和patch_embeds的维度一致,以便可以直接与之相加`
` persistent=False,`
`)`
` def forward(self, pixel_values:torch.FloatTensor)` `-> torch.Tensor:`
`"""`
` pixel_values: [Batch_size,Channels,Height,Width]`
` """`
` _ , _ , height, width = pixel_values.shape`
`## 卷积,3通道转embedding_size通道`
` patch_embeds = torch.FloatTensor(self.patch_embedding(pixel_values))` `## [Batch_size,Channel,Height,Width] -> [Batch_size,Embedding_size,Num_Patches_Height,Num_Patches_Width]`
`## flatten`
` patch_embeds = patch_embeds.flatten(2)` `# [Batch_size,Embedding_size,Num_Patches_Height,Num_Patches_Width] -> [Batch_size,Embedding_size,Num_Patches]`
`## transpose`
` patch_embeds = patch_embeds.transpose(1,2)` `## [Batch_size,Embedding_size,Num_Patches] -> [Batch_size,Num_Patches,Embedding_size] `
`## positon_encoding`
` patch_embeds = patch_embeds + self.position_embeddings(self.position_ids)` `## [Batch_size,Num_Patches,Embedding_size] 自学习的位置编码`
`return patch_embeds`
`上面的卷积配置表示我们希望卷积的结果是patch_size * embedding_size的维度,为了方便大家理解
这里简单介绍一下torch的卷积:
p y t o r c h 的 2D卷积
卷积是通过卷积核将图像的特征提取出来,卷积操作可以如图所示: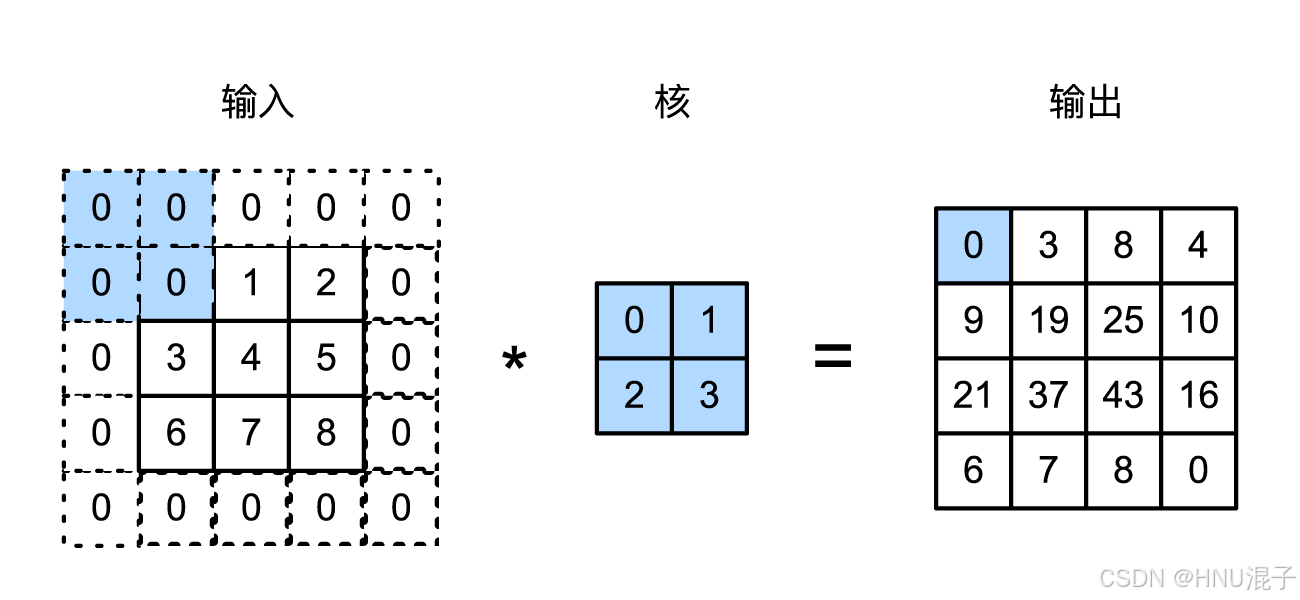
卷积操作本质上是把输入区域展平为向量,同时把卷积核展平为向量再做一次内积得到输出位置的值。
torch的卷积公式:
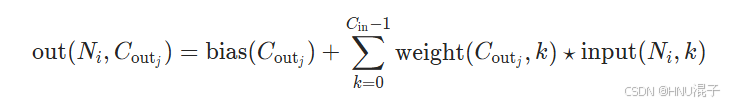
这里N_i 是第i个batch,Cout_j 是指第j个输出通道的输出值,星号代表在二维区域用weight权重核对input区域做一次卷积。
这里可以看到多出了一个通道的概念,其实对于图像来说输入通道就是RGB通道,输出通道是只你希望一个卷积的图像区域有多少个特征。
用图来展示的话如下:

这里彩色的方块指的是1*1的卷积核,我们希望对一个有三个输入通道的输入做卷积,并得到三个输出通道的输出,这样的话对于每个通道,conv2D都会为其生成三个卷积核,每个通道的卷积结果按卷积核的顺序对应相加,比如第一个输出通道的结果等于三个输入通道与各自第一个卷积核卷积的结果进行相加得到。
由此再来看这个公式:
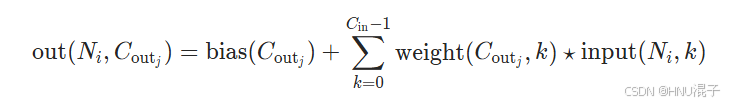
第j个输出通道的结果等于所有输入通道与第j个输出通道的卷积核卷积的结果相加再加上一个偏置矩阵得到。