文章目录
- [SpringCloud Alibaba](#SpringCloud Alibaba)
- 六、Seata
-
- 5、多数据源分布式事务
-
- [5.1 操作多数据源](#5.1 操作多数据源)
-
- [5.1.1 创建多个数据源](#5.1.1 创建多个数据源)
- [5.1.2 创建DynamicRoutingDataSource](#5.1.2 创建DynamicRoutingDataSource)
- [5.1.3 创建切面](#5.1.3 创建切面)
- 6、接入微服务应用
-
- [6.1 版本处理](#6.1 版本处理)
- [6.2 引入依赖](#6.2 引入依赖)
- [6.3 数据源设置为代理](#6.3 数据源设置为代理)
- [6.4 排除数据源的自动配置方式循环依赖](#6.4 排除数据源的自动配置方式循环依赖)
- [6.5 增加配置](#6.5 增加配置)
- [6.6 微服务中创建undo\_log](#6.6 微服务中创建undo_log)
- [7、XA 模式设计思路](#7、XA 模式设计思路)
-
- [7.1 前提](#7.1 前提)
- [7.2 整体机制](#7.2 整体机制)
- [7.3 XA模式使用](#7.3 XA模式使用)
- [7.4 Seata XA模式优势确定](#7.4 Seata XA模式优势确定)

SpringCloud Alibaba
Spring Cloud Alibaba是阿里巴巴提供的一站式微服务解决方案,是Spring Cloud体系中的一个重要分支,它将阿里巴巴在微服务领域的实践经验和开源技术进行了整合,为开发者提供了一系列便捷的工具和组件,用于构建分布式微服务应用。以下是其详细介绍:
1、核心组件
- Nacos:用于服务注册与发现以及配置管理。它可以帮助微服务实例自动注册到注册中心,并能够动态获取配置信息,使应用程序能够灵活地应对配置的变化,无需重启服务。
- Sentinel:主要用于流量控制、熔断降级等功能。它可以保护微服务免受高并发、流量异常等情况的影响,确保系统在压力下能够稳定运行,避免因个别服务出现问题而导致整个系统崩溃。
- RocketMQ:是一款高性能、高可靠的分布式消息队列。它在微服务架构中常用于实现异步消息传递、解耦系统组件之间的依赖关系,从而提高系统的整体性能和可扩展性。
- Seata:致力于提供分布式事务解决方案,确保在分布式系统中数据的一致性。它通过对事务的协调和管理,使得多个微服务之间在进行数据交互时能够遵循ACID原则。
2、优势
- 一站式解决方案:涵盖了微服务架构中的多个关键领域,包括服务治理、配置管理、流量控制、分布式事务等,开发者无需再从多个不同的开源项目中进行整合,大大降低了微服务架构的搭建和维护成本。
- 与Spring Cloud生态的深度集成:基于Spring Cloud的编程模型和规范进行开发,使得熟悉Spring Cloud的开发者能够快速上手并轻松集成到现有的Spring Cloud项目中,充分利用Spring Cloud的各种特性和优势。
- 阿里巴巴的技术实力和实践经验支持:得益于阿里巴巴在大规模分布式系统开发和运营方面的丰富经验,Spring Cloud Alibaba的组件经过了实际生产环境的考验,具有较高的稳定性、性能和可扩展性,能够应对各种复杂的业务场景和高并发流量。
3、应用场景
- 电商系统:在电商业务中,存在多个微服务,如商品服务、订单服务、库存服务等。Spring Cloud Alibaba可以通过Nacos进行服务注册与发现,使用Sentinel对各个服务的流量进行控制,利用RocketMQ实现异步消息通知,比如下单成功后异步通知库存服务扣减库存,通过Seata保证分布式事务的一致性,确保订单和库存等数据的准确性。
- 金融系统:金融领域对数据一致性和系统稳定性要求极高。Spring Cloud Alibaba的Seata可以确保在多个金融业务操作之间的分布式事务一致性,如转账操作涉及到两个不同账户服务之间的资金变动。Nacos可以提供配置管理,方便对金融业务的各种配置参数进行动态调整,Sentinel则可以防止因突发的高并发交易对系统造成冲击。
- 物联网(IoT)平台:物联网场景中,大量的设备会产生实时数据并上传到云端。Spring Cloud Alibaba可以通过Nacos管理各个物联网服务的注册与发现,使用RocketMQ接收和处理大量的设备数据消息,进行异步处理和分发。Sentinel可以对物联网服务的流量进行控制,防止因设备数据突发增长导致系统过载。
六、Seata
5、多数据源分布式事务
5.1 操作多数据源
5.1.1 创建多个数据源
这里配置了我们的所有数据库,并将数据库添加DynamicRoutingDataSource这个动态数据库中,并设置了目标数据源和配置的数据源,配置的数据源以map形式存放,然后将DynamicRoutingDataSource数据源传递给了mybatis,mybatis操作数据库就是通过他来操作
java
@Configuration
@MapperScan("com.dyll.seata.multiple.mapper")
public class DataSourceProxyConfig {
@Bean("originOrder")
@ConfigurationProperties(prefix = "spring.datasource.order")
public DataSource dataSourceMaster() {
return new DruidDataSource();
}
@Bean("originStorage")
@ConfigurationProperties(prefix = "spring.datasource.storage")
public DataSource dataSourceStorage() {
return new DruidDataSource();
}
@Bean("originAccount")
@ConfigurationProperties(prefix = "spring.datasource.account")
public DataSource dataSourceAccount() {
return new DruidDataSource();
}
@Bean("dynamicDataSource")
public DataSource dynamicDataSource(@Qualifier("originOrder") DataSource dataSourceOrder,
@Qualifier("originStorage") DataSource dataSourceStorage,
@Qualifier("originAccount") DataSource dataSourceAccount) {
DynamicRoutingDataSource dynamicRoutingDataSource = new DynamicRoutingDataSource();
// 数据源的集合
Map<Object, Object> dataSourceMap = new HashMap<>(3);
dataSourceMap.put(DataSourceKey.ORDER.name(), dataSourceOrder);
dataSourceMap.put(DataSourceKey.STORAGE.name(), dataSourceStorage);
dataSourceMap.put(DataSourceKey.ACCOUNT.name(), dataSourceAccount);
// 设置默认的数据源
dynamicRoutingDataSource.setDefaultTargetDataSource(dataSourceOrder);
// 设置目标数据源
dynamicRoutingDataSource.setTargetDataSources(dataSourceMap);
DynamicDataSourceContextHolder.getDataSourceKeys().addAll(dataSourceMap.keySet());
return dynamicRoutingDataSource;
}
@Bean
@ConfigurationProperties(prefix = "mybatis")
public SqlSessionFactoryBean sqlSessionFactoryBean(@Qualifier("dynamicDataSource") DataSource dataSource) {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
org.apache.ibatis.session.Configuration configuration=new org.apache.ibatis.session.Configuration();
//使用jdbc的getGeneratedKeys获取数据库自增主键值
configuration.setUseGeneratedKeys(true);
//使用列别名替换列名
configuration.setUseColumnLabel(true);
//自动使用驼峰命名属性映射字段,如userId ---> user_id
configuration.setMapUnderscoreToCamelCase(true);
sqlSessionFactoryBean.setConfiguration(configuration);
return sqlSessionFactoryBean;
}
}5.1.2 创建DynamicRoutingDataSource
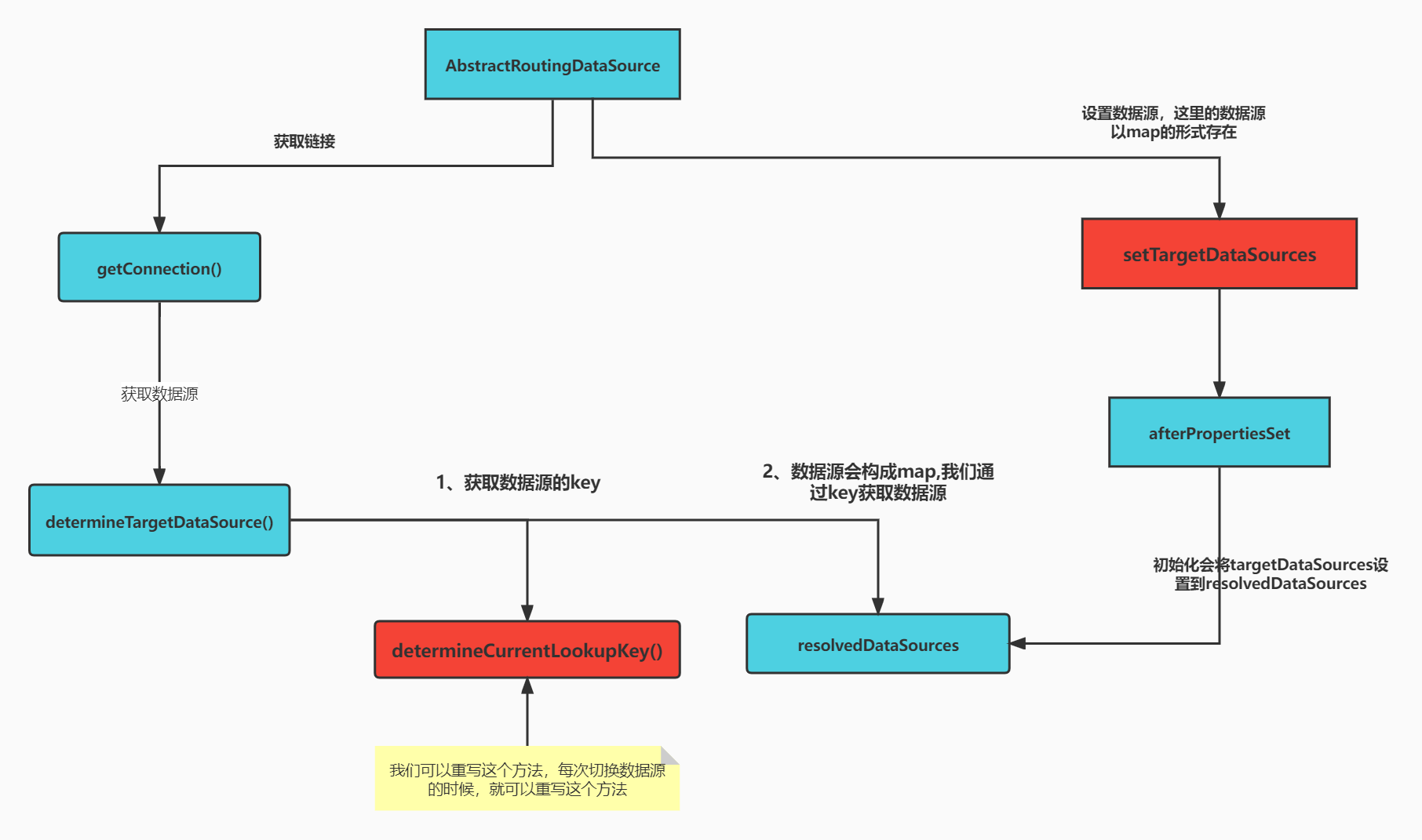
DynamicRoutingDataSource继承了AbstractRoutingDataSource,并且重写了determineCurrentLookupKey方法,这个方法,是在getConnection时候我们会调用这个方法活去对应的key,然后再对应我们的map数据库集合中获取对应的数据源。后面我们在源码讲解
java
@Slf4j
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {
/**
* 该方法的返回值就是项目中所要用的DataSource的key值,
* 拿到该key后就可以在resolvedDataSource中取出对应的DataSource,
* 如果key找不到对应的DataSource就使用默认的数据源。
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
log.info("当前数据源 [{}]", DynamicDataSourceContextHolder.getDataSourceKey());
return DynamicDataSourceContextHolder.getDataSourceKey();
}
public static void main(String[] args) {
System.out.println(DynamicDataSourceContextHolder.getDataSourceKey());
}
}5.1.3 创建切面
我们对应的service 上都是有@Datasource注解,这个注解DynamicDataSourceAspect会在方法调用的时候进行拦截,在方法之间会解析@Datasource中的值,会将其设置到ThreadLocal里面,这里面DynamicDataSourceContextHolder,然后调用mybatis时候获取链接的时候时候会带调用上面的类determineCurrentLookupKey获取对应的key,我们通过这个key可以获取对应的数据源
java
@Aspect
@Component
public class DynamicDataSourceAspect {
private static final Logger logger = LoggerFactory.getLogger(DynamicDataSourceAspect.class);
@Before("@annotation(ds)")
public void changeDataSource(JoinPoint point, DataSource ds) throws Throwable {
DataSourceKey dsId = ds.value();
if (DynamicDataSourceContextHolder.isContainsDataSource(dsId.name())) {
DynamicDataSourceContextHolder.setDataSourceKey(dsId);
logger.debug("Use DataSource :{} >", dsId, point.getSignature());
} else {
logger.error("数据源[{}]不存在,使用默认数据源 >{}", dsId, point.getSignature());
}
}
@After("@annotation(ds)")
public void restoreDataSource(JoinPoint point, DataSource ds) {
logger.debug("Revert DataSource : " + ds.value() + " > " + point.getSignature());
DynamicDataSourceContextHolder.clearDataSourceKey();
}
}首先我们给DynamicRoutingDataSource设置数据源setTargetDataSources 是一个map数据源,设置完后afterPropertiesSet方法里面会将我们设置的map设置到我们的resovledDataSources中
当我调用getConnnection时候会调用DetermineTargetDataSources方法,这个方法会调用我们重写的determineCourrentLookupKey,从而获取数据源对应的ekey
最后 通过key从resolveDataSources中获取了对应的数据源。
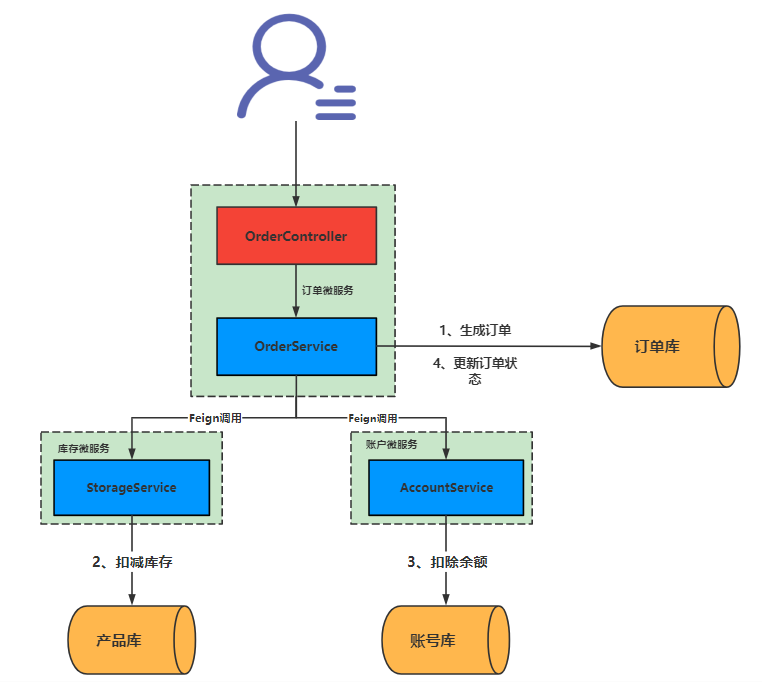
6、接入微服务应用
业务场景:
用户下单,整个业务逻辑由三个微服务构成:
- 仓储服务:对给定的商品扣除库存数量。
- 订单服务:根据采购需求创建订单。
- 帐户服务:从用户帐户中扣除余额。
6.1 版本处理
| Spring Cloud Alibaba Version | Spring Cloud Version | Spring Boot Version | Nacos Version | Seata Version |
|---|---|---|---|---|
| 2.2.9.RELEASE | Hoxton.SR12 | 2.3.12.RELEASE | 2.1.0 | 1.5.2 |
6.2 引入依赖
<!--引入seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
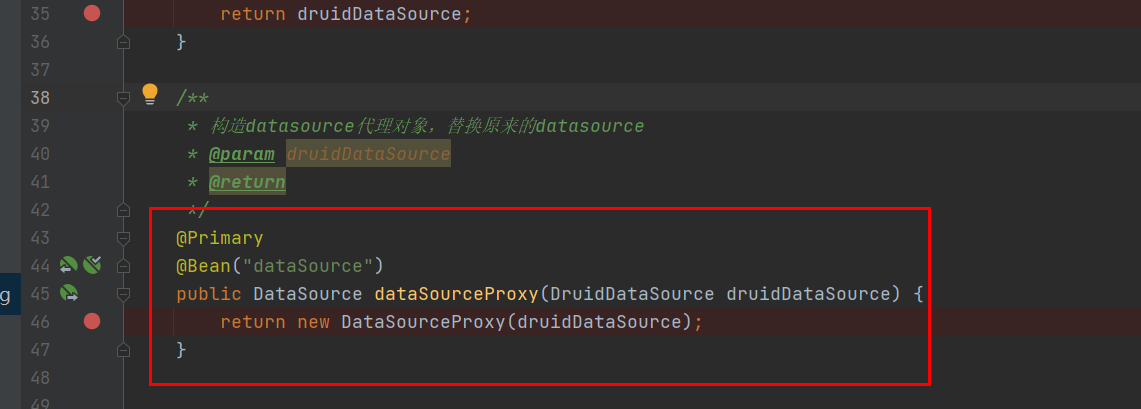
</dependency>6.3 数据源设置为代理
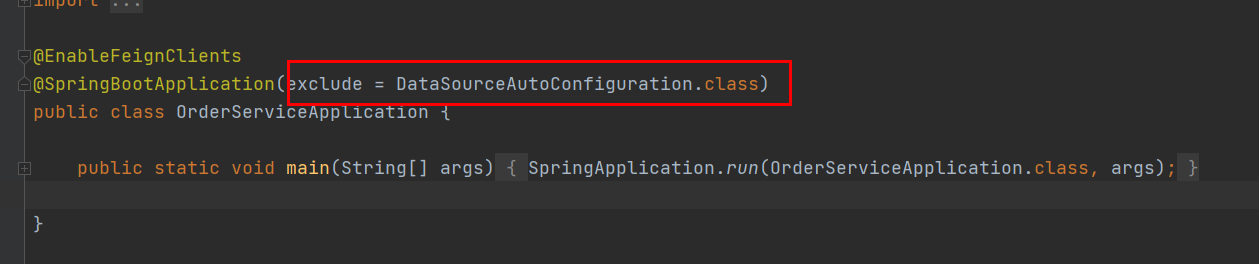
6.4 排除数据源的自动配置方式循环依赖
6.5 增加配置
seata:
application-id: ${spring.application.name}
# seata 服务分组,要与服务端配置service.vgroup_mapping的后缀对应
tx-service-group: default_tx_group
registry:
# 指定nacos作为注册中心
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
namespace:
group: SEATA_GROUP
config:
# 指定nacos作为配置中心
type: nacos
nacos:
server-addr: 127.0.0.1:8848
namespace: seata
group: SEATA_GROUP
data-id: seataServer.properties6.6 微服务中创建undo_log
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';7、XA 模式设计思路
7.1 前提
- 支持XA 事务的数据库。
- Java 应用,通过 JDBC 访问数据库。
7.2 整体机制
在 Seata 定义的分布式事务框架内,利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种 事务模式。
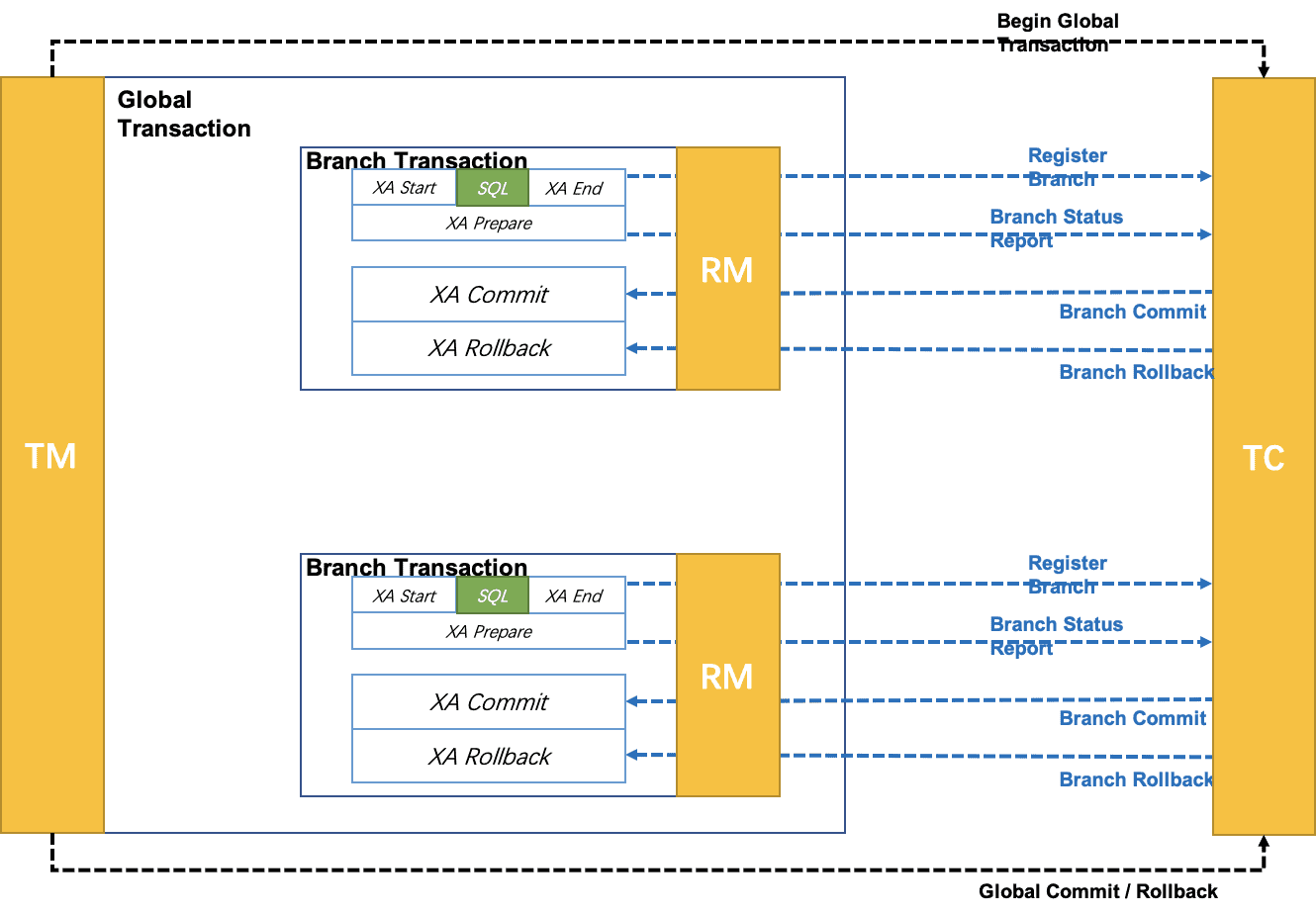
- 执行阶段:
- 可回滚:业务 SQL 操作放在 XA 分支中进行,由资源对 XA 协议的支持来保证 可回滚
- 持久化:XA 分支完成后,执行 XA prepare,同样,由资源对 XA 协议的支持来保证 持久化 (即,之后任何意外都不会造成无法回滚的情况)
- 完成阶段:
- 分支提交:执行 XA 分支的 commit
- 分支回滚:执行 XA 分支的 rollback
7.3 XA模式使用
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}设置XA模式
seata:
data-source-proxy-mode: XA7.4 Seata XA模式优势确定
优势
- 业务无侵入:和 AT 一样,XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
- 支持多种数据库 :XA 协议被主流关系型数据库广泛支持,不需要额外的适配即可使用
- 支持多种语言
缺点:
会有阻塞模式 ,降低性能