文章目录
-
- 引言
- 一、核心概念梳理
-
- [1.1 基础术语(对比关系型数据库)](#1.1 基础术语(对比关系型数据库))
- [1.2 核心概念详解](#1.2 核心概念详解)
- [二、Elasticsearch 架构原理](#二、Elasticsearch 架构原理)
-
- [2.1 集群架构](#2.1 集群架构)
- [2.2 数据写入流程](#2.2 数据写入流程)
- [2.3 数据查询流程](#2.3 数据查询流程)
- [三、快速实践:基于 Spring Boot 集成 Elasticsearch](#三、快速实践:基于 Spring Boot 集成 Elasticsearch)
-
- [3.1 环境准备](#3.1 环境准备)
- [3.2 依赖引入](#3.2 依赖引入)
- [3.3 配置文件](#3.3 配置文件)
- [3.4 代码实现](#3.4 代码实现)
-
- [3.4.1 实体类(映射配置)](#3.4.1 实体类(映射配置))
- [3.4.2 Repository 接口](#3.4.2 Repository 接口)
- [3.4.3 服务层与测试](#3.4.3 服务层与测试)
- [3.5 测试结果](#3.5 测试结果)
- 四、高级特性深度解析
-
- [4.1 聚合分析(Aggregation)](#4.1 聚合分析(Aggregation))
-
- [4.1.1 桶聚合(Bucket Aggregation)](#4.1.1 桶聚合(Bucket Aggregation))
- [4.1.2 指标聚合(Metric Aggregation)](#4.1.2 指标聚合(Metric Aggregation))
- [4.2 分词器定制](#4.2 分词器定制)
-
- [4.2.1 安装 IK 分词器](#4.2.1 安装 IK 分词器)
- [4.2.2 自定义分词词典](#4.2.2 自定义分词词典)
- [4.3 高亮查询](#4.3 高亮查询)
- [4.4 索引生命周期管理(ILM)](#4.4 索引生命周期管理(ILM))
- 五、实践优化建议
-
- [5.1 索引设计优化](#5.1 索引设计优化)
- [5.2 查询性能优化](#5.2 查询性能优化)
- [5.3 集群运维优化](#5.3 集群运维优化)
- 六、常见问题与解决方案
- 七、总结与展望
- 参考资料
引言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在大数据时代,用户对数据检索的需求日益复杂,传统关系型数据库在全文检索、海量数据高效查询等场景下逐渐力不从心。Elasticsearch(简称 ES)作为一款开源的分布式全文搜索引擎,基于 Lucene 构建,具备高可用、高扩展、近实时检索等核心特性,广泛应用于日志分析、电商搜索、监控告警、智能推荐等领域。
本文将从核心概念、架构原理、快速实践、高级特性到性能优化,全面拆解 Elasticsearch 的技术细节,帮助开发者系统掌握这一主流搜索引擎的使用与调优技巧。
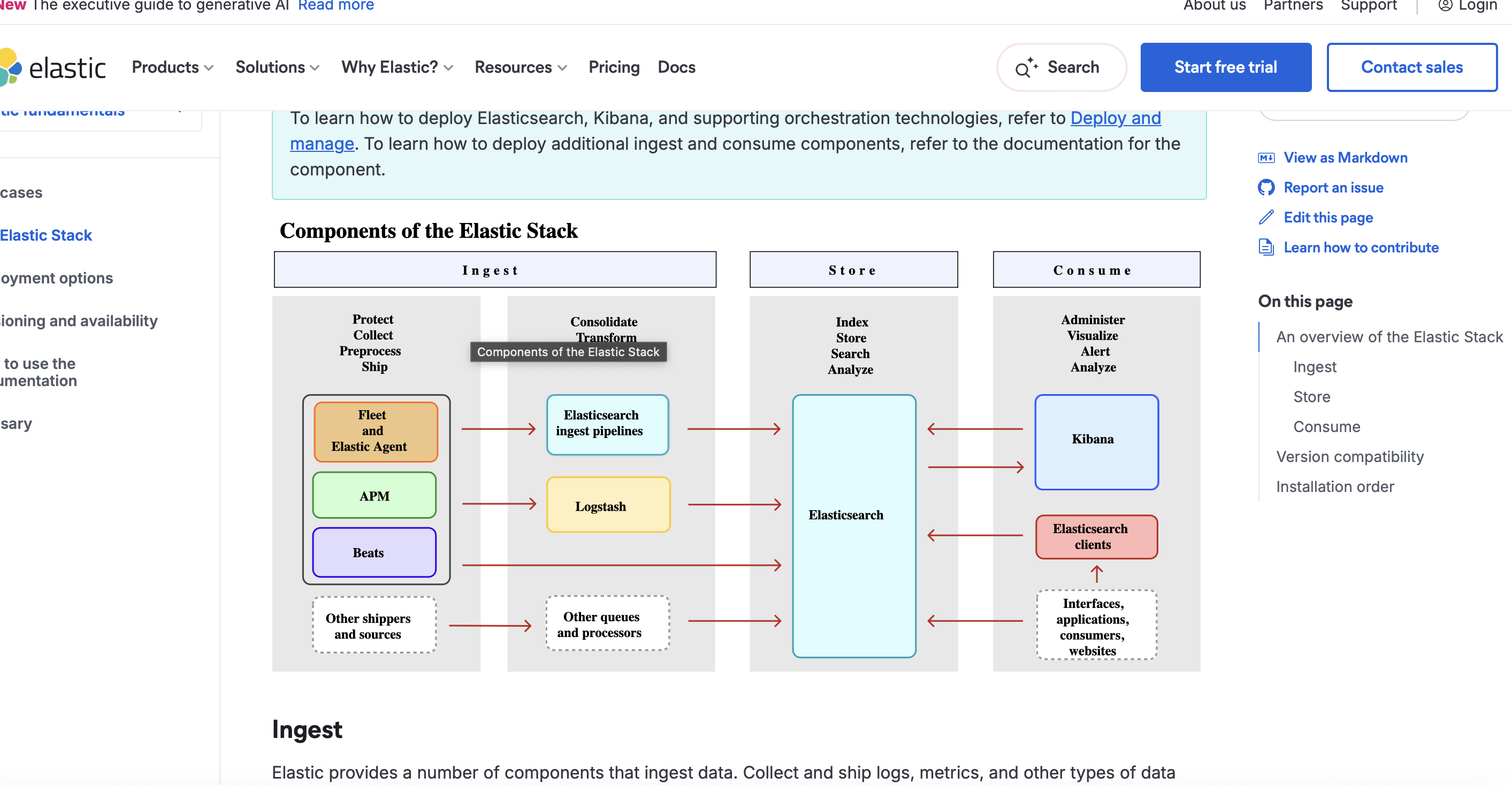
一、核心概念梳理
1.1 基础术语(对比关系型数据库)
| Elasticsearch 术语 | 关系型数据库术语 | 说明 |
|---|---|---|
| 索引(Index) | 数据库(Database) | 存储相同类型文档的集合,如"商品索引""用户索引" |
| 类型(Type) | 表(Table) | 索引内部的文档分类(ES 7.x 后已废弃,一个索引仅对应一种文档类型) |
| 文档(Document) | 行(Row) | 索引中的最小数据单元,以 JSON 格式存储 |
| 字段(Field) | 列(Column) | 文档中的属性,如商品的"名称""价格"字段 |
| 映射(Mapping) | 表结构(Schema) | 定义文档中字段的类型、分词器等属性的元数据 |
| 分片(Shard) | - | 索引的物理拆分单元,分布式存储的核心,分为主分片和副本分片 |
| 副本(Replica) | - | 主分片的备份,用于故障恢复和负载分担 |
1.2 核心概念详解
- 分片(Shard) :
- 主分片(Primary Shard):数据写入的核心分片,索引创建时指定数量(默认 5 个),创建后不可修改。
- 副本分片(Replica Shard):主分片的备份,可动态调整数量(默认 1 个),仅用于查询和故障转移。
- 集群(Cluster):由多个节点组成的分布式系统,共享同一集群名称(默认 "elasticsearch")。
- 节点(Node) :集群中的单个服务器,按功能可分为:
- 主节点(Master Node):管理集群元数据(如索引创建、分片分配),默认所有节点均可作为主节点候选。
- 数据节点(Data Node):存储数据分片,处理读写请求。
- 协调节点(Coordinating Node):转发请求、合并查询结果,默认所有节点都是协调节点。
- 分词器(Analyzer) :将文本字段拆分为术语(Term)的工具,由字符过滤器、分词器、令牌过滤器组成,默认使用
standard分词器。
二、Elasticsearch 架构原理
2.1 集群架构
Elasticsearch 采用去中心化架构,无单点故障风险,核心架构特点:
- 所有节点平等,主节点通过选举产生(基于 Zen Discovery 协议)。
- 数据分片均匀分布在不同数据节点,副本分片与主分片不在同一节点。
- 协调节点接收客户端请求后,路由到对应数据节点执行操作。
2.2 数据写入流程
- 客户端向协调节点发送写入请求。
- 协调节点根据文档 ID 的哈希值计算目标主分片。
- 主分片执行写入操作(先写入内存缓冲区,同时记录事务日志)。
- 主分片同步数据到所有副本分片。
- 所有副本分片确认写入成功后,主分片返回成功响应给客户端。
- 后台定期将内存缓冲区数据刷盘(默认每 1 秒或缓冲区满时),生成段文件(Segment)。
2.3 数据查询流程
- 客户端向协调节点发送查询请求。
- 协调节点将请求广播到所有相关分片(主分片或副本分片)。
- 各分片执行查询并返回Top N结果给协调节点。
- 协调节点合并结果并排序,返回最终结果给客户端。
三、快速实践:基于 Spring Boot 集成 Elasticsearch
3.1 环境准备
- 技术栈:Spring Boot 2.7.x + Spring Data Elasticsearch 4.4.x + Elasticsearch 7.17.x
- 前提:本地或服务器已部署 Elasticsearch 服务(默认端口 9200)。
3.2 依赖引入
xml
<!-- Spring Data Elasticsearch 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- 工具类依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.32</version>
</dependency>3.3 配置文件
yaml
spring:
elasticsearch:
rest:
uris: http://localhost:9200 # Elasticsearch 服务地址
username: elastic # 默认用户名(若开启安全认证)
password: 123456 # 默认密码(若开启安全认证)
data:
elasticsearch:
repositories:
enabled: true # 启用 Elasticsearch 仓库3.4 代码实现
3.4.1 实体类(映射配置)
java
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "product_index") // 对应 ES 中的索引名
public class Product {
@Id // 文档 ID
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word") // 文本类型,使用 IK 分词器(需提前安装 IK 插件)
private String name; // 商品名称
@Field(type = FieldType.Double)
private Double price; // 商品价格
@Field(type = FieldType.Keyword) // 关键字类型,不分词
private String category; // 商品分类
@Field(type = FieldType.Date, format = DateFormat.basic_date_time)
private LocalDateTime createTime; // 创建时间
// getter、setter 方法省略
}3.4.2 Repository 接口
java
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
// 继承 ElasticsearchRepository,泛型为实体类和 ID 类型
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
// 自定义查询方法(Spring Data 自动生成 SQL)
List<Product> findByNameContaining(String keyword); // 模糊查询商品名称
List<Product> findByCategoryAndPriceLessThanEqual(String category, Double price); // 按分类和价格筛选
}3.4.3 服务层与测试
java
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.List;
@Service
public class ProductService {
@Resource
private ProductRepository productRepository;
// 新增商品
public void addProduct(Product product) {
product.setCreateTime(LocalDateTime.now());
productRepository.save(product);
}
// 模糊查询商品
public List<Product> searchProductByName(String keyword) {
return productRepository.findByNameContaining(keyword);
}
// 按分类和价格筛选
public List<Product> filterProduct(String category, Double price) {
return productRepository.findByCategoryAndPriceLessThanEqual(category, price);
}
}
// 测试类
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.List;
@SpringBootTest
public class ElasticsearchTest {
@Resource
private ProductService productService;
@Test
public void testAddProduct() {
Product product = new Product();
product.setId(1L);
product.setName("Apple iPhone 15 Pro");
product.setPrice(9999.0);
product.setCategory("手机");
productService.addProduct(product);
}
@Test
public void testSearchProduct() {
List<Product> products = productService.searchProductByName("iPhone");
System.out.println(products);
}
}3.5 测试结果
- 执行新增操作后,可通过 Kibana 或 curl 命令查询索引
product_index,确认文档已写入。 - 执行查询操作时,Spring Data Elasticsearch 会自动转换为 ES 查询语句,返回符合条件的结果。
四、高级特性深度解析
4.1 聚合分析(Aggregation)
聚合分析用于对数据进行统计汇总,支持多种聚合类型:
4.1.1 桶聚合(Bucket Aggregation)
按条件分组,如按商品分类统计数量:
java
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import javax.annotation.Resource;
public void categoryAggregation() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withIndices("product_index")
.addAggregation(AggregationBuilders.terms("category_count").field("category"))
.build();
SearchHits<Product> searchHits = elasticsearchRestTemplate.search(query, Product.class);
Terms terms = searchHits.getAggregations().get("category_count");
terms.getBuckets().forEach(bucket ->
System.out.println("分类:" + bucket.getKey() + ",数量:" + bucket.getDocCount())
);
}4.1.2 指标聚合(Metric Aggregation)
计算统计指标,如商品平均价格:
java
public void priceAvgAggregation() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withIndices("product_index")
.addAggregation(AggregationBuilders.avg("price_avg").field("price"))
.build();
SearchHits<Product> searchHits = elasticsearchRestTemplate.search(query, Product.class);
double avgPrice = searchHits.getAggregations().get("price_avg").getValue();
System.out.println("商品平均价格:" + avgPrice);
}4.2 分词器定制
默认分词器对中文支持较差,推荐使用 IK 分词器(需提前安装插件):
4.2.1 安装 IK 分词器
bash
# 进入 ES 安装目录的 plugins 文件夹
cd elasticsearch-7.17.0/plugins
# 下载并解压 IK 分词器(版本需与 ES 一致)
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.0/elasticsearch-analysis-ik-7.17.0.zip
unzip elasticsearch-analysis-ik-7.17.0.zip -d ik-analyzer
# 重启 ES 服务4.2.2 自定义分词词典
修改 IK 分词器配置文件 ik-analyzer/config/IKAnalyzer.cfg.xml,添加自定义词典:
xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<entry key="ext_dict">custom.dic</entry> <!-- 自定义词典路径 -->
</properties>在 custom.dic 中添加自定义词汇(如"华为Mate60""酱香拿铁")。
4.3 高亮查询
在搜索结果中高亮显示匹配的关键词:
java
public List<Map<String, Object>> highlightSearch(String keyword) {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withIndices("product_index")
.withQuery(QueryBuilders.matchQuery("name", keyword))
.withHighlightFields(
new HighlightBuilder.Field("name")
.preTags("<em>") // 高亮前缀
.postTags("</em>") // 高亮后缀
)
.build();
SearchHits<Product> searchHits = elasticsearchRestTemplate.search(query, Product.class);
return searchHits.stream().map(hit -> {
Map<String, Object> result = new HashMap<>();
result.put("product", hit.getContent());
result.put("highlight", hit.getHighlightFields());
return result;
}).collect(Collectors.toList());
}4.4 索引生命周期管理(ILM)
针对日志等时序数据,自动管理索引的创建、滚动、删除,避免存储溢出:
- 创建生命周期策略(通过 Kibana Dev Tools):
json
PUT _ilm/policy/log_policy
{
"policy": {
"phases": {
"hot": { // 热阶段:数据写入和高频查询
"actions": {
"rollover": { // 滚动条件:索引大小超过 50GB 或创建时间超过 7 天
"max_size": "50gb",
"max_age": "7d"
}
}
},
"warm": { // 温阶段:低频查询,可优化存储
"min_age": "30d",
"actions": {
"forcemerge": { "max_num_segments": 1 }, // 段合并
"shrink": { "number_of_shards": 1 } // 缩减分片数
}
},
"delete": { // 删阶段:数据过期删除
"min_age": "90d",
"actions": { "delete": {} }
}
}
}
}- 为索引设置生命周期策略:
json
PUT log_index/_settings
{
"index.lifecycle.name": "log_policy"
}五、实践优化建议
5.1 索引设计优化
- 合理设置分片数量 :
- 主分片数量需根据集群节点数和数据量规划(建议每个分片大小 20-50GB)。
- 避免过度分片(如单节点设置 100 个主分片),导致集群元数据管理开销增大。
- 优化字段类型 :
- 对不分词的字段(如分类、ID)使用
keyword类型,避免text类型浪费资源。 - 时间字段使用
date类型,而非string类型,便于时间范围查询和排序。
- 对不分词的字段(如分类、ID)使用
- 关闭不必要的功能 :
- 无需评分的查询场景,设置
index.query.bool.max_clause_count降低内存消耗。 - 非实时更新的索引,关闭自动刷新(
index.refresh_interval: -1),手动控制刷盘时机。
- 无需评分的查询场景,设置
5.2 查询性能优化
- 避免全表扫描 :
- 对查询频繁的字段建立索引(如商品名称、分类)。
- 使用
filter上下文替代query上下文(过滤不计算评分,可缓存结果)。
- 优化聚合查询 :
- 对聚合字段使用
keyword类型,避免对text类型聚合。 - 大规模聚合场景,使用
approx_count_distinct替代精确计数,提升性能。
- 对聚合字段使用
- 分页查询优化 :
- 深度分页场景(如
from: 10000, size: 10),使用search_after替代from/size,避免内存溢出。
- 深度分页场景(如
5.3 集群运维优化
- 节点角色分离 :
- 生产环境中,单独设置主节点(禁用数据存储)和数据节点,避免主节点负载过高。
- 高查询压力场景,新增协调节点,专门处理请求转发和结果合并。
- 监控与告警 :
- 集成 Kibana 监控集群状态、分片健康、查询延迟等指标。
- 设置告警规则(如分片未分配、磁盘使用率超过 85%),及时响应故障。
- 备份与恢复 :
- 定期执行快照备份(
PUT /_snapshot/my_backup/snapshot_1),存储到可靠存储介质。 - 测试恢复流程,确保故障时数据可快速恢复。
- 定期执行快照备份(
六、常见问题与解决方案
| 问题场景 | 解决方案 |
|---|---|
| 索引创建失败 | 检查索引名称是否包含特殊字符,或分片数量超过集群承载能力 |
| 查询结果不准确 | 确认分词器配置是否正确,字段类型是否匹配查询场景 |
| 集群黄色状态(副本未分配) | 检查节点数量是否足够(副本需分配到不同节点),或手动触发分片重分配 |
| 写入性能低下 | 增大批量写入大小,调整刷新间隔,优化分片路由策略 |
| 磁盘使用率过高 | 启用索引生命周期管理,删除过期数据,或扩容集群存储 |
七、总结与展望
Elasticsearch 凭借其强大的检索能力、灵活的扩展性和丰富的生态,已成为分布式搜索领域的标杆产品。从基础的文档读写到复杂的聚合分析,从日志处理到实时推荐,Elasticsearch 都能提供高效的解决方案。
未来,随着 AI 技术与搜索领域的融合,Elasticsearch 可能会进一步增强语义检索、智能推荐等能力;同时,在云原生方向,将更好地适配容器化、Serverless 架构,降低运维成本。对于开发者而言,深入掌握 Elasticsearch 不仅能应对复杂业务场景的检索需求,也能为技术栈升级和职业发展增添核心竞争力。