
随着上周,GPT-4o原生多模态图像生成功能的推出,更多玩法也被开发出来。一夜之间,GPT-4o原生多模态能力的释放,让图像生成、语义分割、深度图构建这些曾需要专业工具链支持的复杂任务,变成了普通人输入一句话就能实现的"视觉魔术"。
目录
[Coovally AI模型训练与应用平台](#Coovally AI模型训练与应用平台)
表象与真相
用户仅需上传一张图片,输入"生成该图像的深度图与语义分割结果",系统便自动输出带有三维空间信息的深度热力图和精确物体边界标注。
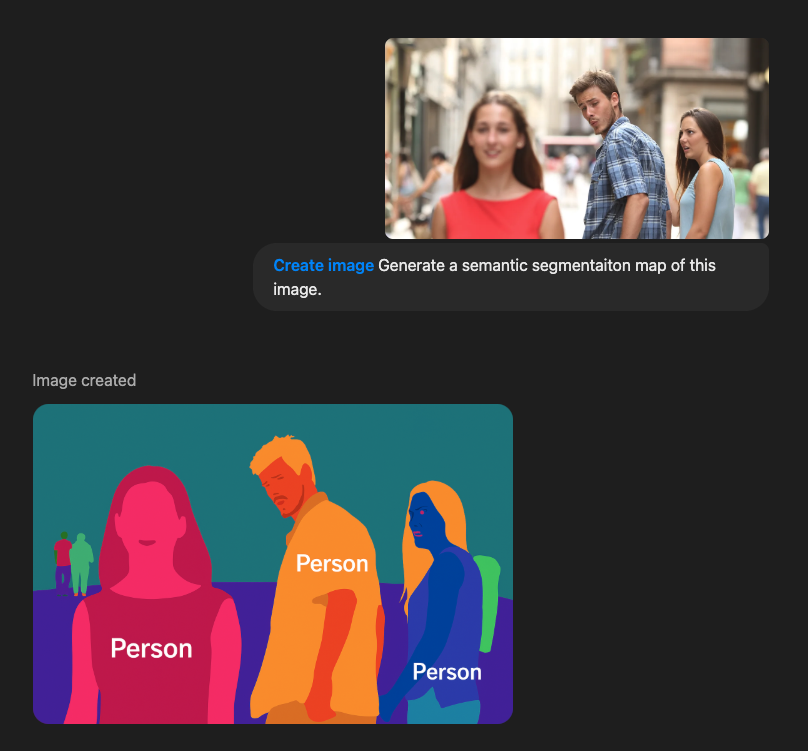

凭借着其快速反应和精准标注,与传统CV任务需经历数据清洗→模型训练→结果优化的漫长链路形成鲜明对比,一度让人直呼计算机视觉被GPT-4o终结了。
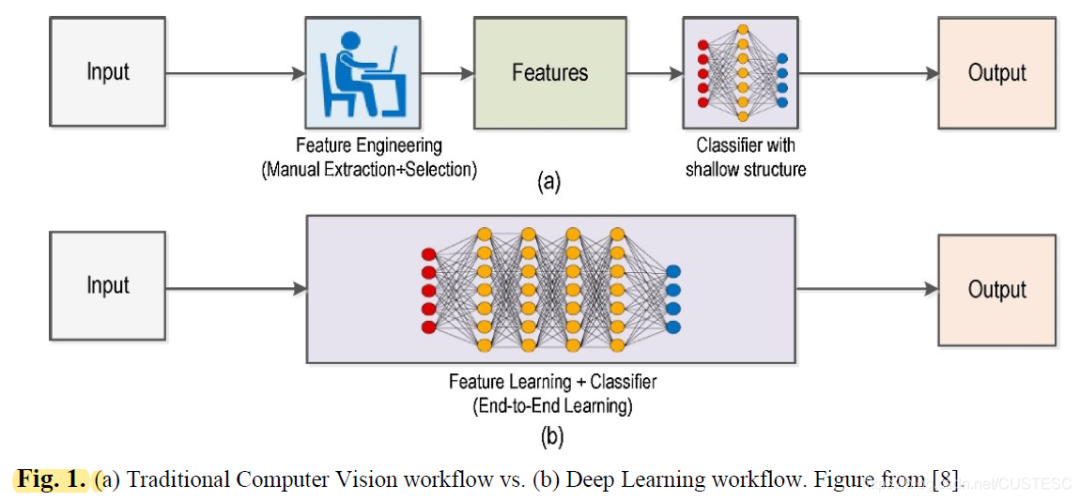
但事实真是如此吗?这场看似颠覆性的技术革命背后,计算机视觉的根基远未动摇。
数据与物理规律
CV大模型的泛化能力高度依赖传统CV积累的数据集。例如,GPT-4o的深度图生成能力源于对NYU Depth V2、KITTI等经典数据集数万小时训练的隐性继承。

虽然这波GPT-4o原生图像生成的技术细节,OpenAI是一点也没有公布,但还是有人从System Card中发现GPT-4o图像生成是原生嵌入在ChatGPT内的自回归模型。

硬件资源适配
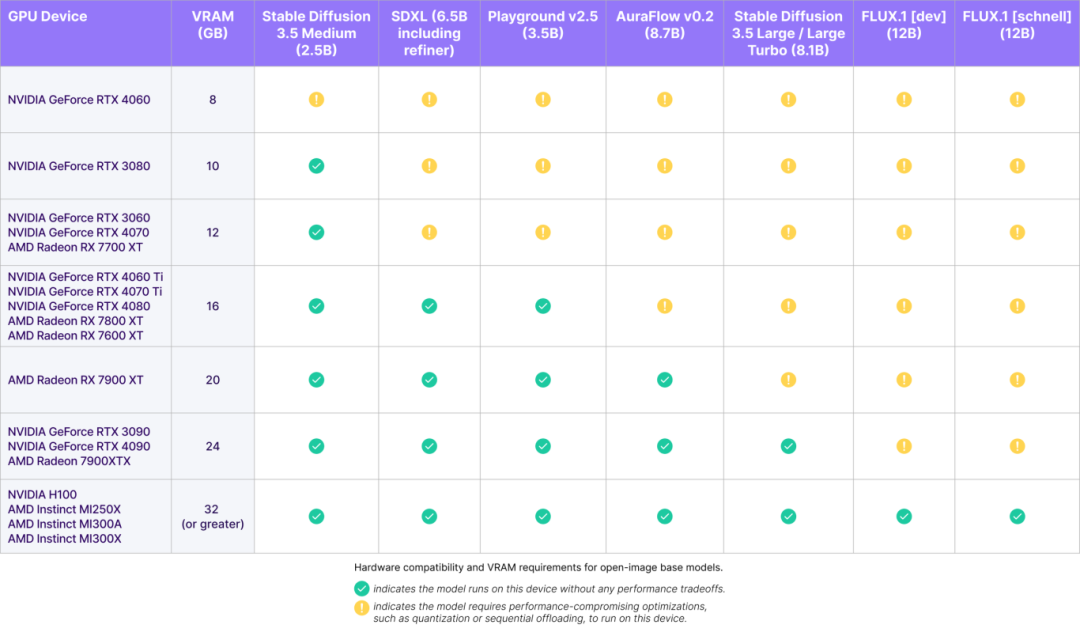
在手机端运行Stable Diffusion需6GB内存,在电脑端至少需要9.9GB内存,而传统MobileNet语义分割模型仅需200MB。训练时间与任务量也相差较大。
不可替代性
工业级精度与可靠性
- **医疗影像:**肺结节检测要求<0.3mm误差,当前大模型在MIT发布的LIDC数据集测试中,假阳性率比传统UNet++模型高47%;
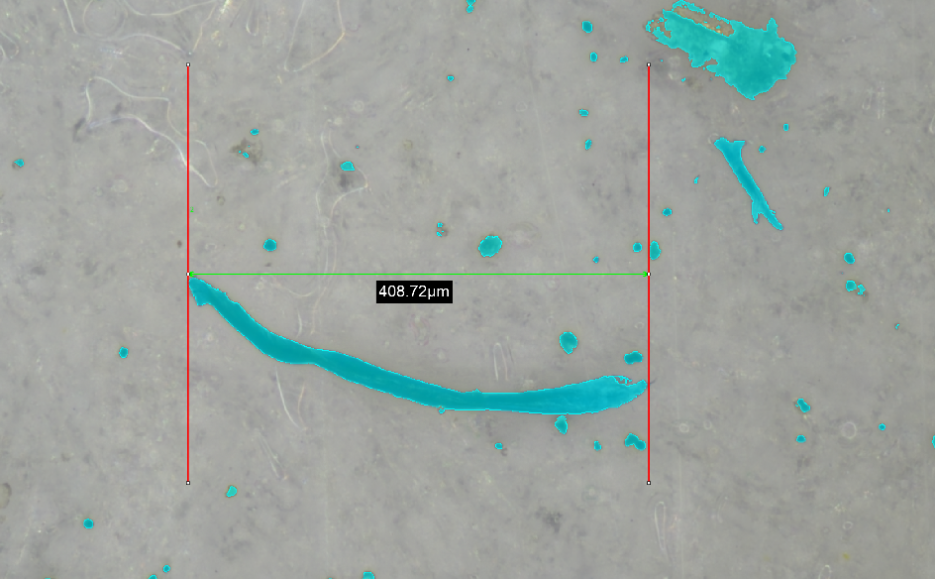
- **精密检测:**半导体晶圆缺陷检测需0.01μm级识别,基于OpenCV的形态学处理+小样本学习的混合架构仍是主流;
- **法律效力:**自动驾驶事故责任判定时,黑箱模型输出结果难以作为证据,而ISO 26262认证要求算法具备完整可追溯性;

资源约束
-
**能耗对比:**处理1080p图像,传统YOLOv5功耗2.1W,而DALL·E 3同等任务功耗达18.7W(数据来源:MLPerf 2023);
-
**时延红线:**无人机避障系统要求<10ms响应,大模型端到端推理时延普遍超过50ms;
-
**冷启动困境:**小众场景(如海底管道腐蚀检测)缺乏训练数据时,基于GrabCut交互式分割的传统方案成本更低;

认知逻辑
- **物理规则编码:**NeRF生成的新视角会出现违反透视原理的扭曲,而传统SfM(运动恢复结构)算法严格遵循多视几何约束;
- **因果推理短板:**大模型能标注"拿着水杯的手",但无法像传统视觉推理框架那样构建"手→施加力→水杯倾斜→液体流动"的因果链;
- **可解释性鸿沟:**FDA要求医疗AI提供特征激活图谱,而ViT注意力机制至今无法达到Grad-CAM的可信级别;
未来趋势
但随着GPT-4o原生图像生成的发布,以及CV领域功能的开发,让大家意识到技术融合或将成为主流趋势:
技术架构融合
多模态大模型与计算机视觉(CV)的融合已突破简单的模块化拼接,转向底层架构的深度重构。传统CV模型需为不同任务设计独立模块(如目标检测、语义分割),而大模型通过共享参数实现多任务联合优化,训练效率提升40%以上;
数据生态融合
技术融合的核心驱动力在于数据资源的深度整合与价值释放,特斯拉将激光雷达点云数据与大模型生成的伪深度图进行对抗训练,解决纯视觉方案在雨雾天气的感知缺陷,Stable Video Diffusion等工具可批量生成带标注的工业缺陷图像,弥补传统CV在小样本场景下的数据短板;
行业应用融合
-
**影像分析:**LLaVA模型提取CT图像全局特征,UNet++聚焦病灶区域,在肺结节检测任务中实现敏感性与特异性双指标突破;
-
**缺陷检测:**GPT-4V初步筛选可疑区域后,Halcon算法执行亚像素级测量,误检率降低至0.01%以下;
-
**长尾场景处理:**Waymo利用大模型生成极端天气虚拟场景,训练传统YOLOv7模型提升泛化能力;
Coovally AI模型训练与应用平台
Coovally平台整合了国内外开源社区1000+模型算法 和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!

具体操作步骤可参考:YOLO11全解析:从原理到实战,全流程体验下一代目标检测
如果你想要另外的模型算法 和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
未来挑战
可解释性困境
医疗领域要求模型输出符合DICOM标准的可追溯结果,而ViT注意力机制难以像传统Grad-CAM方法提供直观解释。
算力成本与能效瓶颈
大模型端到端推理功耗达传统CV模型的9倍,制约其在无人机等移动设备部署
结语
大模型并非计算机视觉的"终结者",而是技术生态的革新者。在可预见的未来,传统CV将坚守高精度、低能耗、强解释性的阵地,而大模型则负责拓宽泛化与创意边界。两者的共生,正推动人类从"看见"迈向"理解"世界的更高维度。在这场融合革命中,CV工程师的角色正从"特征工程师"进化为"认知协议设计师",他们不仅要理解卷积核的数学之美,更要掌握为机器定义"视觉世界观"的哲学。
