剑指Offer(数据结构与算法面试题精讲)C++版------day6
题目一:不含重复字符的最长子字符串

这里还是可以使用前面,提到的双指针方法,使用左右两个指针定界(不妨记为front和end指针),一开始front指针和end指针都指向第一个字符,显然没有出现重复字符,然后end指针后移,计算这里front指针和end指针之间的子串是否存在重复字符,如果存在重复字符,那么将front前移,重新计算统计是否重复。比如这里的示例,等到front和end指针之间为"bab"时发现重复,于是front前移,front和end之间的子串调整为"ab",再次检测是否具备重复的字符。由于这里没有强调使用的字符集范围,这里取常用ASCII码作为字符集,这样就能够使用hash表来存储每个字符出现的次数,实现快速存取,于是得到如下代码:
cpp
# include <iostream>
# include <algorithm>
using namespace std;
bool isAllOnce(int count[]) {
for(int i=0; i<256; ++i) {
if(count[i]==2)return false;
}
return true;
}
int maxSubStrLength(string str) {
int i=0,j=0,maxLength=1,len=str.length();
int count[256]= {0};
for(j=0; j<len; ++j) {
count[str[j]]++;
if(!isAllOnce(count)) {
count[str[i]]--;
i++;
} else {
if(j-i+1>maxLength) {
maxLength=j-i+1;
}
}
}
return maxLength;
}
int main() {
string s1="babcca";
cout<<"输出最大不重复子串的长度:"<<maxSubStrLength(s1)<<endl;
return 0;
}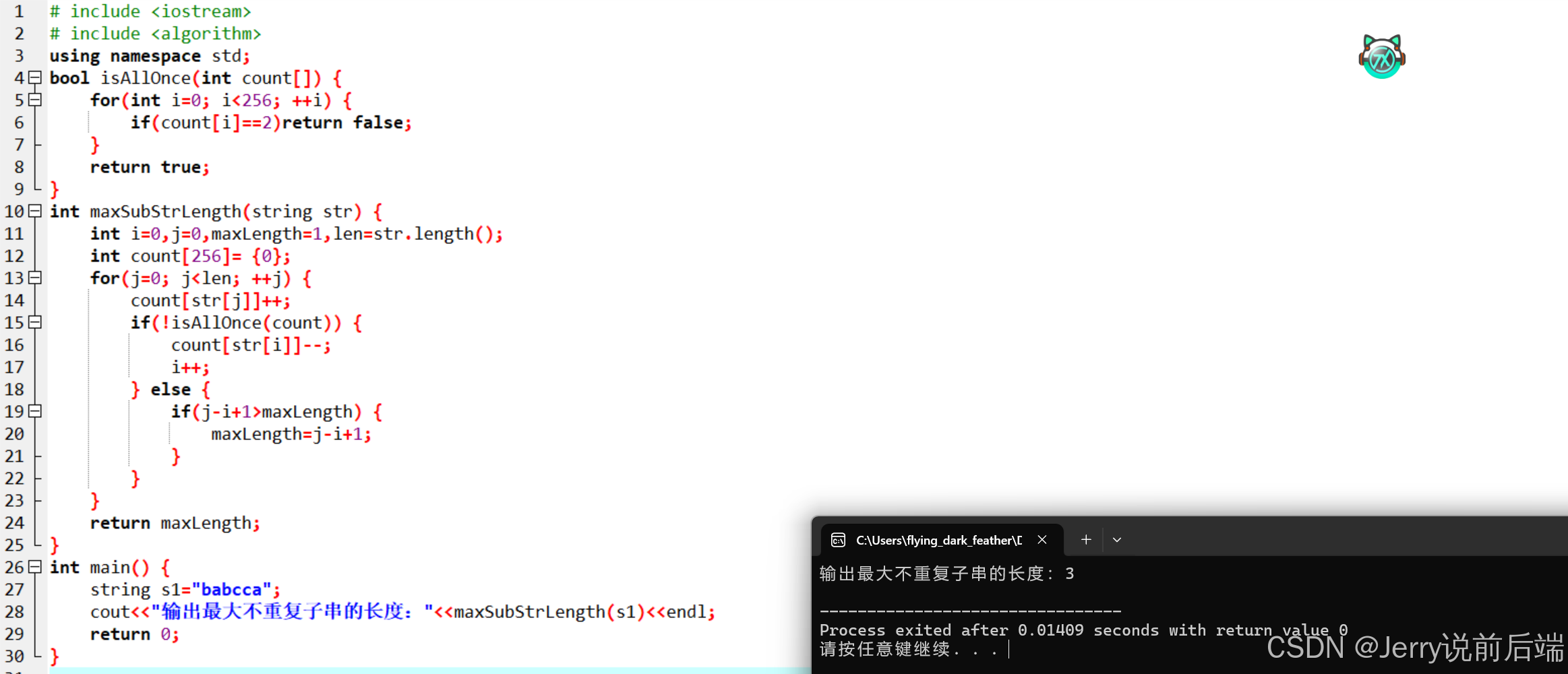
接下来对上述代码的时间复杂度进行深入分析。在该算法的实现过程中,其中使用的 hash 表被设定大小为 256 。之所以这样设置,是因为它能够较为全面地涵盖可能出现的字符情况。当对这个 hash 表进行扫描操作时,由于其固定大小为 256 ,所以需要进行 256 次判断操作。从算法时间复杂度的概念来讲,尽管存在这 256 次的判断,但由于这个操作次数是一个固定的常量,与输入数据的规模大小并无关联,所以这部分操作的时间复杂度依然属于 O(1) 级别。在此基础上,我们转换视角,站在变量 i ,也就是可以理解为 front 指针的角度来进一步考量。因为在整个算法流程中, front 指针最多只需要从数组的起始位置一直扫描到数组的末尾位置,即最多需要完整地扫描整个数组一次。而数组的长度是由输入数据的规模 n 所决定的,随着 n 的变化, front 指针扫描数组的操作次数也会相应变化,且呈线性关系。综合以上两部分的分析,整体算法最终的时间复杂度也就确定为 O(n) 。
题目二:包含所有字符的最短字符串

这里依旧可以考虑使用hash表和双指针的方式来统计是否存在这样的数组。思路大致为,首先扫描一次字符串t,然后标记其中每个字符出现的次数,然后使用双指针遍历s字符串,如果出现了一个子串,使得包含了t中的所有字符,那么统计这个子串和子串的长度,这样便能够遍历完所有子串,每次找到子串之后都更新成最短的那个子串,最终得到如下代码:
cpp
# include <iostream>
# include <algorithm>
using namespace std;
void initCountNum(string t,int count[]) {
for(int i=0; i<256; ++i) {
count[i]=0;
}
for(int i=0,len=t.length(); i<len; ++i) {
count[t[i]]++;
}
}
bool isEmpty(int count[]) {
for(int i=0; i<256; ++i) {
if(count[i]>0)return false;
}
return true;
}
string getMinLenStr(string s,string t) {
int count[256]= {0},len1=s.length(),len2=t.length();
int i=0,j=len2-1,strLen=-1;
string result="";
while(j<len1&&i<len1-len2) {
initCountNum(t,count);
for(int k=i; k<=j; ++k) {
count[s[k]]--;
}
if(isEmpty(count)) {
if(j-i+1<strLen||strLen==-1) {
strLen=j-i+1;
result=s.substr(i,strLen);
}
i++;
} else {
j++;
}
}
return result;
}
int main() {
string s="ADDBANCAD";
string t="ABC";
cout<<"输出s中包含t字符的最短子串:"<<getMinLenStr(s,t)<<endl;
return 0;
}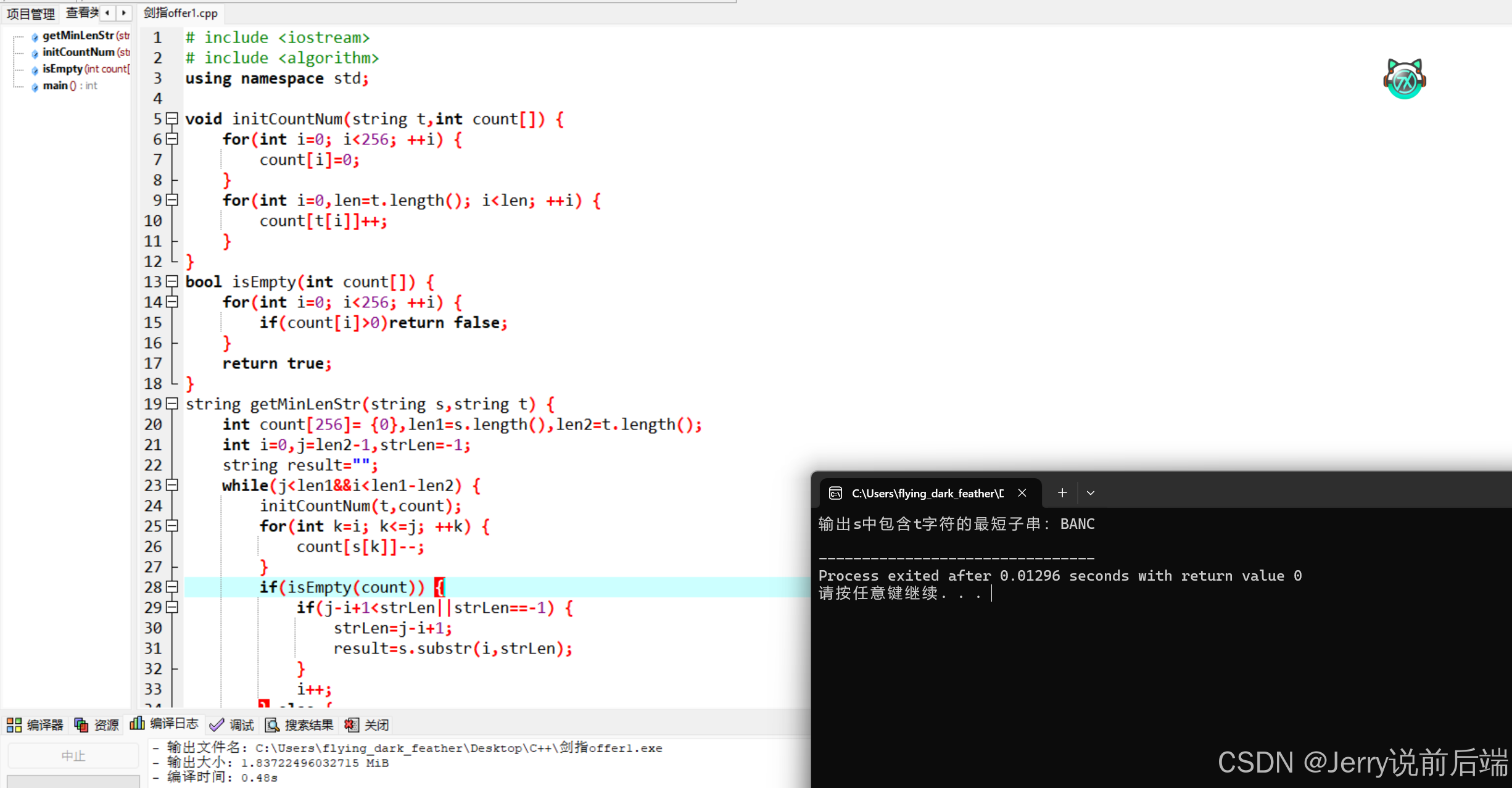
这里的时间复杂度应该怎么分析呢?对于这里函数涉及比较多的算法,分析时间复杂度可以按照函数进行拆解,这里不妨假设字符串s和字符串t的长度分别为m和n,同上面的分析,对于算法isEmpty都是循环并判断256次,这里的时间复杂度为O(1),对于算法initCountNum时间复杂度为O(m)。接下来,算法的时间复杂度应该着重分析getMinLenStr函数,在双指针遍历时,最坏的情况下,第一次遍历到了最后一个字符才拿到了满足要求的子串,需要遍历n-m次,接下来为了尽可能缩短子串长度,因此左指针右移,这部分还需要的比较次数为n-m次,但由于每次需要初始化计数数组count并且需要扣减计数,因此总时间复杂度为O((m+n)*n)。
题目三:有效的回文

回文字符串相关的问题是十分经典且常见的类型,不仅在日常的算法学习和练习中频繁出现,在 LeetCode 上也经常出现。本题的特殊之处在于,题目明确限定了只需要考虑字符串中的字母和数字字符,这一条件为我们的解题思路奠定了基础。基于此,我们的第一步操作便是对原始字符串进行全面且细致的清洗工作。在清洗过程中,需要逐个字符地进行排查,精准地筛选出其中所有的字母和数字字符。同时,对于字母字符里的大写字母,为了保证后续处理的一致性和便捷性,要将其一一转换成对应的小写字母。当完成了字符串的清洗步骤后,就该运用到双指针这一巧妙的算法技巧了。我们设定两个指针,一个处于字符串的最左端,另一个位于字符串的最右端,随后让这两个指针同时朝着字符串的中间方向移动遍历。在遍历的每一个过程中,都要对两个指针所指向的字符内容进行严格比较。一旦发现两个指针指向的内容存在不一致的情况,那么就可以迅速判定这个字符串并非回文串。通过这样严谨且有序的操作流程,我们最终能够实现对回文字符串的准确判断,于是也就得到了如下的代码:
cpp
# include <iostream>
# include <algorithm>
using namespace std;
bool isPalindrome(string s) {
int len=s.length();
for(int i=0,j=len-1; i<len/2; ++i,--j) {
if(s[i]!=s[j])return false;
}
return true;
}
string filterStr(string s) {
string result="";
for(int i=0,len=s.length(); i<len; ++i) {
if((s[i]>='a'&&s[i]<='z')||(s[i]>='0'&&s[i]<='9')) {
result+=s[i];
} else if(s[i]>='A'&&s[i]<='Z') {
result+=tolower(static_cast<unsigned char>(s[i]));
}
}
return result;
}
int main() {
string s="Was it a cat I saw";
cout<<"判断是否是回文字符串:"<<isPalindrome(filterStr(s))<<endl;
return 0;
}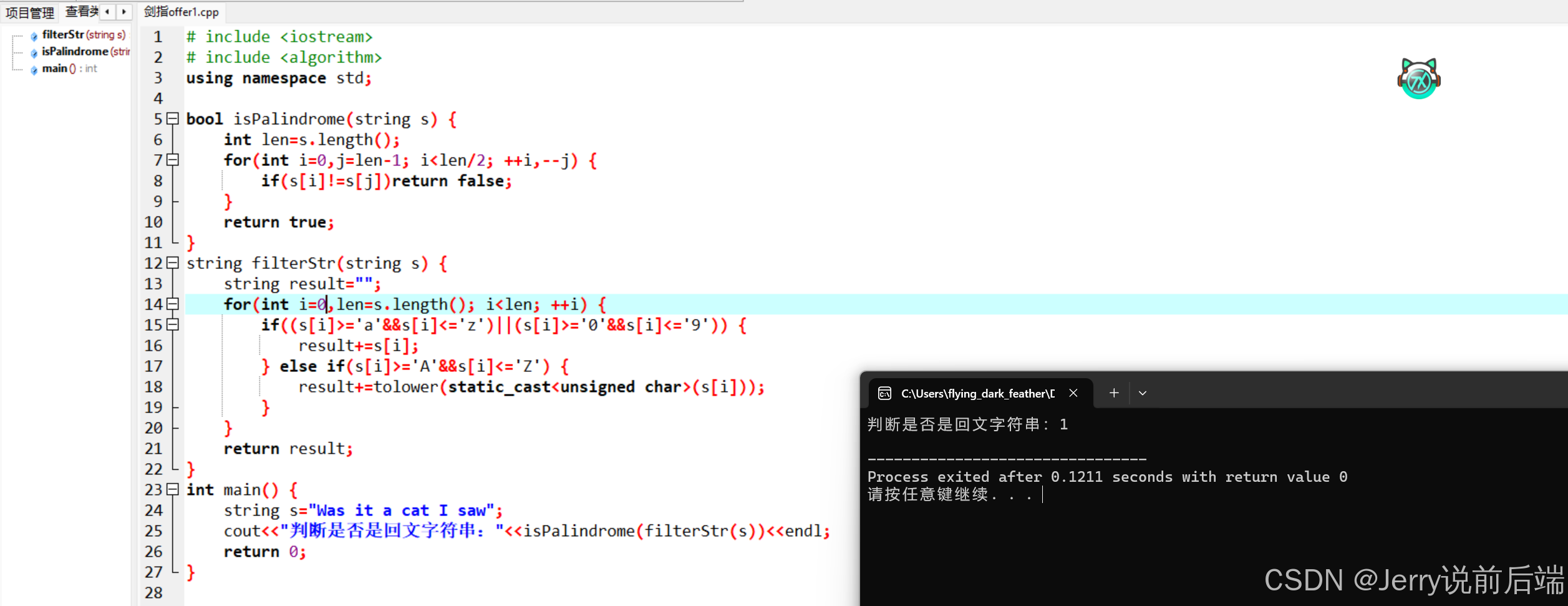
这里我们需要积累一下,C++下大小写的转换方法,之后字符串系列算法估计还会用到。
我是【Jerry说前后端】,本系列精心挑选的算法题目全部基于经典的《剑指 Offer(数据结构与算法面试题精讲)》。在如今竞争激烈的技术求职环境下,算法能力已成为前端开发岗位笔试考核的关键要点。通过深入钻研这一系列算法题,大家能够系统地积累算法知识和解题经验。每一道题目的分析与解答过程,都像是一把钥匙,为大家打开一扇通往高效编程思维的大门,帮助大家逐步提升自己在数据结构运用、算法设计与优化等方面的能力。
无论是即将踏入职场的应届毕业生,还是想要进一步提升自己技术水平的在职开发者,掌握扎实的算法知识都是提升竞争力的有力武器。希望大家能跟随我的步伐,在这个系列中不断学习、不断进步,为即将到来的前端笔试做好充分准备,顺利拿下心仪的工作机会!快来订阅吧,让我们一起开启这段算法学习之旅!