3.0 引言
📌 上章回顾
上一章我们学习了感知机。关于感知机,有好消息,也有坏消息。
✅ 好消息:
即便是复杂的计算任务,感知机理论上也可以表示出来。
只要结构足够深、组合足够巧,它甚至能模拟出一个完整的计算机。
我们看到它能构造:
- 逻辑门(AND、OR、NAND)
- 加法器
- 非线性函数(比如 XOR)
这说明感知机拥有极强的表示能力。
❌ 坏消息:
虽然感知机"能表示",但目前是靠人工设定权重来实现的。
上一章中我们是参考真值表,"拍脑袋"选出了合适的参数:
w = 0.5, 0.5
b = -0.7
这种方式在实际问题中是不可行的,尤其是面对图像、语音这种高维复杂输入时,参数数以千计,我们没法一一设置。
🤖 神经网络的意义:
神经网络的关键优势是:可以从数据中自动学习出合适的权重参数。
这解决了感知机的最大痛点。
📌 本章我们将关注神经网络在"推理阶段"的工作流程,即:
输入层 → 隐藏层 → 输出层 的信号传递
使用激活函数进行非线性变换
📌 而在下一章,我们将开始学习神经网络的训练过程:
如何从数据中学习
误差反向传播算法(backpropagation)。
3.1 从感知机到神经网络
神经网络和上一章介绍的感知机有很多共同点。这里,我们主要以两者的差异为中心,来介绍神经网络的结构。
3.1.1 神经网络的例子
用图来表示神经网络的话,如图3-1所示。
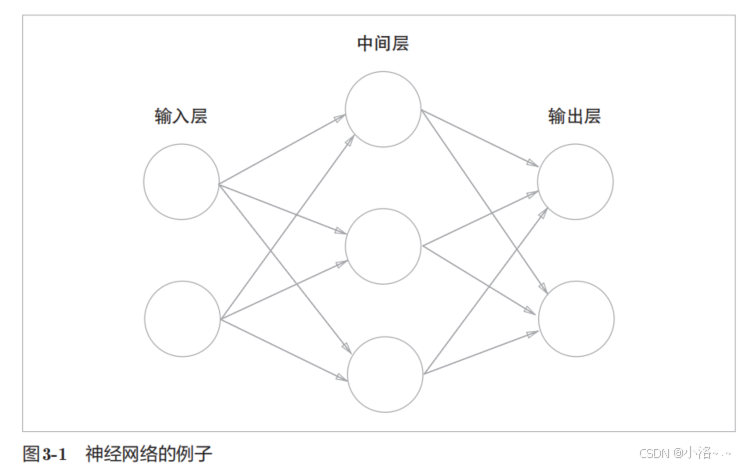
我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。中间层有时也称隐藏层 。"隐藏"一词的意思是,隐藏层的神经元(和输入层、输出层不同)肉眼看不见。另外,本书中把输入层到输出层依次称为第0层、第1层、第2层(层号之所以从0开始,是为了方便后面基于Python进行实现)。
图3-1中,第0层对应输入层,第1层对应中间层,第2层对应输出层。
只看图3-1的话,神经网络的形状类似上一章的感知机。实际上,就神经元的连接方式而言,与上一章的感知机并没有任何差异。那么,神经网络中信号是如何传递的呢?
3.1.2 复习感知机
在了解神经网络中的信号传递方式之前,我们先来复习一下感知机的工作原理。
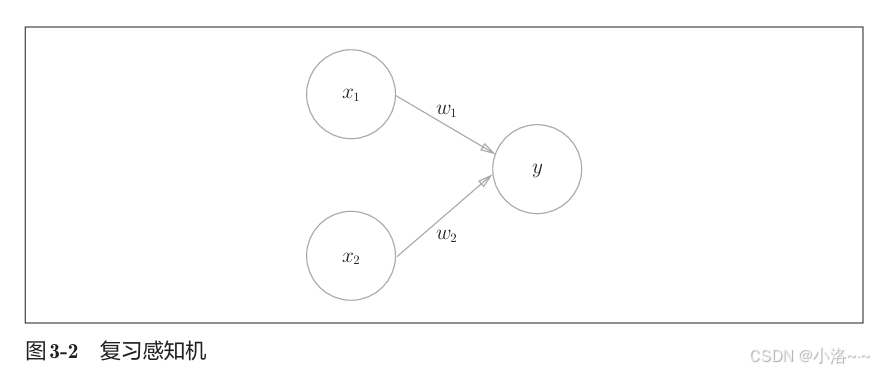
它接收两个输入信号 x 1 x_1 x1 和 x 2 x_2 x2,通过对应的权重 w 1 w_1 w1 和 w 2 w_2 w2 进行加权,然后输出一个值 y y y。
🧮 数学表示(公式 3.1)
y = { 1 ( w 1 x 1 + w 2 x 2 + b > 0 ) 0 otherwise y = \begin{cases} 1 & (w_1 x_1 + w_2 x_2 + b > 0) \\\\ 0 & \text{otherwise} \end{cases} y=⎩ ⎨ ⎧10(w1x1+w2x2+b>0)otherwise
这里的:
- w 1 , w 2 w_1, w_2 w1,w2 是权重,控制每个输入的重要性;
- b b b 是偏置项(bias),控制"激活的容易程度"。
❓偏置是怎么处理的?
在上图中偏置 b b b 没有显式画出,但其实它就像一个特殊输入,值始终为 1。
我们可以把偏置理解为一个"阈值调节器":
- 它始终参与计算;
- 但不会随输入数据变化。
🎨 如果画出完整的结构图(图3-3),就是这样:
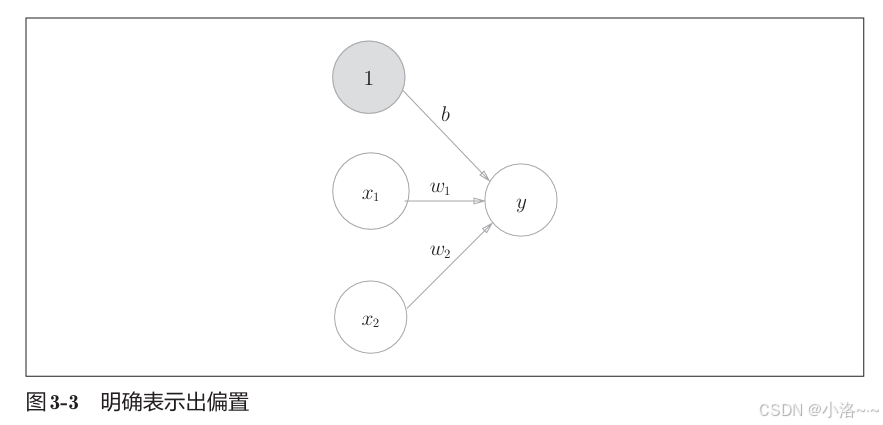
图中将偏置的输入神经元涂成灰色,以示区别。
✅ 更加简洁的数学形式(公式 3.2)
为了简洁,我们引入一个函数 h ( x ) h(x) h(x):
y = h ( w 1 x 1 + w 2 x 2 + b ) y = h(w_1 x_1 + w_2 x_2 + b) y=h(w1x1+w2x2+b)
这个函数 h ( x ) h(x) h(x) 被称为激活函数(activation function)。
🚀 定义激活函数 h(x)(公式 3.3)
最常见的激活函数是阶跃函数:
h ( x ) = { 1 ( x > 0 ) 0 otherwise h(x) = \begin{cases} 1 & (x > 0) \\\\ 0 & \text{otherwise} \end{cases} h(x)=⎩ ⎨ ⎧10(x>0)otherwise
也就是说,如果加权求和的结果大于 0,就输出 1;否则输出 0。
📌 小结
| 项目 | 说明 |
|---|---|
| 输入 x i x_i xi | 外部信号,比如像素值或传感器数据 |
| 权重 w i w_i wi | 表示输入信号的重要性 |
| 偏置 b b b | 控制"激活的门槛",始终与输入1相乘加入 |
| h ( x ) h(x) h(x) | 激活函数,决定输出是否"点亮" |
| 输出 y y y | 感知机的判断结果,0或1 |
通过这种结构,感知机就能模拟出逻辑门、进行分类决策,是神经网络的原始雏形。
3.1.3 激活函数登场
刚才登场的 h ( x ) h(x) h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数(activation function)。如"激活"一词所示,激活函数的作用在于决定如何来激活输入信号的总和。
💡 激活函数的作用
就像"激活"这个词本身所表达的意思,激活函数的目的是:
决定神经元是否被"激活",即是否向下传递信号。
它是整个神经网络中非线性处理的核心。
🧮 更详细的公式分解
之前我们写过感知机的简洁形式:
y = h ( w 1 x 1 + w 2 x 2 + b ) (公式 3.2) y = h(w_1 x_1 + w_2 x_2 + b) \quad \text{(公式 3.2)} y=h(w1x1+w2x2+b)(公式 3.2)
其实它可以拆分成两个步骤:
-
第一步 :求加权和
a = w 1 x 1 + w 2 x 2 + b (公式 3.4) a = w_1 x_1 + w_2 x_2 + b \quad \text{(公式 3.4)} a=w1x1+w2x2+b(公式 3.4) -
第二步 :用激活函数处理 a a a
y = h ( a ) (公式 3.5) y = h(a) \quad \text{(公式 3.5)} y=h(a)(公式 3.5)
这就像把信号先"合成",再"判断是否激活"。
🧠 神经元内部结构图解(图 3-4)

通常我们会用一个圆圈 ○ 表示一个神经元。现在,我们在这个神经元内部加上细节,如下所示:
图示结构说明:
- x 1 , x 2 x_1, x_2 x1,x2:输入信号
- w 1 , w 2 w_1, w_2 w1,w2:权重
- b b b:偏置
- a a a:节点加权和
- h ( a ) h(a) h(a):激活函数处理后输出 y y y
在一些图中,a、h()、y 会在神经元内部显式表示,帮助我们更清晰理解运算流程。
🧠 "节点" vs "神经元"
- 本书中,"节点"和"神经元"是可以互换使用的。
- 节点表示神经网络图中的一个计算单元,和"神经元"含义相同。
📘 图示演变(图 3-5)
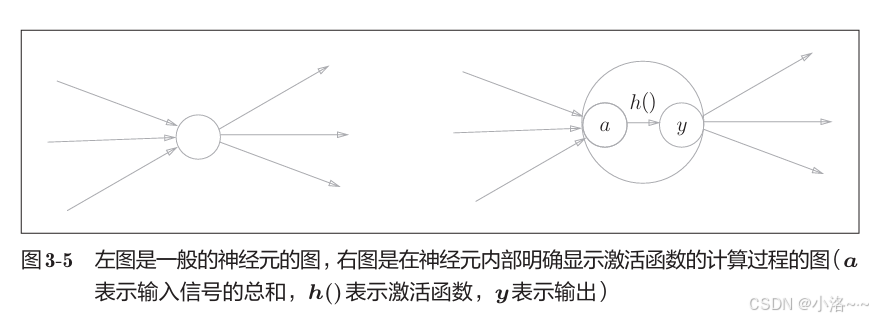
我们常用两种方式画神经元结构图:
| 普通画法(简洁) | 详细画法(显式显示计算过程) |
|---|---|
| 一个圆圈代表一个神经元 | 圆圈内写上 a → h(a) → y |
这种表示方式会在后续神经网络结构图中频繁使用,有助于理解前向传播(forward)和误差传播(backpropagation)。
📌 感知机 与 神经网络 的连接点:激活函数
激活函数是连接"感知机"和"神经网络"的桥梁。
| 模型类型 | 特点 |
|---|---|
| 朴素感知机 | 使用阶跃函数作为激活函数,结构较简单 |
| 多层感知机(MLP) | 使用sigmoid、ReLU等平滑函数,可构成深层网络 |
激活函数的不同,决定了模型能力的差异,也是感知机升级为神经网络的关键一步。
下一节,我们就将系统地介绍各种常见的激活函数,包括:
- sigmoid
- ReLU
- 阶跃函数
- softmax(输出层用)
让我们正式进入神经网络的非线性世界!🌐
3.2 激活函数
在上一节我们提到,感知机的激活函数是"阶跃函数" ------ 输入超过某个阈值时就输出 1,否则输出 0。
感知机使用的是这种非常简单的激活方式,但神经网络的强大之处,恰恰来自于"选择不同的激活函数"。
3.2.1 sigmoid函数
神经网络中最早被广泛使用的激活函数就是 sigmoid 函数,数学表达式如下:
σ ( x ) = 1 1 + e − x (公式 3.6) \sigma(x) = \frac{1}{1 + e^{-x}}\quad \text{(公式 3.6)} σ(x)=1+e−x1(公式 3.6)
sigmoid 函数可以把任意实数输入"压缩"到 0 到 1 的区间内。
实际上,上一章介绍的感知机和接下来要介绍的神经网络的主要区别就在于这个激活函数。
其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。下面,让我们通过和阶跃函数的比较来详细学习作为激活函数的sigmoid函数。
3.2.2 阶跃函数的实现
感知机使用的阶跃函数如下:
h ( x ) = { 1 if x > 0 0 otherwise h(x) = \begin{cases} 1 & \text{if } x > 0 \\ 0 & \text{otherwise} \end{cases} h(x)={10if x>0otherwise
🧪 Python 实现(支持 NumPy 数组)
python
def step_function(x):
return np.array(x > 0, dtype=int)3.2.3 阶跃函数的图形
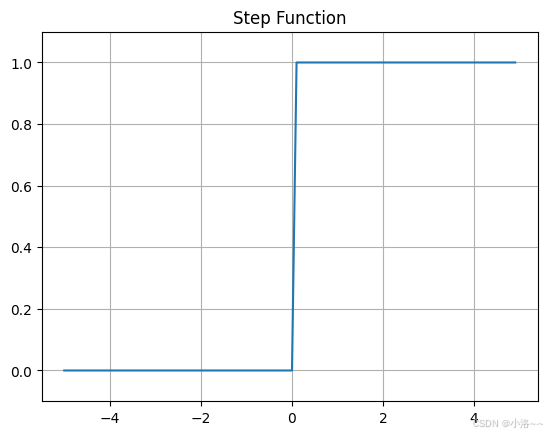
我们可以用 matplotlib 画出阶跃函数的图:
python
import numpy as np
import matplotlib.pyplot as plt
def step_function(x):
return np.array(x > 0, dtype=int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.title("Step Function")
plt.grid(True)
plt.show()这个函数在 x = 0 附近跳跃,呈"台阶状"。
3.2.4 sigmoid函数的实现
下面,我们来实现sigmoid函数。用Python可以像下面这样写出式(3.6)表示的sigmoid函数。
用 Python 可以像下面这样实现:
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))🧪 示例验证
python
x = np.array([-1.0, 1.0, 2.0])
print(sigmoid(x))
# 输出:# array([0.26894142, 0.73105858, 0.88079708])💡 为什么可以处理数组?------ NumPy 的广播功能
NumPy 中的"广播机制"允许标量和数组之间自动对齐维度,从而实现逐元素运算。
python
t = np.array([1.0, 2.0, 3.0])
print(1.0 + t) # array([2., 3., 4.])
print(1.0 / t) # array([1 , 0.5, 0.33333333])广播的本质是:将标量作用在数组的每一个元素上。
sigmoid 函数中的:
python
1 / (1 + np.exp(-x))本质上也就是对数组 x 中的每个元素进行上述运算。
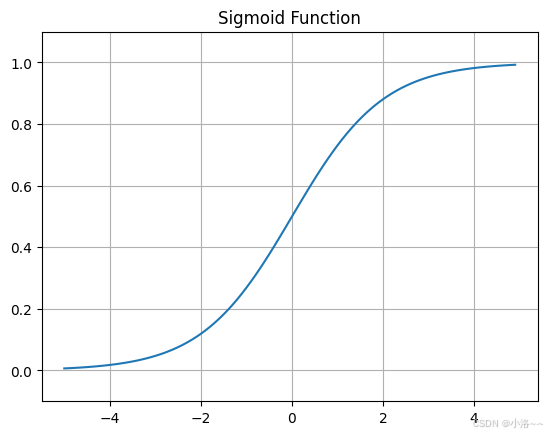
下面我们将 sigmoid 函数绘制成图。代码几乎与阶跃函数相同,唯一的变化是输出函数从 step_function 换成了 sigmoid:
python
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 设置 y 轴范围
plt.title("Sigmoid Function")
plt.grid(True)
plt.show()运行这段代码,可以绘制出 sigmoid 函数的图像,结果呈现一条平滑的 S型曲线(图 3-7)。
3.2.5 sigmoid函数和阶跃函数的比较
我们来看一下 sigmoid 函数 和 阶跃函数 的异同。通过观察它们的图像(如下图 3-8 所示),我们可以更直观地理解这两者的特点。
- 使用
step_function(x)绘制阶跃函数(用虚线) - 使用
sigmoid(x)绘制 sigmoid 函数(用实线)
python
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def step_function(x):
return np.array(x > 0, dtype=int)
x = np.arange(-6.0, 6.0, 0.1)
y_sigmoid = sigmoid(x)
y_step = step_function(x)
plt.plot(x, y_sigmoid, label="sigmoid", linewidth=2)
plt.plot(x, y_step, linestyle="dashed", label="step")
plt.ylim(-0.1, 1.1)
plt.title("Sigmoid vs Step Function")
plt.legend()
plt.grid(True)
plt.show()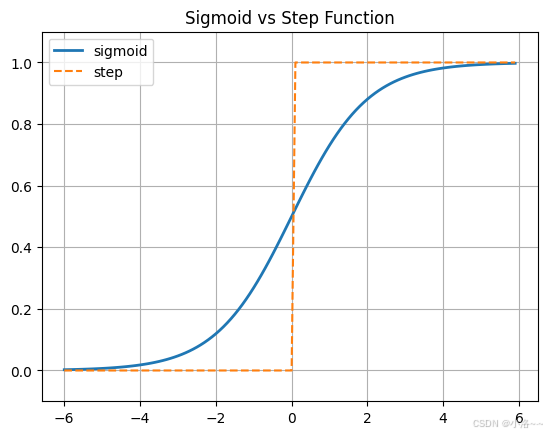
🔍 不同点一:平滑性
-
sigmoid 函数 是一条 平滑连续的 S 型曲线。
- 它的输出值会随着输入值"渐变"。
- 例如输入从 -2 到 2,输出会缓慢地从接近 0 变化到接近 1。
-
阶跃函数 则是一个"断崖式"的函数。
- 当输入大于 0 时,输出立即从 0 跳到 1;
- 小于等于 0 时输出就是 0。
- 中间没有过渡。
✅ 结论:sigmoid 更"柔和",而阶跃更"决绝"。
🔍 不同点二:输出形式
- 阶跃函数的输出值只有两个:0 或 1,是典型的"二元决策"。
- sigmoid 函数的输出值是 连续的小数 ,比如:
- 输入 1 时输出约为 0.73
- 输入 2 时输出约为 0.88
这意味着:
在感知机中流动的是 "0/1" 的开关信号,
而在神经网络中,流动的是 "0~1" 的连续信号。
💧 打个比方(形象理解)
- 阶跃函数就像"竹筒敲石" ------ 要么敲一下,要么不敲(0 或 1)。
- sigmoid 函数更像"水车" ------ 水多了就转得快,水少了就慢慢转,流动是连续的。
✅ 共同点
虽然表现不同,它们还是有很多相似之处:
- 都属于非线性函数
- 都能把输入限制在 0, 1 区间内
- 都可以将"重要信息"激活输出为接近 1,将"无用信息"抑制为接近 0
从图像上看,它们的整体趋势是相似的 ------
输入很小时输出接近 0,输入很大时输出接近 1。
结论:
虽然阶跃函数简单粗暴,适合用作逻辑判断;但 sigmoid 函数更柔和,更适合用于神经网络的训练和信号传递。
3.2.6 为什么激活函数必须是非线性函数?
我们刚刚介绍的 阶跃函数 和 sigmoid 函数 虽然形式不同,但它们有一个重要的共同点:
✅ 它们都是 非线性函数(Non-linear Functions)
🧠 什么是非线性函数?
-
线性函数的形式:
h ( x ) = c ⋅ x h(x) = c \cdot x h(x)=c⋅x其中 ( c ) 是一个常数,图像是一条笔直的直线,输入与输出成正比。
-
非线性函数则不满足上述条件,图像可能是曲线、折线或阶梯状。比如:
- sigmoid 是一条平滑曲线
- 阶跃函数是一条"跳跃"式的线
🤔 那为什么神经网络的激活函数不能用线性函数呢?
这个问题的核心在于:如果激活函数是线性的,那么神经网络的"多层结构"就毫无意义!
📉 举个简单的例子:
假设你使用一个线性函数作为激活函数,如:
h ( x ) = c ⋅ x h(x) = c \cdot x h(x)=c⋅x
现在你搭建了一个三层的神经网络,每一层都使用这个激活函数,最终你得到的输出是:
y ( x ) = h ( h ( h ( x ) ) ) = c ⋅ ( c ⋅ ( c ⋅ x ) ) = c 3 ⋅ x y(x) = h(h(h(x))) = c \cdot (c \cdot (c \cdot x)) = c^3 \cdot x y(x)=h(h(h(x)))=c⋅(c⋅(c⋅x))=c3⋅x
也就是说,整个三层网络的效果,相当于只进行了一次乘法:
y ( x ) = a ⋅ x 其中 a = c 3 y(x) = a \cdot x \quad \text{其中 } a = c^3 y(x)=a⋅x其中 a=c3
❌ 这完全等价于一个"没有隐藏层"的简单网络。
📌 结论
-
神经网络的魅力在于"叠加多层,逐步提取复杂特征";
-
如果使用线性函数,这种"层层叠加"的结构完全被浪费了;
-
所以:
🔥 必须使用非线性激活函数,才能让神经网络真正强大!
3.2.7 ReLU函数
到目前为止,我们介绍了两种激活函数:
- 阶跃函数:简单但不连续,无法用于梯度下降
- sigmoid 函数:平滑、连续、可导,适合训练
那么,现代深度学习中最常用的激活函数是什么呢?
答案就是 ------ ReLU 函数(Rectified Linear Unit)
📐 什么是 ReLU 函数?
ReLU 是一种非常简单却非常强大的非线性函数:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
- 如果输入 x > 0 x > 0 x>0,输出就是 x x x
- 如果输入 x ≤ 0 x \leq 0 x≤0,输出为 0
这条公式的意思是:只保留正数部分,负数全部"砍掉"。
✅ Python 实现非常简单
python
import numpy as np
def relu(x):
return np.maximum(0, x)这里用到了 NumPy 的 maximum 函数,它会对数组的每一个元素取最大值。
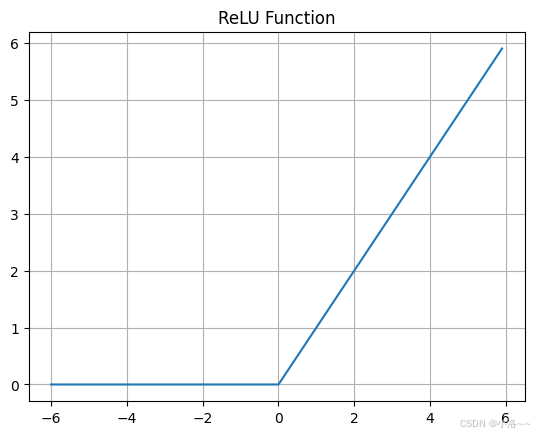
📊 可视化 ReLU 函数
我们可以画出 ReLU 函数的图像,来直观理解它在 x = 0 x=0 x=0 处的"拐点"特性:
python
import numpy as np
import matplotlib.pyplot as plt
def relu(x):
return np.maximum(0, x)
x = np.arange(-6.0, 6.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.title("ReLU Function")
plt.grid(True)
plt.show()图像会显示:在 x = 0 x=0 x=0 的地方出现一个拐点,左边全部输出 0,右边则是线性增长。
💡 ReLU 的优势
| 特性 | 说明 |
|---|---|
| 非线性 | ✅ 是非线性函数,适合神经网络 |
| 计算简单 | ✅ 只需一次比较,不涉及指数运算 |
| 收敛速度快 | ✅ 通常能让训练更高效 |
| 不会饱和(正半轴) | ✅ 对大输入保持响应,不像 sigmoid 那样趋于平稳 |
| 稀疏激活 | ✅ 很多输出为 0,提高稀疏性,有利于提升泛化能力 |
🧾 注意事项
虽然 ReLU 简单好用,但也有一些潜在问题:
-
当输入为负数时,导数为 0,可能会导致神经元死亡(Dead ReLU),即神经元不再更新;
-
为了解决这个问题,深度学习中出现了一些改进版本的 ReLU:
- Leaky ReLU:在负值区域也保留一个很小的斜率;
- PReLU(Parametric ReLU):斜率参数是可学习的;
- ELU(Exponential Linear Unit):在负半轴是指数函数,更平滑。
这些变种都能在负半轴保留一定的梯度,从而缓解 ReLU 的死亡问题。
📌 使用建议
- 在本章中,我们主要使用 sigmoid 函数来帮助理解神经网络的基本原理;
- 但在后续章节(特别是 卷积神经网络 CNN 部分),我们将更多使用 ReLU ,
因为它已成为现代深度学习的"标准配置"。
ReLU 简洁高效,是现代神经网络不可或缺的利器 🔥
3.3 多维数组的运算
在构建神经网络时,如果你能熟练掌握 NumPy 的 多维数组运算,将大大提升效率和代码简洁度。
本节内容分为三部分:
- 3.3.1 多维数组简介
- 3.3.2 矩阵乘法
- 3.3.3 神经网络的内积计算
3.3.1 多维数组
简单说,多维数组就是"数字的集合",可以是:
- 一维:列表
[1, 2, 3] - 二维:矩阵
- 三维及以上:张量(Tensor)
🧪 示例:一维数组
python
import numpy as np
A = np.array([1, 2, 3, 4])
print(A) # [1 2 3 4]
print(np.ndim(A)) # 1(表示是一维数组)
print(A.shape) # (4,)
print(A.shape[0]) # 4(数组的长度)这里的 shape 返回一个元组,即使是一维也保持一致性。
🧪 示例:二维数组(矩阵)
python
B = np.array([[1,2], [3,4], [5,6]])
print(B)
# [[1 2]
# [3 4]
# [5 6]]
print(np.ndim(B)) # 2
print(B.shape) # (3, 2)- 第一维度(行数)是 3
- 第二维度(列数)是 2
- 这就是一个 3x2 的矩阵
3.3.2 矩阵乘法
在神经网络中,我们会频繁用到矩阵乘法。NumPy 中的 np.dot() 可以帮我们轻松搞定。
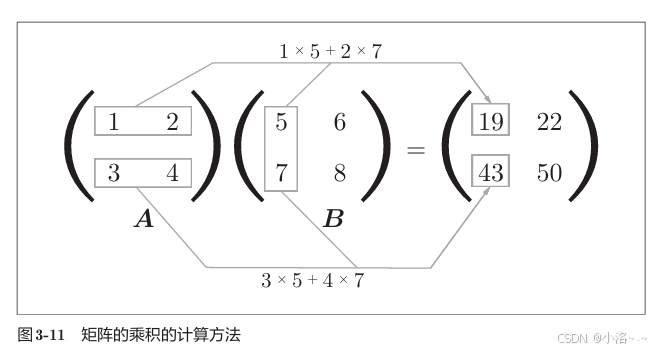
📌 基本示例:2x2 矩阵相乘
python
A = np.array([[1,2], [3,4]])
B = np.array([[5,6], [7,8]])
print(np.dot(A, B))
# 输出:
# [[19 22]
# [43 50]]📌 更通用的例子:2x3 乘 3x2
python
A = np.array([[1,2,3], [4,5,6]]) # 2x3
B = np.array([[1,2], [3,4], [5,6]]) # 3x2
print(np.dot(A, B))
# 输出:
# [[22 28]
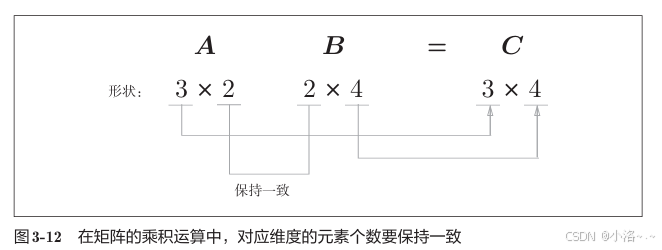
# [49 64]]✅ 注意事项:
要满足:第一个矩阵的"列数" == 第二个矩阵的"行数"
否则将报错:
python
C = np.array([[1,2], [3,4]])
np.dot(A, C)
# ValueError: shapes (2,3) and (2,2) not aligned: 3 (dim 1) != 2 (dim 0)原则是:
-
内维对齐(A 的列 = B 的行)
-
结果维度是 A 的行 × B 的列
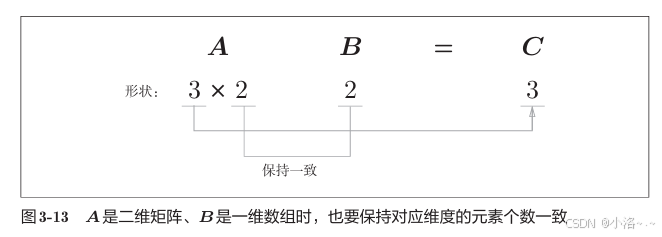
📎 例子:矩阵 × 向量(二维 × 一维)
python
A = np.array([[1,2], [3,4], [5,6]]) # shape: (3,2)
B = np.array([7, 8]) # shape: (2,)
print(np.dot(A, B))
# 输出:
# [23 53 83]这个操作表示:每一行向量与 B 做内积,返回的是一维数组。
3.3.3 神经网络的内积
来看图示结构如下的神经网络(仅包含输入与权重):
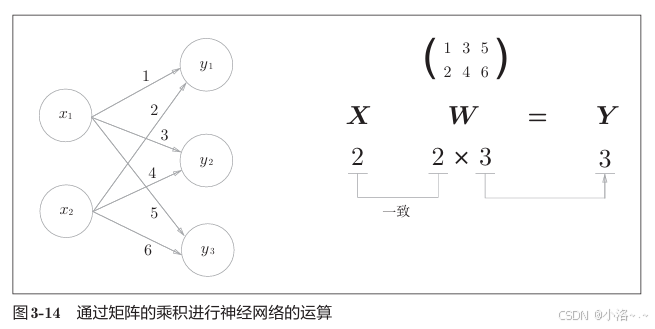
Python 实现如下:
python
X = np.array([1, 2]) # 输入
W = np.array([[1, 3, 5], [2, 4, 6]]) # 权重矩阵
print(np.dot(X, W))
# 输出:
# [ 5 11 17]🧮 计算逻辑
1 × 1 + 2 × 2 = 5 1 × 3 + 2 × 4 = 11 1 × 5 + 2 × 6 = 17 1 \times 1 + 2 \times 2 = 5 \\ 1 \times 3 + 2 \times 4 = 11 \\ 1 \times 5 + 2 \times 6 = 17 1×1+2×2=51×3+2×4=111×5+2×6=17
✅ 小结
| 知识点 | 说明 |
|---|---|
ndim() |
获取数组的维度 |
shape |
获取数组的形状(行列数) |
np.dot(A, B) |
执行矩阵乘法,要求维度对齐 |
| 内积(Dot Product) | 实现神经网络信号传递的核心操作 |
🚀 使用矩阵乘法(而不是
for循环)可以让神经网络的前向传播 更快更简洁!
3.4 三层神经网络的实现
本节我们将通过 NumPy 实现一个完整的 三层神经网络的前向传播(forward)过程。
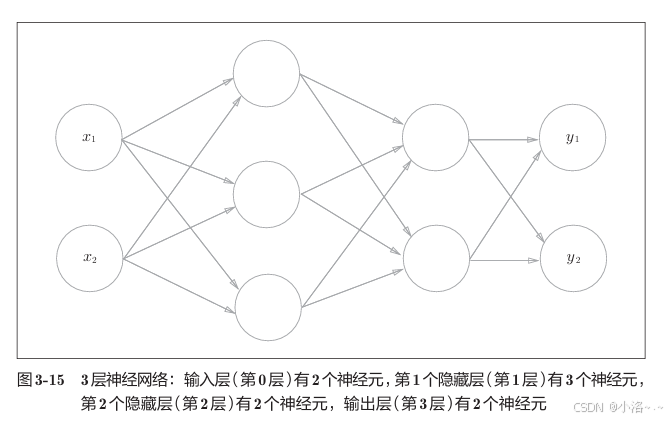
网络包含以下部分:
- 输入层(第0层):2 个神经元
- 第1个隐藏层(第1层):3 个神经元
- 第2个隐藏层(第2层):2 个神经元
- 输出层(第3层):2 个神经元
3.4.1 符号确认
在神经网络中,通常会用如下方式表示权重和偏置:
- W ( 1 ) W^{(1)} W(1):从第0层到第1层的权重矩阵
- b ( 1 ) b^{(1)} b(1):第1层的偏置向量
- 以此类推 W ( 2 ) W^{(2)} W(2), b ( 2 ) b^{(2)} b(2), W ( 3 ) W^{(3)} W(3), b ( 3 ) b^{(3)} b(3)
例如, w 21 ( 1 ) w^{(1)}_{21} w21(1) 表示从第0层第1个神经元到第1层第2个神经元的连接权重。
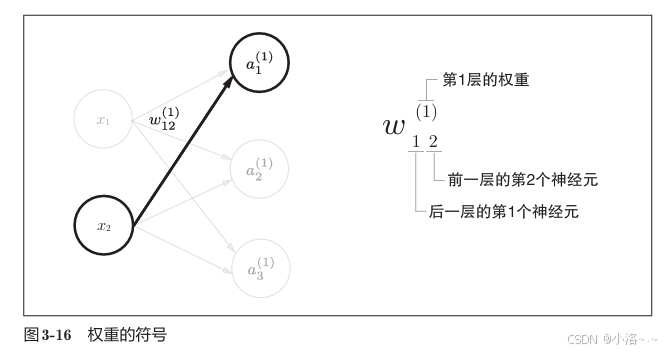
3.4.2 各层间信号传递的实现
我们现在来观察神经网络中信号如何在层与层之间传递。
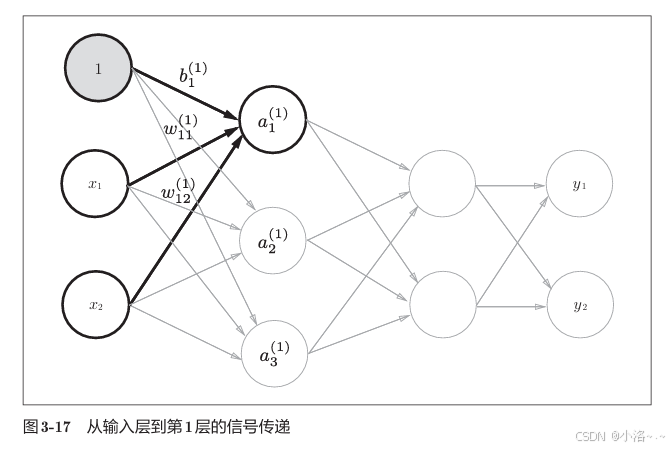
🔹 第0层 → 第1层(隐藏层)
为了简单起见,我们看输入层的两个神经元 x 1 x_1 x1 和 x 2 x_2 x2 是如何影响到第1层神经元的。传递过程如下:
在引入偏置之后,第1层的加权和可以写成:
a 1 = x 1 ⋅ w 11 ( 1 ) + x 2 ⋅ w 21 ( 1 ) + b 1 a 2 = x 1 ⋅ w 12 ( 1 ) + x 2 ⋅ w 22 ( 1 ) + b 2 a 3 = x 1 ⋅ w 13 ( 1 ) + x 2 ⋅ w 23 ( 1 ) + b 3 a_1 = x_1 \cdot w^{(1)}{11} + x_2 \cdot w^{(1)}{21} + b_1 \\ a_2 = x_1 \cdot w^{(1)}{12} + x_2 \cdot w^{(1)}{22} + b_2 \\ a_3 = x_1 \cdot w^{(1)}{13} + x_2 \cdot w^{(1)}{23} + b_3 a1=x1⋅w11(1)+x2⋅w21(1)+b1a2=x1⋅w12(1)+x2⋅w22(1)+b2a3=x1⋅w13(1)+x2⋅w23(1)+b3
我们也可以用矩阵的方式更简洁地写出这些计算:
A ( 1 ) = X ⋅ W ( 1 ) + b ( 1 ) (3.9) \mathbf{A}^{(1)} = \mathbf{X} \cdot \mathbf{W}^{(1)} + \mathbf{b}^{(1)} \tag{3.9} A(1)=X⋅W(1)+b(1)(3.9)
其中:
- X \mathbf{X} X 是输入向量
- W ( 1 ) \mathbf{W}^{(1)} W(1) 是输入层到第1层的权重矩阵
- b ( 1 ) \mathbf{b}^{(1)} b(1) 是第1层的偏置项
- A ( 1 ) \mathbf{A}^{(1)} A(1) 是加权和
✅ Python 实现:
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 输入数据
X = np.array([1.0, 0.5])
# 第1层的权重与偏置
W1 = np.array([[0.1, 0.3, 0.5],
[0.2, 0.4, 0.6]])
b1 = np.array([0.1, 0.2, 0.3])
# 前向传播:输入 → 第1层加权求和 + 激活
A1 = np.dot(X, W1) + b1
Z1 = sigmoid(A1)
print("A1:", A1) # [0.3 0.7 1.1]
print("Z1:", Z1) # [0.5744 0.6681 0.7502]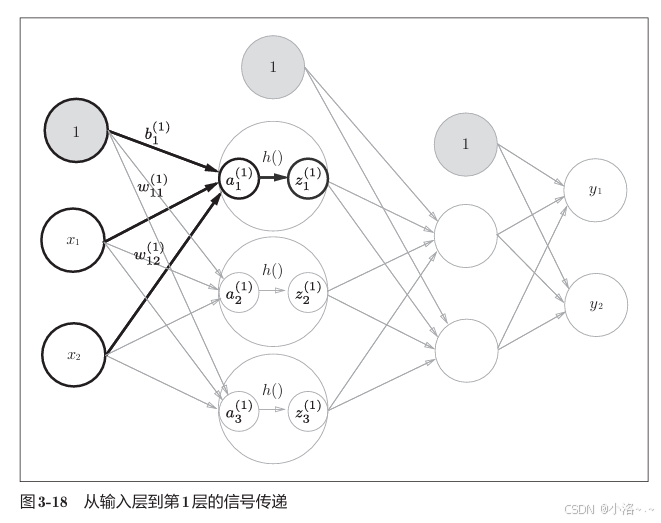
🔹 第1层 → 第2层(隐藏层)
继续将上一层的输出作为当前层的输入:
python
W2 = np.array([[0.1, 0.4],
[0.2, 0.5],
[0.3, 0.6]])
b2 = np.array([0.1, 0.2])
A2 = np.dot(Z1, W2) + b2
Z2 = sigmoid(A2)
print("Z2:", Z2)
🔹 第2层 → 输出层
输出层使用的是恒等函数 (Identity Function),也就是输入等于输出,公式如下:
Y = A ( 3 ) = Z ( 2 ) ⋅ W ( 3 ) + b ( 3 ) Y = A^{(3)} = Z^{(2)} \cdot W^{(3)} + b^{(3)} Y=A(3)=Z(2)⋅W(3)+b(3)
python
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3],
[0.2, 0.4]])
b3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + b3
Y = identity_function(A3) # 或者 Y = A3
print("Y:", Y)🎯 输出层激活函数的选择
| 问题类型 | 输出层激活函数 |
|---|---|
| 回归问题 | 恒等函数 |
| 二分类问题 | sigmoid |
| 多分类问题 | softmax |
我们将在后面小节详细介绍这些激活函数的差异与适用场景。
3.4.3 代码实现小结
我们可以将以上实现封装成两个函数:init_network()和forward()函数。
🧱 初始化网络参数
init_network()函数会进行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变量network中保存了每一层所需的参数(权重和偏置)。
python
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5],
[0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4],
[0.2, 0.5],
[0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3],
[0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network🔁 前向传播函数
forward()函数中则封装了将输入信号转换为输出信号的处理过程。
另外,这里出现了forward(前向)一词,它表示的是从输入到输出方向的传递处理。后面在进行神经网络的训练时,我们将介绍后向(backward,从输出到输入方向)的处理。
python
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y🚀 实际运行
python
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print("预测输出:", y) # [0.31682708 0.69627909]🔚 小结
-
使用矩阵乘法和激活函数,我们可以非常高效地实现多层神经网络;
-
NumPy 提供的向量化运算大大简化了代码复杂度;
-
"前向传播(forward)"是神经网络预测的核心流程;
-
接下来我们将介绍输出层的设计,包括 softmax 等函数。
💡 后续还将学习 "反向传播(backward)",用于训练网络并更新参数。
3.5 输出层的设计
神经网络可以用在两种类型的问题中:分类问题 和 回归问题。
- 分类问题:预测某个输入属于哪一个类别。例如识别一张图片是"猫"还是"狗"。
- 回归问题:预测一个连续的数值。例如预测图片中人物的体重是"65.3kg"。
不同任务要搭配不同的输出层激活函数:
- 分类问题 → 使用
softmax函数 - 回归问题 → 使用
恒等函数(Identity Function)
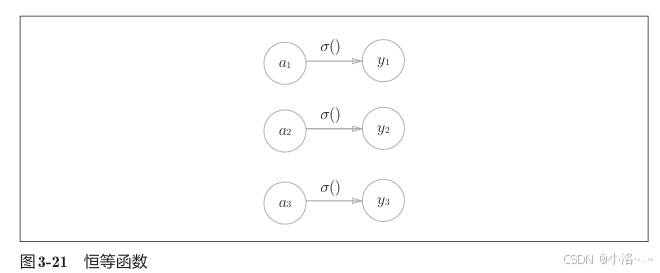
3.5.1 恒等函数和softmax函数
恒等函数 的作用非常简单 ------ 它会"原封不动"地输出输入值。适合用于回归问题 ,例如房价预测等。
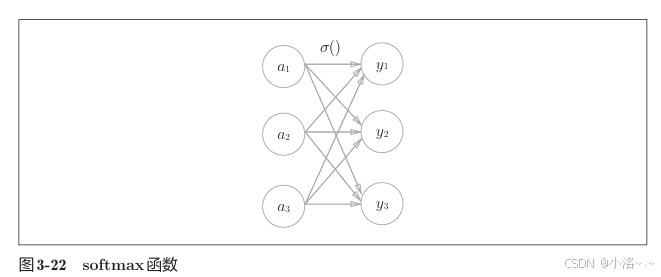
Softmax 函数 则常用于 多分类任务,例如判断图像中是"0~9"哪一个数字。
公式如下:
y k = e a k ∑ j e a j (公式 3.10) y_k = \frac{e^{a_k}}{\sum_j e^{a_j}} \quad \text{(公式 3.10)} yk=∑jeajeak(公式 3.10)
每个输出值都会变成一个概率,所有概率的总和是 1。
Python 实现示例:
python
import numpy as np
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
return exp_a / sum_exp_a
a = np.array([0.3, 2.9, 4.0])
print(softmax(a))# [0.01821127 0.24519181 0.73659691]3.5.2 实现softmax函数时的注意事项
虽然 softmax 函数的数学表达式简单:
y k = e a k ∑ j e a j y_k = \frac{e^{a_k}}{\sum_j e^{a_j}} yk=∑jeajeak
但在实际编程时却存在一个潜在的大问题 ------ 数值溢出(overflow)。
💥 为什么会溢出?
指数函数 exp(x) 的增长速度非常快:
- e 10 ≈ 22000 e^{10} \approx 22000 e10≈22000
- e 100 e^{100} e100 是一个巨大的数,后面有几十个 0
- e 1000 e^{1000} e1000 会变成无穷大(inf)
当你计算如下 softmax 时,就会遇到这个问题:
python
import numpy as np
a = np.array([1010, 1000, 990])
print(np.exp(a) / np.sum(np.exp(a)))输出:
bash
array([ nan, nan, nan]) # nan = Not a Number因为指数结果太大,超出了浮点数能表示的范围,导致整个计算变成了"未定义"的状态。
✅ 如何解决?
我们可以利用一个数学恒等式进行优化:
给 softmax 的输入向量整体减去一个常数 C C C(通常是最大值),不会改变最终的结果。
这背后的数学逻辑是这样的:
e a k ∑ j e a j = C ⋅ e a k C ⋅ ∑ j e a j = e a k − c ∑ j e a j − c \frac{e^{a_k}}{\sum_j e^{a_j}} = \frac{C \cdot e^{a_k}}{C \cdot \sum_j e^{a_j}} = \frac{e^{a_k - c}}{\sum_j e^{a_j - c}} ∑jeajeak=C⋅∑jeajC⋅eak=∑jeaj−ceak−c
其中 c = max ( a ) c = \max(a) c=max(a)。将输入 a a a 减去最大值 c c c,就可以避免过大的指数值导致溢出问题。
✨ 这个技巧不改变 softmax 的输出比例,却能大大提升数值稳定性,是深度学习中非常常见的数值优化方法。
🧪 修复后的 softmax 实现:
python
def softmax(a):
c = np.max(a) # 防止指数爆炸的关键
exp_a = np.exp(a - c) # 所有值都变小了,但比例不变
sum_exp_a = np.sum(exp_a)
return exp_a / sum_exp_a测试一下:
python
a = np.array([1010, 1000, 990])
y = softmax(a)
print(y)
# 输出: [0.99995, 0.000045, 2.06e-09] -> 正常输出 ✅通过这个技巧,我们让 softmax 函数在数值上更稳定,避免了潜在的程序崩溃风险。
3.5.3 softmax函数的特征
在神经网络中,softmax() 函数经常用于输出层,用于将网络输出转化为概率分布。
举个例子:
python
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 防止溢出
sum_exp_a = np.sum(exp_a)
return exp_a / sum_exp_a
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y) # [0.018, 0.245, 0.737]
print(np.sum(y)) # 1.0🎯 结果解读
- 输出值是 0~1 之间 的实数。
- 所有输出值的 总和为 1。
- 因此,softmax 的输出可以被解释为 概率分布。
比如:
- y 0 = 0.018 y_0 = 0.018 y0=0.018 表示类别 0 的概率是 1.8%
- y 1 = 0.245 y_1 = 0.245 y1=0.245 表示类别 1 的概率是 24.5%
- y 2 = 0.737 y_2 = 0.737 y2=0.737 表示类别 2 的概率是 73.7%
这意味着:模型认为输入属于类别 2 的可能性最大!
📌 重要性质
- softmax 不会改变各个元素之间的大小关系!
- 这是因为 exp ( x ) \exp(x) exp(x) 是单调递增函数。
所以:
最大的 a k a_k ak 仍然对应最大的 y k y_k yk,即 softmax 后排序不变。
💡 推理阶段可以省略 softmax 吗?
可以!
在实际使用中,推理阶段(也就是预测)时,通常只取最大值对应的索引:
python
pred = np.argmax(y)而 softmax 在训练阶段保留,是为了配合 交叉熵损失函数 使用。
🎯 为什么训练阶段保留 softmax,而推理阶段可以省略?
在神经网络中,softmax 函数通常在训练阶段使用,原因是:
📌 训练阶段:需要 softmax + 交叉熵损失函数(cross entropy)
- softmax 会将网络输出转化为概率分布(值在 0~1 之间,总和为 1);
- 然后与真实标签进行比较,计算 交叉熵损失;
- 这个组合结构能提供平滑、可微的误差反馈,有利于优化器更新权重。
例如:
python
y_pred = softmax(a) # 输出层的激活值
loss = cross_entropy(y_pred, y_true)🧠 推理阶段:softmax 可以被省略
推理阶段的目标是:判断哪个类别概率最大。
由于 softmax 不改变输入的大小关系(它是单调递增函数),所以我们完全可以跳过 softmax,直接比较原始输出:
python
pred = np.argmax(a) # 直接使用未经过 softmax 的输出这在实际部署中更高效,也节省了计算资源。
🔄 学习 vs 推理:两大阶段
| 阶段 | 目的 | softmax 是否必需 |
|---|---|---|
| 学习阶段 | 优化网络参数,最小化误差 | ✅ 需要(配合交叉熵) |
| 推理阶段 | 根据输入预测最可能的类别 | ❌ 可省略 |
✅ 小结
softmax + 交叉熵= 训练阶段的黄金搭档;- 推理阶段,只需要判断哪个输出值最大,
softmax可以省略; - 这样可以提升速度,尤其适合模型部署时的预测需求。
3.5.4 输出层的神经元数量
输出层的神经元数量应依据任务类型来设定:
| 任务类型 | 输出层神经元数量 |
|---|---|
| 二分类任务 | 通常为 1 或 2 |
| 多分类任务(10类) | 通常为 10 |
| 回归任务 | 根据目标值维度设定 |
以 手写数字识别 为例:
我们希望识别数字 0 到 9 ,共 10 类。
因此输出层应该设置为 10 个神经元 ,每个神经元对应一个数字类别。
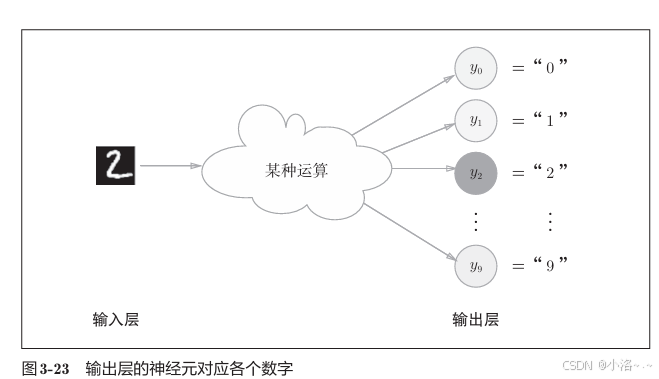
如果 softmax 输出如下:
python
[0.01, 0.03, 0.78, 0.05, ..., 0.02]那么预测结果就是:类别 2 的概率最高 → 模型预测结果是 "2"
🧠 小结:
softmax()将输出转化为 概率形式- 非常适用于 多分类任务
- 推理阶段可省略 softmax,提升运行效率
- 输出层神经元数量 = 类别数
3.6 手写数字识别
介绍完神经网络的结构后,我们来解决一个实际问题:识别手写数字。
假设训练已经完成,我们使用训练好的参数进行"推理处理"(即前向传播)。
3.6.1 MNIST数据集
MNIST 是最经典的手写数字图像集,由 28×28 的灰度图像组成,,各个像素
的取值在0到255之间。每个图像数据都相应地标有"7"" 2"" 1"等标签。共包含:
- 训练集:60,000 张图像
- 测试集:10,000 张图像
- 图像标签:数字
0~9
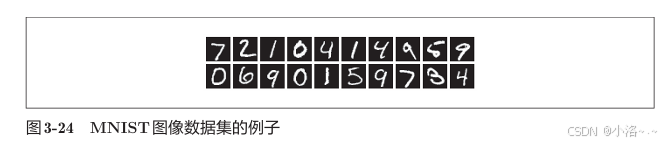
加载 MNIST 数据,显示MNIST图像
修改了源代码,数据集请自行下载。
python
# coding: utf-8
import os
import pickle
import numpy as np
from PIL import Image
dataset_dir = os.path.join("C:/Users/18302/seadrive_root/周妍含/我的资料库/课题/深度学习+大模型学习/ch3", "dataset")
save_file = os.path.join(dataset_dir, "mnist.pkl")
# 加载使用数据集
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
参数:
----------
normalize : 是否将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图片展开成一维数组
返回值:
----------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, "rb") as file:
dataset = pickle.load(file)
if normalize:
for key in ("train_img", "test_img"):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset["train_label"] = _change_one_hot_label(dataset["train_label"])
dataset["test_label"] = _change_one_hot_label(dataset["test_label"])
if not flatten:
for key in ("train_img", "test_img"):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset["train_img"], dataset["train_label"]), (
dataset["test_img"],
dataset["test_label"],
)
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
3.6.2 神经网络的推理处理
我们现在来实现一个简单的神经网络,用于对 MNIST 手写数字图像进行分类预测。
神经网络结构如下:
-
输入层:784 个神经元(因为每张图像是 28×28 像素)
-
隐藏层1:50 个神经元
-
隐藏层2:100 个神经元
-
输出层:10 个神经元(对应数字 0 到 9 的分类)
✅ 关键函数定义
python
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y**init_network()会读入保存在pickle文件sample_weight.pkl中的学习到的权重参数A。这个文件中以字典变量的形式保存了权重和偏置参数。**剩余的2个函数,和前面介绍的代码实现基本相同,无需再解释。现在,我们用这3个函数来实现神经网络的推理处理。然后,评价它的识别精度(accuracy),即能在多大程度上正确分类。
🧪 执行推理处理
首先获得MNIST数据集,生成网络。接着,用for语句逐一取出保存在x中的图像数据,用predict()函数进行分类。predict()函数以NumPy数组的形式输出各个标签对应的概率。
比如输出0.1, 0.3, 0.2, ..., 0.04的数组,该数组表示"0"的概率为0.1," 1"的概率为0.3,等等。
然后,我们取出这个概率列表中的最大值的索引(第几个元素的概率最高),作为预测结果。可以用np.argmax(x)函数取出数组中的最大值的索引,np.argmax(x)将获取被赋给参数x的数组中的最大值元素的索引。最后,比较神经网络所预测的答案和正确解标签,将回答正确的概率作为识别精度。
python
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 概率最大对应的分类标签
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:", float(accuracy_cnt) / len(x))📌 输出说明
示例输出:
python
Accuracy: 0.9352表示神经网络在 10,000 张测试图像上达到了 93.52% 的识别准确率。
完整代码:
python
# coding: utf-8
import os
import numpy as np
import pickle
def identity_function(x):
return x
def step_function(x):
return np.array(x > 0, dtype=np.int)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x)
def relu(x):
return np.maximum(0, x)
def relu_grad(x):
grad = np.zeros(x)
grad[x>=0] = 1
return grad
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def softmax_loss(X, t):
y = softmax(X)
return cross_entropy_error(y, t)
dataset_dir = os.path.join("C:/Users/18302/seadrive_root/周妍含/我的资料库/课题/深度学习+大模型学习/ch3", "dataset")
save_file = os.path.join(dataset_dir, "mnist.pkl")
# 加载使用数据集
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
参数:
----------
normalize : 是否将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图片展开成一维数组
返回值:
----------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, "rb") as file:
dataset = pickle.load(file)
if normalize:
for key in ("train_img", "test_img"):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset["train_label"] = _change_one_hot_label(dataset["train_label"])
dataset["test_label"] = _change_one_hot_label(dataset["test_label"])
if not flatten:
for key in ("train_img", "test_img"):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset["train_img"], dataset["train_label"]), (
dataset["test_img"],
dataset["test_label"],
)
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))🎯 数据预处理的重要性
在 load_mnist() 中设置 normalize=True,会将图像像素值从 0~255 缩放到 0.0~1.0 区间 ------ 这个过程称为正规化。
这是神经网络中非常常见的预处理步骤,带来多种好处:
- 🚀 提高训练效率
- 🎯 提升识别精度
- 🛡️ 避免梯度爆炸问题
📌 常见的预处理方式包括:
- 均值归一化(中心化)
- 标准化(除以标准差)
- 白化处理(Whitening,去除冗余相关性)
3.6.3 批处理
我们已经实现了基于 MNIST 数据集的神经网络推理,现在来关注一个更高效的实现方式 ------ 批处理(Batch Processing)。
🎯 查看数据与权重的形状
通过下面的代码,我们可以查看输入数据及神经网络各层权重的维度:
python
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
print(x.shape) # (10000, 784) -> 一共有10000张图片,每张展平为784维
print(x[0].shape) # (784,)
print(W1.shape) # (784, 50)
print(W2.shape) # (50, 100)
print(W3.shape) # (100, 10)我们可以确认:
-
输入数据维度为 (10000, 784)
-
每层之间的矩阵乘法维度是对齐的
-
输出是 (10,),即每张图像的十分类概率
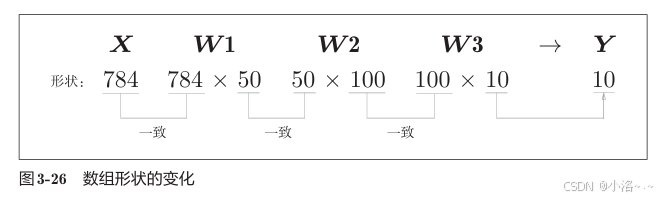
📊 数据维度变换示意
从整体的处理流程来看,图3-26中,输入一个由784个元素(原本是一个28×28的二维数组)构成的一维数组后,输出一个有10个元素的一维数组。这是只输入一张图像数据时的处理流程。
现在我们来考虑打包输入多张图像的情形。比如,我们想用predict()函数一次性打包处理100张图像。为此,可以把x的形状改为100×784,将100张图像打包作为输入数据。用图表示的话,如图3-27所示。
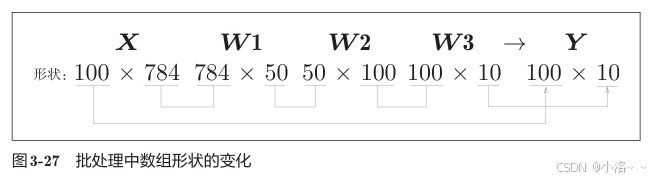
这就是 批处理(Batch Processing)。这种打包式的输入数据称为批(batch)。批有"捆"的意思,图像就如同纸币一样扎成一捆。
✅ 批处理的代码实现
以下是完整实现:
python
x, t = get_data()
network = init_network()
batch_size = 100 # 每批100张图像
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:", float(accuracy_cnt) / len(x)) 示例输出:
python
Accuracy: 0.9352📌 关键说明
range(0, len(x), batch_size)
用来按照批次划分数据,例如:
python
list(range(0, 10, 3)) # 输出 [0, 3, 6, 9]xi:i+batch_size
用切片一次性取出一个批次,例如:
python
x[0:100], x[100:200], ...np.argmax(y_batch, axis=1)
在二维数组中找出每一行中最大的元素的索引(预测类别):
python
x = np.array([
[0.1, 0.8, 0.1],
[0.3, 0.1, 0.6],
[0.2, 0.5, 0.3],
[0.8, 0.1, 0.1]
])
y = np.argmax(x, axis=1)
print(y) # 输出 [1 2 1 0]np.sum(y == t)
计算预测正确的数量:
python
y = np.array([1, 2, 1, 0])
t = np.array([1, 2, 0, 0])
print(y == t) # [True True False True]
print(np.sum(y == t)) # 3🎉 小结
-
批处理(Batch) 是提高神经网络运行效率的关键技术。
-
可减少循环次数,加速计算。
-
未来在模型训练阶段,我们也会使用相同的 批处理逻辑 来进行学习。
3.7 小结
本章介绍了神经网络的前向传播。
虽然本章的神经网络在"信号逐层传递"的结构上与上一章的感知机类似,但两者在激活函数的使用上有显著不同:
感知机使用的是 阶跃函数 (信号急剧变化),而神经网络中则采用了 平滑的 sigmoid 函数。这个差异对后续的"学习"过程非常关键,我们将在下一章详细探讨。
✅ 本章学习要点
-
激活函数
神经网络使用的激活函数是具有平滑性质的函数,如
sigmoid和ReLU。 -
矩阵计算
借助 NumPy 的多维数组,神经网络的前向传播可以高效地实现为一系列矩阵乘法。
-
任务类型划分
机器学习中的问题大致分为:
- 回归问题(输出连续值)
- 分类问题(输出类别)
-
输出层的激活函数选择
- 回归问题 → 使用恒等函数(identity)
- 分类问题 → 使用 softmax 函数
-
输出层神经元数量
分类问题中,输出层神经元个数应等于分类类别的数量。
-
批处理(Batch)
多张图像组成的输入集合称为"批(batch)",批处理可以显著提升推理效率,是现代深度学习的常用技巧。