目录
一、引言
本篇文章将继续介绍Redis中的主从复制机制
二、介绍
主从复制是在分布式系统中实现的,希望有多个服务器来部署redis
1.主从模式:
在若干个redis节点中,有的是主节点,有的是从节点。从节点的数据要跟随主节点进行变化。从节点相当于主节点的副本。从节点上的数据只能读取,不能进行修改。
2.主从+哨兵模式
3.集群模式
三、解决问题
主从模式解决的问题:
1.可用性问题
2.性能/支持的并发量也是比较有限的

四、配置主从复制

offset:从节点和主节点之间同步数据的进度
info命令:replication:查看主从复制的内容

slaveof no one:断开所有的主从复制关系
断开之后,所拥有的数据还是会拥有,但是从节点无法再自动更新数据了
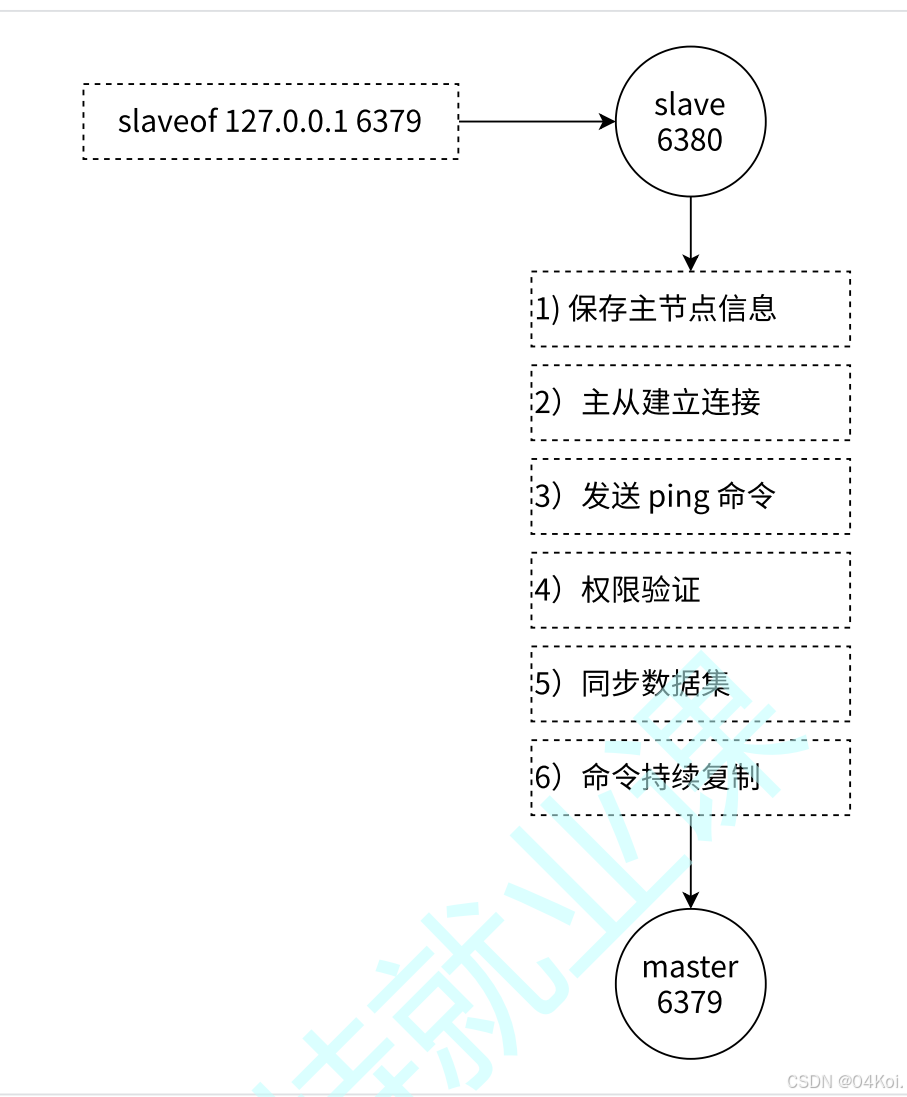
复制是使用了redis的psync命令,完成数据同步的过程。
psync不需要我们手动执行,redis服务器在建立好同步关系之后,自动执行psync。从节点负责执行psync,从节点从主节点那边拉取数据
psync可以从主节点获取全量数据,也可以获取部分数据,主要是看offset的进度,如果offset写作-1,就是获取全量数据,如果是正整数就是获取偏移量的数据
命令:psync replicationid offset
replicationid是主节点生成的,启动的时候就生成了(即使是同一个主节点,每次重启,生成的replicationid都是不同的)从节点和主节点建立了复制关系,就会从主节点这边拿到replicationid。
存在replicationid和replicationid2,replication2是由于A可能因为网络波动掉线了,B就会自己成为主节点(并生成一个replicationid),并且B也会记得A的replicationid(也就是replication2),当网络稳定了,A回归了,B也可以通过replication2重新成为A的从节点。
offset(偏移量):
主节点:会把修改命令,每个命令的字节数进行累加,得到的数字就是偏移量
从节点:现在从节点同步主节点的数据同步到哪个位置了
如果两个redis客户端:replication,offset都一样,就代表两个机器上的redis存储的数据是一样的。
1.复制
全量复制:
1.从节点主动向主节点发送psync命令,由于是第一次,就全量复制
2.根据命令解析处是全量复制,就返回fullresync命令
3.从节点接收到主节点的运行信息(replicationId等)进行保存
4.主节点执行bgsave进行RDB文件的持久化
5.主节点发送RDB文件给从节点,从节点保存RDB数据到本地硬盘
6.**主节点在4,5步进行的时候,这一过程中产生的写操作写入缓冲区中,**等从节点保存完RDB文件后,主节点再将缓冲区的数据也传输给从节点
7.从节点清空自身原有的旧数据
8.从节点加载RDB文件得到与主节点一致的数据
9.从节点判断自己是否开启了AOF,如果开启了就会进行AOF的bgrewriteaof,对冗余信息进行整理。
无硬盘模式的全量复制:
主节点生成的RDB二进制数据不是保存在文件中了,而是直接进行网络传输(省下了读硬盘和写硬盘的操作)
从节点直接把收到的数据进行加载了
runId/replid:
replid和runId是不同的东西
replid主要是在主从复制中起作用,标识了一个数据集合
runid与主从复制没啥关系
部分复制:
psync命令带有具体的replid和offset值,主节点就会去判断按照全量复制还是部分复制。
1.出现网络中断,主节点与从节点断开连接
2.断开期间,主节点收入的数据会放入挤压缓冲区中(基于内存的一个简单队列)
3.恢复连接之后,从节点与主节点建立连接
4.从节点将之前保存好的replid和offset偏移量发给主节点,主节点自我判断是全量复制还是部分复制。
5.根据offset去积压缓冲区查找合适的数据,并响应+continue给从节点
6.主节点根据需要的数据把数据发送给从节点,保证数据一致性。
实时复制:
主节点和从节点已经同步好了数据,但是主节点的数据还在不断改变,也需要同步给从节点。从节点和主节点会建立一个TCP长连接,然后主节点会把修改数据的请求发给从节点。
五、总结
主从复制主要解决了单点问题,可以预防某个redis服务器突然崩了,所以主从复制很好地解决了这个问题,下一篇文章我们将介绍哨兵模式,感谢观看!