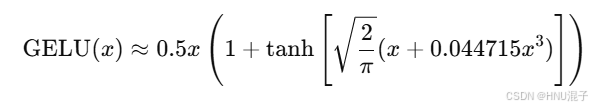前情 回顾
前面我们已经实现一个图像嵌入层和顶层的模型调度:
class` `SiglipVisionTransformer(nn.Module):` `##视觉模型的第二层,将模型的调用分为了图像嵌入模型和transformer编码器模型的调用`
`def` `__init__(self, config:SiglipVisionConfig):`
`super().__init__()`
`self.config = config`
`self.embed_dim = config.hidden_size`
`self.embeddings =` `SiglipVisionEmbeddings(config)` `## 负责将图像嵌入成向量`
`self.encoder =` `SiglipEncoder(config)` `## 负责将向量编码成注意力相关的向量`
`self.post_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)` `## 层归一化`
`def` `forward(self, pixel_values:torch.Tensor)` `-> torch.Tensor:`
`"""`
` pixel_values:` `[Batch_size,Channels,Height,Width]`
`"""`
`## [ Batch_size,Channels,Height,Width] -> [Batch_size,Num_Patches,Embedding_size] `
` hidden_states =` `self.embeddings(pixel_values)` `## 将图像嵌入成向量`
`# [Batch_size,Num_Patches,Embedding_size] -> [Batch_size,Num_Patches,Embedding_size]`
` last_hidden_state =` `self.encoder(hidden_states)` `## 将向量编码成注意力相关的向量`
`# [Batch_size,Num_Patches,Embedding_size] -> [Batch_size,Num_Patches,Embedding_size]`
` last_hidden_state =` `self.post_layer_norm(last_hidden_state)`
`return last_hidden_state`
`这里我们传入一个图像数据集,它会先通过SiglipVisionEmbeddings 把图像编码成嵌入向量,但此时的向量还不是上下文相关的,所以我们加入了一个SiglipEncoder层来做注意力嵌入,嵌入完了之后通过归一化即可返回一个图像的上下文相关的嵌入向量。有关图像嵌入部分和归一化部分之前已经提及了。这里我们着重于实现transformer的注意力层。
编码器 的 结构

由"A****ttention is all you need"这篇论文,我们可以了解到,编码器的架构如上图所示,输入嵌入 + 位置编码形成了编码器的输入,在Encoder层中会有N个这样的Encoder块,每个Encoder块中先通过一个多头注意力计算,再进行残差连接和归一化,然后再通过前向传播的MLP层,再进行一次残差连接和归一化。
这里残差连接的作用是防止梯度消失,多头注意力层可以让不同的token(在图像里面是patch)相关联,然后再通过一个MLP层增加整体的参数和模型的上限。
于是我们也创建一个SiglipEncoder层:
class` `SiglipEncoder(nn.Module):`
`def` `__init__(self, config:SiglipVisionConfig):`
`super().__init__()`
`self.config = config`
`self.embed_dim = config.hidden_size`
`self.num_hidden_layers = config.num_hidden_layers`
`self.layers = nn.ModuleList([SiglipEncoderLayer(config)` `for _ in range(self.num_hidden_layers)])` `## 多层编码器`
`def` `forward(self, input_embeddings:torch.Tensor)` `-> torch.Tensor:`
` hidden_states = input_embeddings`
`for layer in` `self.layers:`
` hidden_states = layer(hidden_states)`
`return hidden_states`
`一个Encoder层由若干个SiglipEncoderLayer块组成,具体多少个是作为超参数在配置中修改的。接着我们需要实现每个SiglipEncoderLayer块。
SiglipEncoderLayer 的 结构
注意:这里我们稍作了修改,我们在模型第二层调用这里加了一个post_layer_norm:
self.post_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)` `## 层归一化`
`这是因为我们希望嵌入向量在进入编码器之前和之后都做一次归一化,所以每个EncodeLayer块中我们先做归一化,再做自注意力,再做归一化和MLP,然后整个Encoder调用的输出,我们会用post_layer_norm做一次归一化。参考SiglipVisionTransformer类。
根据之前的结构我们编写如下的代码:
class` `SiglipEncoderLayer(nn.Module):`
`def` `__init__(self, config:SiglipVisionConfig):`
`super().__init__()`
`self.config = config`
`self.embed_dim = config.hidden_size`
`self.self_atten =` `SiglipAttention(config)` `## 注意力层`
`self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)` `## 层归一化`
`self.mlp =` `SiglipMLP(config)` `## MLP层`
`self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)` `## 层归一化`
`def` `forward(self, hidden_states:torch.Tensor)` `-> torch.Tensor:`
`"""`
` hidden_states:` `[Batch_size,Num_Patches,Embedding_size]`
`"""`
` residual = hidden_states `
` hidden_states =` `self.layer_norm1(hidden_states)` `## 层归一化 `
` hidden_states =` `self.self_atten(hidden_states)` `## 注意力层`
`## 残差连接 [Batch_size,Num_Patches,Embedding_size]`
` residual = hidden_states = hidden_states + residual `
` hidden_states =` `self.layer_norm2(hidden_states)`
` hidden_states =` `self.mlp(hidden_states)` `## MLP层`
`## 残差连接 [Batch_size,Num_Patches,Embedding_size]`
`return hidden_states + residual`
`MLP层的结构
我们先实现简单的MLP层,这里是将自注意力的输出进行线性变换,主要是为了增加参数量,扩展模型的性能上限。代码如下:
class` `SiglipMLP(nn.Module):`
`def` `__init__(self, config:SiglipVisionConfig):`
`super().__init__()`
`self.config = config`
`self.embed_dim = config.hidden_size`
`self.intermediate_size = config.intermediate_size`
`self.fc1 = nn.Linear(self.embed_dim,` `self.intermediate_size)`
`self.fc2 = nn.Linear(self.intermediate_size,` `self.embed_dim)`
`def` `forward(self, hidden_states:torch.Tensor)` `-> torch.Tensor:`
`"""`
` hidden_states:` `[Batch_size,Num_Patches,Embedding_size]`
`"""`
` hidden_states =` `self.fc1(hidden_states)` `## [Batch_size,Num_Patches,Embedding_size] -> [Batch_size,Num_Patches,Intermediate_size]`
` hidden_states = nn.functional.gelu(hidden_states,approximate="tanh")` `## [Batch_size,Num_Patches,Intermediate_size] gelu激活函数`
` hidden_states =` `self.fc2(hidden_states)` `## [Batch_size,Num_Patches,Intermediate_size] -> [Batch_size,Num_Patches,Embedding_size]`
`return hidden_states`
`值得一提的是,这里的激活函数用的是gelu激活函数,那我们对gelu激活函数做一个简单的介绍。
G el u 激活 函数
gelu激活函数是relu激活函数的变体,我们先谈一下激活函数的发展。
激活函数是什么?
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
所以激活函数的作用主要是为模型引入非线性。
早期的 激活 函数 是 s i g m o i d 激活 函数 , 其 公式 和图像如下 :
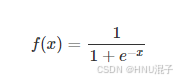
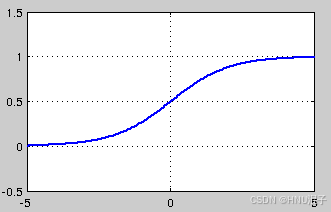
这里从图像就可以看出来这是一个非线性的函数,并且是单调的,它把R域的数值放缩到0和1之间。
但是sigmoid函数有一些问题:
- 在输入小于-5或者大于5的时候,梯度就非常平缓了,这容易导致梯度消失的问题
- 函数的计算公式复杂,这在求梯度的时候要花费很大的计算资源
于是 为了 改进 这些 缺点 , 人 们 又 提出 了 r e l u 激活 函数
relu激活函数的公式如下:
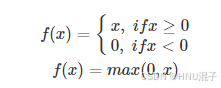
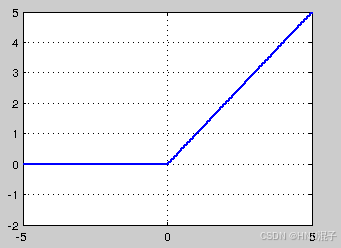
- relu的全称是Rectified Linear Units ,即整流线性单元,这里我们可以看到,梯度被保留下来了,且计算复杂度也降低了。
但是这不够完美,因为小于0的部分都置为0了,模型无法从小于0的神经元中学习到任何知识,所以人们又对其进行优化,并提出了gelu函数。
G e l u 函数
GELU函数的全称是(Gaussian Error Linear Unit ),也叫高斯误差线性激活单元,其公式如下:
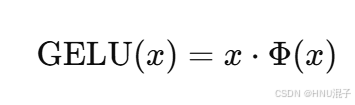
其中,φ(x)表示标准正态分布的累计概率密度函数,从累计概率密度函数的定义我们可以知道,它在R域上从0到1递增的,GELU函数的图像如下所示:
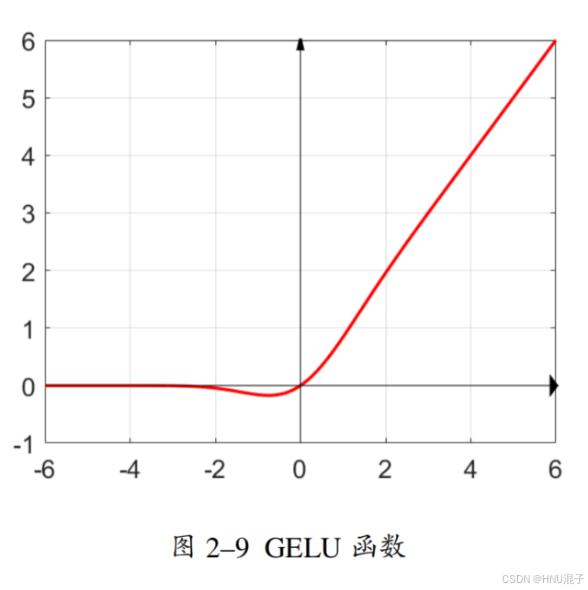
可以看到,在函数小于0的部分并非简单的输出0,而是对一些信息做了保留,同时也让函数更加的平滑了。相比于RELU来说,GELU函数是连续可导的。
在计算复杂度上,GELU虽然比RELU的计算复杂度高上不少,但是人们用近似公式来计算GELU,这使得GELU函数的计算复杂度与sigmoid函数相似,这是可以接受的,因为它改进了sigmoid梯度消失的问题。近似公式如下: