
在信息技术(IT)的滚滚浪潮中,一种新兴技术正以惊人速度崭露头角------隐私计算(Privacy-Preserving Computation)。2025 年,随着数据泄露事件频发、全球隐私法规日益严格,以及企业对数据协作需求的激增,隐私计算成为 IT 行业的焦点。它让数据在不暴露原始信息的情况下实现共享与计算,彻底颠覆了传统数据处理的模式。从金融风控到医疗研究,从广告精准投放到政府数据共享,隐私计算正在为数据安全点燃一盏明灯,成为智能未来的守护者。
隐私计算是什么?它为何能在短时间内引发热议?它又将如何重塑 IT 生态?本文将带你深入探索隐私计算的核心理念、技术基石、应用场景,以及它面临的挑战与前景。无论你是安全工程师、数据科学家,还是对技术趋势充满好奇的探索者,这篇关于隐私计算的全面剖析都将让你受益匪浅。让我们一起揭开这场数据安全革命的面纱!
隐私计算的本质:数据可用不可见的魔法
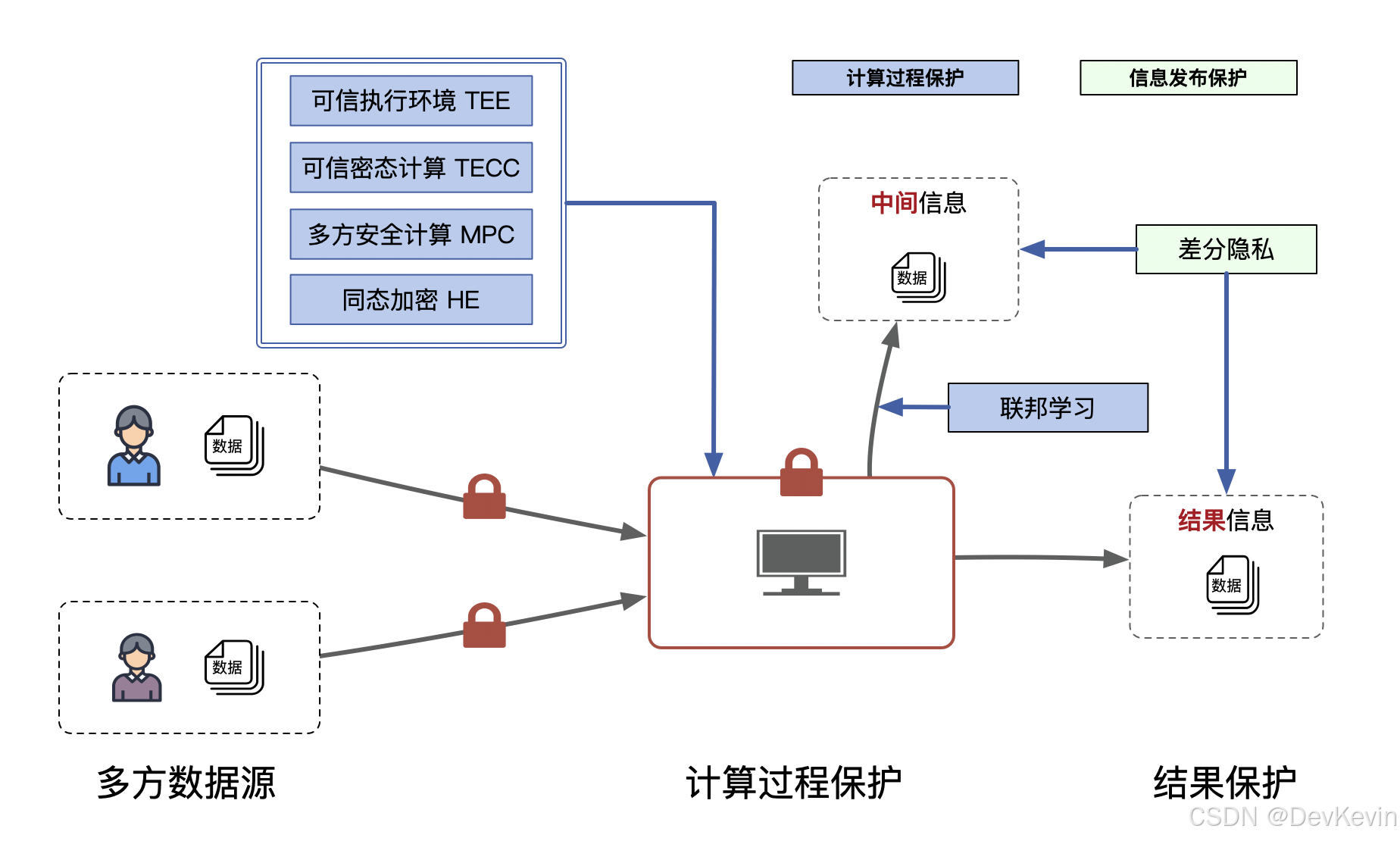
传统数据处理像一个敞开的集市:企业或机构将原始数据交给第三方分析,结果虽然有用,但隐私暴露无遗。而隐私计算则像一场"蒙眼交易":数据不出本地,通过加密或其他技术完成计算,参与方只看到结果,看不到原始数据。这种"数据可用不可见"的特性,正是隐私计算的灵魂。
隐私计算的核心目标是:在保护隐私的前提下,释放数据的价值。它通过数学和密码学的魔法,解决了一个看似矛盾的问题------如何让多方协作分析数据,又不泄露各自的秘密。这种能力让隐私计算成为大数据和 AI 时代的安全基石。
举个例子:两家银行想联合分析客户信用风险,但不愿共享原始数据。隐私计算可以在加密状态下计算风险评分,最终只输出结果,双方数据全程保密。这种"零信任"模式,正在改变数据经济的游戏规则。
隐私计算的演进:从学术梦想到产业热潮

隐私计算的起源可以追溯到 20 世纪 80 年代。1982 年,密码学家安德鲁·姚(Andrew Yao)提出了"百万富翁问题":两个富翁想知道谁更有钱,但不想透露具体财富。这一理论奠定了安全多方计算(MPC)的基石。随后,同态加密(Homomorphic Encryption)和差分隐私(Differential Privacy)相继问世,为隐私计算提供了更多工具。
2010 年代,随着云计算和大数据的兴起,隐私计算从学术走向应用。2016 年,谷歌提出联邦学习(Federated Learning),让设备在本地训练模型,只上传参数而非数据,引发业界轰动。2020 年,欧盟的《通用数据保护条例》(GDPR)和中国的《个人信息保护法》生效,隐私计算成为企业合规的救命稻草。
到 2025 年,隐私计算进入产业化阶段。蚂蚁集团的"隐语"平台支持金融风控,微软的 Azure Confidential Computing 提供硬件级保护,中国的 FATE(联邦 AI 技术框架)开源社区则吸引了全球开发者。隐私计算不再是"实验室玩具",而是数据安全的"产业标配"。
核心技术:隐私计算的基石与工具箱
隐私计算的实现依赖于多学科融合,以下是几个关键技术:
安全多方计算(MPC)
MPC 让多方在加密状态下协作计算。例如,一个简单的加法:
python
from smpc_library import secure_add
party1_data = 100 # 本地数据保密
party2_data = 200 # 另一方数据保密
result = secure_add(party1_data, party2_data)
print("加密加法结果:", result) # 输出 300,原始数据不泄露这通过秘密共享实现计算安全。
同态加密(HE)
HE 允许在密文上直接运算。例如,使用 Python 库 PySEAL:
python
from seal import *
parms = EncryptionParameters(scheme_type.BFV)
parms.set_poly_modulus_degree(4096)
context = SEALContext(parms)
encryptor = Encryptor(context, public_key)
encrypted = encryptor.encrypt(Plaintext("100"))
evaluator.add(encrypted, encrypted2) # 加密状态下加法结果解密后正确,但原始数据不可见。
联邦学习(FL)
FL 让模型在本地训练,只交换参数。例如,一个联邦平均示例:
python
local_model = train_local(data)
global_model = aggregate([local_model, other_models])这保护了设备端数据隐私。
差分隐私(DP)
DP 通过添加噪声保护个体数据。例如,给统计结果加噪:
python
import numpy as np
data = [1, 2, 3, 4, 5]
noisy_mean = np.mean(data) + np.random.laplace(0, 0.1)
print("加噪平均值:", noisy_mean)这确保了统计结果不泄露个体信息。
这些技术各有千秋,共同构成了隐私计算的工具箱,满足不同场景需求。
隐私计算的杀手级应用
隐私计算的价值在现实中熠熠生辉,以下是几个改变行业的案例:
金融风控协作
蚂蚁集团与多家银行用隐语平台联合分析客户信用数据,在不共享原始数据的情况下,生成风险模型,2025 年欺诈检测率提升了 25%。
医疗数据共享
一家医院用联邦学习分析患者数据,与药企合作研发新药。数据不出院墙,研发周期缩短了 30%。
广告精准投放
谷歌用差分隐私优化广告推荐,避免泄露用户浏览历史,2025 年其隐私友好广告收入增长 15%。
智慧城市
北京用 MPC 分析交通和用电数据,优化资源分配,数据不出各单位,城市能效提升 10%。
跨境数据合规
一家中欧企业用同态加密共享供应链数据,满足 GDPR 和《数据安全法》要求,协作效率提高 20%。
这些应用表明,隐私计算不仅是安全工具,更是数据经济的新引擎。
中国在隐私计算中的雄心
中国在隐私计算领域展现了强大实力。蚂蚁集团的隐语平台已服务超 1000 家机构,2025 年其在金融和电商领域的应用覆盖率达 60%。腾讯云的 TFHE(全同态加密框架)支持医疗和政务场景,华为云则推出隐私计算一体机,聚焦工业数据协作。
中国的优势在于:
政策驱动
《个人信息保护法》和《数据安全法》为隐私计算提供了法律土壤。

生态整合
蚂蚁、腾讯等巨头将隐私计算嵌入云服务,形成闭环生态。
开源引领
FATE 社区吸引了全球开发者,推动技术标准化。
例如,蚂蚁集团为一家保险公司开发了隐私风控系统,通过 MPC 分析投保数据,理赔效率提升了 15%。这种本地化创新让中国在隐私计算赛道上占据先机。
挑战与争议:隐私计算的试炼
隐私计算虽潜力无限,但也面临挑战:
性能瓶颈
加密计算(如 HE)比明文慢数百倍,可能拖慢实时应用。
复杂性与成本
部署隐私计算需要专业技能和额外算力,小企业可能难以承受。
信任问题
即使数据加密,用户仍可能质疑平台的可靠性。例如,2024 年一家隐私计算服务商因算法漏洞泄露数据,引发争议。
法规差异
各国隐私标准不一,跨境协作可能受阻。
技术成熟度
部分技术(如零知识证明)仍处于早期,稳定性有待验证。
这些挑战提醒我们,隐私计算的普及需技术与政策的双重突破。
未来展望:隐私计算的下一幕
到 2030 年,隐私计算可能成为数据处理的标配。以下是几个趋势:
AI 与隐私融合
联邦学习将与大模型结合,实现隐私保护的智能推理。
硬件加速
Intel SGX、华为鲲鹏等可信执行环境(TEE)将提升加密计算速度。
全球标准化
ISO 等组织可能推出隐私计算标准,推动跨境数据流动。
对于 IT 从业者,学习隐私计算(如 FATE、PySEAL)将成为新竞争力。一个简单的差分隐私示例:
python
import diffprivlib.models as dp
model = dp.LogisticRegression(epsilon=1.0)
model.fit(X, y)
print("隐私保护模型准确率:", model.score(X_test, y_test))这展示了隐私计算的实用性。
尾声:隐私计算点燃的数据安全未来
隐私计算是一场从数据裸奔到安全协作的革命。它用加密点燃了隐私保护的希望,用技术守护了数据的未来。从金融的联合风控到医疗的隐私研究,隐私计算正在以惊人速度改变IT世界。
你是否准备好迎接隐私计算的崛起?它会如何影响你的行业或生活?是更安全的协作,还是更智能的决策?欢迎在评论区分享你的畅想,一起见证隐私计算如何成为数据安全的未来守护者!