
新智元报道
编辑:编辑部
【新智元导读】2025 年斯坦福 HAI 报告重磅发布,456 页深度剖析全球 AI 领域的最新趋势:中美顶级模型性能差距缩至 0.3%,以 DeepSeek 为代表的模型强势崛起,逼近闭源巨头;推理成本暴降,小模型性能飙升,AI 正变得更高效、更普惠。
就在刚刚,每年都备受瞩目的斯坦福 AI 指数报告,重磅发布了!
这份报告由斯坦福大学以人为本 AI 研究员发布,代表着每年 AI 领域最核心和前沿的动向总结。
今年,这份报告长达 456 页,抛出不少惊人观点。

比如,如今在 2025 年,中美顶级 AI 模型的性能差距已经缩小到了 0.3%(2023 年,这一数字还是 20%),中国模型正在快速追赶美国的领先地位!
而 DeepSeek 领衔的开放权重模型,更是以 1.7% 之差,逼宫各大闭源巨头。前者和后者的差距,已经由 2024 年的 8%,缩小至 2025 年的 1.7%。
当然,目前从行业主导企业来看,美国仍然领先于中国。在 2024 年,90% 的知名 AI 模型来自企业,美国以 40 个模型领先,中国有 15 个。
更明显的一个趋势,就是如今大模型的性能已经趋同!在 2024 年,TOP1 和 TOP10 的模型的差距能有 12%,但如今,它们的差距已经越来越小,锐减至 5%。


十二大亮点
最新的斯坦福 HAI 两篇博文中,浓缩了 2025 年 AI 指数报告的十二大亮点。
- AI 性能再攀高峰,从基准测试到视频生成全面突破
2023 年,研究人员推出了 MMMU、GPQA 和 SWE-bench 等新基准来测试先进 AI 系统的极限。
仅一年后,性能便大幅提升:AI 在三项基准得分分别飙升 18.8%、48.9% 和 67.3%。
不仅如此,AI 在生成高质量视频方面取得重大突破,甚至,在某些场景下 AI 智能体甚至超越人类表现。

· 更有用智能体崛起
2024 年发布的 RE-Bench 基准测试,为评估 AI 智能体复杂任务能力设立了严苛标准。
数据显示:在短期任务(2 小时内)场景下,顶级 AI 系统的表现可达人类专家的 4 倍;但当任务时限延长至 32 小时,人类则以 2:1 的优势反超。
值得注意的是,AI 已在特定领域,如编写特定类型代码,展现出与人类相当的专业水平,且执行效率更胜一筹。

2. 美国领跑顶尖模型研发,但中国与之差距逐渐缩小
2024 年,美国产出 40 个重要 AI 模型,远超中国的 15 个和欧洲的 3 个。
然而,中国模型在性能上的差距正加速缩小:MMLU 等基准测试中,中美 AI 差异从两位数缩小至近乎持平。
同时,中国在 AI 学术论文和专利申请量上持续领跑,中东、拉美和东南亚地区也涌现出具有竞争力的模型。

3. AI 正变得高效且普惠,推理成本暴降 280 倍
随着小模型性能提升,达到 GPT-3.5 水平的推理成本在两年间下降 280 倍,硬件成本以每年 30% 的速度递减,能效年提升率达 40%。
更令人振奋的是,开源模型性能突飞猛进,部分基准测试中与闭源模型的差距从 8% 缩至 1.7%。
· 大模型使用成本持续走低**,年降幅最高 900 倍**
在 MMLU 基准测试中达到 GPT-3.5 水平(MMLU 准确率 64.8%)的 AI 模型调用成本,已从 2022 年 11 月的 20 美元 / 每百万 token,骤降至 2024 年 10 月的 0.07 美元 / 每百万 token(谷歌 DeepMind 的 Gemini-1.5-Flash-8B 模型),18 个月内 AI 成本下降 280 倍。
视具体任务需求,LLM 推理服务价格的年降幅可达 9-900 倍不等。

· 小模型性能显著提升**,参数暴减 142 倍**
2022 年,在大规模多任务语言理解(MMLU)基准测试中,得分超 60% 的最小模型是 PaLM,参数量为 5400 亿。
到了 2024 年,微软 Phi-3-mini 仅用 38 亿参数,就取得了同样的实力。
这代表,两年多的时间里模型参数减少了 142 倍。

4. 科技巨头称霸 AI 前沿,但竞争白热化
2024 年,近 90% 的重要模型源自企业,学术界则保持基础研究优势。
模型规模呈指数增长:训练算力每 5 个月翻番,数据集每 8 个月扩容一倍。
值得注意的是,头部模型性能差距显著缩小,榜首与第十名得分差已从 11.9% 降至 5.4%。

5. AI 逻辑短板,推理能力仍是瓶颈
采用符号推理方法的 AI 系统,能较好解决 IMO 问题(虽未达人类顶尖水平),但 LLM 在 MMMU 等复杂推理任务中表现欠佳,尤其不擅长算术推导和规划类强逻辑性任务。
这一局限影响了其在医疗诊断等高风险场景的应用可靠性。

6. 大厂 ALL in AI,投资与采用率创双纪录
科技大厂们,正全力押注 AI。
2024 年,美国私营 AI 投资达 1091 亿美元,约为中国(93 亿)的 12 倍、英国(45 亿)的 24 倍。
生成式 AI 势头尤猛,全球私募投资达 339 亿美元(同比增 18.7%)。
与此同时,企业 AI 采用率从 55% 升至 78%。研究证实,AI 不仅能提升生产力,多数情况下还可缩小劳动力技能差距。
更引人注目的是,将生成式 AI 应用于至少一项业务职能的企业数量激增------从 2023 年的 33% 跃升至去年的 71%,增幅超一倍。

7. AI 荣膺科学界最高荣誉,摘诺奖桂冠
2024 年,两项诺贝尔奖分别授予深度学习理论基础(物理学)和蛋白质折叠预测(化学)研究,图灵奖则花落强化学习领域。
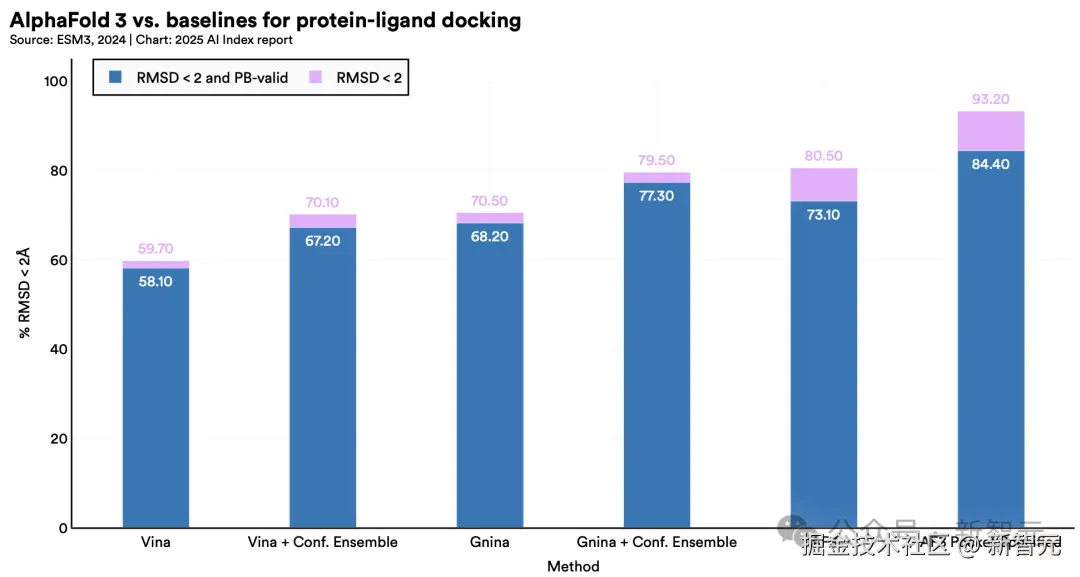
8. AI 教育普及加速,但资源差距仍存
全球 2/3 国家已或计划开展 K-12 计算机科学教育,但非洲地区受限于电力等基础设施,推进缓慢。
美国 81% 的计算机教师认为 AI 应纳入基础课程,但仅 47% 具备相应教学能力。
9. AI 正深度融入日常生活
从医疗到交通,AI 正快速从实验室走向现实。
1995 年,FDA 批准了第一款 AI 赋能的医疗器械。
截至 2024 年 8 月,FDA 已批准 950 款 AI 医疗设备------较 2015 年的 6 款和 2023 年的 221 款,增长迅猛。
而在自动驾驶领域,汽车已脱离实验阶段:美国头部运营商 Waymo 每周提供超 15 万次无人驾驶服务。

10. 全球 AI 乐观情绪上升,但地区差异显著
中国(83%)、印尼(80%)和泰国(77%)民众对 AI 持积极态度,而加拿大(40%)、美国(39%)等发达国家则相对保守。
值得关注的是,德国(+10%)、法国(+10%)等原怀疑论国家态度明显转变。


11. 负责任 AI 生态发展不均
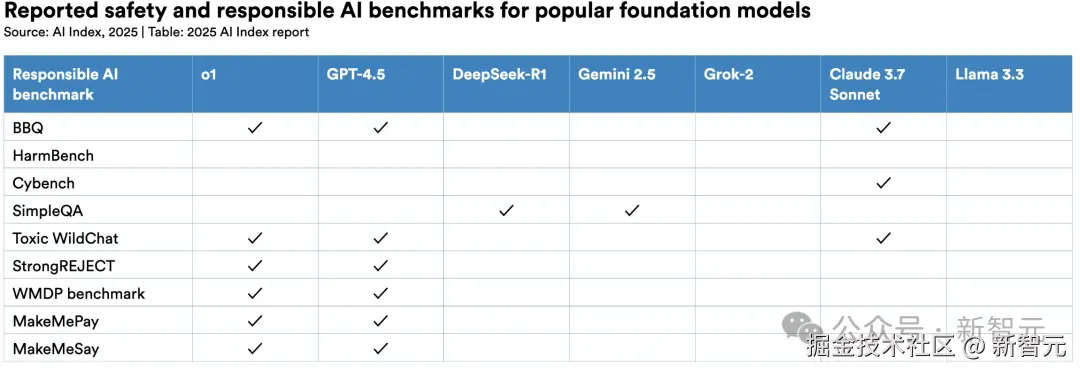
虽然 AI 安全事件激增,但主流模型开发商仍缺乏标准化评估体系。
HELM Safety、AIR-Bench 和 FACTS 等新基准为事实性与安全性评估提供工具。
企业普遍存在「认知与行动脱节」,而各国政府加速协作:2024 年,经合组织、欧盟等国际机构相继发布聚焦透明度、可信度的治理框架。
· 问题 AI 数量跃升
根据权威 AI 危害追踪数据库「AI 事件库」(AI Incidents Database)统计,2024 年全球 AI 相关危害事件激增至 233 起,创下历史新高,较 2023 年暴涨 56.4%。
其中既包括深度伪造私密图像案件,也涉及聊天机器人疑似导致青少年自杀等恶性事件。
尽管该统计未能涵盖全部案例,但已清晰揭示 AI 技术滥用正在呈现惊人增长态势。

12. 全球监管力度持续加强
2024 年美国联邦机构颁布 59 项 AI 法规,涉及部门数量翻倍。
75 个国家立法机构提及 AI 频次同比增长 21.3%,较 2016 年增长九倍。
投资方面:加拿大承诺 24 亿美元,中国设立 475 亿美元半导体基金,法国投入 1090 亿欧元,印度拨款 12.5 亿美元,沙特启动千亿美元级的「超越计划」。

详细亮点解读
下面,我们将摘出报告中的亮点内容,提供更详细的解读。
中美差距仅剩 0.3%
翻开 502 页的报告,最吸睛的部分,莫过于中美 AI 差异这部分了。


报告中强调,虽然 2024 年,美国在顶尖 AI 模型的研发上依然领先,但中美模型之间的性能差距,正在迅速缩小!
为了衡量 AI 领域过去一年演变的全球格局,HAI 特意用 AI 指数,列出了具有代表性的模型所属国家,美国依然居首。
数据显示,在 2024 年,美国机构以拥有 40 个知名模型领先,远远超过中国的 15 个和欧洲的 3 个。

总体来说,模型发布总量已经下降,可能是多个因素共同导致的,比如训练规模日益庞大、AI 技术日益复杂,开发新模型方法的难度也在增加。
AI 模型已成为算力巨兽

· 参数趋势
简单的说,参数就是 AI 模型通过训练学到的一些数字,这些数字决定了模型如何理解输入和怎样输出。
AI 的参数越多需要的训练数据也越多,但同时性能也更厉害。
从 2010 年代初开始,模型的参数量就蹭蹭往上涨,这背后是因为模型设计得越来越复杂、数据更容易获取、硬件算力也更强了。
更重要的是,大模型确实效果好。
下图用了对数刻度,方便大家看清楚 AI 模型参数和算力近年来的爆炸式增长。

随着模型参数数量的增加,训练所需的数据量也在暴涨。
2017 年发布的 Transformer 模型,掀起了大型语言模型的热潮,当时它用了大约 20 亿个 token 来训练。
到了 2020 年,GPT-3 175B 模型的训练数据已经飙到了约 3740 亿个 token。
而 Meta 在 2024 年夏天发布的模型 Llama 3.3,更是用了大约 15 万亿个 token 来训练。
根据 Epoch AI 的数据,大型语言模型的训练数据集规模大约每八个月翻一倍。

训练数据集越来越大,导致的训练时间也变得越来越长。
像 Llama 3.1-405B 这样的模型,训练大概需要 90 天,这在如今已经算是「正常」的了。
谷歌在 2023 年底发布的 Gemini 1.0 Ultra,训练时间大约是 100 天。
相比之下,2012 年的 AlexNet 就显得快多了,训练只花了五六天,而且 AlexNet 当时用的硬件还远没有现在的先进。

· 算力趋势
「算力」指的是训练和运行 AI 模型所需的计算资源。
最近,知名 AI 模型的算力消耗呈指数级增长。据 Epoch AI 估计,知名 AI 模型的训练算力大约每五个月翻一番。
这种趋势在过去五年尤为明显。

去年 12 月,DeepSeek V3 一经推出就引发了广泛关注,主要就是因为它在性能上极其出色,但用的计算资源却比许多顶尖大型语言模型少得多。
下图 1.3.17 比较了中国和美国知名 AI 模型的训练算力,揭示了一个重要趋势:美国的顶级 AI 模型通常比中国模型需要多得多的计算资源。

· 推理成本
推理成本,指的是对一个已训练模型进行查询所需的费用,通常以「每百万 tokens 的美元价格」来衡量。
这份报告中 AI token 的价格数据,来源于 Artificial Analysis 和 Epoch AI 的 API 定价专有数据库,而价格是根据输入与输出 token 的价格按 3:1 的权重平均计算得出的。
可以看出,单位性能的 AI 成本正在显著下降。
而 Epoch AI 估计,根据不同任务类型,大型语言模型的推理成本每年下降幅度可达 9 倍至 900 倍不等。
虽然如此,想要获得来自 OpenAI、Meta 和 Anthropic 的模型,仍需支付不小的溢价。

· 训练成本
虽然很少有 AI 公司披露具体的训练成本,但这个数字普遍已达到数百位美元。
OpenAI CEO 奥特曼曾表示,训练 GPT-4 的训练成本超过了 1 亿美元。
Anthropic 的 CEO Dario Amodei 指出,目前正在训练的模型,成本约为 10 亿美元。
DeepSeek-V3 的 600 万美元,则打破了新低。

图 1.3.24 展示了基于云计算租赁价格的部分 AI 模型的训练成本估算。

图 1.3.25 展示了 AI 指数所估算的所有 AI 模型的训练成本。

在 2024 年,Epoch 能估算的少数模型之一,就是 Llama 3.1-405B,训练成本约为 1.7 亿美元。
另外,AI 模型的训练成本与其计算需求之间存在直接的关联。如图 1.3.26 所示,计算需求更大的模型训练成本显著更高。

参考资料:YZNH