在huggingface上制作小demo
今天好兄弟让我帮他搞一个模型,他有小样本的化学数据,想让我根据这些数据训练一个小模型,他想用这个模型预测一些值
最终我简单训练了一个小模型,起初想把这个模型和GUI界面打包成exe发给他,但是发现打包后3.9GB,太大了吧!!!后来我又找了别的方案,即将训练好的模型以及相关代码、环境配置文件上传到huggingface上,通过hf的界面端直接使用这个模型,接下来我回顾一下整个流程
1.训练模型并写一个简单的GUI
训练数据
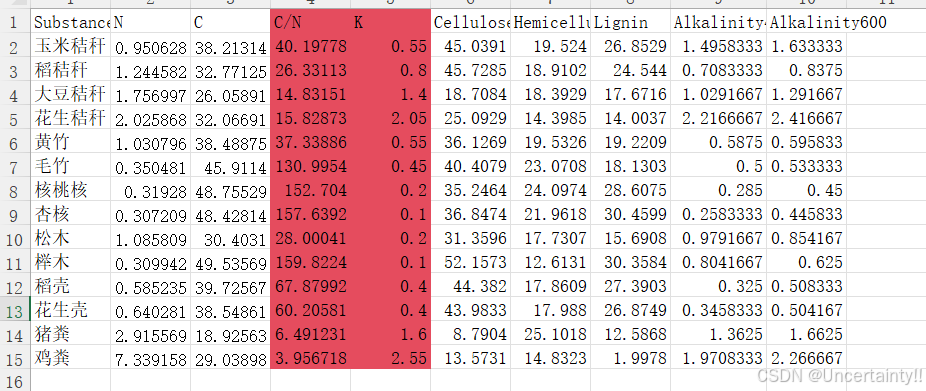
模型输入值:substance、N、C、C/N、K、Cellulose、Hemicellulose、Lignin
模型输出值:Alkaliniy400、Alkalinity600
由于样本较小,为了减小误差,这里采用5折交叉验证
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import joblib
# 定义神经网络模型
class AlkalinityNet(nn.Module):
def __init__(self, input_dim):
super(AlkalinityNet, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 32),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(32, 2) # 输出两个值:400℃ 和 600℃ 碱度
)
def forward(self, x):
return self.model(x)
def train_model(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for X_batch, y_batch in train_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item() * X_batch.size(0)
return running_loss
def evaluate_model(model, val_loader, criterion, device):
model.eval()
running_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in val_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
running_loss += loss.item() * X_batch.size(0)
return running_loss
def main():
# 读取 Excel 数据
data = pd.read_excel('~/PycharmProjects/Alkalinity/datasets/data.xlsx')
# 假设第一列为物质名称,列名为 "Substance"
# 数值特征
num_features = ["N", "C", "C/N", "K", "Cellulose", "Hemicellulose", "Lignin"]
targets = ["Alkalinity400", "Alkalinity600"]
# 提取物质类别和数值特征
substances = data["Substance"].values.reshape(-1, 1)
X_num = data[num_features].values
y = data[targets].values.astype(np.float32)
# 对物质类别使用 OneHotEncoder 编码
encoder = OneHotEncoder(sparse_output=False, handle_unknown='ignore')
X_cat = encoder.fit_transform(substances)
joblib.dump(encoder, 'encoder.pkl')
# 对数值特征进行标准化
scaler_X = StandardScaler()
X_num_scaled = scaler_X.fit_transform(X_num)
joblib.dump(scaler_X, 'scaler_X.pkl')
# 拼接类别特征和数值特征
X_combined = np.hstack([X_cat, X_num_scaled]).astype(np.float32)
# 对目标值进行标准化
scaler_y = StandardScaler()
y_scaled = scaler_y.fit_transform(y)
joblib.dump(scaler_y, 'scaler_y.pkl')
# 转换为 PyTorch tensor
X_tensor = torch.from_numpy(X_combined)
y_tensor = torch.from_numpy(y_scaled)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 交叉验证设置
kf = KFold(n_splits=5, shuffle=True, random_state=42)
num_epochs = 100
batch_size = 8
criterion = nn.MSELoss()
fold_losses = []
print("开始 5 折交叉验证...")
for fold, (train_index, val_index) in enumerate(kf.split(X_tensor), 1):
X_train, X_val = X_tensor[train_index], X_tensor[val_index]
y_train, y_val = y_tensor[train_index], y_tensor[val_index]
train_dataset = TensorDataset(X_train, y_train)
val_dataset = TensorDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
model = AlkalinityNet(input_dim=X_tensor.shape[1]).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
train_loss = train_model(model, train_loader, criterion, optimizer, device)
val_loss = evaluate_model(model, val_loader, criterion, device)
# 这里可以打印每折每轮的损失,也可以选择每隔一定轮数打印一次
# print(f"Fold {fold}, Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss/len(train_dataset):.4f}, Val Loss: {val_loss/len(val_dataset):.4f}")
avg_val_loss = val_loss / len(val_dataset)
print(f"第 {fold} 折验证 Loss: {avg_val_loss:.4f}")
fold_losses.append(avg_val_loss)
print("5 折交叉验证平均 Loss:", np.mean(fold_losses))
# 在全数据集上训练最终模型
final_dataset = TensorDataset(X_tensor, y_tensor)
final_loader = DataLoader(final_dataset, batch_size=batch_size, shuffle=True)
final_model = AlkalinityNet(input_dim=X_tensor.shape[1]).to(device)
optimizer = optim.Adam(final_model.parameters(), lr=0.001)
print("开始在全数据集上训练最终模型...")
for epoch in range(num_epochs):
train_loss = train_model(final_model, final_loader, criterion, optimizer, device)
# 可打印训练进度
# print(f"Epoch {epoch+1}/{num_epochs}, Loss: {train_loss/len(final_dataset):.4f}")
# 保存最终模型参数
torch.save(final_model.state_dict(), 'final_model.pth')
print("最终模型已保存到 final_model.pth")
if __name__ == '__main__':
main()
python
import numpy as np
import torch
import torch.nn as nn
import joblib
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# 定义与训练时相同的网络结构
class AlkalinityNet(nn.Module):
def __init__(self, input_dim):
super(AlkalinityNet, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 32),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(32, 2)
)
def forward(self, x):
return self.model(x)
def predict_alkalinity(input_data):
"""
参数 input_data 为字典,包含以下键值:
"Substance": 物质名称,例如 "玉米秸秆"
"N", "C", "C/N", "K", "Cellulose", "Hemicellulose", "Lignin"
返回预测的 [400℃ 碱度, 600℃ 碱度]
"""
# 数值特征顺序与训练时一致
num_features = ["N", "C", "C/N", "K", "Cellulose", "Hemicellulose", "Lignin"]
# 提取物质名称与数值特征
substance = np.array([[input_data["Substance"]]])
X_num = np.array([input_data[feat] for feat in num_features]).reshape(1, -1).astype(np.float32)
# 加载保存的 OneHotEncoder 和 StandardScaler
encoder = joblib.load('encoder.pkl')
scaler_X = joblib.load('scaler_X.pkl')
scaler_y = joblib.load('scaler_y.pkl')
X_cat = encoder.transform(substance)
X_num_scaled = scaler_X.transform(X_num)
# 拼接类别特征和数值特征
X_combined = np.hstack([X_cat, X_num_scaled]).astype(np.float32)
# 转换为 tensor
X_tensor = torch.from_numpy(X_combined)
# 加载模型,注意输入维度需与训练时保持一致
input_dim = X_combined.shape[1]
model = AlkalinityNet(input_dim=input_dim)
# 加载模型参数
model.load_state_dict(torch.load('final_model.pth', map_location=torch.device('cpu'), weights_only=True))
model.eval()
with torch.no_grad():
y_pred_tensor = model(X_tensor)
y_pred_scaled = y_pred_tensor.numpy()
# 将预测结果反标准化
y_pred = scaler_y.inverse_transform(y_pred_scaled)
return y_pred[0]
if __name__ == '__main__':
# 示例输入,请根据实际物质成分调整数值
input_data = {
"Substance": "鸡粪",
"N": 1.0,
"C": 40.0,
"C/N": 40.0,
"K": 2.5,
"Cellulose": 29.0,
"Hemicellulose": 25.0,
"Lignin": 12.0
}
result = predict_alkalinity(input_data)
print("预测 400℃ 碱度:", result[0])
print("预测 600℃ 碱度:", result[1])本地推理看看

python
import tkinter as tk
from tkinter import messagebox
import tkinter.font as tkFont
import joblib
import numpy as np
import torch
import torch.nn as nn
# 定义与训练时一致的模型结构
class AlkalinityNet(nn.Module):
def __init__(self, input_dim):
super(AlkalinityNet, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 32),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(32, 2) # 输出 400℃ 和 600℃ 的碱度值
)
def forward(self, x):
return self.model(x)
def predict():
try:
# 获取用户输入的各项数值
substance = entry_substance.get()
N = float(entry_N.get())
C = float(entry_C.get())
C_N = float(entry_CN.get())
K = float(entry_K.get())
cellulose = float(entry_cellulose.get())
hemicellulose = float(entry_hemicellulose.get())
lignin = float(entry_lignin.get())
except ValueError:
messagebox.showerror("输入错误", "请确保所有数值项均正确填写")
return
# 构造输入字典
input_data = {
"Substance": substance,
"N": N,
"C": C,
"C/N": C_N,
"K": K,
"Cellulose": cellulose,
"Hemicellulose": hemicellulose,
"Lignin": lignin
}
try:
# 加载保存的预处理器
encoder = joblib.load('encoder.pkl')
scaler_X = joblib.load('scaler_X.pkl')
scaler_y = joblib.load('scaler_y.pkl')
except Exception as e:
messagebox.showerror("加载错误", f"加载预处理器失败:{e}")
return
# 对物质类别特征进行 one-hot 编码
substance_arr = np.array([[input_data["Substance"]]])
X_cat = encoder.transform(substance_arr)
# 数值特征转换与标准化
X_num = np.array([[input_data["N"], input_data["C"], input_data["C/N"], input_data["K"],
input_data["Cellulose"], input_data["Hemicellulose"], input_data["Lignin"]]], dtype=np.float32)
X_num_scaled = scaler_X.transform(X_num)
# 拼接特征
X_combined = np.hstack([X_cat, X_num_scaled]).astype(np.float32)
X_tensor = torch.from_numpy(X_combined)
# 加载模型(注意:模型参数文件和输入预处理器需放在同一目录下)
input_dim = X_combined.shape[1]
model = AlkalinityNet(input_dim=input_dim)
try:
model.load_state_dict(torch.load('final_model.pth', map_location=torch.device('cpu'), weights_only=True))
except Exception as e:
messagebox.showerror("加载模型错误", f"加载模型失败:{e}")
return
model.eval()
with torch.no_grad():
y_pred_tensor = model(X_tensor)
y_pred_scaled = y_pred_tensor.numpy()
# 反标准化得到预测值
y_pred = scaler_y.inverse_transform(y_pred_scaled)
pred_400 = y_pred[0, 0]
pred_600 = y_pred[0, 1]
# 在界面上显示预测结果
label_pred_400.config(text=str(pred_400))
label_pred_600.config(text=str(pred_600))
# 创建 GUI 主窗口
root = tk.Tk()
root.title("碱度预测模型")
# 设置参考尺寸与基础字体大小(可根据需要调整)
REF_WIDTH = 800
REF_HEIGHT = 600
BASE_FONT_SIZE = 18
# 用于存放所有需要动态调整字体的控件
widgets_to_update = []
# 创建一个默认字体对象,初始大小 BASE_FONT_SIZE
default_font = tkFont.Font(family="SimSun", size=BASE_FONT_SIZE)
# 辅助函数:创建标签并加入更新列表(居中显示)
def create_label(text, row, col):
lbl = tk.Label(root, text=text, font=default_font, anchor="center")
lbl.grid(row=row, column=col, padx=5, pady=5, sticky="nsew")
widgets_to_update.append(lbl)
return lbl
# 辅助函数:创建输入框并加入更新列表(内容居中)
def create_entry(row, col):
ent = tk.Entry(root, font=default_font, justify="center")
ent.grid(row=row, column=col, padx=5, pady=5, sticky="nsew")
widgets_to_update.append(ent)
return ent
# 定义行列权重,使控件居中扩展
for i in range(11):
root.grid_rowconfigure(i, weight=1)
for j in range(2):
root.grid_columnconfigure(j, weight=1)
# 创建左侧标签
label_substance = create_label("物质", 0, 0)
label_N = create_label("N", 1, 0)
label_C = create_label("C", 2, 0)
label_CN = create_label("C/N", 3, 0)
label_K = create_label("K", 4, 0)
label_cellulose = create_label("纤维素", 5, 0)
label_hemicellulose = create_label("半纤维素", 6, 0)
label_lignin = create_label("木质素", 7, 0)
label_400 = create_label("400摄氏度碱度", 8, 0)
label_600 = create_label("600摄氏度碱度", 9, 0)
# 创建右侧输入框
entry_substance = create_entry(0, 1)
entry_N = create_entry(1, 1)
entry_C = create_entry(2, 1)
entry_CN = create_entry(3, 1)
entry_K = create_entry(4, 1)
entry_cellulose = create_entry(5, 1)
entry_hemicellulose = create_entry(6, 1)
entry_lignin = create_entry(7, 1)
# 用于显示预测结果的标签(400℃ 和 600℃)
label_pred_400 = create_label("未预测", 8, 1)
label_pred_600 = create_label("未预测", 9, 1)
# 预测按钮(也加入更新列表)
predict_button = tk.Button(root, text="预测", font=default_font, command=predict)
predict_button.grid(row=10, column=0, columnspan=2, pady=10)
widgets_to_update.append(predict_button)
# 定义一个函数,在窗口大小变化时更新所有控件的字体大小
def on_resize(event):
# 根据窗口当前尺寸与参考尺寸计算缩放比例
scale_factor = min(event.width / REF_WIDTH, event.height / REF_HEIGHT)
new_font_size = max(int(BASE_FONT_SIZE * scale_factor), 8) # 设置最小字体为8
# 更新所有控件字体
new_font = (default_font.actual("family"), new_font_size)
for widget in widgets_to_update:
widget.config(font=new_font)
# 绑定窗口尺寸变化事件
root.bind("<Configure>", on_resize)
root.mainloop()本地运行看看效果
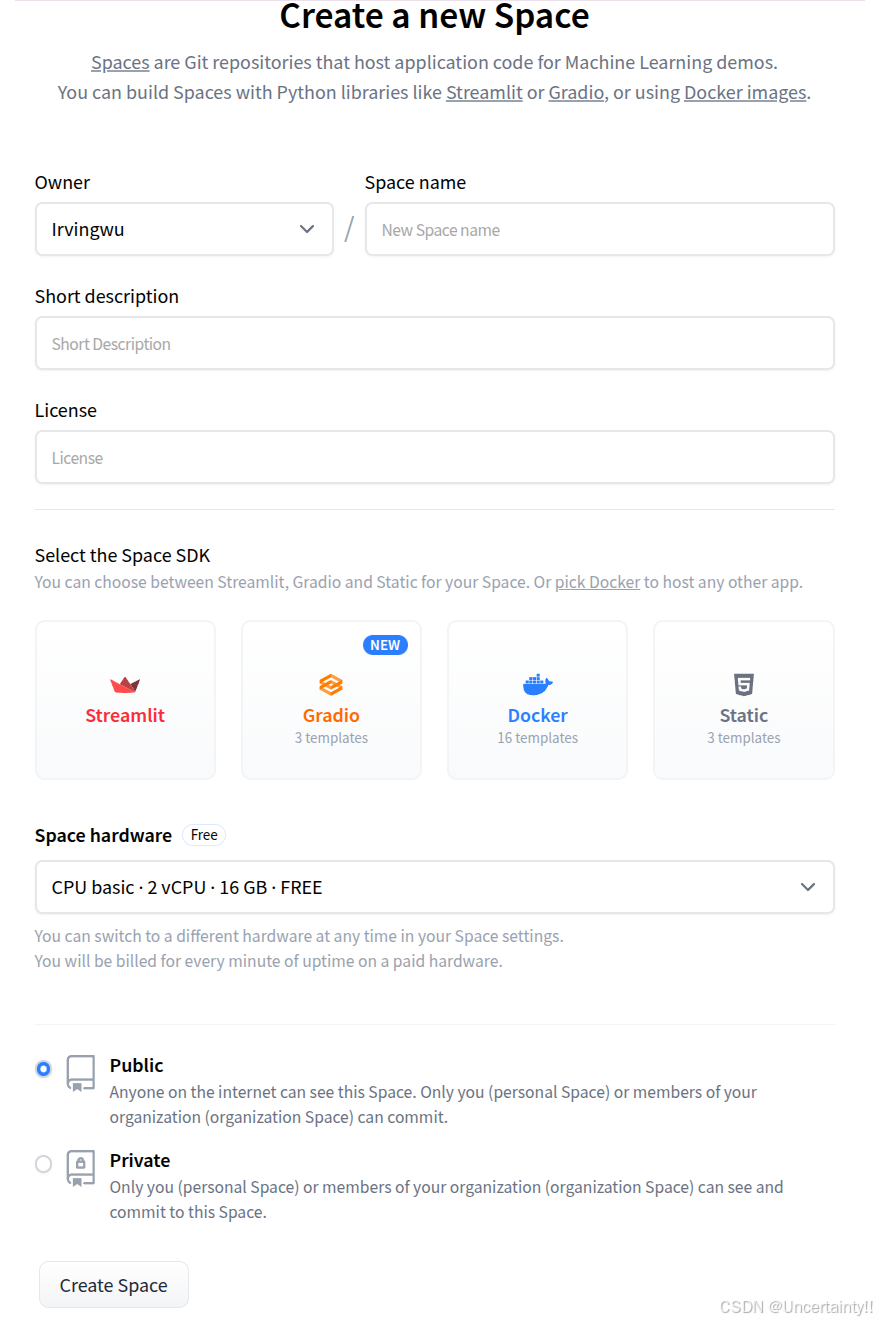
2.在huggingface上创建Space
点击new space

填写相关信息后点击Create
3.上传模型、代码、环境配置文件
上传你的模型和相应代码、以及requirements.txt
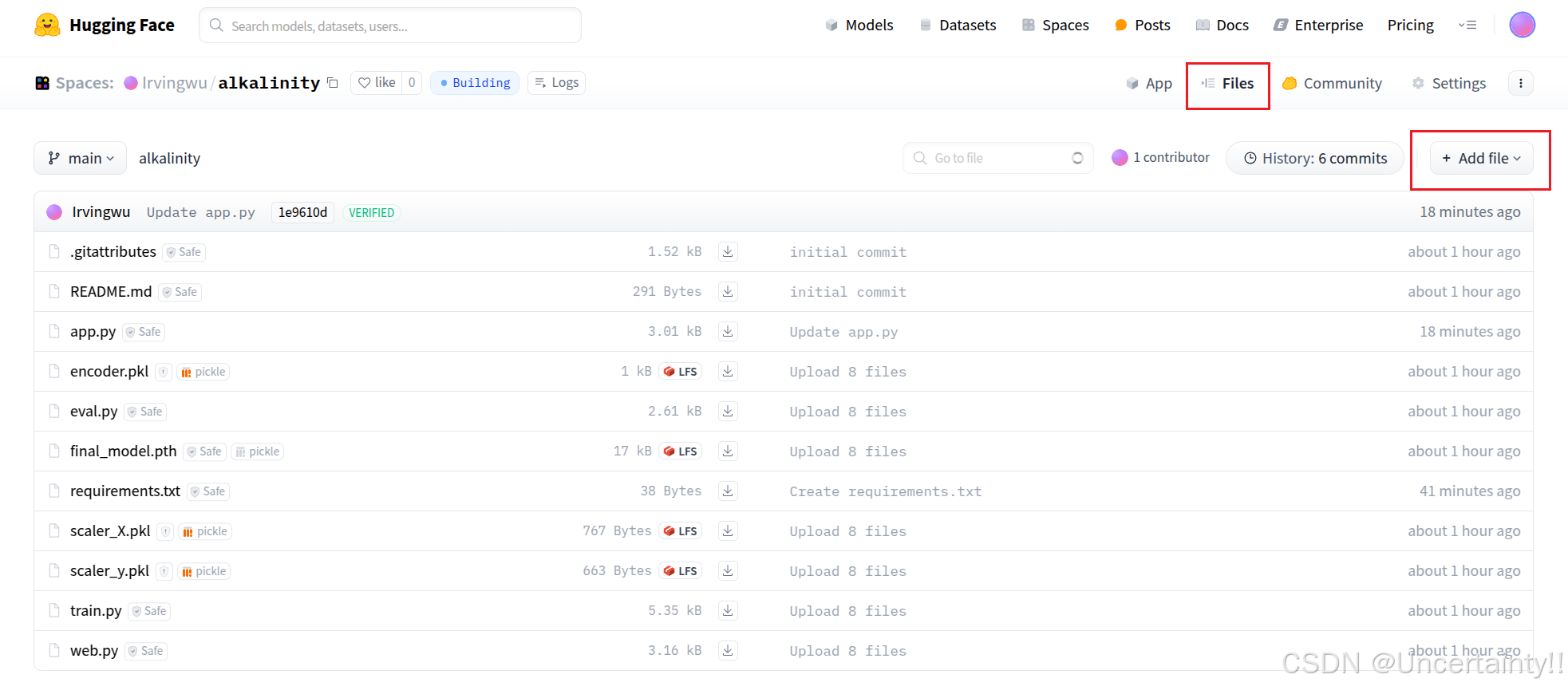 requirements.txt中直接写需要用到的库
requirements.txt中直接写需要用到的库

上传文件中需要有个名为 app.py的文件,huggingface会根据这个文件创建网页端应用
为了能够让hf分享别人可以访问的public链接,在app.py中添加参数share=True
python
# Launch the app with shareable link
if __name__ == "__main__":
iface.launch(share=True)为了不让模型自动推理运行,而是让它点击运行时才推理,我们需要将app.py中 live=True设置为False
python
# Create Gradio interface
iface = gr.Interface(
fn=predict,
inputs=[
gr.Textbox(label="Substance", placeholder="Enter substance"),
gr.Number(label="N"),
gr.Number(label="C"),
gr.Number(label="C/N"),
gr.Number(label="K"),
gr.Number(label="Cellulose"),
gr.Number(label="Hemicellulose"),
gr.Number(label="Lignin")
],
outputs=[
gr.Number(label="400℃ Alkalinity"),
gr.Number(label="600℃ Alkalinity")
],
live=False, # Disable live prediction to avoid automatic prediction
title="Alkalinity Prediction Model",
description="Input relevant data and click the 'Predict' button to get predictions."
)hf会根据环境配置文件下载相关库并根据app.py创建应用
 这样就可以在网页端直接使用模型
这样就可以在网页端直接使用模型
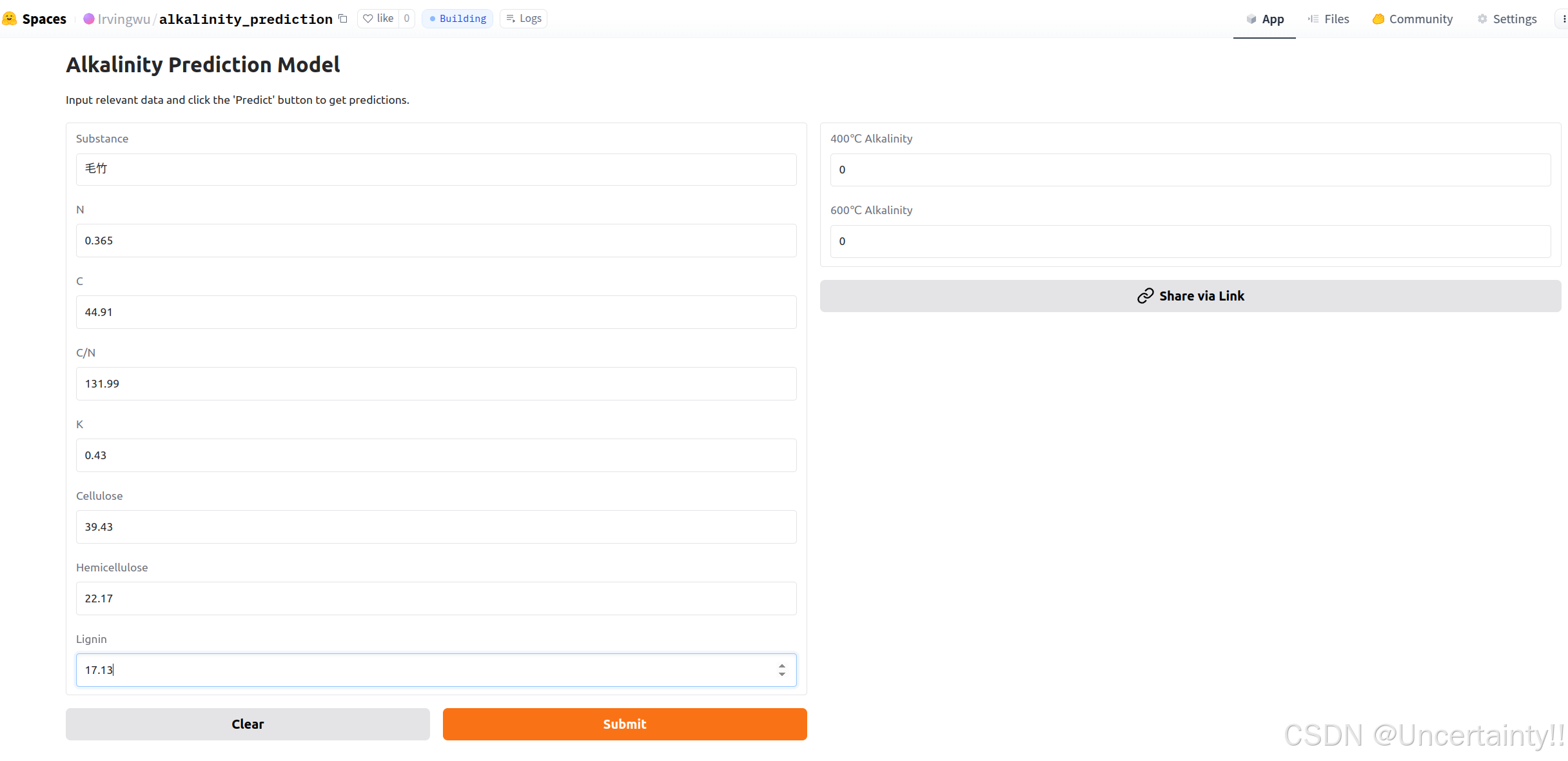 将左侧输入值填入后,点击submit后模型输出值显示到右侧
将左侧输入值填入后,点击submit后模型输出值显示到右侧
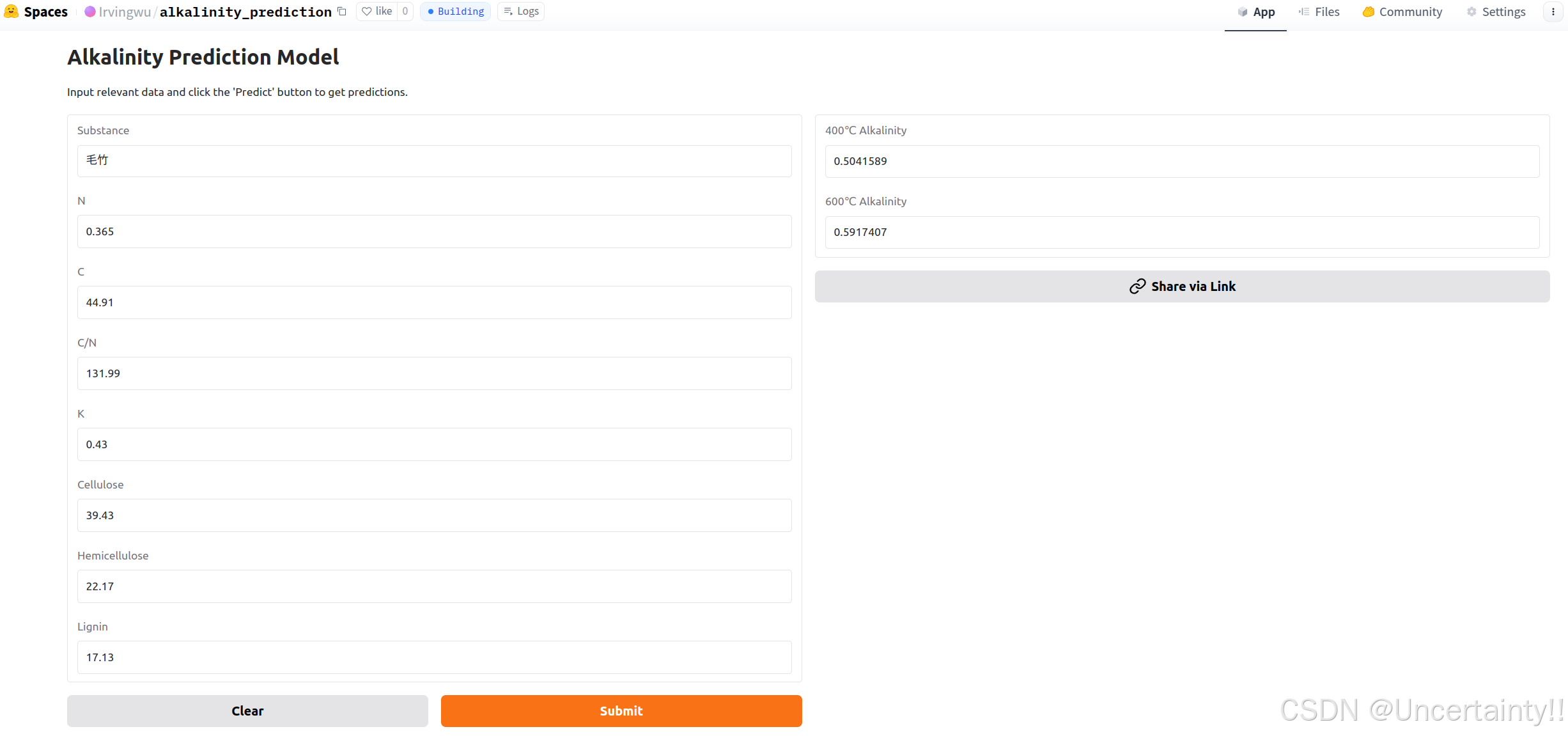
将分享链接分享给好兄弟后,他就可以直接在网页端使用我训练好的简单模型了