C/C++
编译运行过程
预处理(gcc -E,宏,头文件,注释,.i,ii),编译(-S,词法语法语义分析,.s),汇编(汇编代码转换成机器可执行的命令),链接(静态,将目标文件与静态库.a链接生成可执行文件;动态,只有库引用嵌入)
内存分段
代码段:可执行代码,只读的常量(某些编译器放到.rodata)
数据段:已初始化的全局变量,已初始化的静态变量
BSS:未初始化变量,未初始化的静态变量,自动初始化为0
堆:动态分配
栈:局部变量
程序的局部性原理
局部性原理(Locality Principle)是指程序在访问内存时,具有访问局部区域数据的倾向性。局部性原理可以大大提高缓存命中率,提高程序运行效率。
时间局部性:近期访问的数据或指令,在短时间内可能会被再次访问。
空间局部性:程序访问某个地址后,通常会访问其附近的地址。
管理资源生命周期的方法
手动管理:new,delete
RAII(Resource Acquisition Is Initialization):智能指针,vector,fstream,lock_guard和unique_lock
友元
在 C++ 中,friend 关键字用于允许非成员函数、外部函数或其他类访问私有(private)和受保护(protected)成员。这通常用于提高类的灵活性,但要谨慎使用,以免破坏封装性(Encapsulation)。
友元函数:
✅ 友元函数可以访问私有和受保护成员。
✅ 友元函数不是类的成员,因此不需要 this 指针。
✅ 友元函数可以是全局函数或其他类的成员函数。
友元类:
✅ 友元类的所有成员函数都可以访问目标类的私有成员。
✅ 友元关系是单向的,即 A 是 B 的友元类,但 B 不是 A 的友元。
✅ 友元类破坏了封装性,应谨慎使用。
友元类的成员函数:有时,我们不想把整个类设为友元,而只想让某个成员函数访问私有成员。
memcpy和memmove
memcpy 和 memmove 都是 C/C++ 标准库中的内存拷贝函数,用于在内存区域之间复制数据。
两者的主要区别在于是否支持重叠(overlapping)内存区域。

map,mutimap,unordered_map
map基于红黑树实现,有序,不重复,log(n);mutimap基于红黑树实现,有序,可重复log(n);unordered_map基于哈希表实现,无序,不重复,log(1)。
set,mutiset,unordered_set
set基于红黑树实现,有序,不重复,log(n);mutiset基于红黑树实现,有序,可重复log(n);unordered_set基于哈希表实现,无序,不重复,log(1)。
override与final
override 关键字用于显式标识一个虚函数是 重写(override)基类中的虚函数。它能够帮助编译器检查函数签名是否正确,确保我们确实是想要重写一个虚函数。如果重写的函数与基类的虚函数签名不匹配,编译器会给出错误提示。
final 关键字用于声明不允许进一步重写的虚函数或不允许继承的类。
- 当 final 用于虚函数时,表示该函数在当前类中是最终实现,无法在派生类中被重写。
- 当 final 用于类时,表示该类不能被继承。
explicit
防止构造函数隐式转换
C++11特性
权限
结构体默认为public,类默认为private,继承时同样。
static关键字
局部静态变量:局部静态变量是指在函数内部声明的静态变量。与普通局部变量不同,静态局部变量的生命周期持续到程序结束,而不是仅在函数调用期间存在。它们仅在第一次调用时初始化一次,之后保留其值。
全局静态变量:全局静态变量是指在函数外部声明的静态变量,它的作用域仅限于定义它的文件(翻译单元)。它不能在其他文件中访问。
静态函数:静态函数是指被 static 修饰的函数。它的作用域仅限于定义它的文件,不能在其他文件中调用。静态函数通常用于实现封装,防止其他文件直接调用。
静态数据成员:静态数据成员属于类而不是类的实例。它们对所有类的对象是共享的,因此静态数据成员的值是相同的。静态数据成员的声明通常放在类内,而定义通常放在类外。
静态成员函数:静态成员函数与静态数据成员类似,不依赖于类的任何实例,因此它们只能访问静态数据成员和其他静态成员函数,不能访问非静态成员。
操作系统
虚拟内存
虚拟内存为程序提供比实际物理内存更大的内存空间。虚拟内存就是把实际地址空间映射到虚拟地址空间的技术,这样就实现了内存隔离、内存扩展、物理内存管理、页面交换等技术。
分段与分页
分段:分段是一种将程序的内存分成多个逻辑段的内存管理方式。每个段通常代表程序的一个逻辑部分,如代码段、数据段(全局,静态)、BSS(未初始化变量)堆(动态分配)栈(局部变量)等。每个段都有一个段基址(段起始地址)和段长度(段的大小)。
分页:分页是一种将程序的内存分成固定大小的页面进行管理的方式。内存被划分为相同大小的页面,而物理内存被划分为相同大小的页框。分页的基本思想是将程序的虚拟地址空间映射到物理地址空间,页表查询。
用户态和内核态
用户态(User Mode)和内核态(Kernel Mode)是操作系统中最核心的概念之一,它们定义了程序运行的不同权限级别和资源访问范围。当程序需要执行特权操作(如读取文件、网络通信、内存分配)时,必须通过**系统调用(System Call)**进入内核态。
系统调用
系统调用是用户态程序与操作系统内核交互的接口,允许用户程序请求内核执行特权操作,如 文件操作、进程管理、网络通信、内存管理等。
中断,异常
中断和异常是两种不同的事件,二者都会导致CPU暂停当前的程序执行,转而去执行特定的处理程序。中断一般是由于外部设备或其他处理器导致的,一般是异步的,也就是说可以在任何时候发生,不会由当前的指令造成。比如键盘输入、鼠标输入、网络数据到达,来提醒CPU去处理这些事件。异常则是在当前CPU内部发生的,一般是同步的,由当前的指令造成。比如除数异常、访问非法内存地址、执行非法指令等,来提醒CPU去处理这些错误。
进程创建
fork,exec,clone
进程通信
管道:管道是一种半双工(只能一个方向传输)的通信机制,常用于父子进程之间的数据传输,通过内核提供的缓冲区进行。匿名管道仅用于亲缘进程间通信,命名管道可跨进程。
消息队列:消息队列是一个链表形式的消息集合,存储在内核中,由消息队列标识符引用。
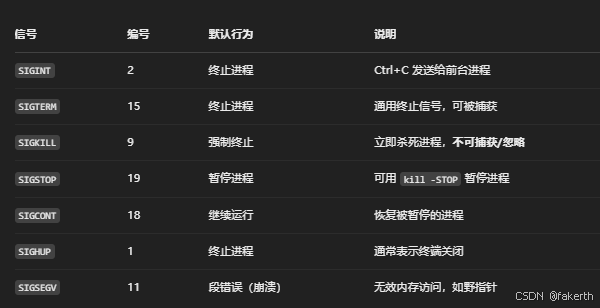
信号:信号是一种异步通知机制,用于通知进程发生了某个事件。
共享内存: 共享内存是一段可以被多个进程访问的内存区域。本质上是让不同进程"看到"同一块物理内存,是最快的进程间通信方式之一(零拷贝,直接读写),通常与信号量或互斥机制配合使用,确保同步与互斥;
信号量:信号量是一个"计数器",用于控制多个进程或线程对共享资源的访问。
套接字:套接字是操作系统提供的通信接口,用于不同主机之间、同一主机内的不同进程之间进行数据交换。它就像数据传输的"网关",允许应用程序发送和接收数据。
进程调度
进程调度是操作系统中管理进程执行的关键机制,它决定了多个进程在 CPU 上执行的顺序。操作系统通过调度算法来分配 CPU 时间,使得系统能够合理、有效地利用 CPU 资源,提高系统的吞吐量和响应时间。
调度过程分为几个主要的阶段:
-
进程创建:当新进程创建时,它会被放入就绪队列中。
-
进程选择:操作系统的调度程序从就绪队列中选择一个进程进行调度。
-
进程执行:被选择的进程开始执行。
-
进程状态变更:
-
就绪状态:进程已就绪,等待 CPU 执行。
-
运行状态:进程正在执行。
-
阻塞状态:进程因等待某些事件(如 I/O)而被挂起。
-
-
进程切换:当当前运行的进程时间片耗尽或需要等待 I/O 时,操作系统会进行进程切换,将 CPU 交给下一个就绪的进程。
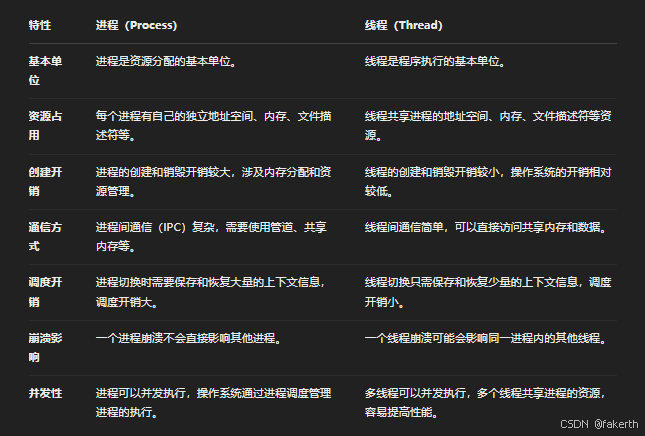
进程与线程区别
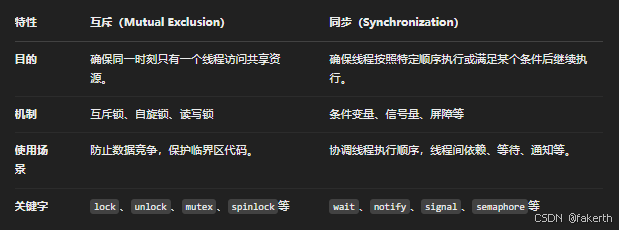
互斥和同步
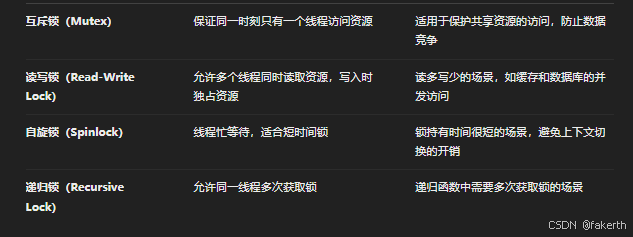
锁
锁(Lock)是并发编程中的一种基本机制,用于控制对共享资源的访问,以避免多个线程或进程在并发执行时发生竞争条件(Race Condition),确保数据的一致性和完整性。锁的本质是保证在同一时刻,只有一个线程能够访问临界区中的共享资源。
孤儿进程和僵尸进程

LD_PRELOAD
用户可以强制在程序启动时加载指定的共享库,优先于程序默认的库
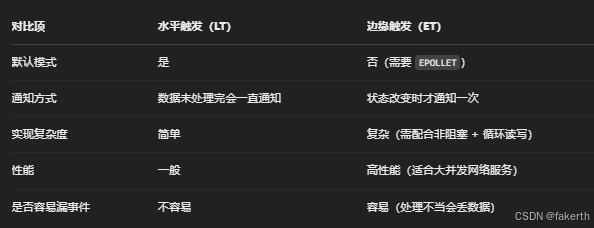
I/O多路复用
一个单一的线程或进程中同时监视多个文件描述符(如套接字、文件、管道等),以确定这些文件描述符中的哪些已经准备好进行I/O操作(如读、写、或发生异常)。比如一个服务器程序,它需要处理多个客户端的网络请求。每个客户端连接到服务器的一个套接字。可以用多路复用技术(如 epoll)来"监视"所有这些套接字。为每个请求分配一个进程/线程的方式不合适,所以使用一个进程来维护多个 Socket。进程可以通过一个系统调用函数(select、poll、epoll)从内核中获取多个事件。
select 和 poll 都是内核通过轮询(遍历)的方式来检查多个文件描述符是否有 I/O 操作就绪(如可读、可写、异常情况等)。poll 没有文件描述符数量的限制,因为它采用的是动态数组的方式来存储文件描述符和事件。epoll 使用事件通知机制,一旦某个文件描述符的状态发生变化,内核会将这个事件通知给 epoll,使得程序不需要反复轮询所有文件描述符。
epoll实现的数据结构是红黑树和双向链表,红黑树用于存储和管理所有被监视的文件描述符(文件描述符通常是 socket)。当你向 epoll 实例添加、删除或修改一个文件描述符时,epoll 会将这个文件描述符插入或移除红黑树中。红黑树是一种自平衡的二叉搜索树,确保了插入、删除和查找操作的时间复杂度为 O(log n),这使得 epoll 能够高效地管理大量的文件描述符。双向链表用于存储就绪事件(即有 I/O 操作准备好的文件描述符)。当某个文件描述符就绪时,它会被加入到这个双向链表中。双向链表的插入和删除操作非常高效,时间复杂度为 O(1),这对于 epoll 处理大量并发连接时的性能至关重要。
计算机网络
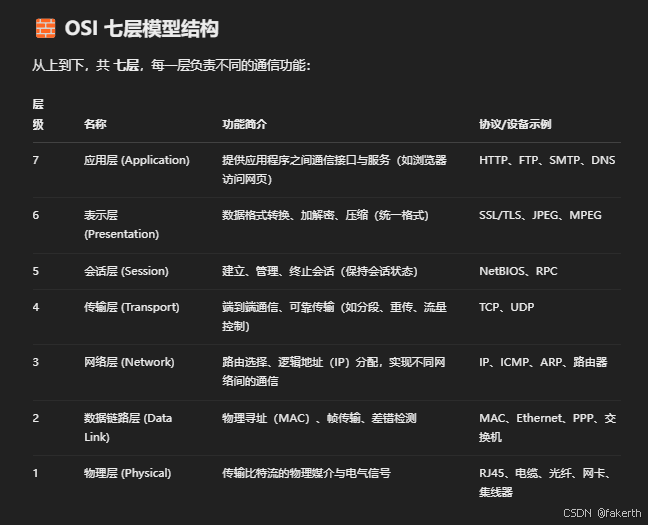
OSI参考模型
http状态码

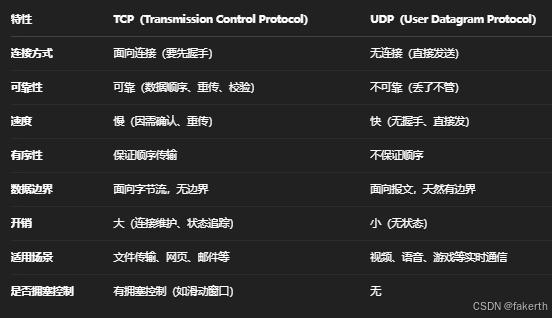
TCP与UDP
三次握手
bash
客户端 服务器
| ------ SYN(seq=x) --------> |
| |
| <--- SYN-ACK(seq=y, ack=x+1) ---|
| |
| ------ ACK(ack=y+1) --------> |
连接建立完成第一次握手:客户端 → 服务器
-
发送 SYN 报文,seq = x,进入 SYN_SENT 状态。
-
表示请求建立连接。
第二次握手:服务器 → 客户端
-
收到 SYN 后,发送 SYN+ACK 报文,seq = y, ack = x+1。
-
进入 SYN_RECV 状态,表示"我收到了你的请求,也准备好了"。
第三次握手:客户端 → 服务器
-
客户端收到 SYN+ACK,发送 ACK 报文,ack = y+1。
-
进入 ESTABLISHED 状态,服务器收到后也进入 ESTABLISHED 状态。
✅连接建立完成。
四次挥手
bash
客户端 服务器
| ------ FIN(seq=u) --------> |
| |
| <--------- ACK(ack=u+1) --------|
| |
| <------ FIN(seq=v) ------------ |
| |
| --------- ACK(ack=v+1) -------> |
连接关闭完成第一次挥手:客户端 → 服务器
-
客户端发送 FIN,表示不再发送数据了,但仍可接收数据。
-
进入 FIN_WAIT_1 状态。
第二次挥手:服务器 → 客户端
-
收到 FIN,回复 ACK,表示"知道了"。
-
进入 CLOSE_WAIT 状态。
第三次挥手:服务器 → 客户端
-
等待服务器把该发的数据发完后,发送 FIN。
-
进入 LAST_ACK 状态。
第四次挥手:客户端 → 服务器
-
客户端收到 FIN 后发送 ACK,进入 TIME_WAIT 状态。
-
等待 2MSL(最大报文生存时间)后,进入 CLOSED 状态。
-
服务器收到 ACK 后,立即关闭连接。
为什么握手是三次、挥手是四次?
握手中,SYN 和 ACK 可以合并发送(第二次握手),所以只需三次。
挥手中,FIN 和 ACK 通常不能合并,因为服务端可能还有数据要发,因此需要四次。
数据结构
红黑树
红黑树(Red-Black Tree)是一种 自平衡二叉查找树(BST),用于在最坏情况下也能提供良好的查找、插入和删除效率。红黑树是 AVL树的轻量替代方案,相比 AVL 树插入和删除时的旋转更少,因此在写操作较多的场景中性能更优。
红黑树的性质(核心规则)
-
每个节点要么是红色,要么是黑色。
-
根节点是黑色。
-
所有叶子节点(NIL)都是黑色。
-
红色节点的子节点必须是黑色(不能连续两个红色节点)。
-
从任一节点到其所有叶子节点的路径中,黑色节点数量相同(黑高一致)。
这些性质保证了树的平衡性:最长路径不会超过最短路径的2倍。
算法
动态规划
动态规划(Dynamic Programming,简称 DP)是一种用于求解最优化问题的算法设计思想,它通过将复杂问题分解成更小的子问题、保存子问题的解以避免重复计算,从而提升效率。
状态转移方程:
bash
dp[i] = min(dp[i-1], dp[i-2]) + cost[i]DFS,BFS
排序
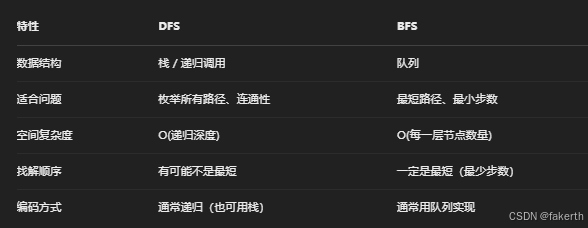
冒泡排序(Bubble Sort):相邻两个数比较,把最大的"冒"到最后。
插入排序(Insertion Sort):从第二个元素开始,向前插入到合适的位置。
选择排序(Selection Sort):每次选择最小的元素,放在未排序序列的开头。
快速排序(Quick Sort):选一个"基准值",比它小的放左边,比它大的放右边,然后递归。
归并排序(Merge Sort):递归分成小块,然后合并排序。
堆排序(Heap Sort):先建一个大顶堆,然后不断将堆顶(最大值)放到末尾。
Rust
编程思想
Rust的编程思想安全性(所有权,不需要回收机制)、并发性和性能
数据库
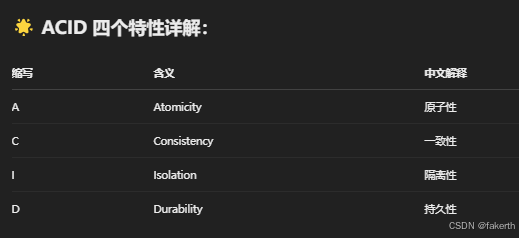
四个特性,ACID
文件写入的过程
1.用户空间请求写入
当一个程序需要向文件写入数据时,它会通过系统调用请求操作系统执行文件写入操作。
- 常见的系统调用:write()、fwrite()、open()(打开文件)
2.系统调用与内核交互
当程序调用 write() 等系统调用时,程序会进入内核态,操作系统将会进行以下操作:
-
参数校验:检查写入操作的合法性,如文件描述符是否有效,文件是否存在,是否有写入权限等。
-
缓冲区管理:操作系统会将数据缓存到内核中的缓冲区(通常是页缓存)。如果数据比较小,可能不会立即写入磁盘,而是先写入缓冲区,待缓冲区满或者文件关闭时再写入磁盘。
3.数据写入磁盘
当内核准备好写入数据时,会根据文件描述符指向的文件路径,执行实际的磁盘 I/O 操作。这个过程包含:
-
文件系统管理:内核会使用文件系统来定位文件数据块(例如,EXT4、NTFS等)。文件系统管理元数据(如文件大小、位置、权限等)并决定数据应写入哪些磁盘块。
-
磁盘调度:操作系统通过磁盘调度算法(如 FIFO、SSTF)管理写入请求的顺序,减少磁盘寻道时间,优化磁盘 I/O 性能。
-
物理存储:数据被写入磁盘的物理存储介质中,通常是 HDD(机械硬盘)或 SSD(固态硬盘)。磁盘存储通常由磁头或闪存芯片进行管理。
4.同步与数据持久化
写入磁盘的过程可能会涉及同步机制以确保数据的持久性,特别是在发生故障时。
-
同步写入:通过调用 fsync() 或 fdatasync() 系统调用,操作系统会强制将数据从内存中的缓存写入到磁盘,确保数据不丢失。通常,操作系统会在文件关闭时自动将缓存区的内容刷新到磁盘。
-
异步写入:如果没有强制同步,数据可能会先存入内存缓存,稍后再异步写入磁盘。这种方式提高了性能,但存在数据丢失的风险(例如,系统崩溃时)。
5.文件关闭与缓冲区刷新
当文件写入完成并调用 close() 时,内核会执行以下操作:
-
刷新缓存:如果缓冲区中还有未写入的数据,操作系统会将数据写入磁盘。
-
释放文件描述符:释放与文件相关的资源,并更新文件的元数据(如修改时间等)。
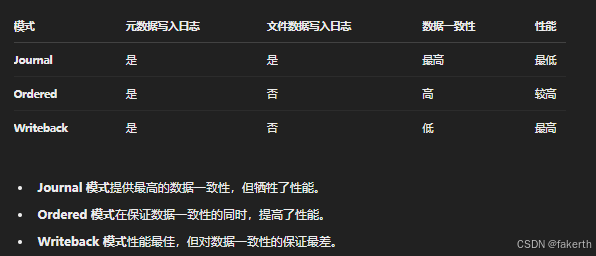
6.文件系统的日志机制(可选)
一些现代文件系统(如 EXT4、XFS)使用日志(journal)机制来保证写入操作的原子性和持久性。每当数据被写入磁盘时,文件系统首先将操作记录到日志中,然后再执行实际的写入操作。如果系统崩溃,文件系统可以通过日志恢复到一致的状态。