TL;DR
- 2025 年 4 月 5 日,Meta AI 正式发布了第四代大型语言模型 Llama 4。引入了 Mixture-of-Experts (MoE,专家混合) 架构,同时原生支持多模态输入,最小的 Llama 4 Scout 模型支持 10m 的长文本输入。
Paper name
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Paper Reading Note
Paper URL:
背景
- 近两年来,大模型领域竞争激烈,OpenAI 的 GPT-4、Anthropic 的 Claude 以及谷歌的 Gemini 等闭源模型引领潮流。Meta 希望通过开源策略参与这一竞赛,以开放的方式推进 AI 技术发展
- Llama 4 的目标是提供业界领先的 AI 能力,同时保持开放透明,让研究者和开发者能够自由使用和改进模型
简介
以下是 Llama 4 各变体的详细规格
| 模型 | 活跃参数 | 总参数 | 专家数 | 上下文窗口 | 备注 |
|---|---|---|---|---|---|
| Scout | 17B | 109B | 16 | 10M | 适合单 GPU 运行,性能优于 Gemini 2.0 Flash-Lite |
| Maverick | 17B | 400B | 128 | 未指定 | 性能优于 GPT-4o,成本效益高 |
| Behemoth | 288B | ~2T | 16 | 未指定 | 仍在训练中,预计超越 GPT-4.5 等模型 |
- Scout:活跃参数 17 亿(17B),总参数 1090 亿(109B),16 个专家,上下文窗口达 1000 万标记(10M)。它能运行在单个 NVIDIA H100 GPU 上,适合资源有限的用户。
- Maverick:活跃参数 17 亿,总参数 4000 亿(400B),128 个专家,性能表现优于 GPT-4o 和 Gemini 2.0 Flash,成本效益高。
- Behemoth:活跃参数 2880 亿(288B),总参数约 2 万亿(~2T),16 个专家,目前仍在训练中,预计在数学、多语言和图像基准测试中表现卓越。

细节
预训练
-
模型规模与架构
- Llama 4 引入了 Mixture-of-Experts (MoE,专家混合) 架构,这是 Llama 系列首次采用 MoE 技术。MoE 的核心思想是拥有多个"专家"子模型,在处理每个输入时仅激活一部分参数,从而大幅提升参数规模却不显著增加推理开销
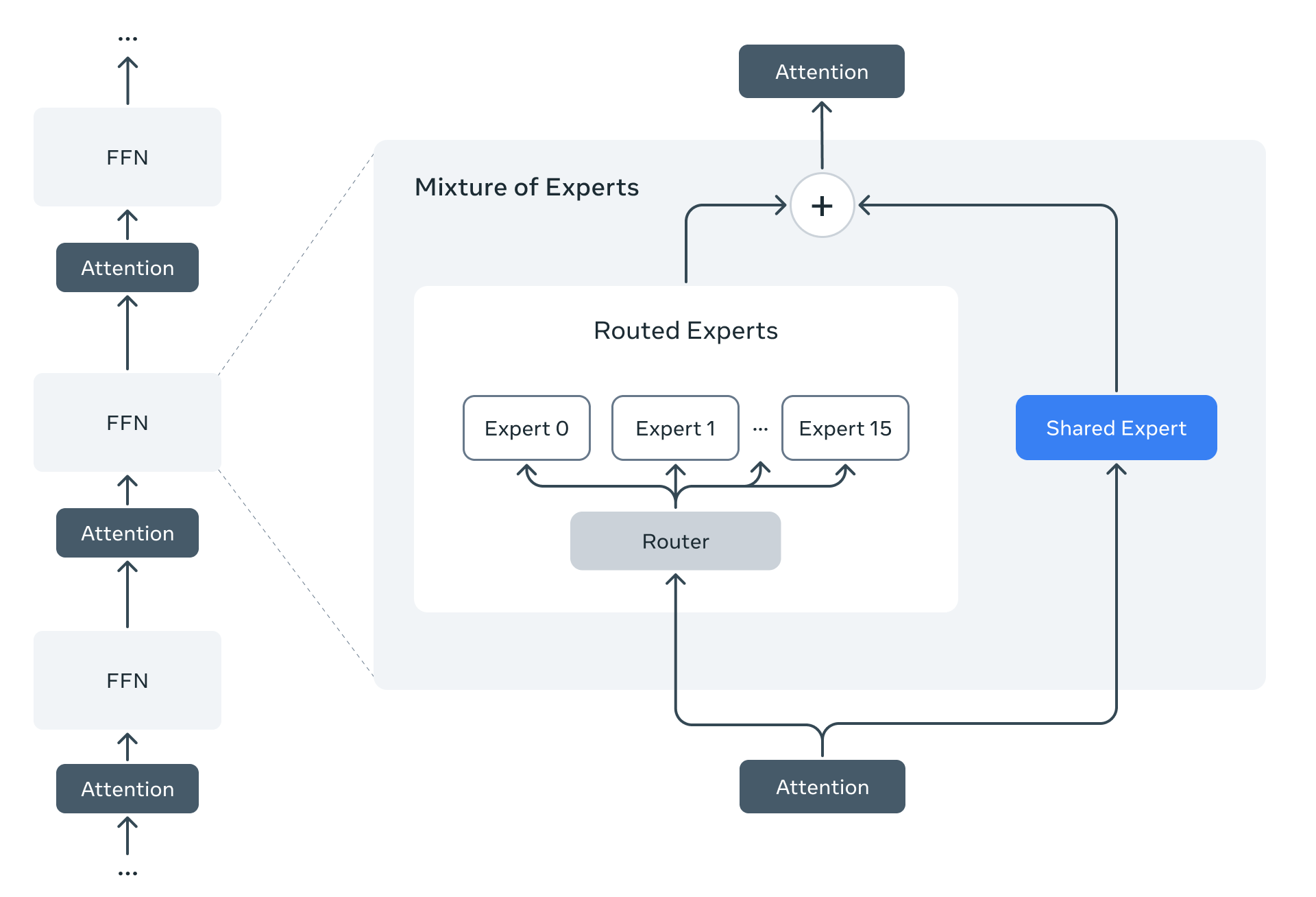
- vision encoder 使用了升级版本的 MetaCLIP,与一个 freeze 参数的 Llama 模型同时训练,从而和 LLM 更适配
- 部分层使用了 NoPE,即不使用 rope 作为位置编码,另外大部分层使用 RoPE 进行编码。另外提出了 iRoPE,采用了 inference time temperature scaling 来提升长文本泛化能力
- Llama 4 引入了 Mixture-of-Experts (MoE,专家混合) 架构,这是 Llama 系列首次采用 MoE 技术。MoE 的核心思想是拥有多个"专家"子模型,在处理每个输入时仅激活一部分参数,从而大幅提升参数规模却不显著增加推理开销
-
训练数据:
- 使用 30 万亿标记的训练数据,涵盖 200 种语言,其中超过 100 种语言的标记数超过 10 亿,相比 Llama 3 的 15 万亿标记翻倍。
- 多模态数据,支持文本、图片和视频数据
-
基建:
- 采用 FP8 精度,在 32000 个 GPU 上达到 390 TFLOPs 的性能,支持多达 48 张图像的预训练,测试时支持 8 张图像。
后训练
-
后训练最大的难度是平衡模型的多模态输入、推理、对话等能力
-
包括监督微调(SFT)、在线强化学习(RL)和直接偏好优化(DPO),特别针对推理、编码和数学问题进行优化。顺序是:
- 小规模 SFT:删除了 50% 的 easy 难度数据
- 在线强化学习(RL)
- 小规模直接偏好优化(DPO):解决模型回复质量问题,在模型智能程度与对话能力之间取得平衡
-
SFT 和 DPO 使用小规模训练的原因是发现 SFT 和 DPO 会过度约束模型,限制了在线 RL 阶段的探索。
-
安全
- 安全是 Llama 4 的重点。模型纳入了 Llama Guard 和 Prompt Guard,以减少偏见和有害内容生成。拒绝率从 Llama 3.3 的 7% 降至低于 2%,政治倾向与 Grok 相当,较 Llama 3.3 减半。
实验
-
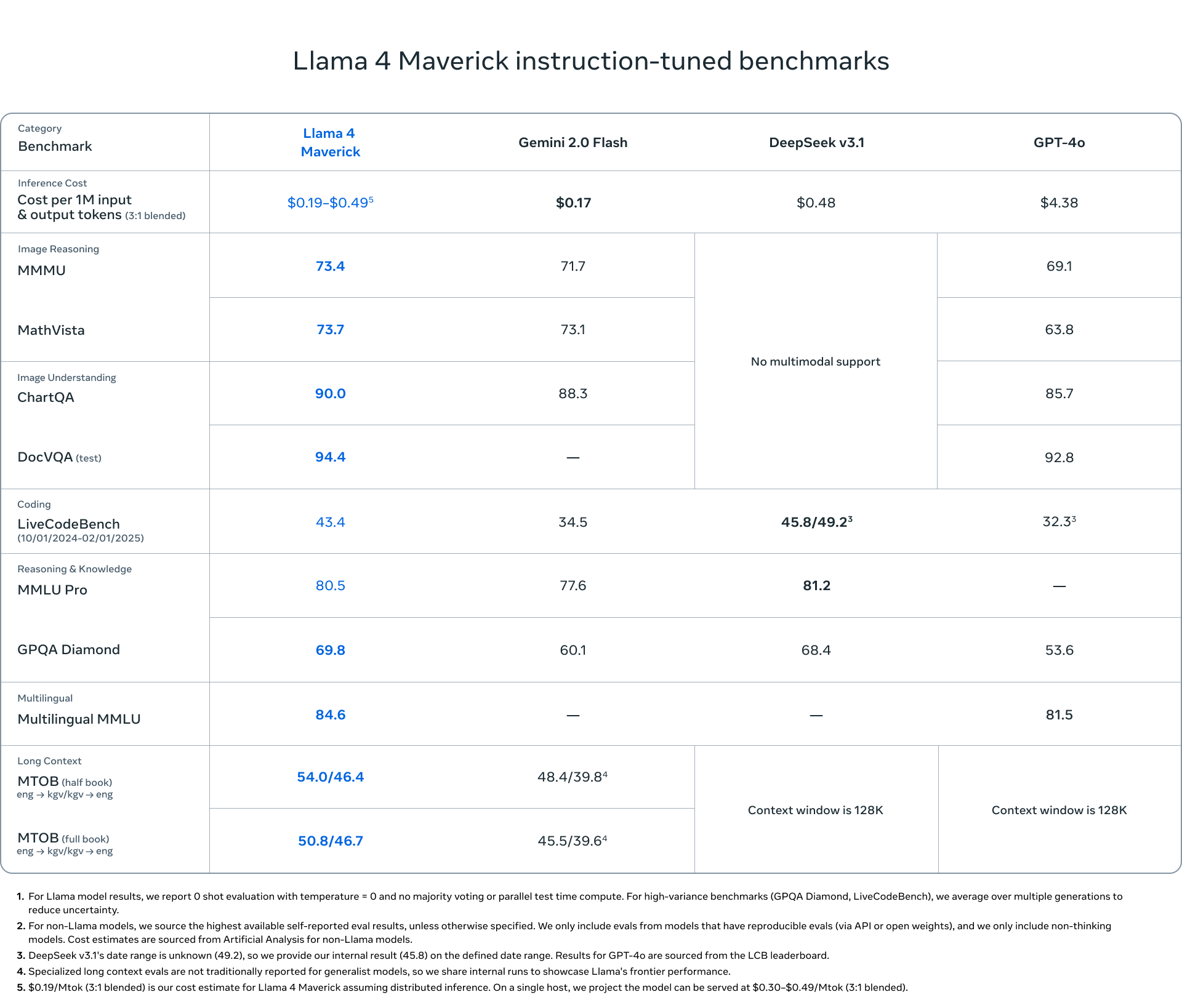
Llama 4 Maverick 17B 激活参数,400B 总参数,推理成本比 llama3-70B 低,在代码、推理等方面超过 GPT-4o 和 Gemini 2.0,和参数量更大的 deepseek-v3.1 比也性能相当
-
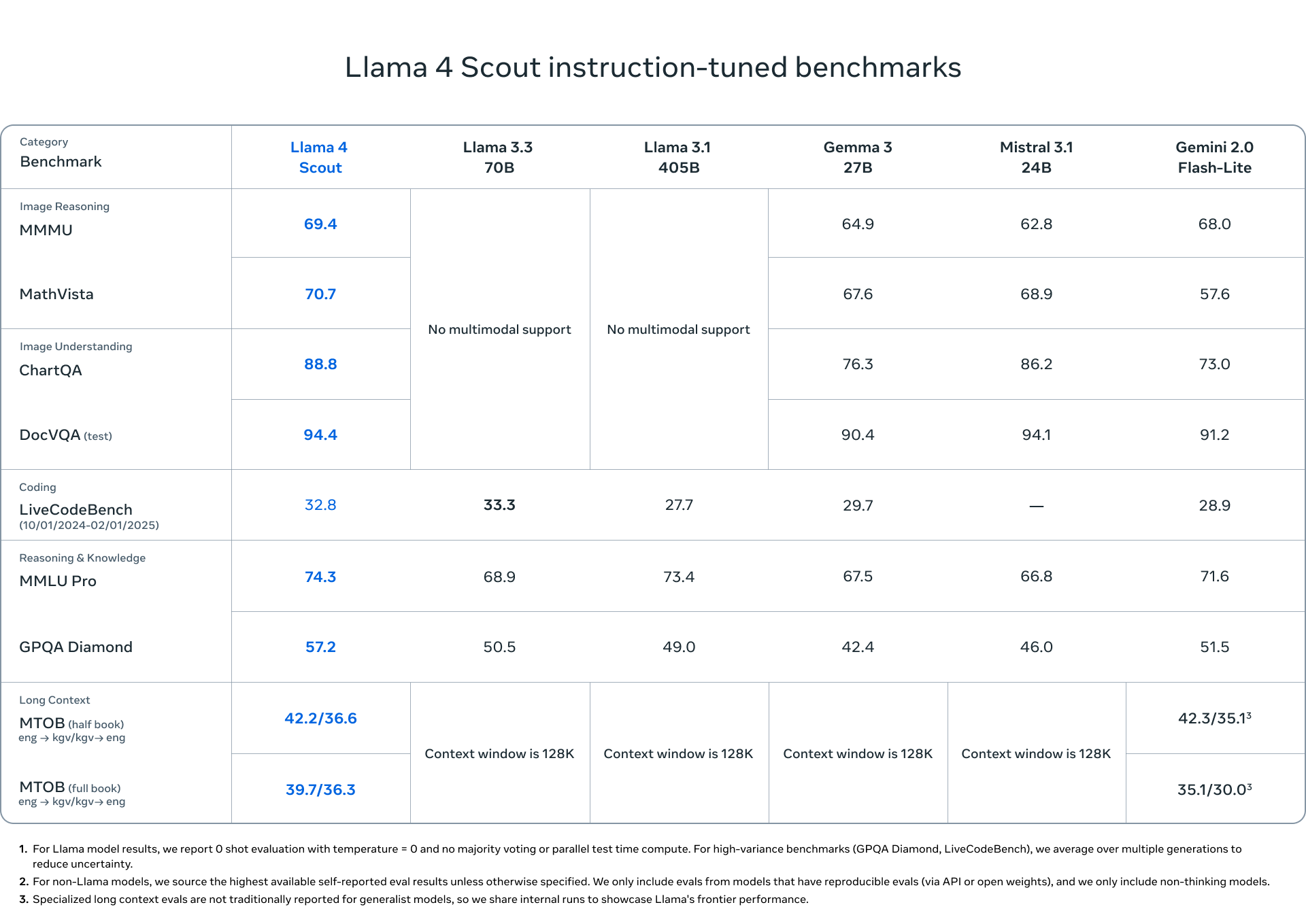
最小的 Llama 4 Scout 模型也有出色的 image grouding 能力,视觉理解能力。
-
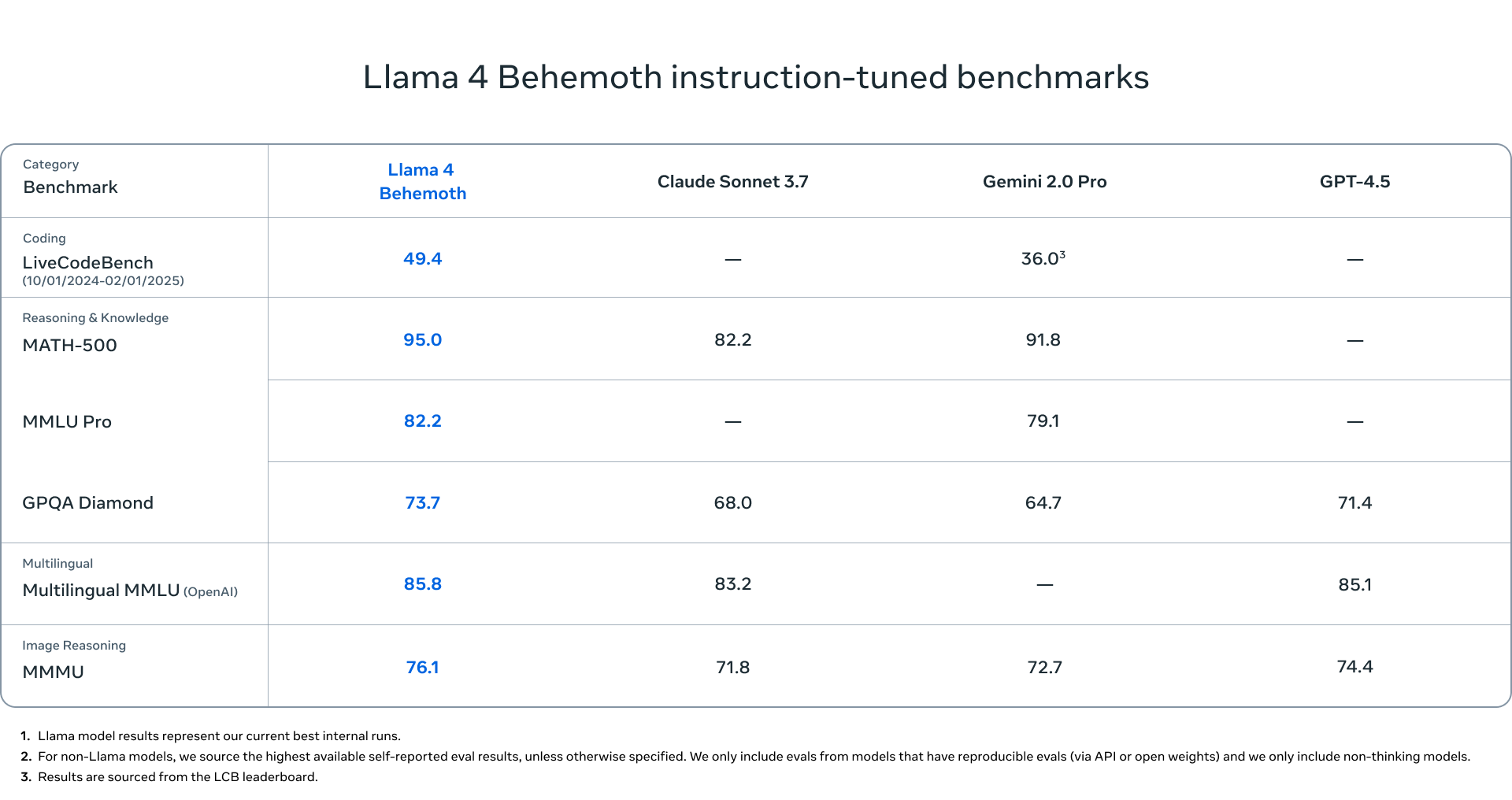
最大的还在训练的模型 Llama 4 Behemoth,这个模型没有开源,主要是作为 teacher 模型来蒸馏小模型。
总结
- benchmark 指标看起来都挺强的,原生多模态能力感觉还是值得期待的,毕竟是 meta 出品
- 网络上流传的刷 benchmark 其实应该石锤起来还是挺容易的,毕竟模型都开源了,如果真的是按照爆料所说的把所有公开的测试集都拿来训练了未来肯定会找到一些证据,暂时从技术报告来看所有的设计和创新都还挺合理的