Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
Pandas 主要引入了两种新的数据结构:Series 和 DataFrame 。(可以理解为表格)
- Series : 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。

0、1、2 表示行索引
李四、王五、张三表示数据值
dtype 表示数据值的类型
- DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。

0、1、2 表示行索引
name、age、gender表示列索引
1、安装pandas
直接安装:
pip install pandas
安装失败可以更换地址:
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装成功后,我们就可以导入 pandas 包使用:
python
import pandas导入 pandas 一般使用别名 pd 来代替
python
import pandas as pd查看 pandas 版本
python
import pandas as pd
print(pd.__version__)2、Series
Pandas Series 类似表格中的一个列,类似于一维数组,可以保存任何数据类型 Series 由索引(index)和列组成,函数:
| 函数名 | 参数 |
|---|---|
| pandas.Series(data,index,dtype) | data:一组数据(ndarray 类型) index:数据索引标签,如果不指定,默认从 0 开始 dtype:数据类型,默认会自己判断 copy:表示对 data 进行拷贝,默认为 False |
2.1创建Series对象
2.1.1列表创建Series对象
python
import pandas as pd
# 列表形式
L = ['张三','李四','王五']
S = pd.Series(L)
print(S)
python
import pandas as pd
# 列表形式
L = ['张三','李四','王五']
S = pd.Series(L, index=['a', 'b', 'c'])
print(S)
2.1.2字典创建 Series 对象
python
import pandas as pd
data={'name':'Alice','age':25}
df=pd.Series(data)
print(df)
2.2访问
python
import pandas as pd
data={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)
print(df['name'])
print(df['age'])
print(df['city'])
# Alice
# 25
# Beijing2.3遍历
2.3.1使用 items()
python
import pandas as pd
data={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)
#遍历Series对象
#使用 items(): 遍历Series对象的键值对
for a,b in df.items():
print(f"键值:{a},数据:{b}")
# 键值:name,数据:Alice
# 键值:age,数据:25
# 键值:city,数据:Beijing2.3.2使用 index
python
import pandas as pd
data={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)
#遍历Series对象
# 使用 index 属性: 遍历Series对象的索引
for i in df.index:
print(f"索引:{i}, 值:{df[i]}")
# 索引:name, 值:Alice
# 索引:age, 值:25
# 索引:city, 值:Beijing2.3.3values
python
import pandas as pd
data={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)
#遍历Series对象
# values 属性:返回Series对象中所有的值
for i in df.values:
print(f"数据:{i}")
# 数据:Alice
# 数据:25
# 数据:Beijing3、DataFrame
| 函数名 | 参数 |
|---|---|
| pd.DataFrame( data, index, columns, dtype, copy) | data:一组数据(ndarray、series, map, lists, dict 等类型) index:索引值,或者可以称为行标签 columns:列标签 dtype:数据类型 copy:默认为 False,表示复制数据 data |
在 Pandas 中,DataFrame 的每一行或每一列都是一个 Series。
DataFrame 是一个二维表格,可以看作是由多个 Series 组成的。
3.1创建 DataFrame 对象
3.1.1列表创建
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df)
#[1,2,3]是一行,[4,5,6]是一行,以此类推
#有4行, 分别对应A、B、C、D
#有3列,分别对应X、Y、Z
python
import pandas as pd
data = [[1,2],[4,5,6],[7,8,9],[10,11]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df)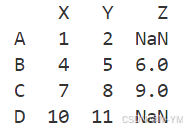
第1、4行比第2、3行少一个元素,则以NaN填充,数据类型转换为float
3.1.2字典创建
python
import pandas as pd
data= {'name':['Alice','Bob','Charlie','David'],'age':[25,30,35,40]}
df=pd.DataFrame(data)
print(df)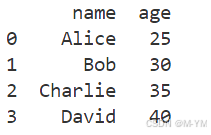
python
import pandas as pd
data= {'name':['Alice','Bob','Charlie','David'],'age':[25,30,35,40]}
df=pd.DataFrame(data,index=['A','B','C','D'])
print(df)
3.2列索引操作
DataFrame 可以使用列索(columns index)引来完成数据的选取、添加和删除操作
3.2.1获取数据
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df['Y'])
#行不能这样获取,df['A']会报错
# A 2
# B 5
# C 8
# D 113.2.2添加列
1.直接添加
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df['M'] = [10,20,30,40]
print(df)
# X Y Z M
# A 1 2 3 10
# B 4 5 6 20
# C 7 8 9 30
# D 10 11 12 402.assign方法
assign方法添加数据是新建一个
assign()函数可以给DataFrame添加一列或多列数据,并返回一个新的DataFrame。
原DataFrame数据不变,新DataFrame包含原数据和新数据。
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
f=df.assign(M=[10,20,30,40])
print(df)
print(f)
df=df.assign(M=[10,20,30,40])
print(df)
# X Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12
# X Y Z M
# A 1 2 3 10
# B 4 5 6 20
# C 7 8 9 30
# D 10 11 12 40
# X Y Z M
# A 1 2 3 10
# B 4 5 6 20
# C 7 8 9 30
# D 10 11 12 403.insert方法
在指定的位置插入新列
使用insert方法在指定位置插入新列,参数:
-
loc: 插入位置的列索引。
-
column: 新列的名称。
-
value: 要插入的 Series。
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
#在列索引为1的位置插入一列W,并赋值为[100,200,300,400]
df.insert(1, 'W', [100,200,300,400])
print(df)
# X W Y Z
# A 1 100 2 3
# B 4 200 5 6
# C 7 300 8 9
# D 10 400 11 123.2.3修改数据
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df['X']=[10,20,30,40]
print(df)
# X Y Z
# A 10 2 3
# B 20 5 6
# C 30 8 9
# D 40 11 12
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df['X']=df['X']+10
print(df)
# X Y Z
# A 11 2 3
# B 14 5 6
# C 17 8 9
# D 20 11 12修改列名
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df.columns=['a','b','c']
print(df)
# a b c
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12rename 方法修改列名 :
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df = df.rename(columns={'X':'a'})
print(df)
# a Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 123.3 loc 选取数据
df.loc\[\] 只能使用标签索引,不能使用整数索引。当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭,也就是包括边界值标签(开始和结束)
loc方法返回的数据类型:
1.如果选择单行或单列,返回的数据类型为Series
2.选择多行或多列,返回的数据类型为DataFrame
3.选择单个元素(某行某列对应的值),返回的数据类型为该元素的原始数据类型(如整数、浮点数等)。
:
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df.loc['B']) # 输出B行数据
print(df.loc['B':'C']) # 输出B到C行数据
print(df.loc['B','X']) # 输出B行X列数据
print(df.loc['B':'C','Y':'Z']) # 输出B到C行,Y列到Z列数据
print(df.loc[['A','D'],['X','Z']]) # 输出A和D行,X列和Z列数据
# X 4
# Y 5
# Z 6
# X Y Z
# B 4 5 6
# C 7 8 9
# 4
# Y Z
# B 5 6
# C 8 9
# X Z
# A 1 3
# D 10 123.4 iloc 选取数据
iloc 方法用于基于位置(integer-location based)的索引,即通过行和列的整数位置来选择数据。
语法:
DataFrame.iloc[row_indexer, column_indexer]参数:
-
row_indexer:行位置或布尔数组。
-
column_indexer:列位置或布尔数组。
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df.iloc[1]) # 输出B行数据
print(df.iloc[1:3]) # 输出B到C行数据
print(df.iloc[1,0]) # 输出B行,X列数据
print(df.iloc[1:3,[1,2]]) # 输出B到C行,Y列到Z列数据
print(df.iloc[[0,3],[0,2]]) # 输出A和D行,X列和Z列数据
# X 4
# Y 5
# Z 6
# X Y Z
# B 4 5 6
# C 7 8 9
# 4
# Y Z
# B 5 6
# C 8 9
# X Z
# A 1 3
# D 10 123.5添加数据
3.5.1 loc方法添加
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
#添加一行
df.loc['E']=[13,14,15]
print(df)
#添加一列
df['W']=[16,17,18,19,20]
print(df)
X Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12
# E 13 14 15
# X Y Z W
# A 1 2 3 16
# B 4 5 6 17
# C 7 8 9 18
# D 10 11 12 19
# E 13 14 15 203.5.2 concat拼接
python
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)参数:
objs: 要连接的 DataFrame 或 Series 对象的列表或字典。
axis: 指定连接的轴,0 或 'index' 表示按行连接,1 或 'columns' 表示按列连接。
join: 指定连接方式,'outer' 表示并集(默认),'inner' 表示交集。
ignore_index: 如果为 True,则忽略原始索引并生成新的索引。
keys: 用于在连接结果中创建层次化索引。
levels: 指定层次化索引的级别。
names: 指定层次化索引的名称。
verify_integrity: 如果为 True,则在连接时检查是否有重复索引。
sort: 如果为 True,则在连接时对列进行排序。
copy: 如果为 True,则复制数据。
python
#多行添加
#concat
#axis=0表示行合并
#axis=1表示列合并
#ignore_index参数指定是否重置索引,默认False,没有ignore_index就可能会出现重复索引
def f3():
df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})
df2=pd.DataFrame({'A':[7,8,9],'B':[10,11,12]})
df3=pd.concat([df1,df2],axis=0,ignore_index=True)
print(df3)
print("*****")
# f3()
#列合并
def f4():
df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})
df2=pd.DataFrame({'C':[7,8,9],'D':[10,11,12]})
df3=pd.concat([df1,df2],axis=1)
print(df3)
# f4()
#join方法合并数据,outer表示合并所有行,inner表示合并匹配的行
def f5():
df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})
df2=pd.DataFrame({'A':[7,8,9],'B':[10,11,12],'C':[13,14,15]})
df3 = pd.concat([df1,df2],axis=0) #join默认是outer,合并所有行,即保留df1和df2的所有行
print(df3)
print("*****")
df4 = pd.concat([df1,df2],axis=0,join='inner') #join='inner'交集,即只保留df1和df2的交集,'C':[13,14,15]不会被保留
print(df4)
print("*****")
# f5()
#DataFrame和Series的拼接
def f6():
df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})
print("行合并")
s1=pd.Series([7,8,9],name='C')
df2=pd.concat([df1,s1],axis=0)
print(df2)
print("列合并")
df2=pd.concat([df1,s1],axis=1)
print(df2)
# f6()3.5删除数据
通过drop方法删除 DataFrame 中的数据,默认情况下,drop() 不会修改原 DataFrame,而是返回一个新的 DataFrame。
python
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')参数:
-
labels:必写
-
类型:单个标签或列表。
-
描述:要删除的行或列的标签。如果 axis=0,则 labels 表示行标签;如果 axis=1,则 labels 表示列标签。
-
-
axis:必写
-
类型:整数或字符串,默认为 0。
-
描述:指定删除的方向。axis=0 或 axis='index' 表示删除行,axis=1 或 axis='columns' 表示删除列。
-
-
index:
-
类型:单个标签或列表,默认为 None。
-
描述:要删除的行的标签。如果指定,则忽略 labels 参数。
-
-
columns:
-
类型:单个标签或列表,默认为 None。
-
描述:要删除的列的标签。如果指定,则忽略 labels 参数。
-
-
level:
-
类型:整数或级别名称,默认为 None。
-
描述:用于多级索引(MultiIndex),指定要删除的级别。
-
-
inplace:
-
类型:布尔值,默认为 False。
-
描述 :如果为 True,则直接修改原 DataFrame,而不是返回一个新的 DataFrame。
-
-
errors:
-
类型:字符串,默认为 'raise'。
-
描述:指定如何处理不存在的标签。'raise' 表示抛出错误,'ignore' 表示忽略错误。
-
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
f=df.drop('X',axis=1)
print(df)
print(f)
# X Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12
# Y Z
# A 2 3
# B 5 6
# C 8 9
# D 11 12则直接修改原 DataFrame,而不是返回一个新的 DataFrame。
python
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df.drop('B',axis=0,inplace=True)
print(df)
# X Y Z
# A 1 2 3
# C 7 8 9
# D 10 11 124、函数
4.1常用方法
isnull() 和 notnull() 用于检测 Series、DataFrame 中的缺失值。所谓缺失值,顾名思义就是值不存在、丢失、缺少
-
isnull():如果为值不存在或者缺失,则返回 True
-
notnull():如果值不存在或者缺失,则返回 False
4.2常用的统计学函数
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积 |
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
# 计算每列的均值
mean_values = df.mean()
print(mean_values)
# 计算每列的中位数
median_values = df.median()
print(median_values)
#计算每列的方差
var_values = df.var()
print(var_values)
# 计算每列的标准差
std_values = df.std()
print(std_values)
# 计算每列的最小值
min_values = df.min()
print("最小值:")
print(min_values)
# 计算每列的最大值
max_values = df.max()
print("最大值:")
print(max_values)
# 计算每列的总和
sum_values = df.sum()
print(sum_values)
# 计算每列的非空值数量
count_values = df.count()
print(count_values)4.3重置索引
重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
reindex
reindex() 方法用于重新索引 DataFrame 或 Series 对象。重新索引意味着根据新的索引标签重新排列数据,并填充缺失值。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
语法:
python
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=np.nan, limit=None, tolerance=None)参数:
-
labels:
-
类型:数组或列表,默认为 None。
-
描述:新的索引标签。
-
-
index:
-
类型:数组或列表,默认为 None。
-
描述:新的行索引标签。
-
-
columns:
-
类型:数组或列表,默认为 None。
-
描述:新的列索引标签。
-
-
axis:
-
类型:整数或字符串,默认为 None。
-
描述:指定重新索引的轴。0 或 'index' 表示行,1 或 'columns' 表示列。
-
-
method:
-
类型:字符串,默认为 None。
-
描述:用于填充缺失值的方法。可选值包括 'ffill'(前向填充)、'bfill'(后向填充)等。
-
-
copy:
-
类型:布尔值,默认为 True。
-
描述:是否返回新的 DataFrame 或 Series。
-
-
level:
-
类型:整数或级别名称,默认为 None。
-
描述:用于多级索引(MultiIndex),指定要重新索引的级别。
-
-
fill_value:
-
类型:标量,默认为 np.nan。
-
描述:用于填充缺失值的值。
-
-
limit:
-
类型:整数,默认为 None。
-
描述:指定连续填充的最大数量。
-
-
tolerance:
-
类型:标量或字典,默认为 None。
-
描述:指定重新索引时的容差。
-
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 重新索引行
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index)
print(df_reindexed)
# 重新索引列
new_columns = ['A', 'B', 'C', 'D']
df_reindexed = df.reindex(columns=new_columns)
print(df_reindexed)
# 重新索引行,并使用前向填充
# 新的行索引 ['a', 'b', 'c', 'd'] 包含了原索引中不存在的标签 'd',使用 method='ffill' 进行前向填充,因此 'd' 对应的行填充了前一行的值。
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, method='ffill')
print(df_reindexed)
# 重新索引行,并使用指定的值填充缺失值
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, fill_value=0)
print(df_reindexed)4.4遍历
DataFrame 这种二维数据表结构,遍历会获取列标签
python
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
df = pd.DataFrame(data)
for i in df:
print(i)
# name
# age4.4.1itertuples() 遍历行
itertuples() 方法用于遍历 DataFrame 的行,返回一个包含行数据的命名元组。
itertuples() 是遍历 DataFrame 的推荐方法,因为它在速度和内存使用上都更高效。
python
#遍历行
#itertuples()方法可以将DataFrame转换成一个迭代器,每一行都是一个namedtuple,可以直接访问每一列的值。
#使用itertuples()方法遍历DataFrame,并打印每一行的索引、值、列名。
for row in df.itertuples():
print(row) #row是一个namedtuple,包含索引、值、列名
# Pandas(Index=0, name='Alice', age=25)
# Pandas(Index=1, name='Bob', age=30)
# Pandas(Index=2, name='Charlie', age=35)index=False参数表示不显示索引
python
for row in df.itertuples(index=False):
# print(row)
for i in row:
print(i)
# Alice
# 25
# Bob
# 30
# Charlie
# 354.4.2 items()遍历列
items() 方法用于遍历 DataFrame 的列,返回一个包含列名和列数据的迭代器。
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 使用 items() 遍历列
for column_name, column_data in df.items():
print(f"Column Name: {column_name}, Column Data: {column_data}")
#输出:
Column Name: A, Column Data: a 1
b 2
c 3
Name: A, dtype: int64
Column Name: B, Column Data: a 4
b 5
c 6
Name: B, dtype: int64
Column Name: C, Column Data: a 7
b 8
c 9
Name: C, dtype: int644.4.3 使用属性遍历
loc 和 iloc 方法可以用于按索引或位置遍历 DataFrame 的行和列。
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 使用 loc 遍历行和列
for index in df.index:
for column in df.columns:
print(f"Index: {index}, Column: {column}, Value: {df.loc[index, column]}")
# 输出:
Index: a, Column: A, Value: 1
Index: a, Column: B, Value: 4
Index: a, Column: C, Value: 7
Index: b, Column: A, Value: 2
Index: b, Column: B, Value: 5
Index: b, Column: C, Value: 8
Index: c, Column: A, Value: 3
Index: c, Column: B, Value: 6
Index: c, Column: C, Value: 94.5 排序
4.5.1 sort_index
sort_index 方法用于对 DataFrame 或 Series 的索引进行排序。
python
DataFrame.sort_index(axis=0, ascending=True, inplace=False)
Series.sort_index(axis=0, ascending=True, inplace=False)参数:
-
axis:指定要排序的轴。默认为 0,表示按行索引排序。如果设置为 1,将按列索引排序。
-
ascending:布尔值,指定是升序排序(True)还是降序排序(False)。
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['b', 'c', 'a'])
# 按行索引标签排序,不对对应的值排序
df_sorted = df.sort_index()
#输出:
A B C
a 3 6 9
b 1 4 7
c 2 5 8
#按列索引标签降序排序
df_sorted = df.sort_index(axis=1,ascending=False)
print(df_sorted)
# 输出:
C B A
b 7 4 1
c 8 5 2
a 9 6 34.5.2 sort_values
sort_values 方法用于根据一个或多个列的值对 DataFrame 进行排序。
python
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False,
kind='quicksort', na_position='last')参数:
-
by:列的标签或列的标签列表。指定要排序的列。
-
axis:指定沿着哪个轴排序。默认为 0,表示按行排序。如果设置为 1,将按列排序。
-
ascending:布尔值或布尔值列表,指定是升序排序(True)还是降序排序(False)。可以为每个列指定不同的排序方向。
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
-
kind:排序算法。默认为 'quicksort',也可以选择 'mergesort'(归并排序) 或 'heapsort'(堆排序)。
-
na_position:指定缺失值(NaN)的位置。可以是 'first' 或 'last'。
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [3, 2, 1],
'B': [6, 5, 4],
'C': [9, 8, 7]
}
df = pd.DataFrame(data, index=['b', 'c', 'a'])
# 按列 'A' 排序
df_sorted = df.sort_values(by='A')
print(df_sorted)
# 按列 'A' 和 'B' 排序
df_sorted = df.sort_values(by=['A', 'B'])
print(df_sorted)
# 按列 'A' 降序排序
df_sorted = df.sort_values(by='A', ascending=False)
print(df_sorted)
# 按列 'A' 和 'B' 排序,先按A列降序排序,如果A列中值相同则按B列升序排序
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 25, 35, 30],
'Score': [85, 90, 80, 95, 88]
})
df_sorted = df.sort_values(by=['Age', 'Score'], ascending=[False, True])
print(df_sorted)4.6 去重
drop_duplicates 方法用于删除 DataFrame 或 Series 中的重复行或元素。
python
drop_duplicates(by=None, subset=None, keep='first', inplace=False)
Series.drop_duplicates(keep='first', inplace=False)参数:
-
by:用于标识重复项的列名或列名列表。如果未指定,则使用所有列。
-
subset:与 by 类似,但用于指定列的子集。
-
keep:指定如何处理重复项。可以是:
-
'first':保留第一个出现的重复项(默认值)。
-
'last':保留最后一个出现的重复项。
-
False:删除所有重复项。
-
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的删除重复项后的对象。
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 2, 3],
'B': [4, 5, 5, 6],
'C': [7, 8, 8, 9]
}
df = pd.DataFrame(data)
print(df)
# 删除所有列的重复行,默认保留第一个出现的重复项
df_unique = df.drop_duplicates()
print(df_unique)
# 删除重复行,保留最后一个出现的重复项
df_unique = df.drop_duplicates(keep='last')
print(df_unique)
# 修改原数据
df.drop_duplicates(keep='last', inplace=True)
print(df)
#原数据
# A B C
# 0 1 4 7
# 1 2 5 8
# 2 2 5 8
# 3 3 6 9
# 删除所有列的重复行,默认保留第一个出现的重复项
# A B C
# 0 1 4 7
# 1 2 5 8
# 3 3 6 9
# 删除重复行,保留最后一个出现的重复项
# A B C
# 0 1 4 7
# 2 2 5 8
# 3 3 6 94.7 分组
4.7.1 groupby
groupby 方法用于对数据进行分组操作,这是数据分析中非常常见的一个步骤。通过 groupby,你可以将数据集按照某个列(或多个列)的值分组,然后对每个组应用聚合函数,比如求和、平均值、最大值等。
python
DataFrame.groupby(by, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)参数:
-
by:用于分组的列名或列名列表。
-
axis:指定沿着哪个轴进行分组。默认为 0,表示按行分组。
-
level:用于分组的 MultiIndex 的级别。
-
as_index:布尔值,指定分组后索引是否保留。如果为 True,则分组列将成为结果的索引;如果为 False,则返回一个列包含分组信息的 DataFrame。
-
sort:布尔值,指定在分组操作中是否对数据进行排序。默认为 True。
-
group_keys:布尔值,指定是否在结果中添加组键。
-
squeeze:布尔值,如果为 True,并且分组结果返回一个元素,则返回该元素而不是单列 DataFrame。
-
observed:布尔值,如果为 True,则只考虑数据中出现的标签。
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]
}
df = pd.DataFrame(data)
# 按列 'A' 分组
grouped = df.groupby('A')
# 查看分组结果
for name, group in grouped:
print(f"Group: {name}")
print(group)
print()
mean = df.groupby(['A']).mean()
print(mean)
#输出:
C D
A
bar 4.0 40.0
foo 4.8 48.0
mean = grouped['C'].mean()
print(mean)
#输出:
A
bar 4.0
foo 4.8
# 在分组内根据C列求平均值
# transform用于在分组操作中对每个组内的数据进行转换,并将结果合并回原始 DataFrame。
mean = grouped['C'].transform(lambda x: x.mean())
df['C_mean'] = mean
print(df)
#输出:
A B C D C_mean
0 foo one 1 10 4.8
1 bar one 2 20 4.0
2 foo two 3 30 4.8
3 bar three 4 40 4.0
4 foo two 5 50 4.8
5 bar two 6 60 4.0
6 foo one 7 70 4.8
7 foo three 8 80 4.8
# 在分组内根据C列求标准差
std = grouped['C'].transform(np.std)
df['C_std'] = std
print(df)
# 在分组内根据C列进行正太分布标准化
norm = grouped['C'].transform(lambda x: (x - x.mean()) / x.std())
df['C_normal'] = norm
print(df)4.7.2 filter
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]
}
df = pd.DataFrame(data)
# 按列 'A' 分组,并过滤掉列 'C' 的平均值小于 4 的组
filtered = df.groupby('A').filter(lambda x: x['C'].mean() >= 4)
print(filtered)4.8 合并
merge 函数用于将两个 DataFrame 对象根据一个或多个键进行合并,类似于 SQL 中的 JOIN 操作。这个方法非常适合用来基于某些共同字段将不同数据源的数据组合在一起,最后拼接成一个新的 DataFrame 数据表。
python
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),
copy=True, indicator=False, validate=None)参数:
-
left:左侧的 DataFrame 对象。
-
right:右侧的 DataFrame 对象。
-
how:合并方式,可以是 'inner'、'outer'、'left' 或 'right'。默认为 'inner'。
-
'inner':内连接,返回两个 DataFrame 共有的键。
-
'outer':外连接,返回两个 DataFrame 的所有键。
-
'left':左连接,返回左侧 DataFrame 的所有键,以及右侧 DataFrame 匹配的键。
-
'right':右连接,返回右侧 DataFrame 的所有键,以及左侧 DataFrame 匹配的键。
-
-
on:用于连接的列名。如果未指定,则使用两个 DataFrame 中相同的列名。
-
left_on 和 right_on:分别指定左侧和右侧 DataFrame 的连接列名。
-
left_index 和 right_index:布尔值,指定是否使用索引作为连接键。
-
sort:布尔值,指定是否在合并后对结果进行排序。
-
suffixes:一个元组,指定当列名冲突时,右侧和左侧 DataFrame 的后缀。
-
copy:布尔值,指定是否返回一个新的 DataFrame。如果为 False,则可能修改原始 DataFrame。
-
indicator:布尔值,如果为 True,则在结果中添加一个名为 __merge 的列,指示每行是如何合并的。
-
validate:验证合并是否符合特定的模式。
内连接
python
import pandas as pd
# 创建两个示例 DataFrame
left = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
})
right = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K4'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
})
# 内连接
result = pd.merge(left, right, on='key')
print(result)
#输出:K3、K4被忽略
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2左连接
python
import pandas as pd
# 创建两个示例 DataFrame
left = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
})
right = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K4'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
})
# 左连接,以左侧表为准
result = pd.merge(left, right, on='key', how='left')
print(result)
# 输出:
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN4.9 随机抽样
python
DataFrame.sample(n=None, frac=None, replace=False, weights=None,
random_state=None, axis=None)参数:
-
n:要抽取的行数
-
frac:抽取的比例,比如 frac=0.5,代表抽取总体数据的50%
-
replace:布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回
-
weights:可选参数,代表每个样本的权重值,参数值是字符串或者数组
-
random_state:可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据
-
axis:表示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)
4.10 空值处理
4.10.1 检测空值
isnull()用于检测 DataFrame 或 Series 中的空值,返回一个布尔值的 DataFrame 或 Series。
notnull()用于检测 DataFrame 或 Series 中的非空值,返回一个布尔值的 DataFrame 或 Series。
python
import pandas as pd
import numpy as np
# 创建一个包含空值的示例 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 检测空值
is_null = df.isnull()
print(is_null)
# 检测非空值
not_null = df.notnull()
print(not_null)4.10.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
python
# 创建一个包含空值的示例 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 用 0 填充空值
df_filled = df.fillna(0)
print(df_filled)4.10.3 删除空值
dropna() 方法用于删除 DataFrame 或 Series 中的空值。
python
# 创建一个包含空值的示例 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 删除包含空值的行
df_dropped = df.dropna()
print(df_dropped)
#输出:
A B C
0 1.0 5.0 9
3 4.0 8.0 12
# 删除包含空值的列
df_dropped = df.dropna(axis=1)
print(df_dropped)
#输出:
C
0 9
1 10
2 11
3 125、读取CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本);
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
5.1 to_csv()
to_csv() 方法将 DataFrame 存储为 csv 文件
python
import pandas as pd
# 创建一个简单的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 将 DataFrame 导出为 CSV 文件
df.to_csv('output.csv', index=False)5.2 read_csv()
read_csv() 表示从 CSV 文件中读取数据,并创建 DataFrame 对象。
python
import pandas as pd
df = pd.read_csv('output.csv')
print(df)6、绘图
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作;
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口;
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形。
python
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 25, 30, 40]
}
df = pd.DataFrame(data)
# 绘制折线图
df.plot(kind='line')
# 显示图表
plt.show()
# 绘制柱状图
df.plot(kind='bar')
# 显示图表
plt.show()
# 绘制直方图
df['A'].plot(kind='hist')
# 显示图表
plt.show()
# 绘制散点图
df.plot(kind='scatter', x='A', y='B')
# 显示图表
plt.show()饼图
python
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个示例 Series
data = {
'A': 10,
'B': 20,
'C': 30,
'D': 40
}
series = pd.Series(data)
# 绘制饼图
series.plot(kind='pie', autopct='%1.1f%%')
# 显示图表
plt.show()