万事开头难,苦尽便是甜
------ 25.4.8
一、什么是强化学习
强化学习和有监督学习是机器学习中的两种不同的学习范式
强化学习: 目标是让智能体通过与环境的交互,学习到一个最优策略以最大化长期累积奖励。
不告诉具体路线,首先去做,做了之后,由环境给你提供奖励,根据奖励的多少让模型进行学习,最终找到正确路线
**例如:**在机器人导航任务中,智能体需要学习如何在复杂环境中移动,以最快速度到达目标位置,同时避免碰撞障碍物,这个过程中智能体要不断尝试不同的行动序列来找到最优路径。
监督学习: 旨在学习一个从输入特征到输出标签的映射函数,通常用于预测、分类和回归等任务。
给出标准答案,让模型朝着正确答案方向去进行学习
**例如:**根据历史数据预测股票价格走势,或者根据图像特征对图像中的物体进行分类,模型通过学习已知的输入输出对来对新的未知数据进行预测
二、强化学习的重要概念
1.智能体和环境
智能体是个很宽泛的概念,可以是一个深度学习模型,也可以是一个实体机器人
环境可能随智能体的动作发生变化,为智能体提供奖励
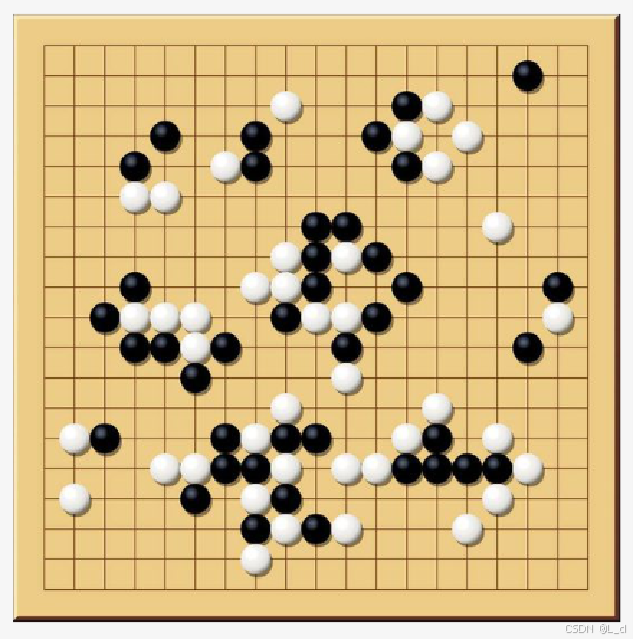
例:
以一个围棋智能体为例,围棋规则即是环境
状态(State): 当前的盘面即是一种状态
行动(Action): 接下来在棋盘中的下法是一种行动
奖励(Reward): 输赢是一种由环境给出的奖励,奖励随每个动作逐个传递
**奖励黑客(reward hacking):**在强化学习(RL)中,智能体通过利用奖励函数中的漏洞或模糊性来获得高奖励,而没有真正完成预期任务的行为。
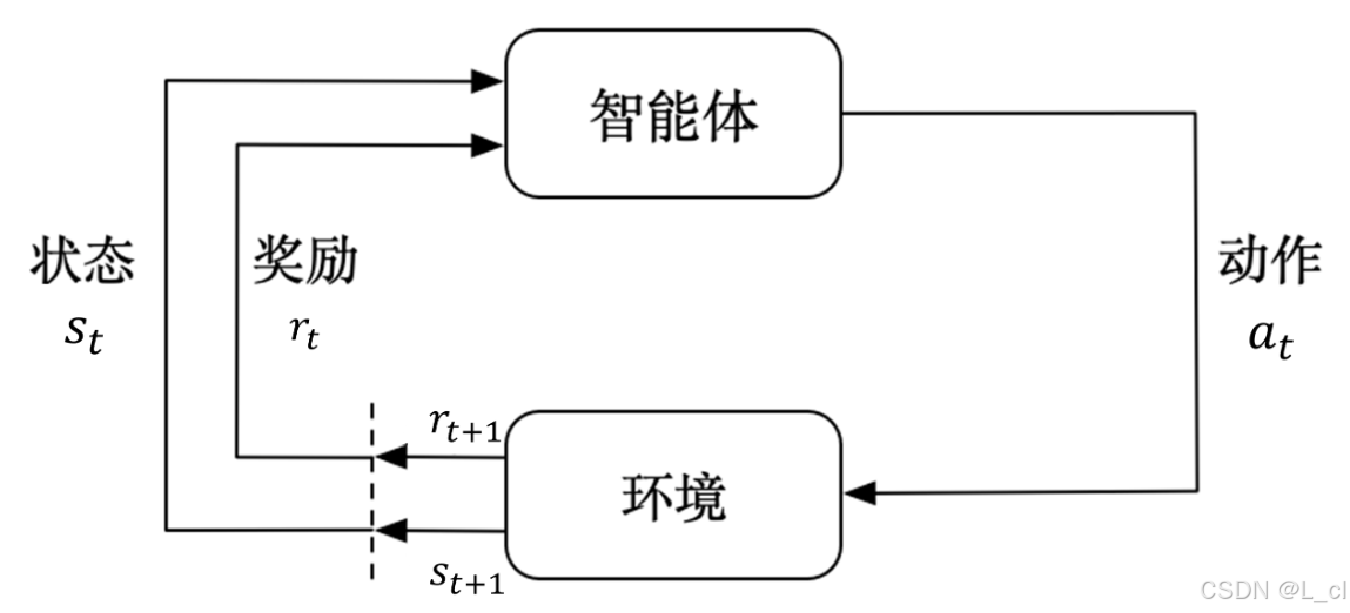
2.强化学习基础流程
智能体在状态 s_t 下,选择动作 a_t
环境根据动作 a_t 转移到新状态 s_t+1,并给出奖励 r_t
智能体根据奖励 r_t 和新状态 s_t+1 更新策略或价值函数
重复上述过程,直到达到终止条件
① 智能体与环境交互 :智能体(Agent) 在环境中执行动作(Action),环境 根据智能体的动作给出反馈,即奖励(Reward),并转移到新的状态(State)
② 状态感知与动作选择 :智能体 根据当前的状态 ,依据某种策略(Policy) 选择下一个动作 。策略可以是确定性的,也可以是随机的
③ 奖励反馈 :环境 根据智能 体的动作给予奖励,奖励可以是即时的,也可以是延迟的。智能体的目标 是最大化累积奖励
④ 策略更新 :智能体 根据获得的奖励 和新的状态 ,更新其策略 或价值函数(Value Function) ,以优化未来的决策
⑤ 循环迭代 :上述过程不断重复,智能体通过不断的试错和学习,逐步优化其策略,以达到最大化累积奖励的目标
强化学习的核心在于智能体通过与环境的交互,不断优化其策略,以实现长期奖励的最大化
2.策略(Policy)
智能体要学习的内容 ------ 策略(Policy): 用于根据当前状态,选择下一步的行动
以围棋来说,可以理解为在当前盘面下,下一步走每一格的概率
策略 π 是一个:输入状态(state) 和 输出动作(action) 的函数
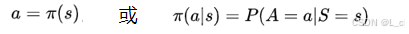
或者是一个:输入为状态+动作 ,输出为概率 的函数
有了策略之后,就可以不断在每个状态下,决定执行什么动作,进而进入下一个状态,依次类推完成整个任务
s1 -> a1 -> s2 -> a2 -> s3....基于前一个状态,产生下一个动作,这就是所谓的**"马尔可夫决策过程" 【MDP】**
强化学习有多种策略
3.价值函数(Value Function)【奖励】
智能体要学习的内容 ------ 价值函数(Value Function): 基于策略 π得到的函数,具体分为两种:
① 状态价值函数 V(s)
最终未来的收益
表示从状态 s开始,遵循策略 π 所能获得的长期累积奖励(r_t)的期望
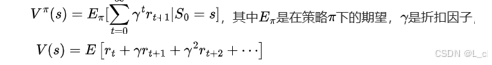
折扣因子 γ ∈ 0,1,反映对于未来奖励的重视程度,γ 越接近于1,表示模型越看重未来的奖励,γ 越接近于0,代表模型越看重当前的奖励
② 动作价值函数 Q(s, a)
下在某点时,未来的收益
表示在状态 s 下采取动作 a,遵循策略 π 所能获得的长期累积奖励的期望
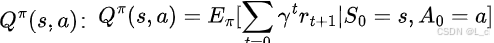
状态价值函数评估的是当前环境局面怎么样
动作价值函数评估的是当前环境下采取某一个动作收益会怎么样
二者关系: 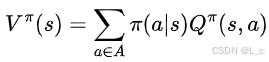
在每一个状态下,执行每个动作得到的奖励乘以执行每个动作的概率,再求和,就等于当前状态下的状态价值函数,也就是所谓的全概率公式
4.优势估计函数
优化目标 ------ 优势估计函数: 类似于损失函数Loss,但区别在于我们需要最大化这个值,表示在当前状态下我应该选取的最好的动作
A(s, a) = Q(s, a) - V(s)
动作价值函数Q和 状态价值函数V都是基于策略 π 的函数,所以整个函数也是一个基于策略 π 的函数
策略 π可以是一个神经网络,要优化这个网络的参数
训练过程中,通过最大化 优势估计函数 A(s,a),来更新策略网络的参数
也就是说优势估计函数的作用类似于loss函数 ,是一个优化目标,可以通过梯度反传(梯度上升)来优化
这是强化学习中的一种方法,一般称为策略梯度算法
策略梯度算法 是强化学习中与NLP任务最有关的方法
三、强化学习 与 NLP
将文本生成过程看作一个序列决策过程
状态(state) = 已经生成的部分文本
动作(action) = 选择下一个要生成的token
强化学习适用于NLP 中的 推理任务 和 泛模型
做某种任务最终结果进行推理 ,不在乎中间结果,对泛化性要求较高,适合使用强化学习
先输入一个提示词(当前的状态),然后输出接下来的词,重点在于设计奖励

四、PPO算法
1.定义
PPO(Proximal Policy Optimization,近端策略优化)是OpenAI于2017年提出的一种策略梯度算法,旨在改进传统策略梯度方法的训练稳定性。其核心思想是通过限制策略更新幅度,避免因步长过大导致的性能崩溃,同时平衡探索与利用
2.核心机制
① 剪切(Clipping) :通过截断新旧策略概率比(如设置阈值ε=0.2),限制策略突变。
② 重要性采样 :利用历史数据调整梯度权重,提升样本效率。
③ Actor-Critic框架 :策略网络(Actor)生成动作,价值网络(Critic)评估长期收益
3.训练目标
多阶段流程:奖励模型训练 → Critic网络预训练 → 策略迭代优化
动态优势估计 :通过Critic网络预测状态价值,计算TD误差
稳定性控制 :KL散度惩罚防止策略突变,熵奖励鼓励探索
4.核心公式
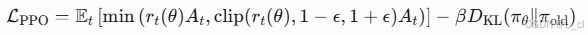
**r_t(θ) = π_θ(a_t | s_t)/ π_old(a_t | s_t):**策略更新比率
**A_t:**GAE(广义优势估计)
**ξ:**Clipping阈值(通常为0.1 ~ 0.2)
5.算法流程
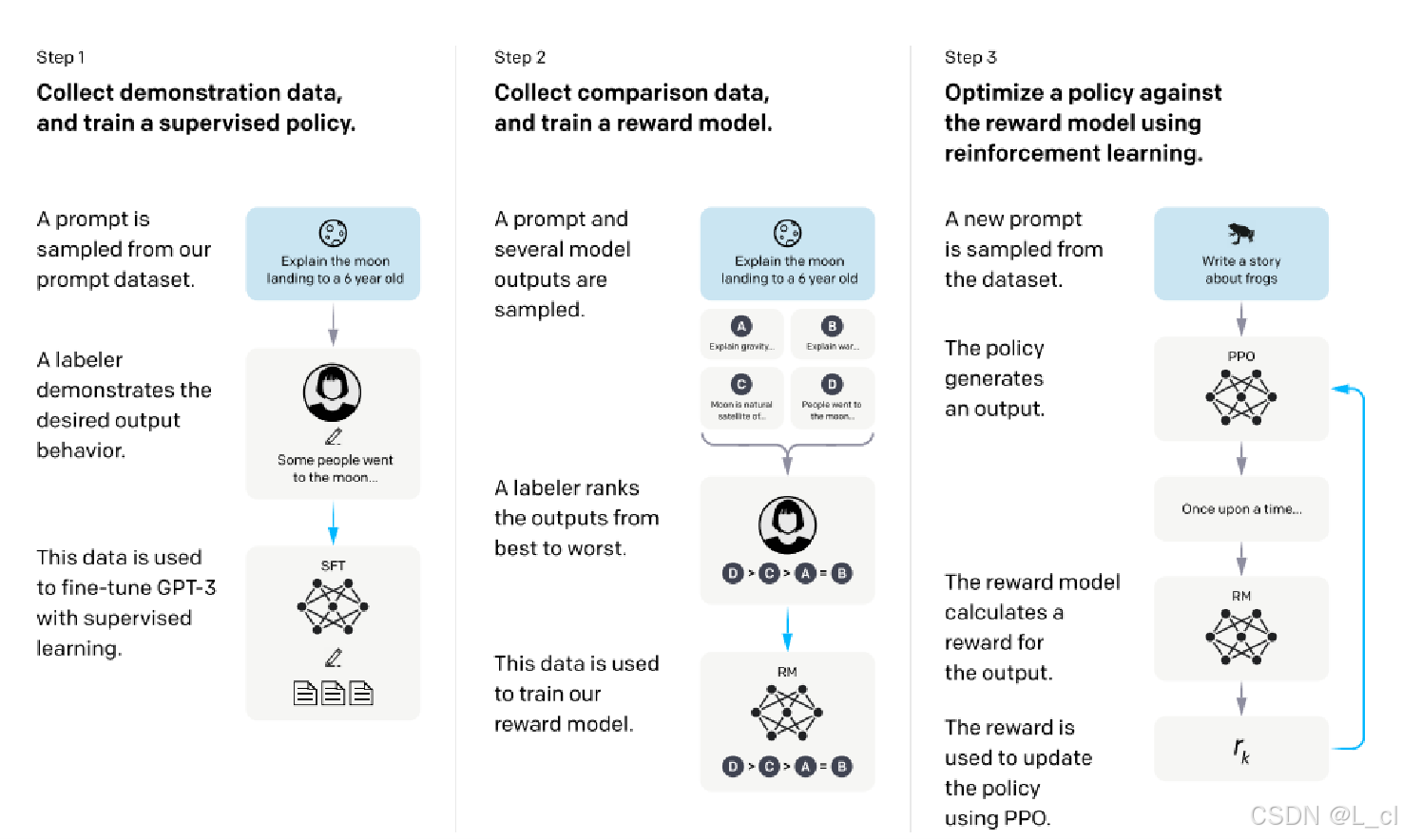
第一个阶段:SFT ,把模型从续写转换为问答,标准的有监督学习过程(收集数据,给一些提示词,由人来标注对应的希望的答案,让模型进行学习)
第二个阶段: 训练一个所谓的奖励模型(给一个提示词到若干个模型,若干个模型会输出若干个结果,然后有一个标注人员将这些结果按照优劣进行排序,然后用一个专门的模型按排序的顺序学习结果的优劣,来进行排序比较谁比谁好)
第三个阶段: 利用第二步训练的奖励模型函数policy,优化我们的语言模型,使用强化学习的方法(用一个新的提示词生成新的答案,计算其奖励数值,利用奖励模型计算奖励分数,然后用PPO算法优化选择的策略模型)
6.RW训练(奖励模型训练)
训练目标 :训练一个奖励模型(Reward Model),将人类偏好或环境反馈映射为标量奖励。
输入 :标注的偏好数据(如"答案A比答案B好")或环境交互数据。
作用:为RL训练提供奖励信号,指导策略优化。
对于一个输入问题,获取若干可能的答案,由人工进行排序打分,两两一组进行Reward Model训练
Ⅰ、奖励公式
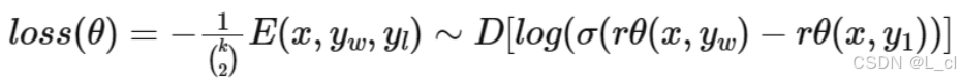
**x:**问题(prompt)
y_w: 相对好的答案
y_l: 相对差的答案
rθ: 一个交互式文本匹配模型,输入为一个问答对(x,y),输出为标量(0 ~ 1),输出的 rθ分数 越接近于0,答案越不好;输出的 rθ分数 越接近于1,答案越好;rθ 也就是强化学习中的奖励模型
Ⅱ、如何判断是否是一个好的答案:
最大化 rθ(x, y_w) - rθ(x, y_l) 作为训练目标,最小化 -rθ(x, y_w) - rθ(x, y_l) 作为loss损失
训练好的 rθ 分数 越接近于0,答案越不好;输出的 rθ分数 越接近于1,答案越好
示例: 
5.RL训练(强化学习训练)
目标:通过PPO算法优化策略模型(Actor),最大化累积奖励。
流程:
数据采样:当前策略生成交互数据(状态-动作-奖励)。
优势估计 :使用GAE(广义优势估计)计算动作长期收益。
策略更新 :通过剪切目标函数调整策略参数,限制KL散度。

RLHF训练目标
新旧两版模型,多关注二者的差异,少关注二者的共性

6.PPO加入约束


五、DPO算法
1.定义
DPO(Direct Preference Optimization,直接偏好优化)是一种替代PPO的轻量化RLHF(基于人类反馈的强化学习)方法,由斯坦福团队提出。其核心思想是跳过显式奖励模型训练reward model,直接利用偏好数据优化策略。
实际上DPO并不是严格意义上的强化学习,更适合叫对比学习
2.核心公式

**β:**温度系数,控制优化强度
**σ:**Sigmoid函数,将概率差映射为偏好得分
π_ref**:**参考策略(如SFT模型)
3.训练目标
单阶段优化 :直接利用偏好对数据**(y_w,y_l)**训练,无需独立奖励模型
策略对齐 :通过KL散度约束,确保新策略π_θ与参考策略π_ref不过度偏离
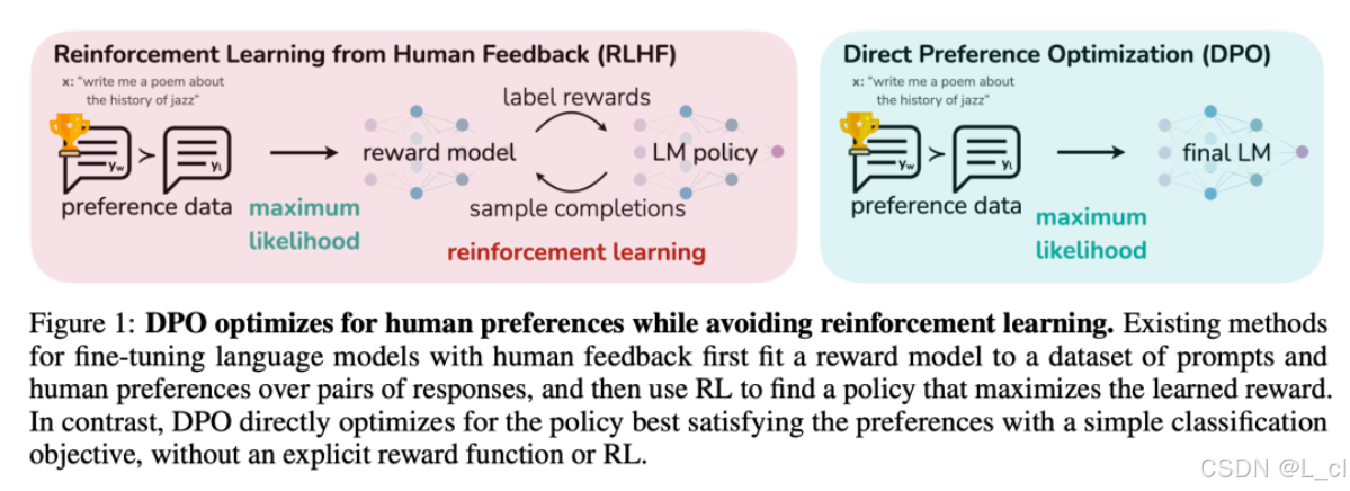
4.DPO 与 PPO的核心区别
| 维度 | PPO | DPO |
|---|---|---|
| 训练流程 | 需奖励模型(RM)+策略模型(Actor / Policy) | 仅策略模型Policy(直接优化偏好数据) |
| 数据依赖 | 环境交互数据 + 奖励模型标注 | 人类偏好对(无需奖励模型) |
| 计算复杂度 | 高(需多模型协同训练) | 低(单模型优化) |
| 适用场景 | 复杂任务(如游戏AI、机器人控制) | 对齐任务(如对话生成、文案优化) |
| 稳定性 | 依赖剪切机制和奖励模型设计 | 更稳定(避免奖励模型误差传递) |
| 多样性 | 支持多目标优化(如探索与利用) | 可能受限于偏好数据分布 |
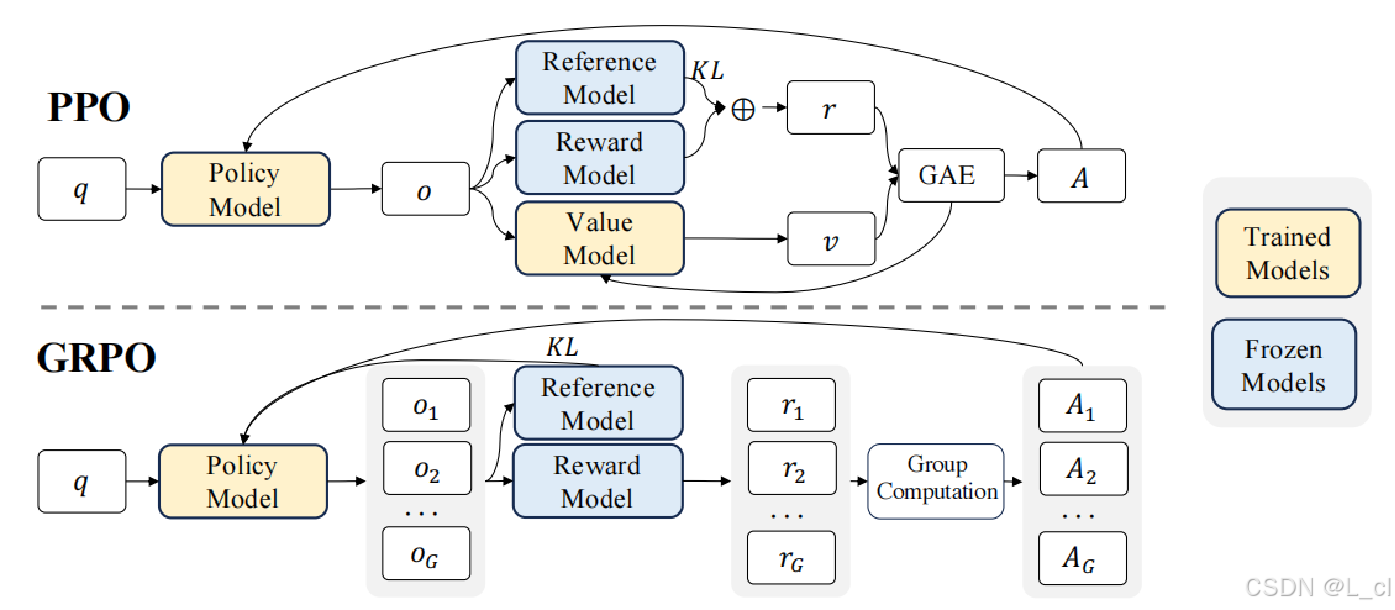
六、GRPO算法
1.定义
GRPO由DeepSeek提出,通过组内归一化优势估计替代Critic网络,核心优势在于:
多候选生成 :同一提示生成多个响应(如G=8),计算组内相对奖励
动态基线计算 :用组内均值和标准差归一化优势值,公式为:A_i = (r_i - μ_group) / σ_group****
资源优化 :省去Critic网络,显存占用降低50%
2.核心公式

3.PPO、GRPO算法目标对比
PPO算法: 追求绝对奖励最大化,通过剪切机制和KL约束平衡探索与利用,适合复杂动态环境;
GRPO算法: 聚焦组内相对优势优化,通过统计归一化和自对比降低计算成本,更适合资源受限的静态推理任务。
奖励(Reward model)可以是硬规则,如:
① 问题是否回答正确,正确为1,错误为0
② 生成代码是否可运行,可运行为1,不可运行为0
③ 回复格式是否符合要求,符合要求为1,不符合为0
④ 回复文本是否包含不同语种,不包含为1,包含为0
七、DeepSeek-R1

模型输出格式:
<think>
......
</think>
<answer>
......
</answer>
这种先输出一段think思考过程,再输出一段answer答案的模型现在我们称为Reasoning Model
如何得到R1模型
**第一步:**预训练 + SFT 得到DeepSeek - v3 - Base模型
**第二步:**通过一些带有长思维链的数据再做SFT
**第三步:**做强化学习得到R1模型
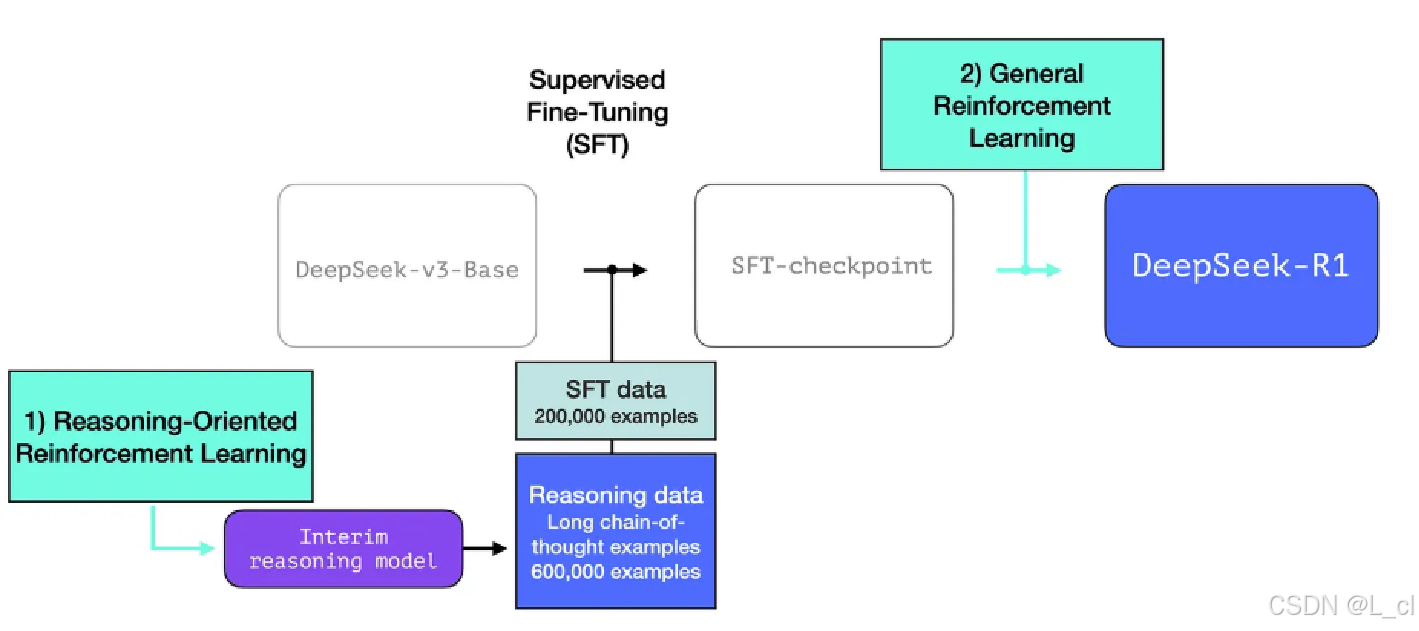
R1-zero
带有长思维链的数据从R1-zero模型训练得到
R1-zero: 使用一个预训练模型,不做SFT,直接使用GRPO,用规则替换奖励,再进行强化学习,在训练过程中模型就可以自发直接得到R1-zero,这个模型可以自然得到长的推理链
使用GRPO + 规则奖励,直接从基础模型(无sft)进行强化学习得到 模型在回复中会产生思维链,包含反思,验证等逻辑 虽然直接回答问题效果有缺陷,但是可以用于生成带思维链的训练数据