
1 特征工程的范式革命
传统机器学习:手工特征工程的艺术
在传统机器学习中,特征工程是一个关键步骤,它涉及将原始数据转化为能够被机器学习模型高效利用的特征。这通常需要领域专家的经验和知识,以手动设计和提取特征。
例如,在图像识别中,手工特征工程可能包括提取图像的边缘、纹理和形状等特征,以帮助模型更好地理解图像内容。在文本处理中,将文本转化为词频向量或TF-IDF向量等特征,使模型能够进行情感分析和文本分类等任务
java
// Java示例:传统特征提取(以文本处理为例)
public Map<String, Integer> extractFeatures(String text) {
// 手动实现词频统计、TF-IDF计算等
// 需要领域专家设计特征提取规则
}深度学习:端到端的特征学习

深度学习的兴起标志着特征工程的一次范式革命。深度学习模型,尤其是卷积神经网络(CNN)和循环神经网络(RNN),能够自动从原始数据中学习特征,而无需过多的人工干预。
例如,在图像识别领域,深度学习模型可以直接从像素数据中学习到高层次的特征表示,而无需手动提取边缘或纹理特征。这种端到端的学习方法不仅减轻了特征工程的负担,还提高了模型的性能和泛化能力
特征工程的范式革命
特征工程的范式革命体现在从手工特征提取到自动化特征学习的转变。这一革命不仅提高了模型的性能,还推动了人工智能技术的发展。随着自动特征工程工具和算法的发展,特征工程正变得更加自动化和智能化,为模型性能的提升提供了新的可能性
python
# Python示例:自动特征提取(使用Keras)
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(input_dim,)))2 模型能力的量变到质变
参数规模的指数级增长对比
在人工智能的发展历程中,模型参数规模的增长是一个显著的趋势。从早期的简单模型到现代的大型语言模型(LLM),参数数量从几百万增长到数千亿甚至万亿级别。这种指数级增长带来了模型能力的巨大提升,使得模型能够捕捉到更复杂的模式和关系。例如,GPT-3拥有1750亿参数,而最新的GPT-4参数规模更是达到了1.8万亿。这种参数规模的扩大不仅提高了模型的性能,还推动了人工智能技术的快速发展。
层次化特征抽象的实现原理
深度学习模型,尤其是卷积神经网络(CNN)和Transformer架构,通过多层的神经网络结构实现了层次化的特征抽象。在CNN中,每一层的神经元负责提取不同层次的特征,从简单的边缘和纹理到复杂的形状和对象。Transformer架构则通过自注意力机制,能够处理序列数据中的长距离依赖关系,并在每一层中提取不同层次的语义信息。这种层次化的特征抽象使得模型能够自动从原始数据中学习到有用的特征表示,而无需人工设计特征,大大提高了模型的泛化能力和适应性。

3 数据依赖性的根本差异
小数据场景下的表现对比
在小数据场景中,模型的性能和表现受到数据量的限制。小模型通常在小数据集上表现更好,因为它们需要较少的训练数据,能够更快地收敛,并且对数据的过拟合风险较低。
例如,在生物信息学中,TabPFN模型能够在样本量较少的数据集上实现高精度预测,其ROC AUC分数比传统方法(如CatBoost)提升了约18.7%,这得益于其对复杂数据分布的建模能力。
相比之下,大模型在小数据场景下可能会因为数据不足而难以充分发挥其潜力,甚至可能出现过拟合现象。
大数据时代的性能天花板
在大数据时代,大模型由于其庞大的参数规模和复杂的结构,能够处理大规模的数据集,并从中学习到更复杂的模式和关系。然而,随着数据量的不断增加,大模型也面临着性能天花板。
- 首先,大模型需要海量的数据来训练,这不仅增加了训练成本和时间,还对计算资源提出了极高的要求。
- 其次,大模型在处理大规模数据时可能会出现性能瓶颈,如训练速度慢、推理速度慢、能耗高等问题。
- 此外,大模型对数据的质量和分布变化非常敏感,数据的微小变化可能导致模型性能的大幅波动。
- 最后,大模型在某些任务上可能已经达到性能的极限,进一步提升性能需要更多的创新和突破。
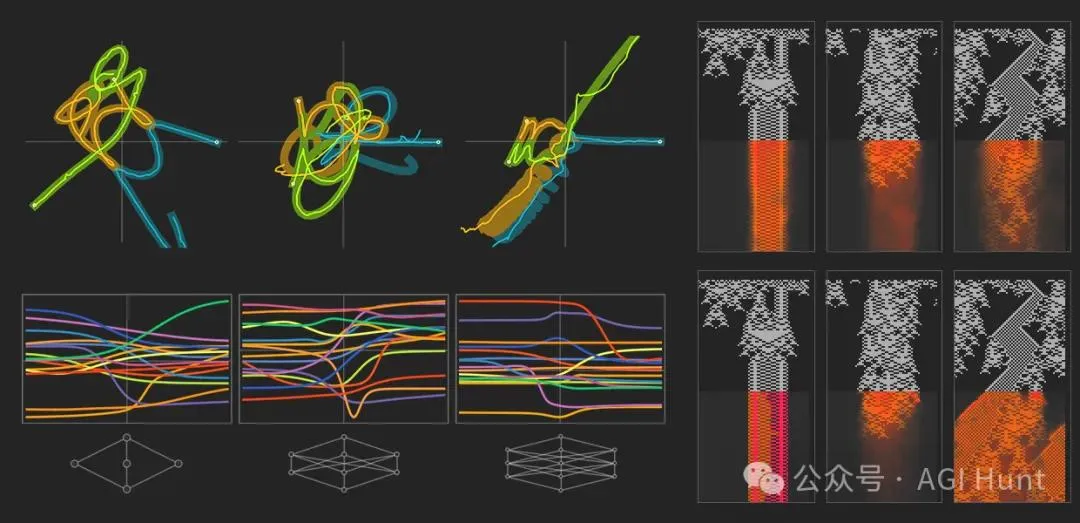
4 可解释性的哲学思考
决策树的可视化解读
决策树是一种易于理解和解释的机器学习模型,它通过树状结构表示决策过程和结果。每个节点代表一个特征的测试,每个分支代表测试的结果,而每个叶节点代表最终的决策或预测结果。决策树的可视化可以通过绘制树状图来实现,直观地展示数据是如何被分割和分类的。例如,通过可视化决策树,我们可以清楚地看到每个特征在决策过程中的作用,以及数据是如何根据这些特征被分配到不同的类别中的。
神经网络的黑箱困境

与决策树不同,神经网络,尤其是深度神经网络,通常被视为"黑箱"模型。这是因为它们的内部结构和决策过程非常复杂,难以直观理解。
神经网络由多层神经元组成,每一层的神经元都对输入数据进行复杂的非线性变换,最终输出预测结果。这种复杂性使得我们很难解释模型是如何从输入数据中提取特征并做出决策的。
可解释性技术的突破
尽管神经网络的黑箱特性带来了挑战,但近年来,可解释性技术的发展为突破这一困境提供了可能。
以下是一些常见的可解释性技术:
- 可视化技术:通过可视化神经网络的内部结构和数据流,我们可以更直观地理解模型的行为。例如,可以可视化卷积神经网络中的特征图,展示模型在不同层次上是如何提取图像特征的。
- 特征重要性分析:通过分析输入特征对模型输出的影响,我们可以了解哪些特征对模型的决策最为关键。例如,在电商推荐系统中,通过特征重要性分析可以了解用户浏览历史、购买记录等特征对商品推荐结果的贡献。
- 基于规则提取的方法:从复杂模型中提取易于理解的规则。例如,从神经网络中提取"如果-那么"形式的规则,帮助人们理解模型的决策逻辑。
哲学思考
可解释性不仅是技术问题,也是一个哲学问题。它涉及到我们对知识、理解和信任的定义。在某些领域,如医疗和金融,模型的可解释性至关重要,因为这些领域的决策往往涉及重大风险。例如,在医疗诊断中,医生需要理解AI模型的决策依据,以便在必要时进行干预。
未来展望
随着技术的不断进步,可解释性技术将继续发展和改进。未来的研究方向可能包括开发更先进的可视化工具、改进特征重要性分析方法,以及探索新的模型架构,以提高模型的透明度和可解释性。同时,我们也需要在技术发展和实际应用之间找到平衡,确保可解释性技术能够真正满足不同领域的需求。
总之,可解释性是人工智能发展中的一个重要课题。通过不断探索和创新,我们可以逐步揭开神经网络的"黑箱",使其决策过程更加透明和可信。这不仅有助于提高模型的性能和可靠性,也为人工智能在更多领域的应用奠定了基础。