引言
2025年4月,Meta正式发布了全新的Llama 4系列模型,这标志着Llama生态系统进入了一个全新的时代。Llama 4不仅是Meta首个原生多模态模型,还采用了混合专家(MoE)架构,并提供了前所未有的上下文长度支持。本文将详细介绍Llama 4的主要特性、技术创新以及社区对这次更新的相关评测结果,帮助您全面了解这一AI领域的重大突破。
Llama 4系列模型概览

Meta此次推出了Llama 4系列的三个主要模型:
-
Llama 4 Scout:拥有17B活跃参数和16个专家,总参数量为109B。它是同类中最佳的多模态模型,可以在单个NVIDIA H100 GPU上运行,并提供业界领先的1000万token上下文窗口。
-
Llama 4 Maverick:拥有17B活跃参数和128个专家,总参数量为400B。它在多项广泛报告的基准测试中击败了GPT-4o和Gemini 2.0 Flash,同时在推理和编码方面与新的DeepSeek v3取得了相当的结果,但活跃参数不到后者的一半。
-
Llama 4 Behemoth:拥有288B活跃参数和16个专家,总参数量接近2万亿。作为Meta最强大的LLM,它在多项STEM基准测试中优于GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro。目前该模型仍在训练中,尚未公开发布。
值得注意的是,虽然Llama 4 Maverick的总参数量为400B,但在处理每个token时,实际参与计算的"活跃参数"始终是17B。这大大降低了推理和训练的延迟。
技术创新与突破
混合专家(MoE)架构:效率与性能的完美平衡
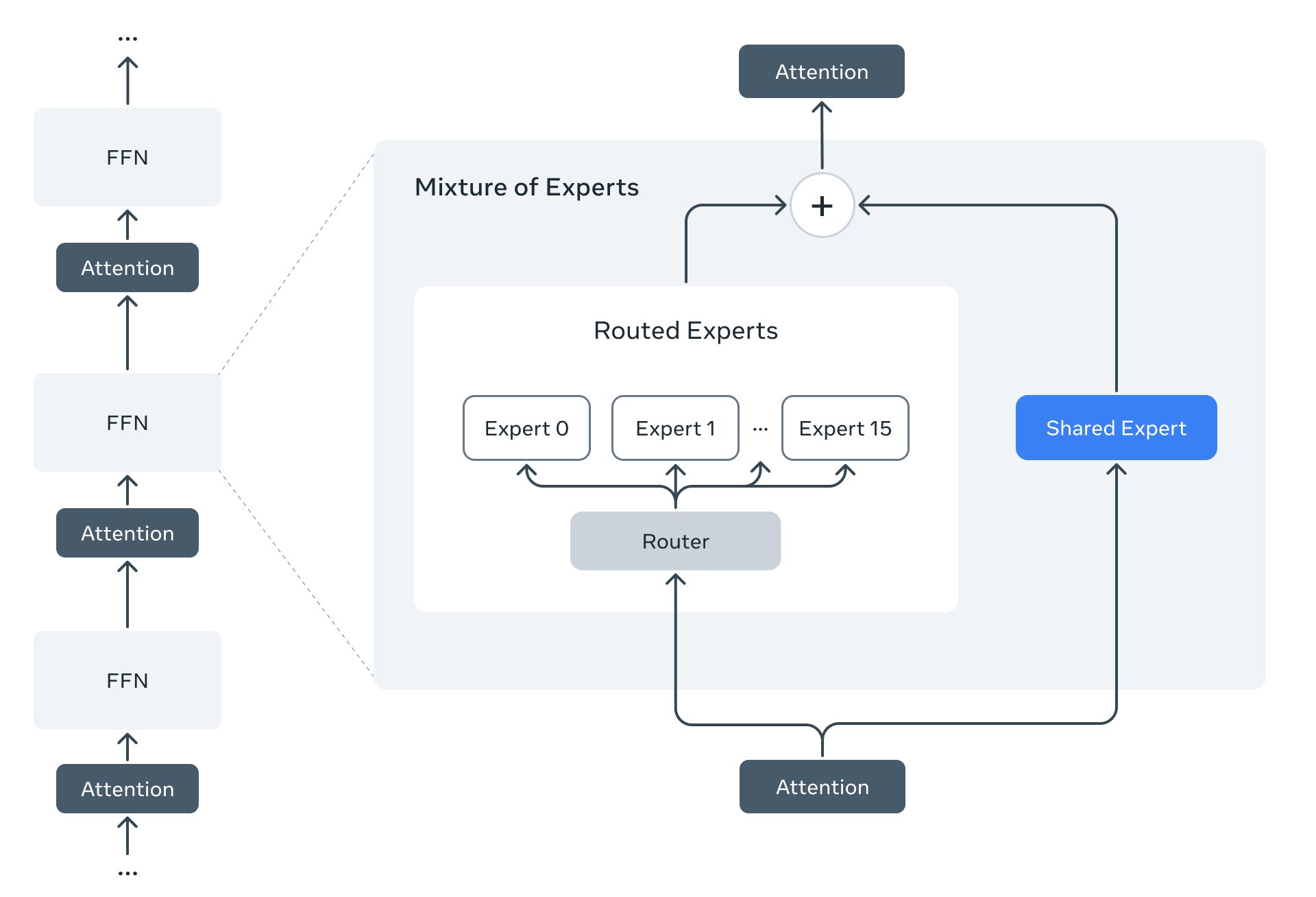
Llama 4是Meta首次使用混合专家(MoE)架构的模型。在MoE模型中,单个token只激活总参数的一小部分。这种架构在训练和推理方面更加计算高效,与固定训练FLOP预算相比,能够提供更高的质量。
例如,Llama 4 Maverick模型有17B活跃参数和400B总参数。它使用交替的密集层和混合专家(MoE)层来提高推理效率。MoE层使用128个路由专家和一个共享专家。每个token都会被发送到共享专家和128个路由专家中的一个。因此,虽然所有参数都存储在内存中,但在提供这些模型服务时,只有一部分总参数被激活。
原生多模态能力:视觉与文本的无缝融合
Llama 4模型设计具有原生多模态性,通过早期融合将文本和视觉token无缝集成到统一的模型主干中。早期融合是一个重大进步,因为它使模型能够用大量未标记的文本、图像和视频数据联合预训练。
这些模型在各种图像和视频帧上进行了训练,以提供广泛的视觉理解能力,包括时间活动和相关图像。这使得模型能够轻松处理多图像输入和文本提示,用于视觉推理和理解任务。模型在预训练阶段支持多达48张图像,并在后训练阶段测试中显示出良好的结果,最多支持8张图像。
超长上下文支持:突破性的1000万token容量
Llama 4 Scout将支持的上下文长度从Llama 3的128K大幅增加到业界领先的1000万token。这开启了许多可能性,包括:
- 多文档摘要生成
- 解析大量用户活动进行个性化任务
- 对庞大代码库的深度推理
- 长文本理解与分析
技术实现:Llama 4 Scout在预训练和后训练阶段都使用了256K上下文长度,这使基础模型具备了先进的长度泛化能力。Llama 4架构的一个关键创新是使用交替注意力层(无位置嵌入)。此外,还采用了推理时间注意力温度缩放来增强长度泛化。这种架构被称为iRoPE,其中"i"代表"交替"注意力层,突出了支持"无限"上下文长度的长期目标,而"RoPE"指的是大多数层中使用的旋转位置嵌入。
训练方法与优化
预训练创新:MetaP超参数设置技术
Meta开发了一种新的训练技术,称为MetaP,它允许可靠地设置关键模型超参数,如每层学习率和初始化比例。这些超参数在不同的批量大小、模型宽度、深度和训练token上都能很好地迁移。
Llama 4通过在200种语言上进行预训练来支持开源微调工作,其中超过100种语言的token超过10亿个,总体上比Llama 3多10倍的多语言token。
此外,Meta还专注于高效的模型训练,使用FP8精度,同时不牺牲质量并确保高模型FLOP利用率。在使用FP8和32K GPU预训练Llama 4 Behemoth模型时,每个GPU达到了390 TFLOP。总体数据混合训练包含超过30万亿个token,是Llama 3预训练混合的两倍多,包括多样化的文本、图像和视频数据集。
后训练优化:创新的三阶段训练流程
Meta为Llama 4 Maverick模型采用了全新的后训练流程:
- 轻量级监督微调(SFT)
- 在线强化学习(RL)
- 轻量级直接偏好优化(DPO)
关键发现:SFT和DPO可能会过度约束模型,限制在线RL阶段的探索,导致次优精度,特别是在推理、编码和数学领域。
解决方案:Meta通过使用Llama模型作为评判标准,移除了超过50%被标记为"简单"的数据,并对剩余的更难数据集进行轻量级SFT。在随后的多模态在线RL阶段,通过仔细选择更难的提示,实现了性能的大幅提升。
模型评测与性能对比
Llama 4系列官方评测结果
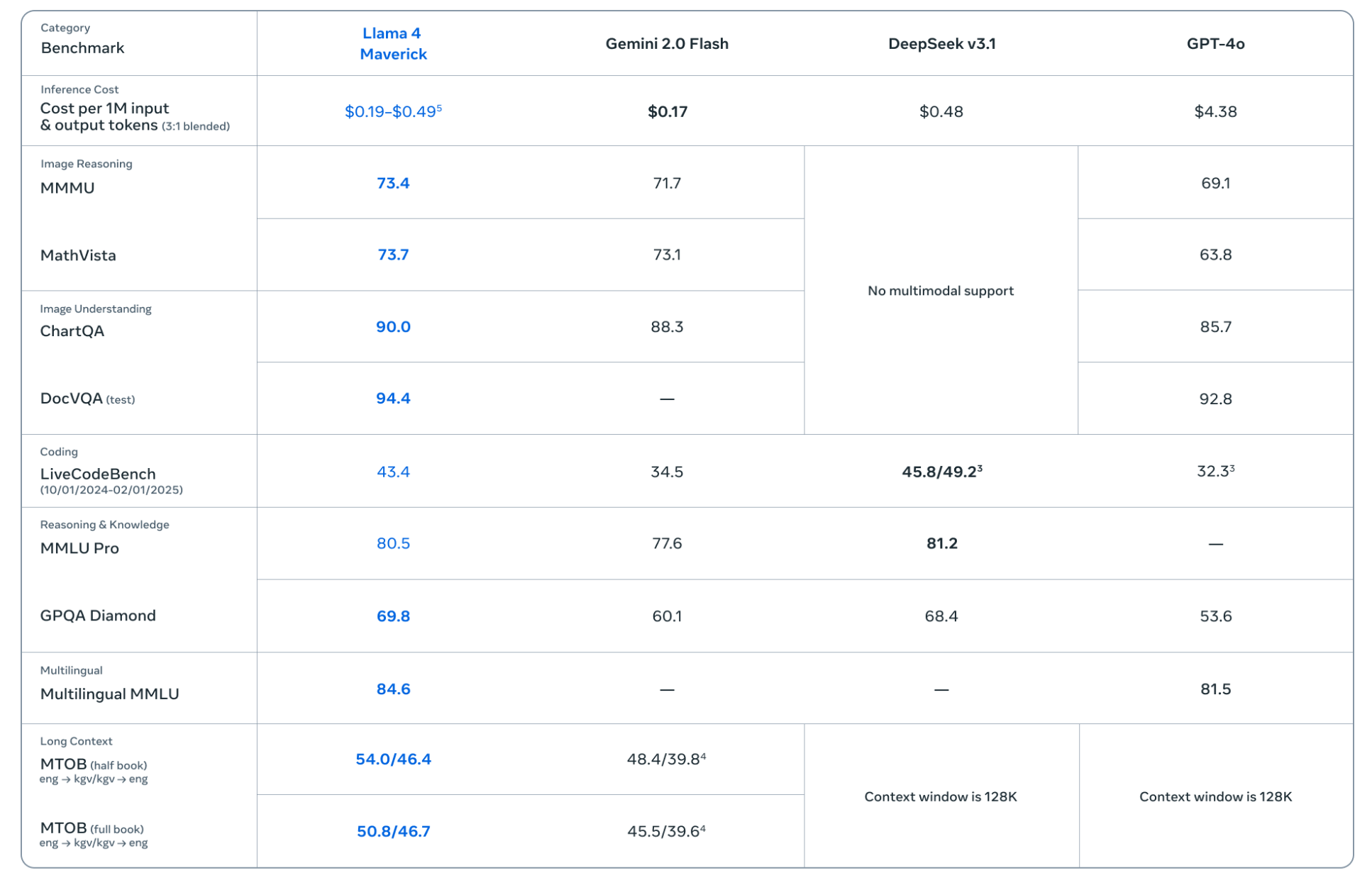
从Meta官方给出的评测结果可以看出,Llama 4 Maverick主要是全面对标GPT-4o和Gemini 2.0 Flash,同时作为开源模型,也与DeepSeek v3进行了对比。
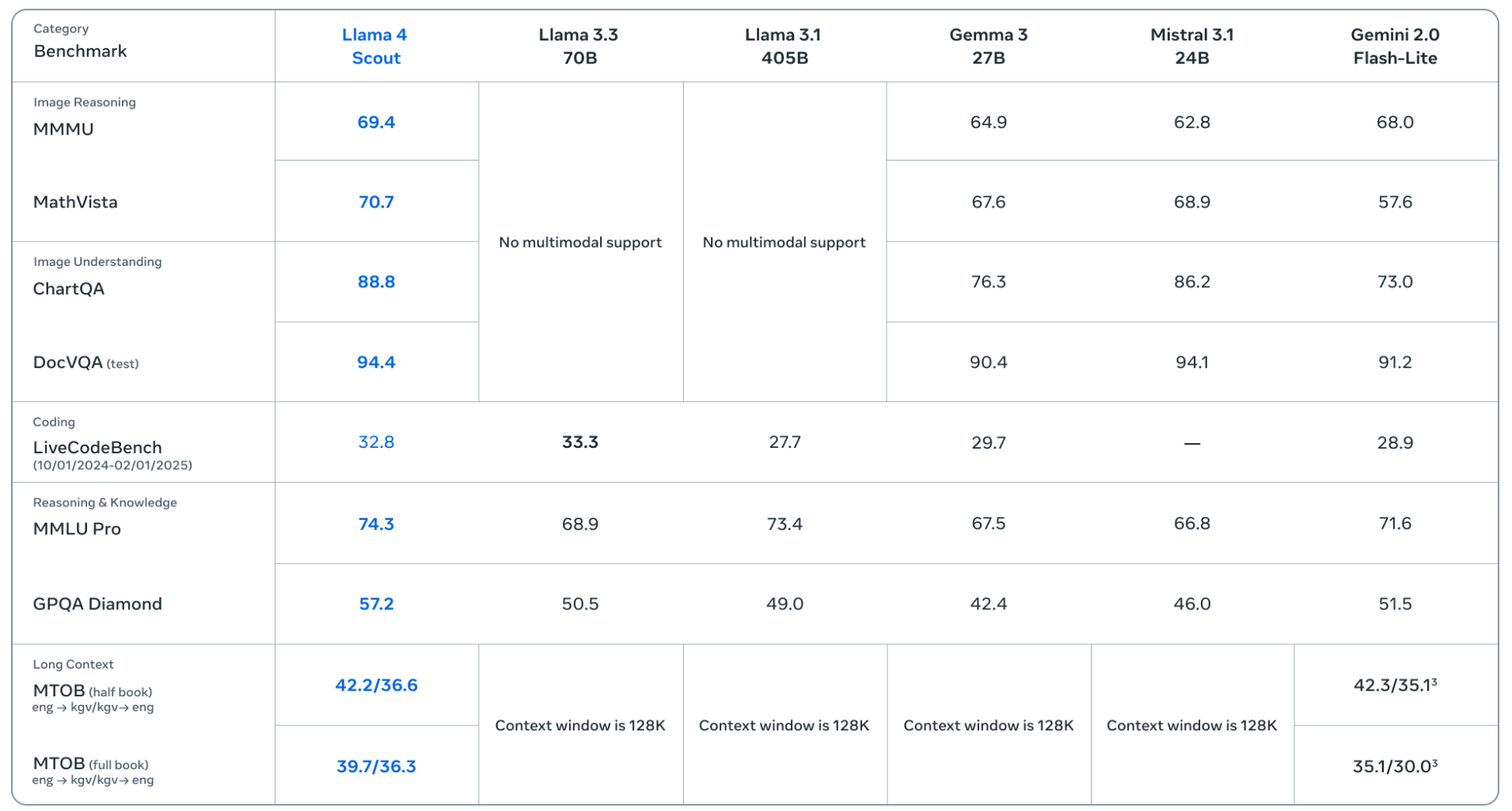
而Llama 4 Scout则主要对标轻量级的模型,比如Gemma 3、Gemini 2.0 Flash-Lite等。
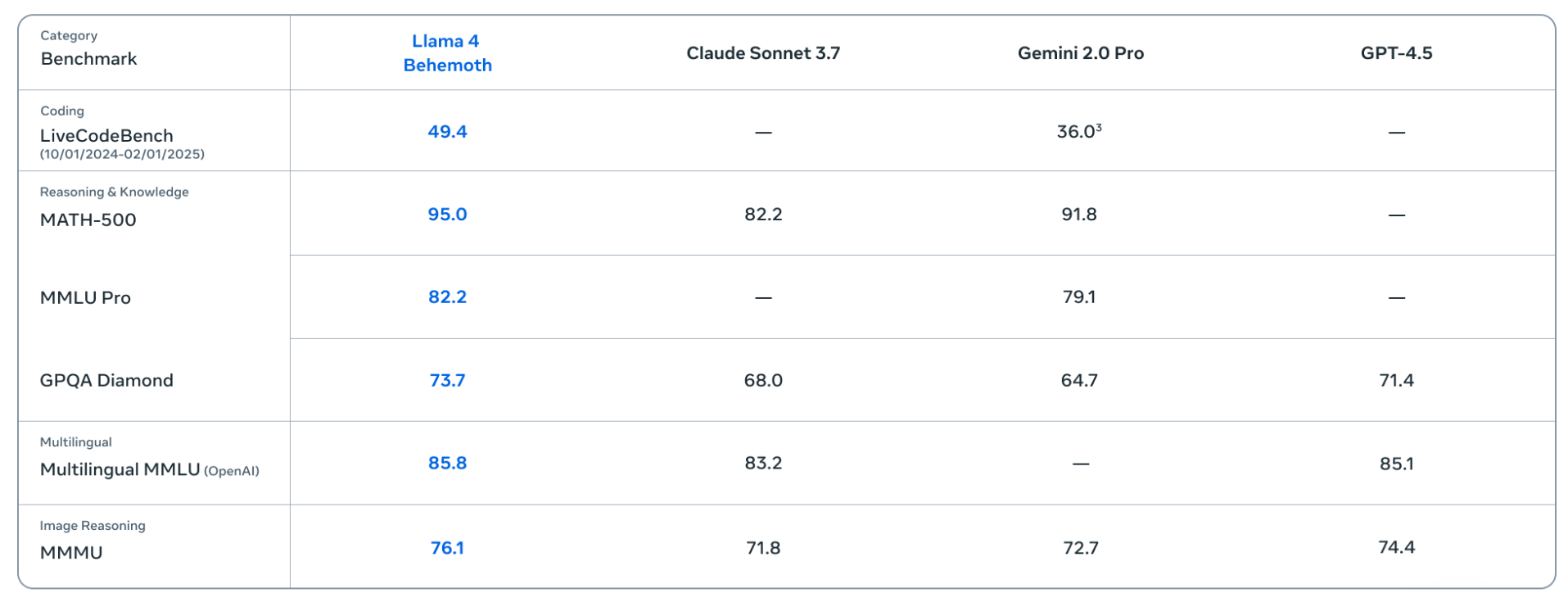
尚未发布的最强模型Llama 4 Behemoth,从数据上显著优于Claude 3.7 Sonnet和Gemini 2.0 Pro。
社区独立评测结果
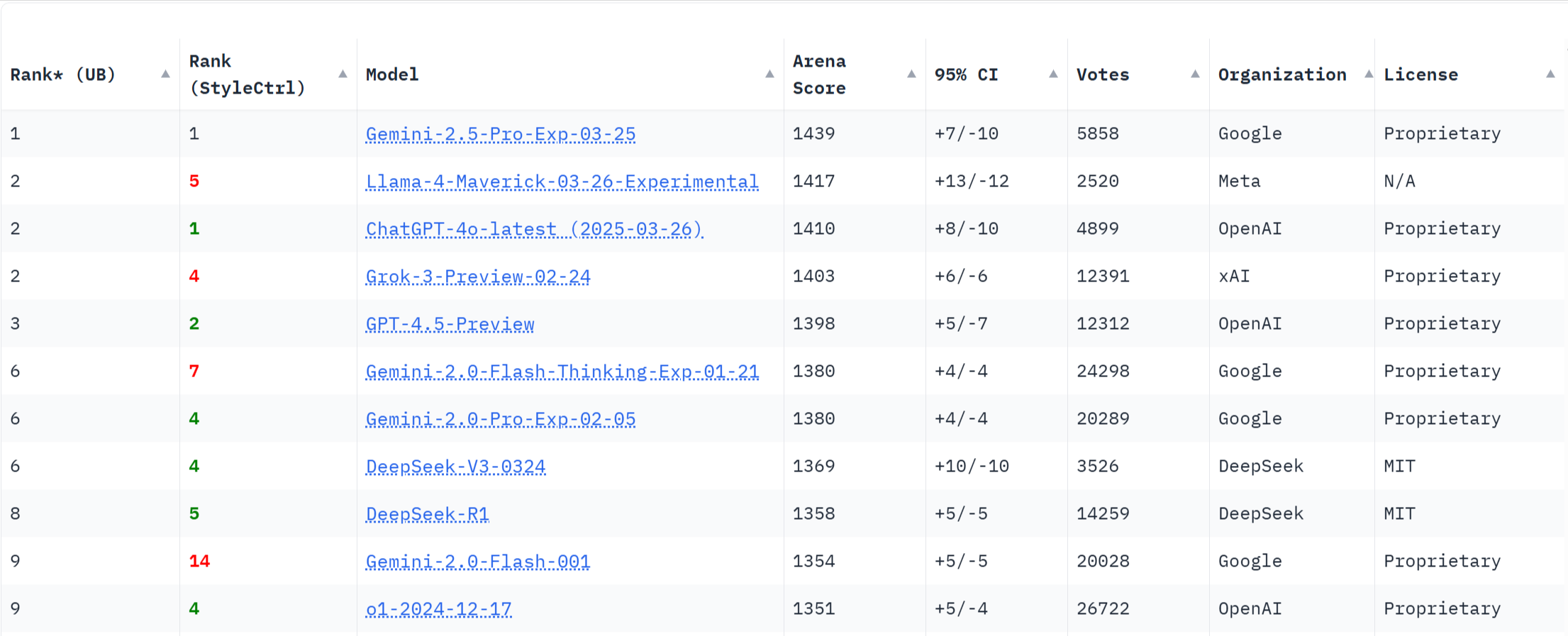
官方评测自然只是一家之言,社区评测则更为客观。以下是来自LMArena的评测结果,可以看到,Llama 4 Maverick仅次于Google刚发布不久的Gemini-2.5-Pro,位居第二。
编码能力与Agent能力评测
对于AI研究者和开发者来说,编码能力和Agent能力是评判大语言模型实用性的重要指标。
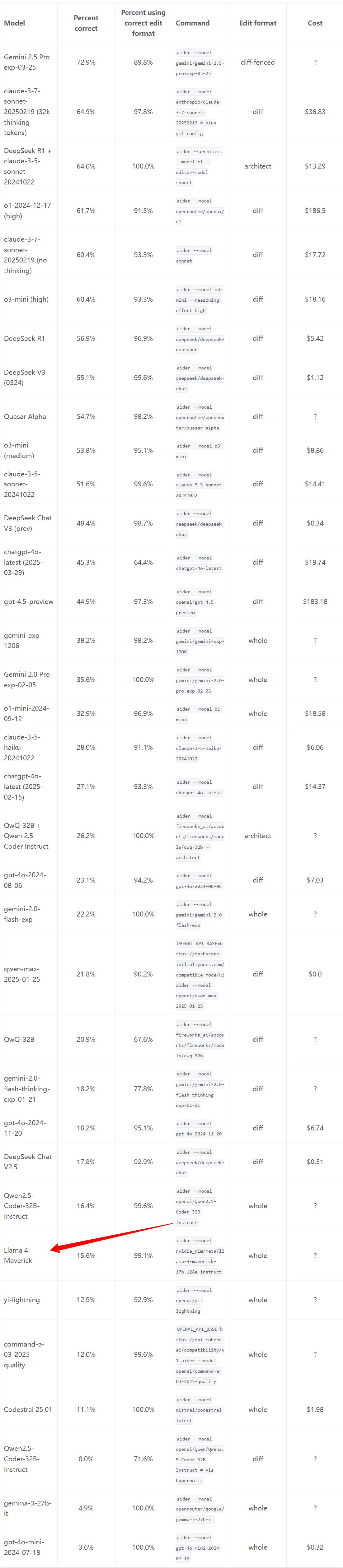
编码能力评测:从Aider Polyglot leaderboard的结果来看,即使是Llama 4 Maverick,在编码能力上也排名相当靠后,基本就是DeepSeeK V2.5的水平,这与预期有一定差距。
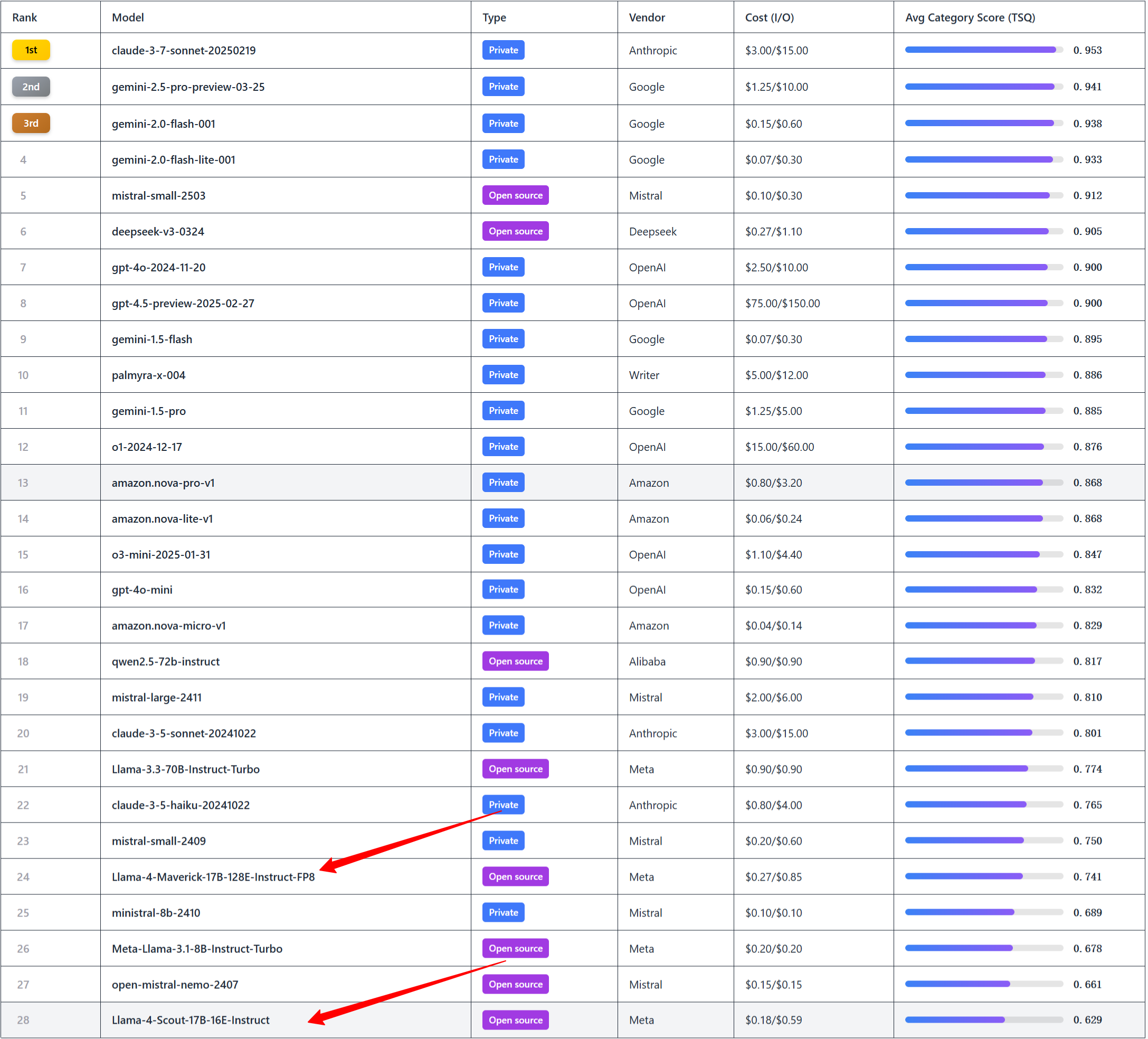
Agent能力评测:在huggingface agent leaderboard中,Llama 4 Maverick甚至连前20都排不进去。不仅与商业模型相比有差距,就是与开源的Qwen和DeepSeek相比,也略显不足,甚至不如自家上一代的Llama-3.3,这一点令人意外。
这两项特别关键的评测中,Llama 4的表现都不尽如人意,期待官方之后能继续优化或对测试结果做出合理解释。
总结
总体来说,Llama 4系列模型在技术上实现了多项创新:
- 首次采用MoE架构,大幅提升计算效率
- 原生多模态能力,实现文本与视觉的深度融合
- 突破性的1000万token超长上下文支持
- 创新的训练方法与优化技术
然而,在实际社区评测中,特别是在编码能力和Agent能力方面,Llama 4系列的表现还有待提高。作为Meta新一代的开源模型,Llama 4理应在各方面取得更好的评测结果,但目前看来,距离预期还有一定差距。
应用前景:作为问答模型,Llama 4表现尚可,但作为智能体的大脑,还需进一步优化。目前的表现似乎更适合考试场景,而非实战应用,暂时还未能进入我的AI智能体大脑候选列表。