新用户可获得高达 200 美元的服务抵扣金
亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
在信息密度越来越高的今天,我们每天接触的文字量远超以往。但眼睛和手始终是有限的资源------开车时、运动时、做饭时,想看一篇长文几乎是不可能的。如果这些文字能直接"说"出来,我们就能用耳朵接收信息,释放眼睛和双手的负担。这正是文本转语音(Text-to-Speech, TTS)技术的意义所在,而 Amazon Polly 则是这一领域中最易上手、功能完善的云端服务之一。【权益传送门】
Amazon Polly 的工作原理
早期的 TTS 技术,更多是基于规则或拼接的合成------把录好的音素按顺序拼成句子,听感往往机械、生硬。后来有了统计参数合成(HMM),虽然在流畅度上有所提升,但音色依旧缺乏自然情感。深度学习的出现,尤其是 WaveNet、Tacotron 等神经网络架构的普及,让机器合成语音在音质、节奏、情感表现上都接近真人。这也是 Amazon Polly 得以"听起来像人"的技术基础。
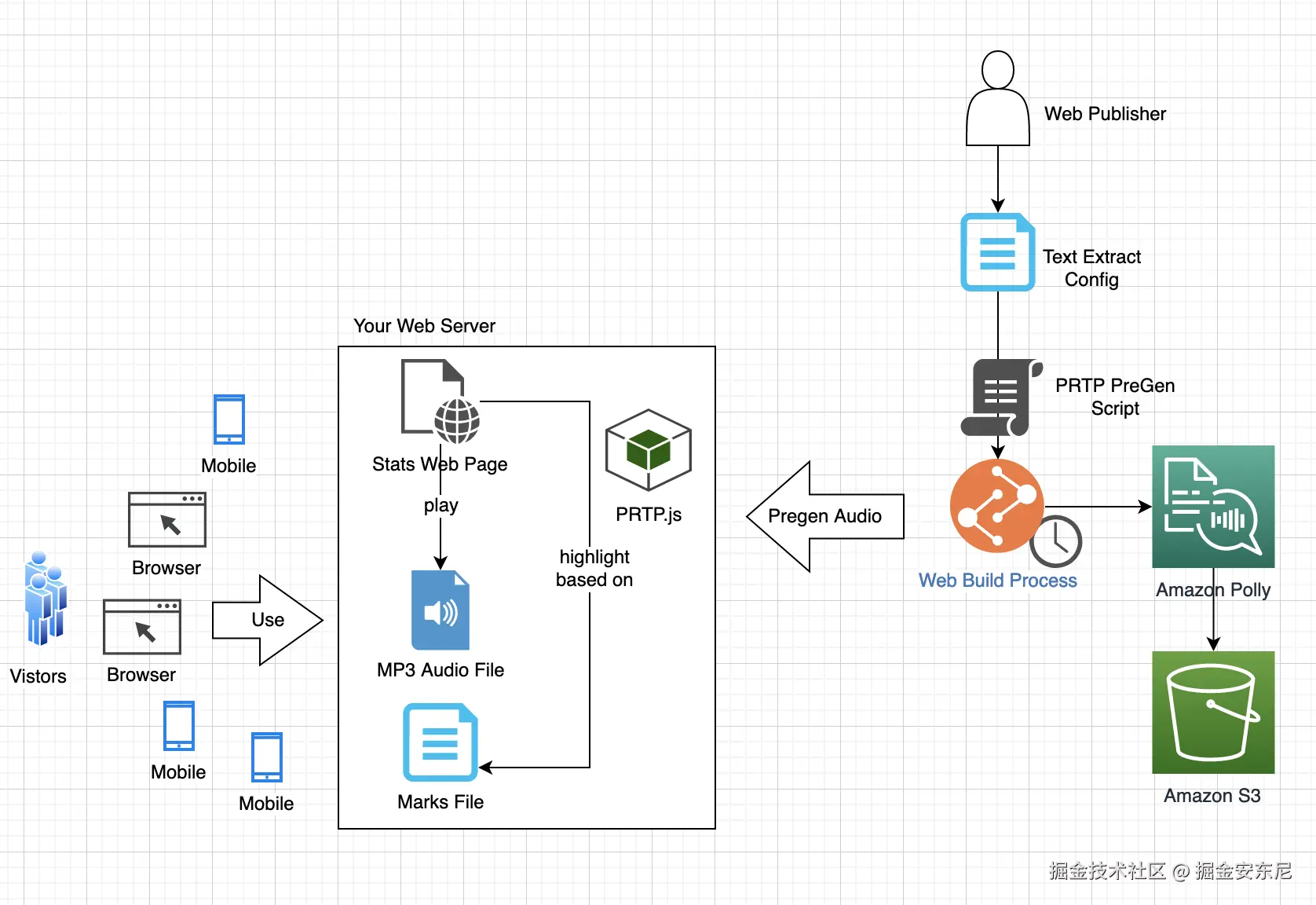
与自建模型相比,云端 TTS 最大的优势是免去了语音数据采集、模型训练和推理部署的复杂工作。对大多数开发者而言,直接调用 API 获取音频,既能保证效果,又能大幅缩短开发周期。Amazon Polly 的定位,就是提供一个完全托管、即开即用的语音生成平台,覆盖几十种语言、数百种声音,支持参数化控制语速、音调、音量,甚至耳语模式。
无论多先进的 TTS,本质上都是两步走:提取特征 和生成音频。
Polly 在接收到文本后,首先会对输入进行语言学分析------分词、词性标注、重音定位、音节划分等。这些信息会被映射到时间轴上,生成一组时间对齐的声学特征,比如梅尔频谱图(Mel Spectrogram)用于刻画频率随时间的变化,F0 基频表示音高变化。这一步的准确性决定了语音的自然程度。
接着,Polly 会将这些特征送入深度神经网络(通常是基于 Tacotron 变体和神经声码器的架构)进行波形合成。这是"把乐谱变成声音"的过程------网络会根据频谱预测连续的波形样本,最终输出逼真的音频流。由于整个过程在云端完成,延迟极低,几乎可以实现实时合成,这对直播、游戏解说等场景尤为重要。
用声音赋能更多场景
虽然 TTS 最直观的用途是朗读文字,但在不同的业务中,它的作用各不相同。
在在线教育中,Polly 可以自动为课文配音,让语言学习者听到标准发音,也能在听力训练中提供可调语速的素材。对视障用户而言,TTS 更是让他们能平等获取数字内容的关键工具。
在媒体与出版领域,传统有声书制作需要录音棚和配音演员,而 Polly 允许将文章、书籍批量转换成多语言音频,大幅降低成本并加快上架速度。新闻网站甚至可以在发布文章的同时生成音频版本,提升用户停留时间。
在客户服务 和智能助理中,Polly 的自然语音输出能够让交互更具亲和力。呼叫中心可以用它来动态播报个性化内容,比如订单状态、账户信息,而不是重复单调的录音。
在游戏与沉浸式体验中,Polly 能根据玩家行为即时生成对白和解说,让 NPC 真正"活"起来。结合 VR 环境,还能打造沉浸感极强的语音引导。
代码实践:用 Python 接入 Amazon Polly
理论再好,也得落到代码上。Amazon Polly 的 API 非常直观,下面我们用 Python 演示一次完整的调用过程,并解释其中的关键点。
首先需要安装 Amazon SDK for Python(boto3):
pip install boto3然后编写调用代码:
ini
import boto3
# 创建 Polly 客户端
polly = boto3.client(
'polly',
region_name='us-east-1', # 选择离用户最近的区域
aws_access_key_id='YOUR_AWS_ACCESS_KEY',
aws_secret_access_key='YOUR_AWS_SECRET_KEY'
)
# 要转换的文本
text = "你好,欢迎使用 Amazon Polly。这是一段中文合成语音的示例。"
# 调用 TTS
response = polly.synthesize_speech(
Text=text,
OutputFormat='mp3', # 支持 mp3、ogg_vorbis、pcm
VoiceId='Zhiyu', # 中文女声,可改为其他语言和声音
Engine='neural' # 使用神经网络引擎,效果更自然
)
# 保存音频文件
with open('output.mp3', 'wb') as f:
f.write(response['AudioStream'].read())
print("音频已生成:output.mp3")这里有几个细节值得注意:
- Engine 参数 :
standard和neural两种模式,后者音质更自然,但可能价格略高。 - VoiceId :不同语言有不同的可选声音,可以通过
describe_voices()方法列出。 - 缓存策略:对相同文本的重复合成,可以本地缓存音频,减少请求次数。
Web 实时朗读示例
如果想在网页中让用户直接点击按钮播放 Polly 的语音,可以用前端 JavaScript 配合后端 API 实现。后端负责调用 Polly 并返回音频 URL,前端直接用 <audio> 标签播放。
前端示例(假设后端已提供 /tts 接口):
xml
<button onclick="playTTS()">朗读</button>
<audio id="player" controls></audio>
<script>
async function playTTS() {
const res = await fetch('/tts?text=欢迎访问我们的网站');
const blob = await res.blob();
const url = URL.createObjectURL(blob);
document.getElementById('player').src = url;
document.getElementById('player').play();
}
</script>这样,用户体验就是输入文字 → 点击按钮 → 听到声音,延迟在网络条件良好的情况下几乎感受不到。
开发经验与优化建议
使用 Polly 时,有几点经验值得参考。首先,选择合适的 VoiceId 很关键,比如中文有"Zhiyu"偏柔和,"ZhiyuNeural"更自然;英文有多种口音可选,适合国际化应用。其次,多语言应用应提前规划文本编码与语言标记,避免合成时发音错误。另外,在移动端播放音频要注意兼容性,有些浏览器需要用户交互才能自动播放。
我认为,TTS 正在从"朗读工具"向"语音交互接口"演化。未来的 Polly 很可能不仅生成声音,还能动态调整语气、情绪,甚至根据对话上下文改变表达方式。个性化语音克隆技术的成熟,也会让品牌拥有专属"声音形象",像 Logo 一样成为识别符。
在这个趋势下,越早将 TTS 融入产品,就越能积累语音交互的设计经验。无论是教育、媒体,还是物联网与虚拟世界,声音都可能成为下一代交互的核心入口。而 Amazon Polly 这样的云端方案,正好帮我们用最少的代价先跑起来。
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~