什么是火山模型
火山模型作为数据库领域内一个已相当成熟的计算模型,其核心思想是将关系代数中的每一种操作映射为一个独立的Operator,进而将整个SQL查询过程构建成一个Operator树结构。这一模型通过从根节点开始,逐级向下至叶子节点,递归调用next()函数。
例如 SQL:
SELECT Id, Name, Age, (Age - 30) * 50 AS Bonus
FROM People
WHERE Age > 30对应火山模型如下:
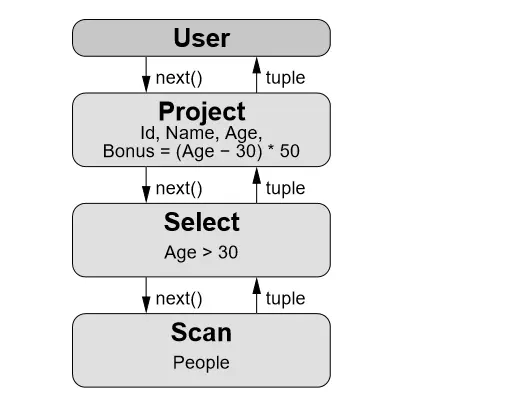
其中------
User:客户端;
Project:垂直分割(投影),选择字段;
Select(或 Filter):水平分割(选择),用于过滤行,也称为谓词;
Scan:扫描数据。
这里包含了 3 个 Operator,首先 User 调用最上方的 Operator(Project)希望得到 next tuple,Project 调用子节点(Select),而 Select 又调用子节点(Scan),Scan 获得表中的 tuple 返回给 Select,Select 会检查是否满足过滤条件,如果满足则返回给 Project,如果不满足则请求 Scan 获取 next tuple。Project 会对每一个 tuple 选择需要的字段或者计算新字段并返回新的 tuple 给 User。当 Scan 发现没有数据可以获取时,则返回一个结束标记告诉上游已结束。
为了更好地理解一个 Operator 中发生了什么,下面通过伪代码来理解 Select Operator:
Tuple Select::next() {
while (true) {
Tuple candidate = child->next(); // 从子节点中获取 next tuple
if (candidate == EndOfStream) // 是否得到结束标记
return EndOfStream;
if (condition->check(candidate)) // 是否满足过滤条件
return candidate; // 返回 tuple
}
}火山模型的优缺点
可以看出火山模型的优点在于:简单,每个 Operator 可以单独抽象实现、不需要关心其他 Operator 的逻辑。
那么缺点呢?也够明显吧?每次都是计算一个 tuple(Tuple-at-a-time),这样会造成多次调用 next ,也就是造成大量的虚函数调用,这样会造成 CPU 的利用率不高。
知识点补习------虚函数
C++ 中用 virtual 标记的函数,而在 Java 中没有 final 修饰的普通方法(没有标记为 static、native)都是虚函数。
虚函数的重要特性是支持在子类中进行 override(重写),从而实现面向对象的重要特性之一:多态。
但是为什么之前的数据库设计者没有去优化这方面呢?是他们没想到吗?怎么可能?这个时候我们可能要考虑到 30 年前的硬件水平了,当时的 IO 速度是远远小于 CPU 的计算速度的,那么 SQL 查询引擎的优化则会被 IO 开销所遮蔽(毕竟花费很多精力只带来 1% 场景下的速度提升意义并不大)。
可是随着近些年来存储越来越快,这个时候我们再思考如何让计算更快可能就有点意思了。
优化方向
首先,考虑到大量虚函数的调用,那我能否写一个循环去执行 Operator 中的计算逻辑呢?执行完成后再向上传递,这样将之前的自上而下的拉模型改成了自下而上的推模型,databricks 的官方博客中提到他们使用一个简单的 benchmark 比较了火山模型与大学新手的手写代码的性能,性能差异如下:

这种手写代码的方式具有有将近 10 倍的性能提升,那么我们是否可以自动生成代码呢?只要自动生成的代码和高效的人肉代码几乎一致,那么提升的效果应该还是很明显的。
其次 ,火山模型中一次只取一条数据,如果每次取多条数据呢?貌似可行啊,因为可以将每次 next 带来的 CPU 开销被一组数据给分摊。这样当 CPU 访问元组中的某个列时会将该元组加载到 CPU Cache(如果该元组大小小于 CPU Cache 缓存行的大小), 访问后继的列将直接从 CPU Cache 中获取,从而具有较高的 CPU Cache 命中率,然而如果只访问一个列或者少数几个列时 CPU 命中率仍然不理想。另外,我们再想想什么时候可以做到取多条数据同时计算呢?当然是同一列的时候,所以针对的是列存的场景,因为输入是同列的一组数据,面对的是相同的操作,这正是向量寄存器干的事情,这是 CPU 层面计算性能的优化,因此称为向量化。并且如果每次只取一列的部分数据,返回一个可以放到 CPU Cache 的向量,那么又可以利用到 CPU Cache。
知识点补习:向量化
向量化计算就是将一个循环处理一个数组的时候每次处理 1 个数据共处理 N 次,转化为向量化------每次同时处理 8 个数据共处理 N/8 次,其中依赖的技术就是 SIMD(Single Instruction Multiple Data,单指令流多数据流),SIMD 可以在一条 CPU 指令上处理 2、4、8 或者更多份的数据。
思考
优化方向有了,即编译执行 (即代码生成)和向量化,但是在实际场景中我们要考虑得更多一些,比如在 SQL 很大时,是否会造成编译(生成代码)过慢呢?
相比火山模型,编译执行和向量化都使数据库查询执行性能得到了极大的提升,这两者之间相比又如何呢。首先这两个模型是不相容的,二者只能取其一。因为编译执行强调的是以数据为中心,在一个 CPU Pipeline 内是不会有物化的,但是向量化执行是拉模型,每次经过 next() 调用,向量的传递必须要进行物化。
总结
本文先通过简单的案例介绍了什么是火山模型,然后给出了优缺点,接着从缺点中结合内存的发展提出 CPU 层面的优化方案,最后介绍了编译执行和向量化这两种方案。后续,会继续介绍编译执行与向量化的具体性能表现以及二者如何结合。
OceanBase 云数据库现已支持免费试用,现在申请,体验分布式数据库带来全新体验吧 ~