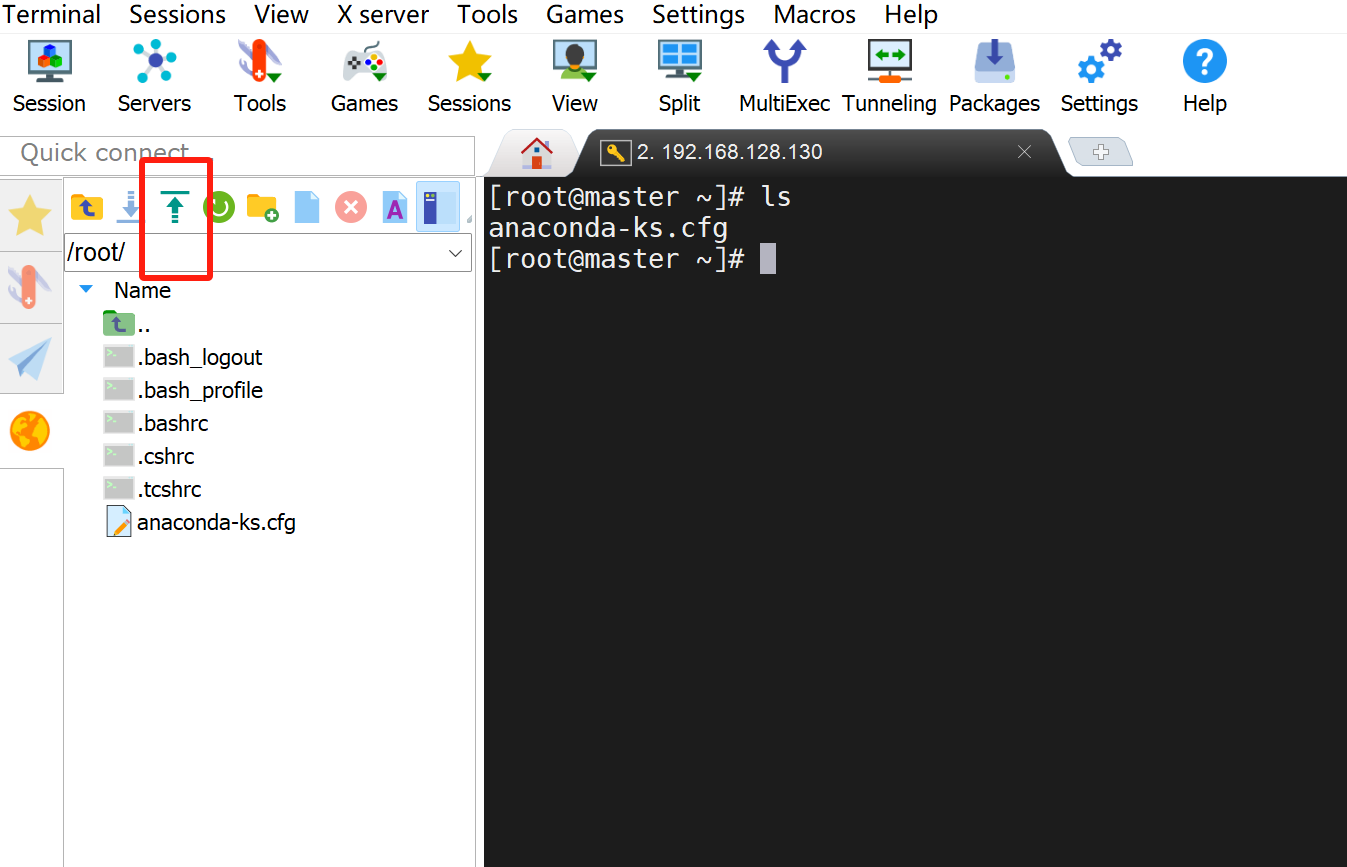
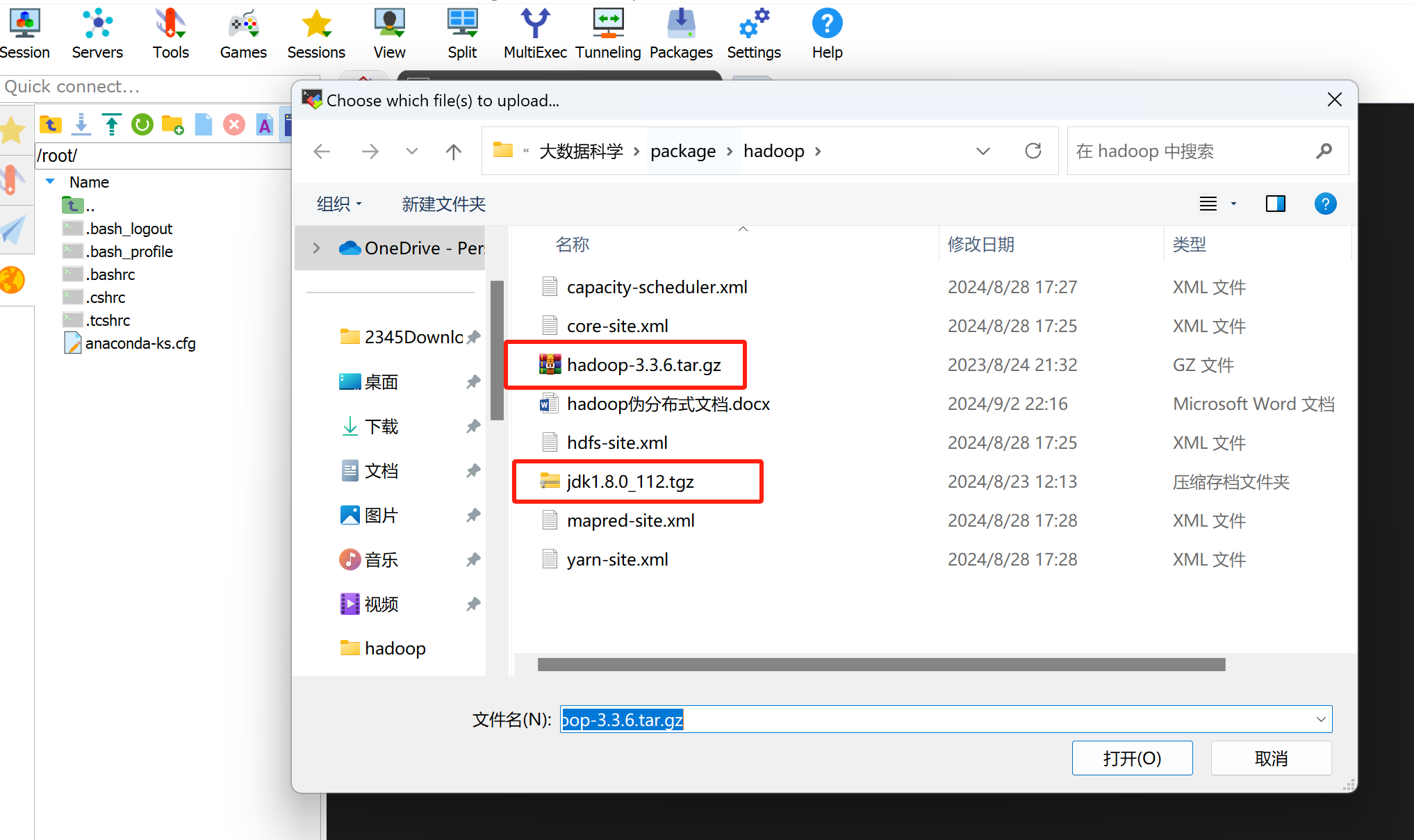
1. 上传jdk和hadoop安装包到服务器
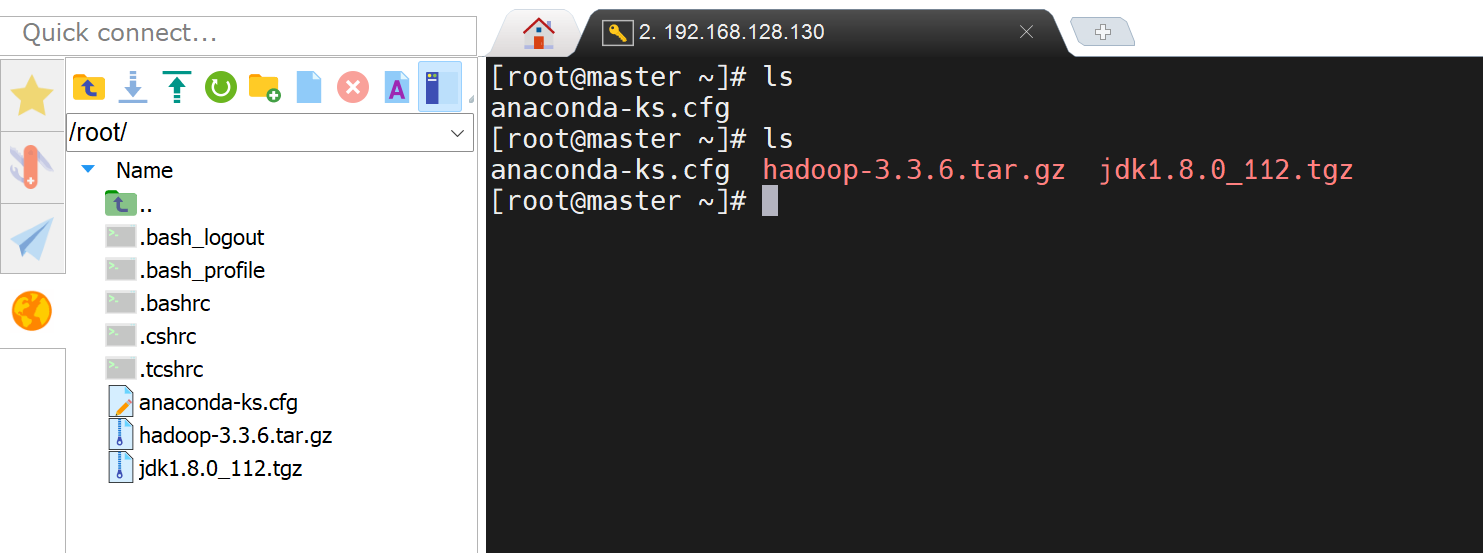
2. 解压压缩包
shell
tar xf jdk1.8.0_112.tgz -C /usr/local/
tar xf hadoop-3.3.6.tar.gz -C /usr/local/
3. 关闭防火墙
shell
#关闭防火墙
systemctl stop firewalld
#关闭防火墙开机自启
systemctl disable firewalld4. 修改配置文件
core-site.xml、hadoop-env.sh、yarn-env.sh、mapred-site.xml、yarn-site.xml、hdfs-site.xml
vim /usr/local/hadoop-3.3.6/etc/hadoop/core-site.xml
shell
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
</configuration>vim /usr/local/hadoop-3.3.6/etc/hadoop/mapred-site.xml
shell
<configuration>
<!-- Framework name -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Job history properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>vim /usr/local/hadoop-3.3.6/etc/hadoop/yarn-site.xml
shell
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN ResourceManager的主机名,通常是集群的主节点 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- ResourceManager的RPC服务地址 -->
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<!-- ResourceManager的调度器地址,用于任务调度 -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<!-- ResourceManager的Web应用程序地址,用于浏览集群状态 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<!-- ResourceManager的Web应用程序HTTPS地址,启用安全连接时使用 -->
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<!-- ResourceManager的资源跟踪服务地址,节点管理器向该地址报告资源信息 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<!-- ResourceManager的管理接口地址,用于管理和控制集群 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<!-- NodeManager本地存储临时文件的目录 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<!-- 是否启用日志聚合,将节点上的日志收集到一个中心位置 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 存储应用程序日志的远程目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<!-- 日志服务器的URL,用于访问应用程序的历史日志 -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
</property>
<!-- 是否启用虚拟内存检查,可以防止内存超用,但可能会影响任务运行 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 定义NodeManager的辅助服务,mapreduce_shuffle是MapReduce任务所需的服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置ShuffleHandler类,处理MapReduce Shuffle操作 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 配置NodeManager节点上可用的内存(以MB为单位) -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!-- 调度器允许分配的最小内存大小 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 调度器允许分配的最大内存大小 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- Map任务分配的内存大小 -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<!-- Reduce任务分配的内存大小 -->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<!-- 配置NodeManager可用的CPU核心数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>vim /usr/local/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
shell
<configuration>
<!-- NameNode directory -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<!-- DataNode directory -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<!-- Allow HTTP access to NameNode -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- Replication factor -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
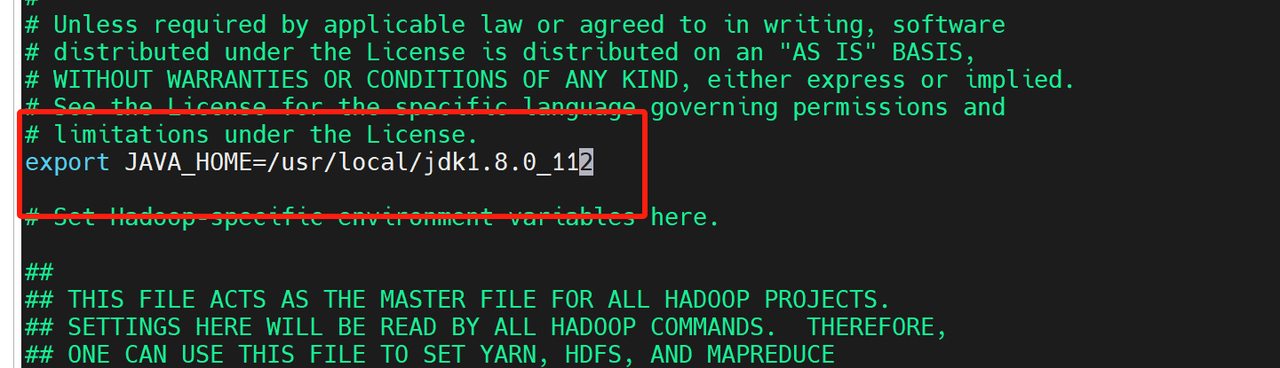
</configuration>vim /usr/local/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
vim /usr/local/hadoop-3.3.6/etc/hadoop/yarn-env.sh
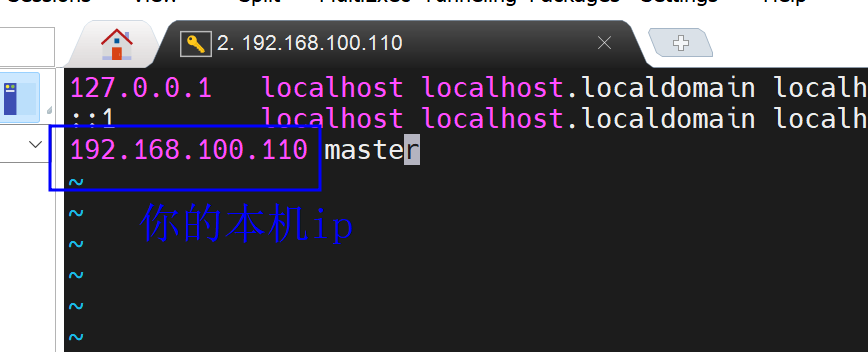
vim /etc/hosts
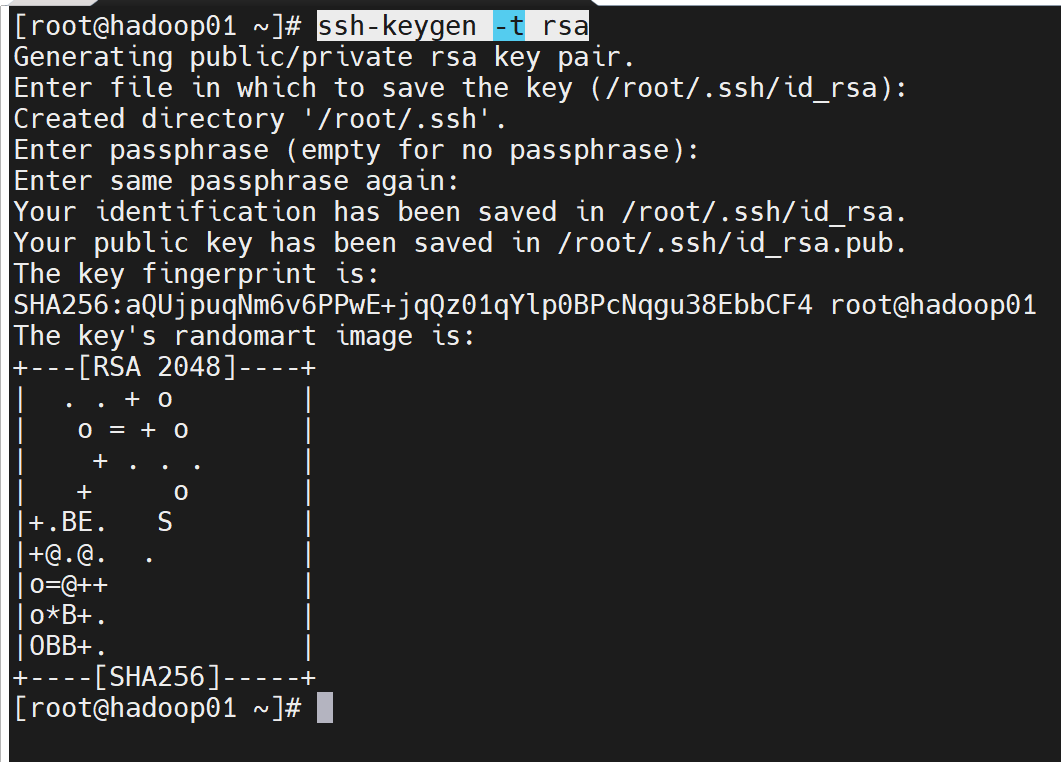
5. 创建ssh免密
shell
ssh-keygen -t rsa回车回车回车
shell
ssh-copy-id master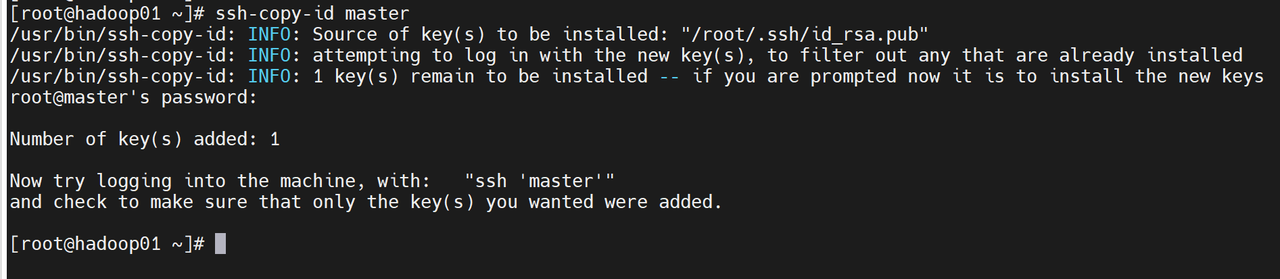
6. 配置java和hadoop环境变量
vi /etc/profile
shell
export JAVA_HOME=/usr/local/jdk1.8.0_112
export HADOOP_HOME=/usr/local/hadoop-3.3.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
- 验证是否成功
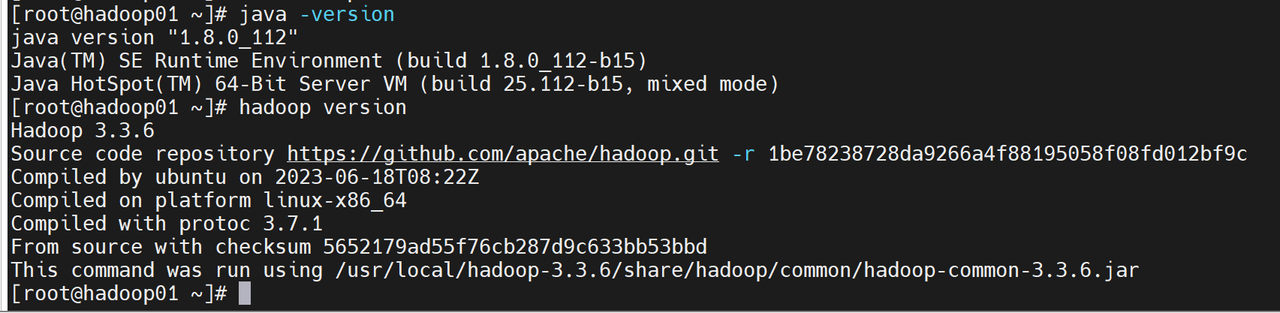
java -version
hadoop version
7. 格式化namenode
hdfs namenode -format

8. 修改启动、停止脚本
vi /usr/local/hadoop-3.3.6/sbin/start-dfs.sh
增加配置
shell
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root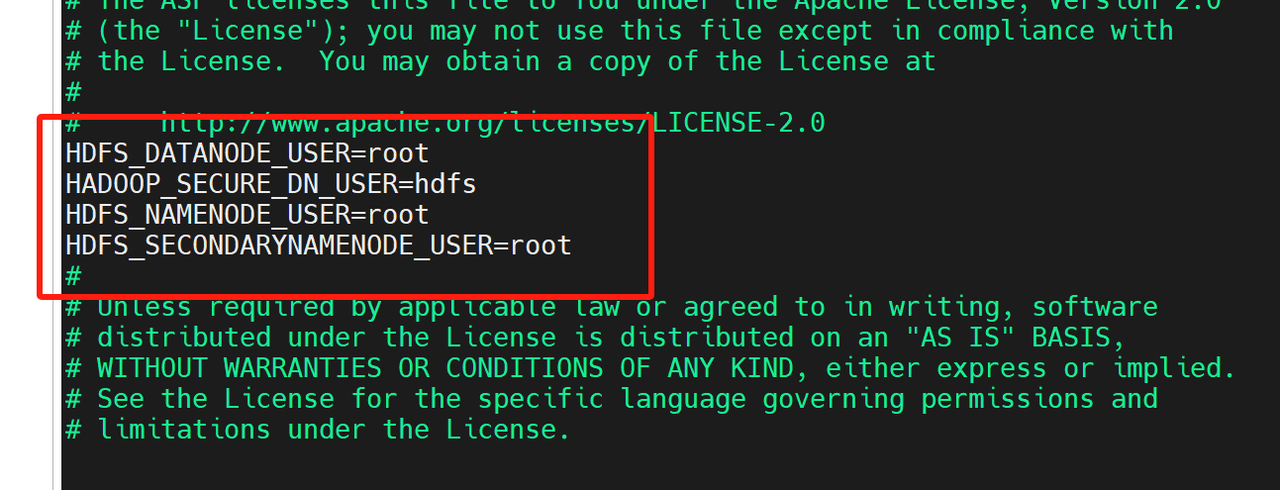
vi /usr/local/hadoop-3.3.6/sbin/stop-dfs.sh
shell
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootvi /usr/local/hadoop-3.3.6/sbin/start-yarn.sh
shell
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root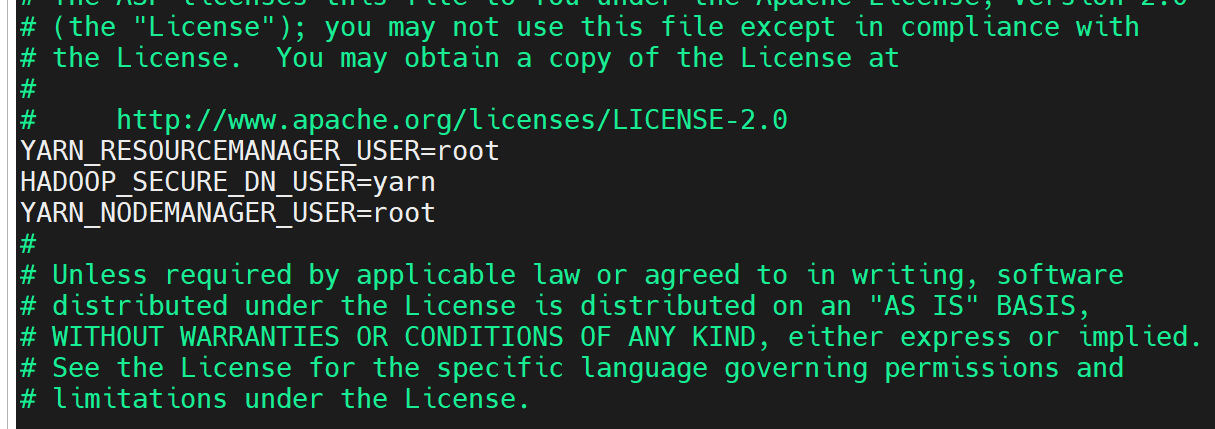
vi /usr/local/hadoop-3.3.6/sbin/stop-yarn.sh
shell
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root9. 启动hadoop集群
shell
start-dfs.sh
start-yarn.sh
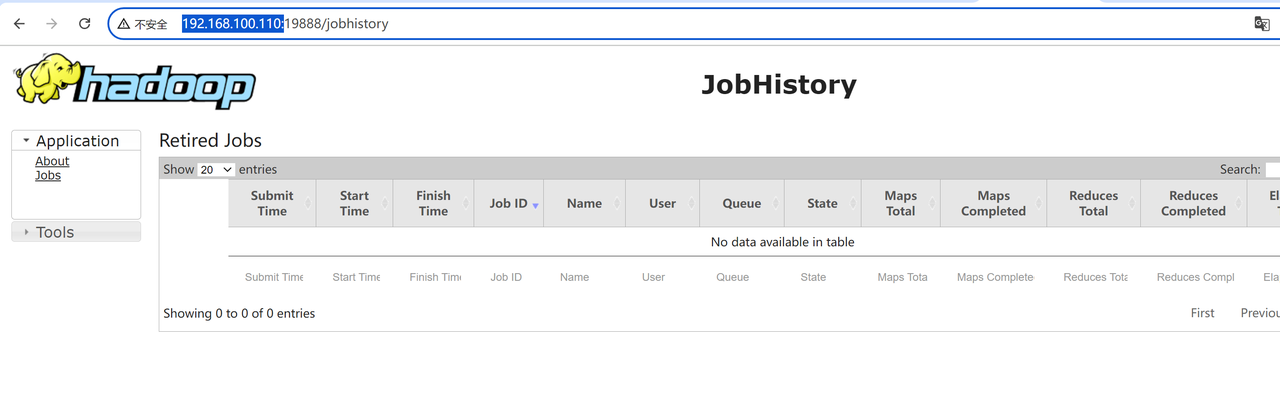
mr-jobhistory-daemon.sh start historyserver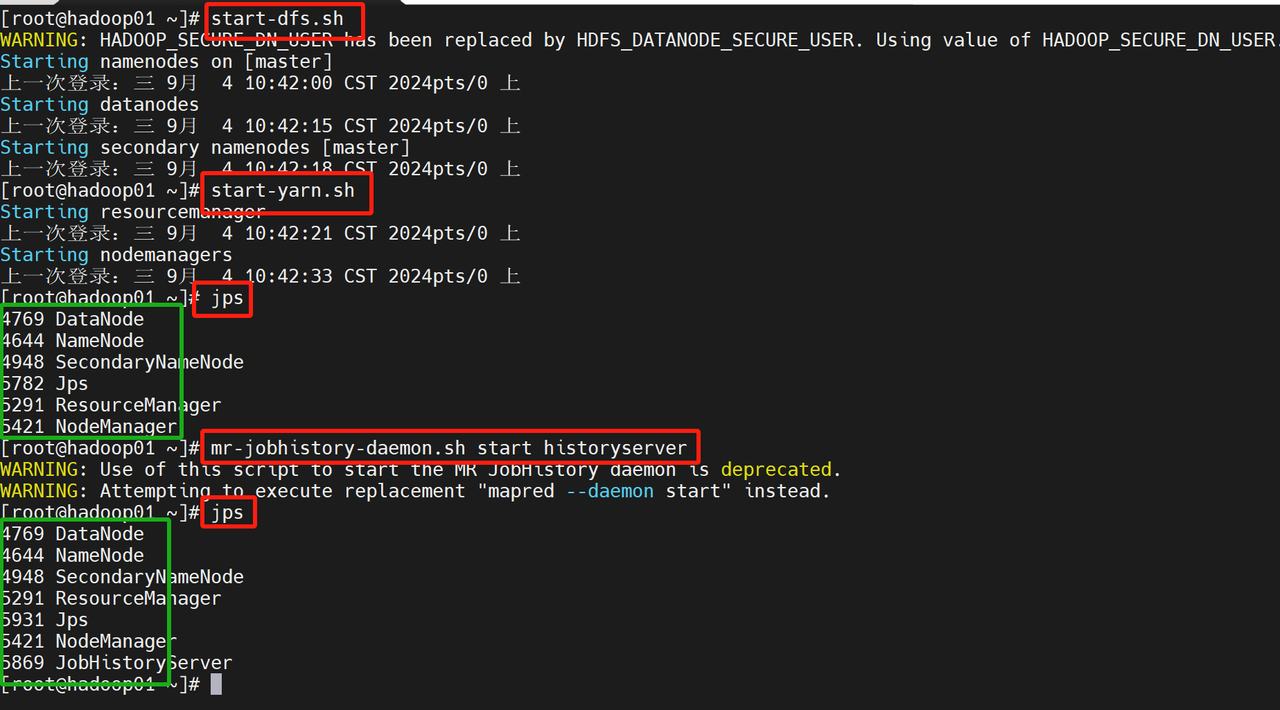
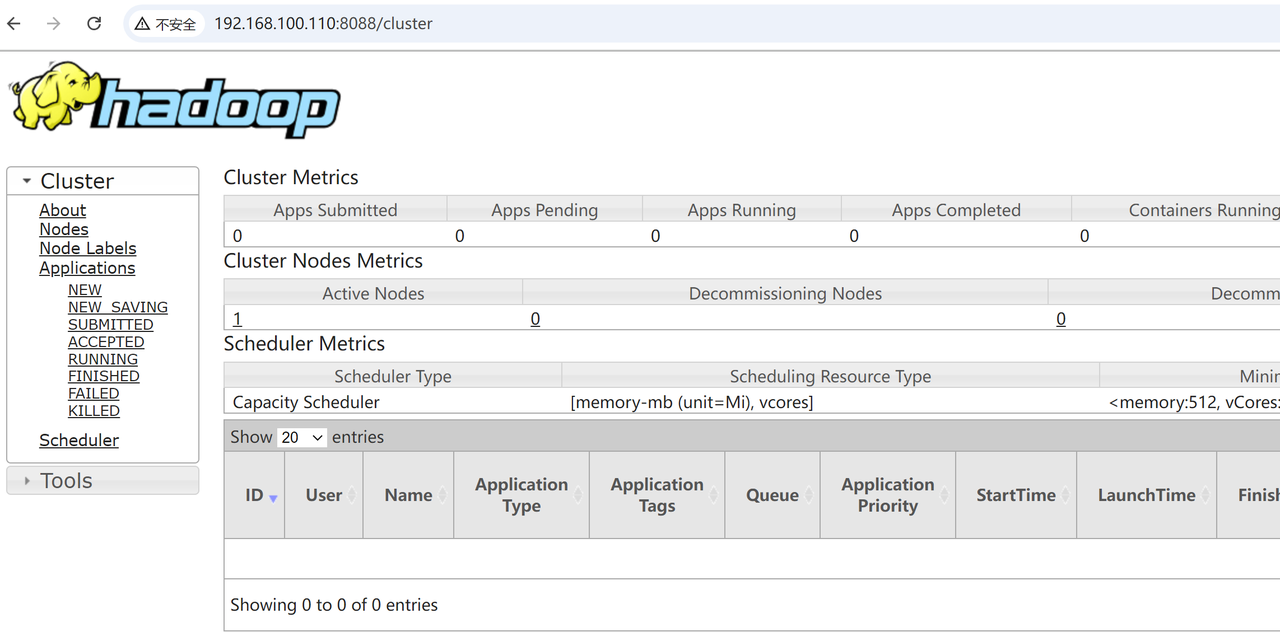
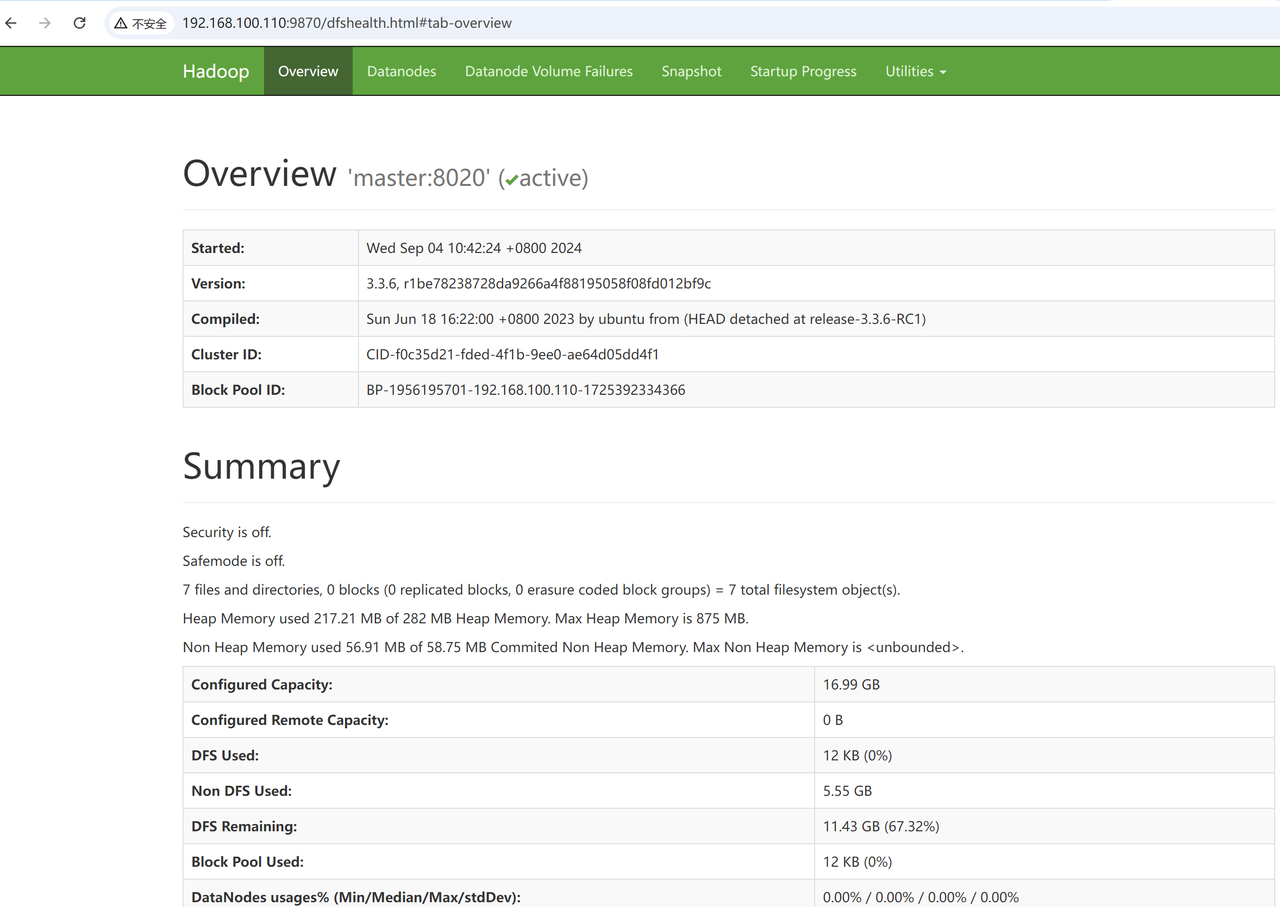
10. 界面查看
10.1 hdfs的web查看
输入自己IP地址加端口
10.2 yarn的web查看