| 上一篇 | 下一篇 |
|---|---|
| 注意力机制(第1/4集) | 待编写 |
一、pytorch 中的多维注意力机制:
在 N L P NLP NLP 领域内,上述三个参数都是 向量 , 在 p y t o r c h pytorch pytorch 中参数向量会组成 矩阵 ,方便代码编写。
①结构图
注意力机制结构图如下:
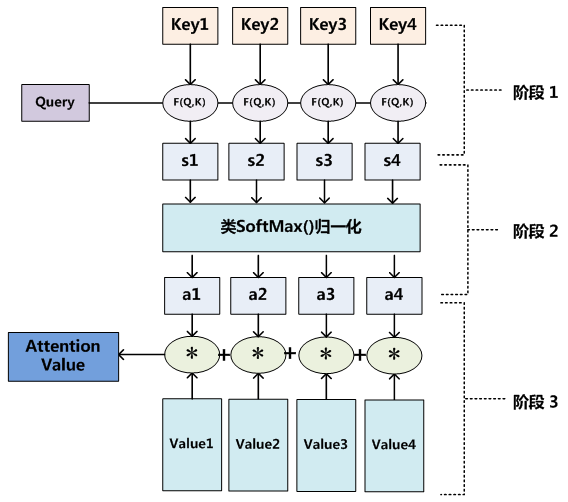
②计算公式详解
计算注意力分数的方式有很多,目前最常用的就是点乘。具体如下:
当向量 q u e r y \large query query 和 k e y \large key key 长度相同时,即 q 、 k i ∈ R ( 1 × d ) q、k_i∈R^{(1×d)} q、ki∈R(1×d) ,则有:注意力分数 s ( q , k i ) = < q , k i > d k \large s(q,k_i)=\frac{<q,k_i>}{\sqrt{d_k}} s(q,ki)=dk <q,ki> ,符号 < q , k i > <q,k_i> <q,ki> 表示点乘/内积运算(向量点乘,结果为标量)。其中 d k d_k dk 是 k i k_i ki 向量的长度(为什么要在原注意力分数底下除以 d k \sqrt{d_k} dk 后面会详解)。
当向量组成矩阵时,假设 Q ∈ R ( n × d ) Q∈R^{(n×d)} Q∈R(n×d) , K ∈ R ( m × d ) K∈R^{(m×d)} K∈R(m×d) , V ∈ R ( m × v ) V∈R^{(m×v)} V∈R(m×v) 。每个矩阵都是由参数行向量堆叠组成。则有:
F ( Q ) = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ⋅ K T d k ) ⋅ V \Large F(Q)=Attention(Q,K,V)=softmax(\frac{Q·K^T}{\sqrt{d_k}})·V F(Q)=Attention(Q,K,V)=softmax(dk Q⋅KT)⋅V
其中 Q K T d ∈ R ( n × m ) \large \frac{QK^T}{\sqrt{d}}∈R^{(n×m)} d QKT∈R(n×m) 是注意力分数,, s o f t m a x ( Q K T d k ) ∈ R ( n × m ) \large softmax(\frac{QK^T}{\sqrt{d_k}})∈R^{(n×m)} softmax(dk QKT)∈R(n×m) 是注意力权重, F ( Q ) ∈ R ( n × v ) \large F(Q)∈R^{(n×v)} F(Q)∈R(n×v) 是输出。
这是一种并行化矩阵计算形式,将所有的 q q q 组合成一个矩阵 Q Q Q , k k k 和 v v v 类似,都被组合成了矩阵 K K K 和 V V V 。其详细过程如下:
已知 Q ∈ R ( n × d ) Q∈R^{(n×d)} Q∈R(n×d) , K ∈ R ( m × d ) K∈R^{(m×d)} K∈R(m×d) , V ∈ R ( m × v ) V∈R^{(m×v)} V∈R(m×v) ,该尺寸表示有 n n n 个 q q q , m m m 个 k k k 和 m m m 个 v v v 。则:
Q × K T = \[ ⋯ q 1 ⋯ ⋯ q 2 ⋯ ⋮ ⋯ q n ⋯ ] ● \[ ⋮ k 1 ⋮ ⋮ ⋮ k 2 ⋮ ⋮ ⋯ ⋮ k m ⋮ ⋮ ] = q 1 ⋅ k 1 q 1 ⋅ k 2 ⋯ q 1 ⋅ k m q 2 ⋅ k 1 q 2 ⋅ k 2 ⋯ q 2 ⋅ k m ⋮ ⋮ ⋱ ⋮ q n ⋅ k 1 q n ⋅ k 2 ⋯ q n ⋅ k m Q \times K^T =\\ \begin{bmatrix} \begin{bmatrix} \cdots & q_1 & \cdots \end{bmatrix} \\ \begin{bmatrix} \cdots & q_2 & \cdots \end{bmatrix} \\ \vdots \\ \begin{bmatrix} \cdots & q_n & \cdots \end{bmatrix} \end{bmatrix} ● \begin{bmatrix} \begin{bmatrix} \vdots \\ k_1 \\ \vdots \\ \vdots \end{bmatrix} & \begin{bmatrix} \vdots \\ k_2 \\ \vdots \\ \vdots \end{bmatrix} & \cdots & \begin{bmatrix} \vdots \\ k_m \\ \vdots \\ \vdots \end{bmatrix} \end{bmatrix}= \begin{bmatrix} q_1 \cdot k_1 & q_1 \cdot k_2 & \cdots & q_1 \cdot k_m \\ q_2 \cdot k_1 & q_2 \cdot k_2 & \cdots & q_2 \cdot k_m \\ \vdots & \vdots & \ddots & \vdots \\ q_n \cdot k_1 & q_n \cdot k_2 & \cdots & q_n \cdot k_m \end{bmatrix} Q×KT= ⋯q1⋯⋯q2⋯⋮⋯qn⋯ ● ⋮k1⋮⋮ ⋮k2⋮⋮ ⋯ ⋮km⋮⋮ = q1⋅k1q2⋅k1⋮qn⋅k1q1⋅k2q2⋅k2⋮qn⋅k2⋯⋯⋱⋯q1⋅kmq2⋅km⋮qn⋅km
上述运算可以得到每个小 q q q 对 m m m 个小 k k k 的注意力分数,再经过放缩(除以 d k \sqrt{d_k} dk )和 s o f t m a x softmax softmax 函数后得到每个小 q q q 对 m m m 个小 k k k 的注意力权重矩阵,其尺寸为 n × m n×m n×m ,最终和 V V V 相乘,得到 F ( Q ) F(Q) F(Q) ,其尺寸为 n × v n×v n×v ,对应着 n n n 个 q q q 的 v a l u e value value 。
③公式细节解释
-
第一点:
使用点乘来计算注意力分数的意义:矩阵点乘 Q ⋅ K T Q·K^T Q⋅KT 就意味着做点积/内积,(在注意力机制中,点积通常等同于内积,在数学上点积是内积的特例),内积可直接衡量两个向量的方向对齐程度。若两个向量方向一致(夹角为 0 ° 0° 0° ),则内积最大;方向相反(夹角为 180 ° 180° 180° ),则内积最小。点乘不仅包含方向信息,还隐含向量长度的乘积。例如,若两个长向量方向一致,内积值会显著高于短向量,可能更强调其相关性。
-
第二点:
上述公式中, s o f t m a x softmax softmax 里对注意力分数还除以了 d k \sqrt{d_k} dk ,是因为:由于 s o f t m a x softmax softmax 函数的计算公式用到了 e e e 的次方,当两个数之间的倍数很大时,比如说 99 和 1 ,经过求 e e e 的次方运算之后,差别会指数倍增加,这样求出来的概率会很离谱,不是0.99和0.01,而是0.99999999和0.0000000001(很多9和很多0)。让其中每个元素除以 d k \sqrt{d_k} dk 之后,会降低倍数增加的程度(更数学性的解释可以看 00 预训练语言模型的前世今生(全文 24854 个词) - B站-水论文的程序猿 - 博客园 这篇博客中的有关注意力机制的讲解)。其功能类似于防止梯度消失。
-
第三点:
一般来说,在 t r a n s f o r m e r transformer transformer 里, K = V K=V K=V 。当然 K ≠ V K≠V K=V 也可以,不过两者之间一定是有对应关系,能组成键值对的。
二、自注意力机制(Self-Attention)
当上述的三个参数都由一个另外的共同参数 经过不同的线性变换 生成时(即三者同源),就是自注意力机制。其值体现为 Q ≈ K ≈ V Q≈K≈V Q≈K≈V 。
这三个矩阵是在同一个矩阵 X X X 上乘以不同的系数矩阵 W Q 、 W K 、 W V W_Q、W_K、W_V WQ、WK、WV 得到的,因此自注意力机制可以说是在计算 X X X 内部各个 x i x_i xi 之间的相关性。其后续步骤和注意力机制一样。(为什么叫自注意力机制,估计是因为这里是计算自己内部之间的相关性吧)
【++注意++ 】:最终生成的新的 v a l u e value value 其实依然是小 x x x 的向量表示,只不过这个新向量蕴含了其他的小 x x x 的信息。
具体公式如下:
Q = W Q ⋅ X , K = W K ⋅ X , V = W V ⋅ X F ( Q ) = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ⋅ K T d k ) ⋅ V \large Q=W_Q·X,~~~~K=W_K·X,~~~~V=W_V·X\\ \Large F(Q)=Attention(Q,K,V)=softmax(\frac{Q·K^T}{\sqrt{d_k}})·V Q=WQ⋅X, K=WK⋅X, V=WV⋅XF(Q)=Attention(Q,K,V)=softmax(dk Q⋅KT)⋅V
在 N L P NLP NLP 中,可以举一个小例子理解一下(矩阵内数值即为注意力权重):
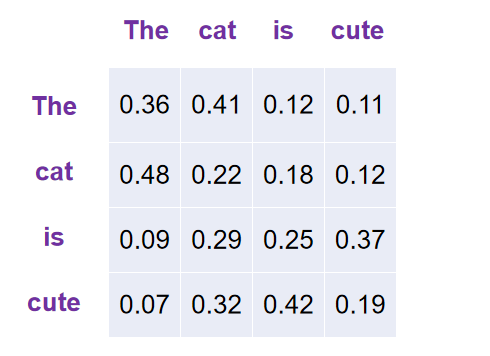
上图中,每一个单词就是一个小 q q q ,单词用向量表示。(有个误区:不是说自注意力机制中,小 q q q 和自己的注意力分数就是最大的,这个要看具体语义需求)
其他变种:交叉注意力机制( Q Q Q 和 V V V 不同源, K K K 和 V V V 同源)。
三、掩码自注意力机制(Masked Self-Attention)
在 N L P NLP NLP 里,在训练过程中,比如说我想训练模型生成:"The cat is cute" 这样一个句子,并且计算其自注意力权重,这个时候 "The cat is cute" 就是已知的 label 。但是句子是一个一个单词生成的( The → The cat → The cat is → The cat is cute),第一个生成 The ,第二个生成 cat ... 在没有完全生成之前,都是不能提前告诉模型后面的答案。已知句子总长度为 4 4 4 ,那么注意力权重的个数依次是 1 → 2 → 3 → 4 。如下图所示:
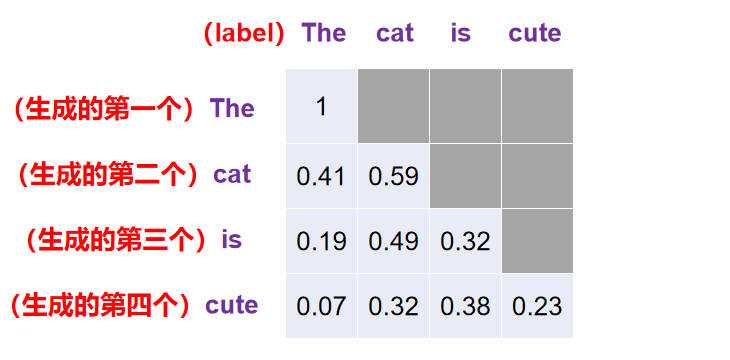
注意了,这里的生成是指训练时的生成,掩码机制只在训练时使用,因为训练时机器知道有位置信息的句子(句子的长度也已知晓),为了防止窥探到下一个字就要掩码。但在实际使用模型时(测试时),是没有参考答案的,所以不需要掩码!
其实还有其他作用,诸如:避免填充干扰等,后面在 transformer 里会详解。
四、多头注意力机制(Multi-Head Self-Attention)
本质上就是: X X X 做完三次线性变换得到 Q 、 K 、 V Q、K、V Q、K、V之后,将 Q 、 K 、 V Q、K、V Q、K、V分割成 8 8 8 块进行注意力计算,最后将这 8 8 8 个结果拼接,然后线性变换,使其维度和 X X X 一致。(并不是直接对 X 进行切分,也不是对 X 进行重复线性变换)
意义:原论文其实也说不清楚这样做的意义,反正给人一种能学到更细致的语义信息的感觉(深度学习就是这样~~)。
流程图如下:
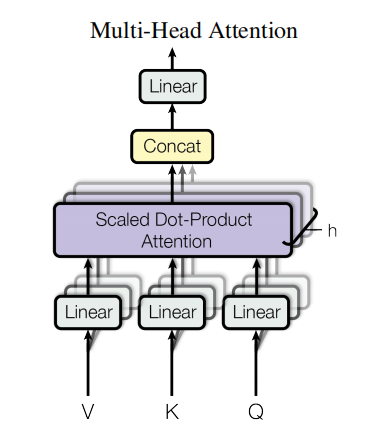
++第一步:++
输入序列 X X X 首先经过三次独立的线性变换,生成查询( Q u e r y Query Query)、键( K e y Key Key)、值( V a l u e Value Value)矩阵:
Q = W Q ⋅ X Q=W_Q·X Q=WQ⋅X , K = W K ⋅ X K=W_K·X K=WK⋅X , V = W V ⋅ X V=W_V·X V=WV⋅X 。其中, W Q 、 W K 、 W V W_Q、W_K、W_V WQ、WK、WV 是可学习的权重矩阵。
++第二步:++
将 Q 、 K 、 V Q、K、V Q、K、V 矩阵沿特征维度平均分割为多个头。一般头数均为 8 8 8(即 h = 8 h=8 h=8),假设 Q 、 K 、 V Q、K、V Q、K、V 的特征维度为 M M M ,则分割之后每个头的特征维度为 M / 8 M/8 M/8 。
++第三步:++
每个头各自并行计算注意力并得到各自的输出(先点积,再缩放,再做 s o f t m a x softmax softmax ,再乘以 v a l u e value value )【每个头学习不同子空间的语义关系】
++第四步:++
合并多头输出,将所有头的输出拼接为完整维度,再通过一次线性变换整合信息:
O u t p u t = C o n c a t ( h e a d 1 , ... , h e a d h ) ⋅ W O Output=Concat(head_1,...,head_h)⋅W_O Output=Concat(head1,...,headh)⋅WO 。其中 W O W_O WO 是最后的线性层的投影矩阵。
值得一提的是:针对 "将 Q 、 K 、 V Q、K、V Q、K、V分割成 8 8 8 块" 这个步骤,《Attention Is All You Need》论文原文说的是: linearly project h times ,意思就是将 Q 、 K 、 V Q、K、V Q、K、V通过线性层将其变换为 8 8 8 个新的特征维度为 M / 8 M/8 M/8 的 Q ′ 、 K ′ 、 V ′ Q^{'}、K^{'}、V^{'} Q′、K′、V′ 。不过这在数学上等效于直接分割成 8 8 8 块,并且后者在算法实现上能提高效率。代码如下:
python
Q = torch.randn(batch_size, seq_len, h*d_k)
Q = Q.view(batch_size, seq_len, h, d_k) # 分割为 h 个头.view() 函数的作用是变换尺寸,将原来的三维张量,变成四维张量( h 个三维张量),元素的值不变,元素的总数也不变,其效果等于切割。