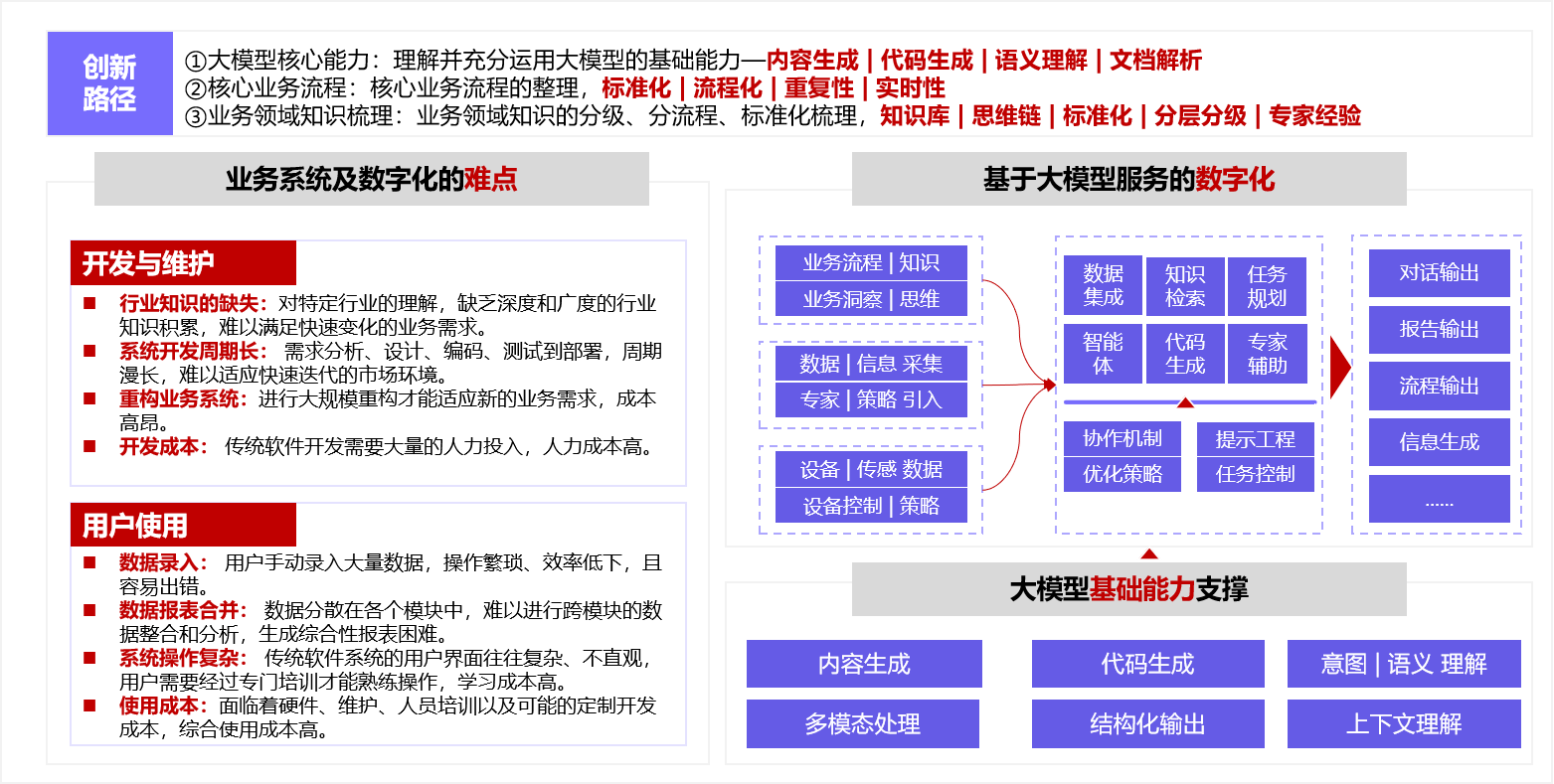
1-背景
传统数据系统与业务数字化的开发与维护面临诸多挑战:行业知识获取壁垒高、需求变化快导致开发周期长、系统复杂度高以及人力与资源投入成本巨大。同时,用户在使用过程中也常遇到痛点:手动录入数据繁琐低效、数据分散于各模块难以整合分析、系统操作复杂学习成本高,以及包含软硬件、维护、培训在内的高昂使用成本。这些因素共同制约了数据工作流的自动化效率和深度,凸显了利用新兴技术,如大型语言模型驱动的多智能体协作,来优化数据处理、整合知识、简化交互并最终实现数据工作流自动化的迫切性与技术价值。
在复杂多变的业务场景下,单纯依赖大型语言模型的通用能力难以满足精细化、专业化的数据工作流需求。其核心挑战在于模型缺乏实时、 精准的行业知识和对动态业务逻辑的深刻理解,容易产生内容幻觉或无法执行复杂任务。因此,引入结合了检索增强生成(RAG)技术的将领域知识,如数据知识、数据分析流程、模型构建方法等,结合的多智能体协作体系中变得至关重要。本文通过让智能体(Agents)在执行任务时,能实时从外部知识库、数据库、乃至图谱中检索相关数据与知识,有效弥补了大型模型的知识局限性和滞后性。它不仅能确保工作流输出的准确性、时效性和专业性,更能通过多智能体协同,模拟专家经验,处理涉及多系统、多步骤的复杂业务流程,实现真正意义上的数据与知识深度融合及工作流自动化,是提升决策质量和业务效率的关键驱动力。
2-技术架构
整体架构
本技术架构以大型语言模型(LLM)驱动的多智能体系统为核心,结合检索增强生成(RAG)技术深度融合领域业务知识。用户任务输入后,系统首先通过LLM RAG理解任务并进行拆解、筛选适配的智能体(Agents)。随后,调度多智能体中心的专业Agent,这些Agent利用底层专业模型库工具和多源多模态数据集执行具体子任务,整个过程受到策略辅助模块的支撑与管控,最终输出结果并沉淀历史知识以持续优化。
各模块流程
LLM RAG与任务分解: 接收用户请求,利用RAG融合领域知识理解意图,将复杂任务分解为子任务序列,并为各子任务匹配最优智能体执行。
多智能体中心: 汇集各类专业智能体,如数据处理、分析、报告等。各Agent封装特定技能,调用专业模型库和工具执行分配的子任务。
专业模型库与数据集: 提供OCR、NLP、ML等模型及多源多模态数据。智能体调用这些底层资源完成数据获取与专业处理任务。
多智能体策略辅助: 提供任务审核、专家介入、安全管控、资源调度等支持能力,保障多智能体协作过程的顺畅、安全与高效。
历史知识沉淀: 记录执行过程、结果、代码、用户反馈与评估信息,构建提示词、任务与记忆库,反馈优化系统未来表现。
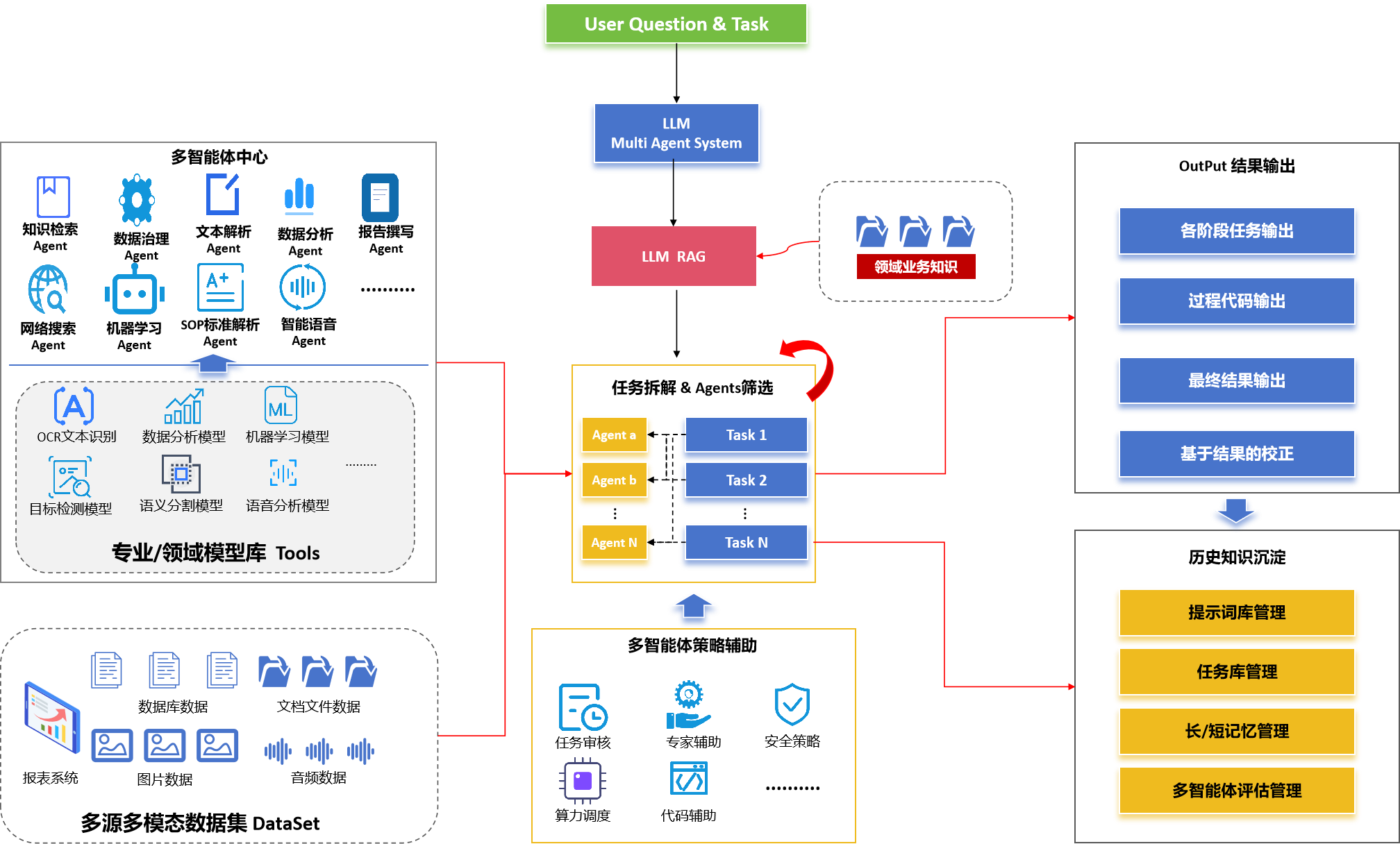
该架构通过LLM的统一调度和RAG的知识增强,实现了任务的智能分解与专业智能体的协同执行。它有机整合了多源数据、领域模型库和策略辅助能力,形成一个闭环系统:不仅能自动化完成复杂的数据工作流,还能通过历史知识的积累与反馈不断自我完善,持续提升处理效率、准确性和智能化水平。
3-产品实践
1、业务场景提示
- 提示数据分析过程中的业务步骤及可使用的智能体
python
Scenario 1: Data Analysis
If the user's question pertains to the field of data analysis, follow these steps for planning:
Use search_data_agent to query or search for the required data items (if the user has already provided relevant data items, skip this step).
Based on the search results, generate or merge the required data files using relevant agents such as pandas_data_analy(especial for csv/xls/xlsx...)\sql_agents(especial for sql database), Futures Data Analysis, sql_agents, etc.
Break down the data analysis tasks according to the user's question and the available data.
Execute each data analysis task accordingly.
Compile and write a comprehensive data analysis report.
Relate agents: search_data_agent, pandas_data_analy, sql_agents, Futures Data Analysis,report_agent.2、业务知识嵌入:先检索数据知识
- 任务规划前先自主检索知识库内关于该任务的相关知识,将所需的知识、用户的核心业务流程进行融合,保证业务流程具备领域知识的加持。
python
with st.status('😊正在思考(Thinking)...', state='running',expanded=True) as status:
# 记录任务开始时间
st.session_state.disprompt = False
task_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
task_start_time = datetime.datetime.now()
##获取knowledge文件夹内所有json文件
try:
documents_chunks_info_LIST = {}
doc_chunks_LIST = {}
KB_summary_LIST = {}
kb_info_files = [f for f in os.listdir(KB_info_file_path) if f.endswith('.json')]
for kg_file in kb_info_files:
with open(os.path.join(KB_info_file_path, kg_file), 'r', encoding='utf-8') as file:
selected_kb = json.load(file)
kg_file = kg_file.replace('.json', '')
documents_chunks_info_LIST[kg_file] = selected_kb['documents_chunks_info']
doc_chunks_LIST[kg_file] = selected_kb['all_chunks']
KB_summary_LIST[kg_file] = selected_kb['documents_summary']
#print(kg_file)
#print(documents_chunks_info_LIST)
kg_file = knowledge_info_retrieval(prompt, KB_summary_LIST)
#print(kg_file)
kg_file = re.sub(r'[\r\n]+', '', kg_file)
#print(kg_file)
doc_chunk_revent = chunk_retrieval(documents_chunks_info_LIST[kg_file], prompt)
with open("C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output/doc_chunk_revent.json", 'r', encoding='utf-8') as json_file:
doc_chunk_revents = json.load(json_file)
#print(doc_chunk_revent)
doc_chunks = doc_chunks_LIST[kg_file]
plain_retrieval_qa_result = plain_retrieval_qa(doc_chunks[doc_chunk_revents['chunk_number']], prompt)
except:
erro = traceback.format_exc()
stream_text(f"##### Knowledge Retrieval : No relevant knowledge was found for this task, or the search failed.\n###### Error: \n{erro}",speed=100)
plain_retrieval_qa_result = plain_retrieval_qa('No relevant knowledge was found for this task, or the search failed.', prompt)
st.session_state.messages.append({"role": "assistant", "content": '#### RETRIEVAL RESULT: \n'+str(plain_retrieval_qa_result)})
stream_text(f"##### RETRIEVAL RESULT: \n{plain_retrieval_qa_result}",speed=100)
st.success('Task Retrieval & Thinking Completed!')3、智能体协作
任务规划:用户业务任务+业务知识融合的业务任务流,自主规划任务
python
##任务执行
with open('C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/Agents Info.json', 'r', encoding='utf-8') as file:
agents_info = json.load(file)
# 提取每个 agent 的名称、描述和输出
agent_info_list = []
for agent_name, agent_data in agents_info.items():
agent_info = {
"name": agent_data.get("name", ""),
"description": agent_data.get("description", ""),
"output": agent_data.get("output", "")
}
agent_info_list.append(agent_info)
with st.spinner('正在规划任务(Task Planning)...'):
time.sleep(5)
task_config = task_planning(plain_retrieval_qa_result, agent_info_list, 'C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output')
global_config_ = task_config['task_execution_steps']
st.session_state.messages.append({"role": "assistant", "content": '#### Task Planning Result:\n'+str(task_config)})
tabs = st.tabs(["Task Planning Flow", "Task Planning JSON"])
with tabs[1]:
with st.chat_message("assistant",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/chat_icon.png"):
st.markdown(f"<h3>Task Planning</h3>", unsafe_allow_html=True)
st.json(task_config)
with tabs[0]:
with st.chat_message("assistant",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/chat_icon.png"):
st.markdown(f"<h3>Task Planning Flow</h3>", unsafe_allow_html=True)
nodes, edges, config = create_flowchart(task_config['task_execution_steps'])
# 在 Streamlit 中显示流程图
agraph(nodes=nodes, edges=edges, config=config)
st.session_state.flowchart.append((nodes, edges, config))
st.session_state.messages.append({"role": "assistant_flow", "content": (nodes, edges, config)})
st.success('Task Planning Completed!')
status.update(label="Thinking Completed!", state='complete',expanded=True)
st.session_state.task_excute_step.append(" step 1: "+task_config['task_execution_steps'][0]['action'][:150] + "..." if len(task_config['task_execution_steps'][0]['action']) > 150 else task_config['task_execution_steps'][0]['action'])
智能体分步执行
python
if task_config['agents_selection_dict'] != {}:
# 任务拆解
i = 0
output_data = {"steps": []}
prompt_out_put = "User's total task is :" + plain_retrieval_qa_result + '\n this step task is :' + str(task_config['task_execution_steps'][0])
all_task_execute_results_dict = {} # 创建一个字典来存储所有任务的执行结果
step_times = {}
for step in task_config['task_execution_steps']:
with st.status('正在执行任务(Task Execution)...:**Step{}:** {}'.format(step['step'], step['action']), state='running', expanded=True) as status:
try:
step_start_time = datetime.datetime.now()
# agent 参数
time.sleep(5)
global_config_ = global_config(prompt_out_put, agent_info)
# 步骤1输出
agent_file = agents_info[step['tool_selection']]['code_path']
params = global_config_[step['tool_selection']]
agent_out_put = code_py_exec(agent_file, params)
print('Step' + str(i) + 'out_put is:' + str(agent_out_put))
if i < len(task_config['task_execution_steps']) - 1:
time.sleep(5)
prompt_out_put = prompt_info_agent(i, task_config['task_execution_steps'][i + 1], str(agent_out_put))
print('Step' + str(i) + 'prompt_out_put is:' + prompt_out_put)
i += 1
# 记录每一步骤的输出内容
step_data = {
"step_num": f"step {step['step']}",
"task": step['action'],
"expected_output": step['expected_output'],
"global_config_": str(global_config_),
"agent_out_put": agent_out_put,
"next_step_prompt_info": prompt_out_put
}
#中间结果输出
# 将步骤数据添加到输出数据中
time.sleep(5)
output_data["steps"].append(step_data)
# 将输出数据写入 JSON 文件
with open('C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output/task_temp_output/overall_task_iteration_output.json', 'w') as json_file:
json.dump(output_data, json_file, indent=4)
task_excute_result = code_excute_output_optimize(plain_retrieval_qa_result, str(output_data))
#print('task_excute_result is:' + str(task_excute_result))
st.session_state.messages.append({"role": "assistant", "content": task_excute_result})
time.sleep(5)
step_end_time = datetime.datetime.now()
step_times[step['step']] = (step_end_time - step_start_time).total_seconds()
tabs = st.tabs(["Task Execution Result", "Task Execution Report"])
with tabs[0]:
with st.chat_message("assistant",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/chat_icon.png"):
st.markdown(f"<h3>Step {step['step']} - '{step['action']}' is executed successfully! The task took {step_times[step['step']]:.2f}s.</h3 style='color: blue;'>", unsafe_allow_html=True)
stream_text(task_excute_result,speed=400)
with tabs[1]:
try:
reylt= report_generation(str(agent_out_put), 'C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output/report/temp')
except:
pass
time.sleep(3)
step_report_markdown_page('c:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\task_excute_output\\report\\temp')
all_task_execute_results_dict[step['step']] = task_excute_result
except:
# 记录任务失败的原因
step_error = traceback.format_exc()
retry_count=0
# 将任务执行结果存储到字典中
all_task_execute_results_dict[step['step']] = None
print('task_excute is failed:' + str(step))
task_excute_result = code_excute_output_optimize(plain_retrieval_qa_result, 'task_excute is failed:' + str(step) + '\n the error is:' + str(step_error))
st.session_state.messages.append({"role": "assistant", "content": task_excute_result})
tabs = st.tabs(["Task Execution Result", "Task Execution Report"])
with tabs[0]:
with st.chat_message("assistant",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/chat_icon.png"):
st.markdown(f"<h3>Step {step['step']} - {step['action']} is executed failed!</h3>", unsafe_allow_html=True)
st.markdown(task_excute_result)
with tabs[1]:
try:
reylt= report_generation(str(agent_out_put), 'C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output/report/temp')
except:
step_error_ = traceback.format_exc()
st.markdown(f'step report generation is failed! the error is: {step_error_}')
time.sleep(3)
step_report_markdown_page('c:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\task_excute_output\\report\\temp')
step_end_time = datetime.datetime.now()
step_times[step['step']] = (step_end_time - step_start_time).total_seconds()
#with st.status('正在执行任务(Task Execution)...:##### Step +{}:{}'.format(str(i+1), step['action']), state='running', expanded=True) as status:
status.update(label='Task Execution Completed:**Step**{}:{}'.format(step['step'], step['action']), state='complete', expanded=True)
if i < len(task_config['task_execution_steps']):
#st.session_state.task_excute_step += 1
st.session_state.task_excute_step.append("#### step"+str(i)+': '+task_config['task_execution_steps'][i]['action'][:130] + "..." if len(task_config['task_execution_steps'][i]['action']) > 130 else task_config['task_execution_steps'][i]['action'])
#st.session_state.task_excute_step.append(step['action'][:30]+"..." if len(step['action'])>30 else step['action'])
#sys.exit(1)
st.success(f"Step {step['step']} - '{step['action']}' Execution completed successfully! The task took {step_times[step['step']]:.2f}s.")
5、结果展示
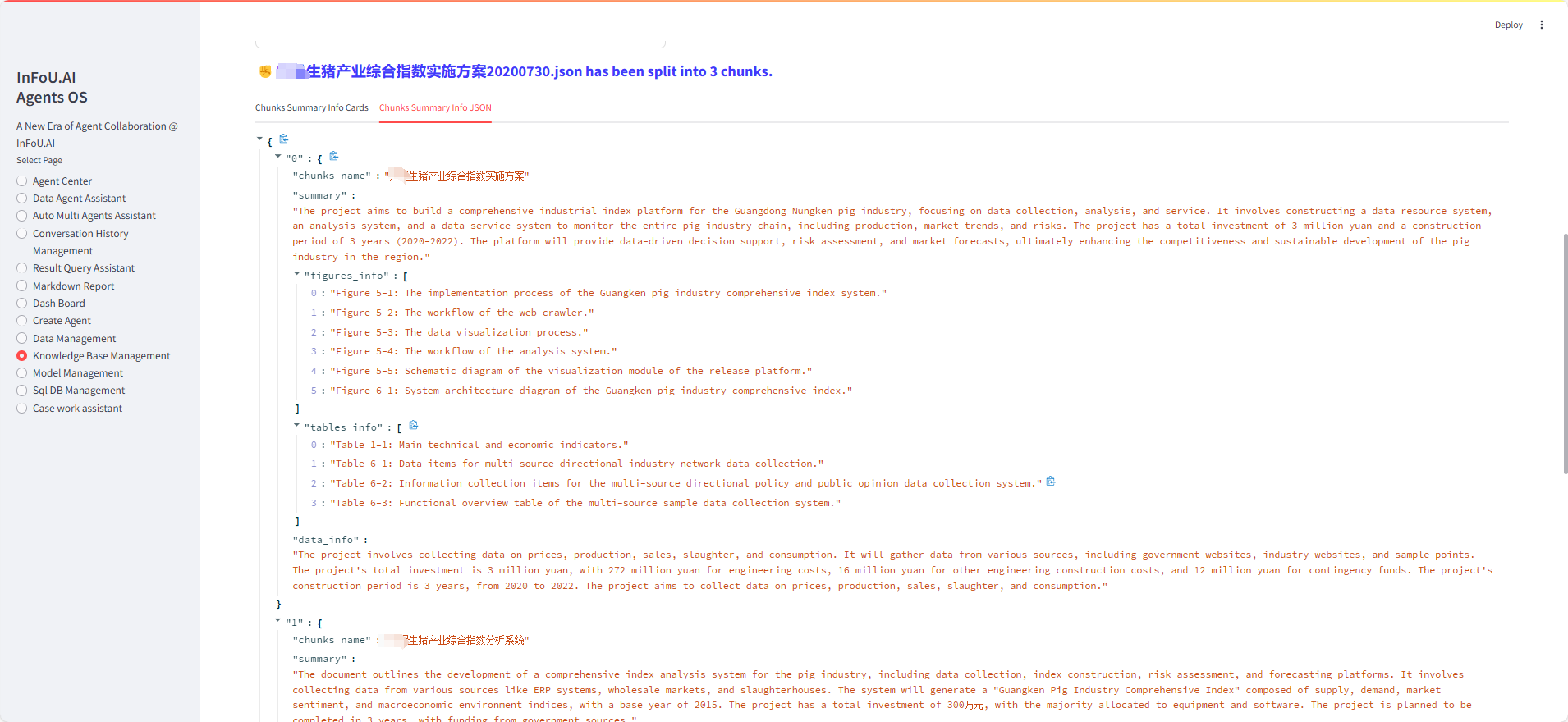
已经构建的知识库体系
(1)农业市场数据分析
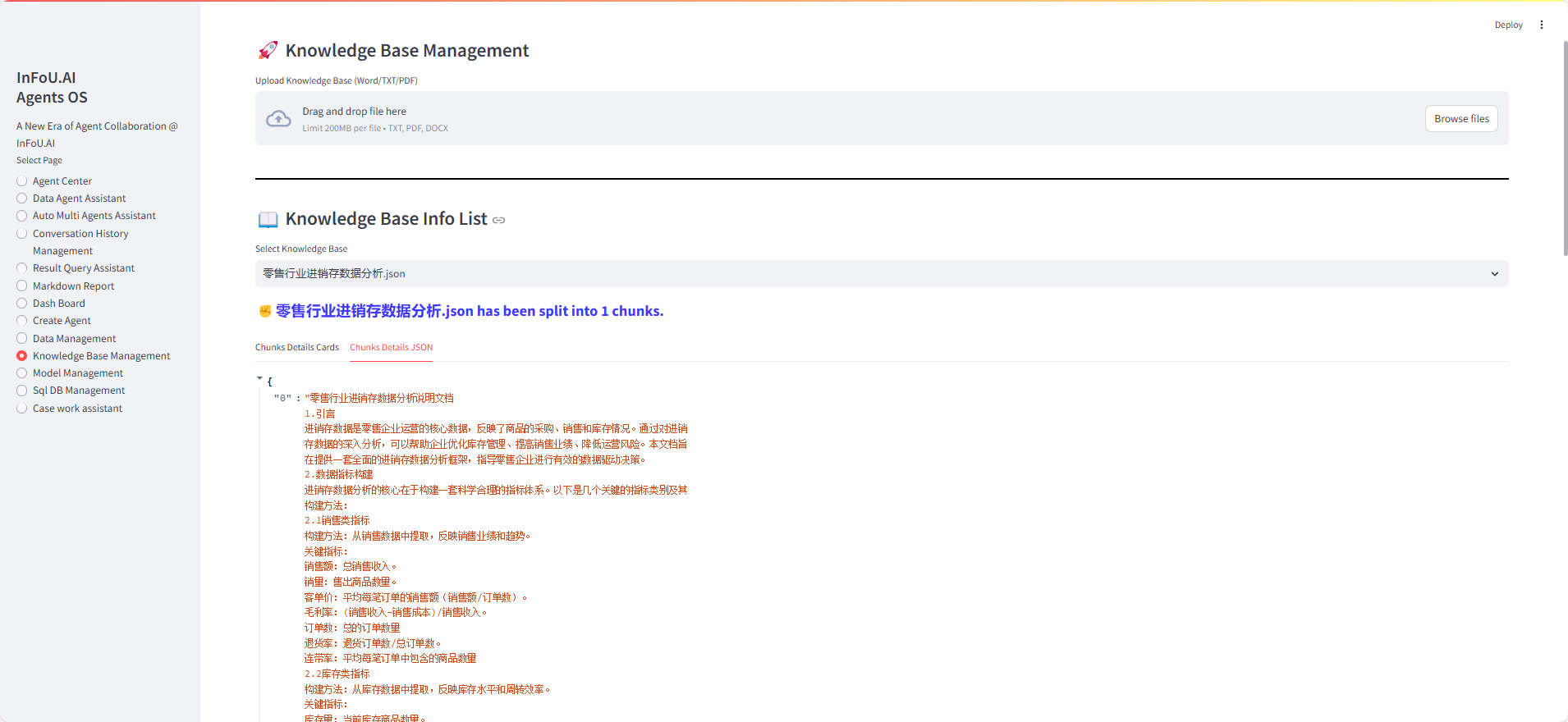
(2)零售行业数据分析方法
任务一:基于sql数据库的数据分析
- user's Task:分析olist电商公司销售情况,包括流量指标:活跃用户数(DAU、MAU、时段),销售形势指标:季节性销售、月度销售情况等 运营指标:GMV(季度、月)、ARPU(季度、月)、订单数(天、月、时段) RFM用户价值分层:各层次用户品类(热门指数 = 金额 + 评价分数)
(1)领域知识检索
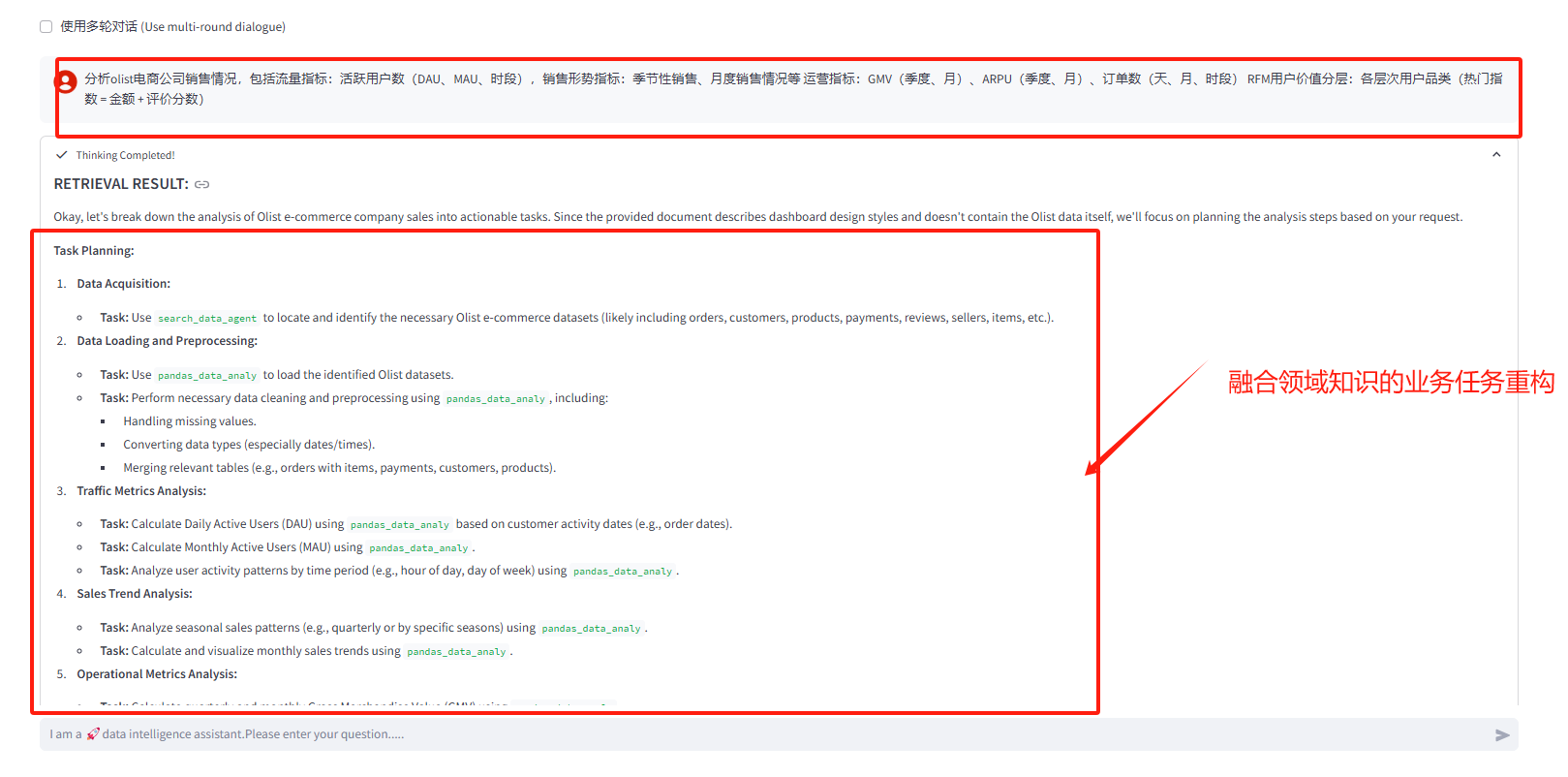
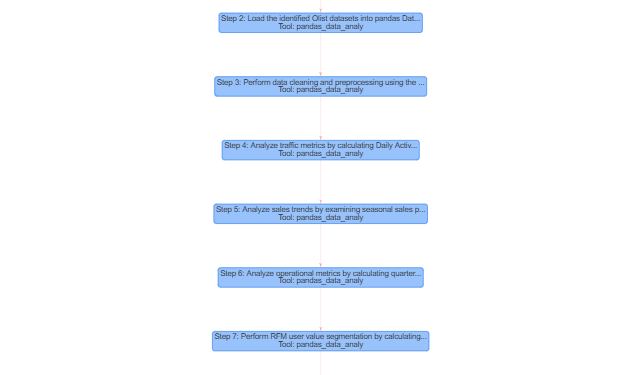
(2)任务规划:检索数据、python-pandas分析-数据看板
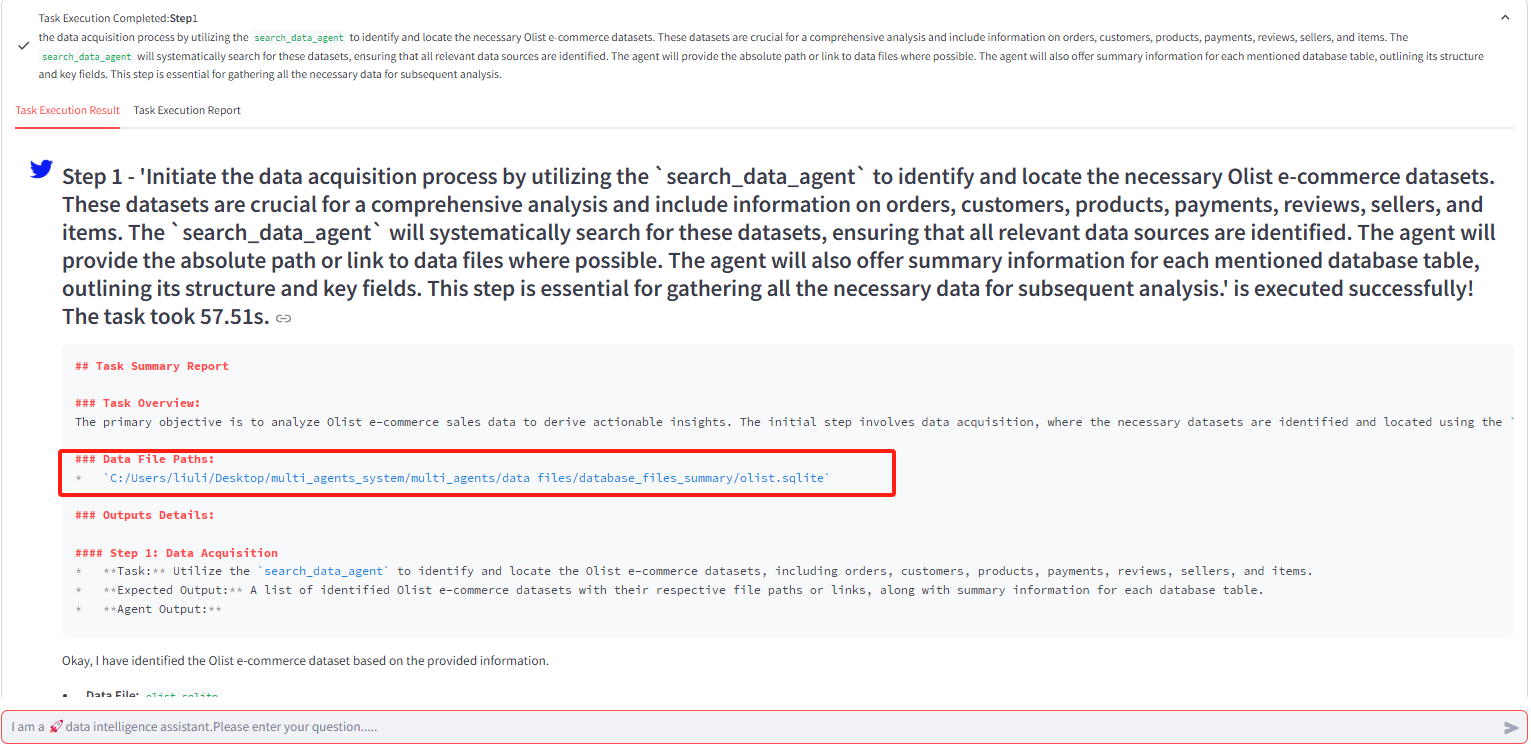
(3)智能体执行:
-
准确找到相关数据库文件
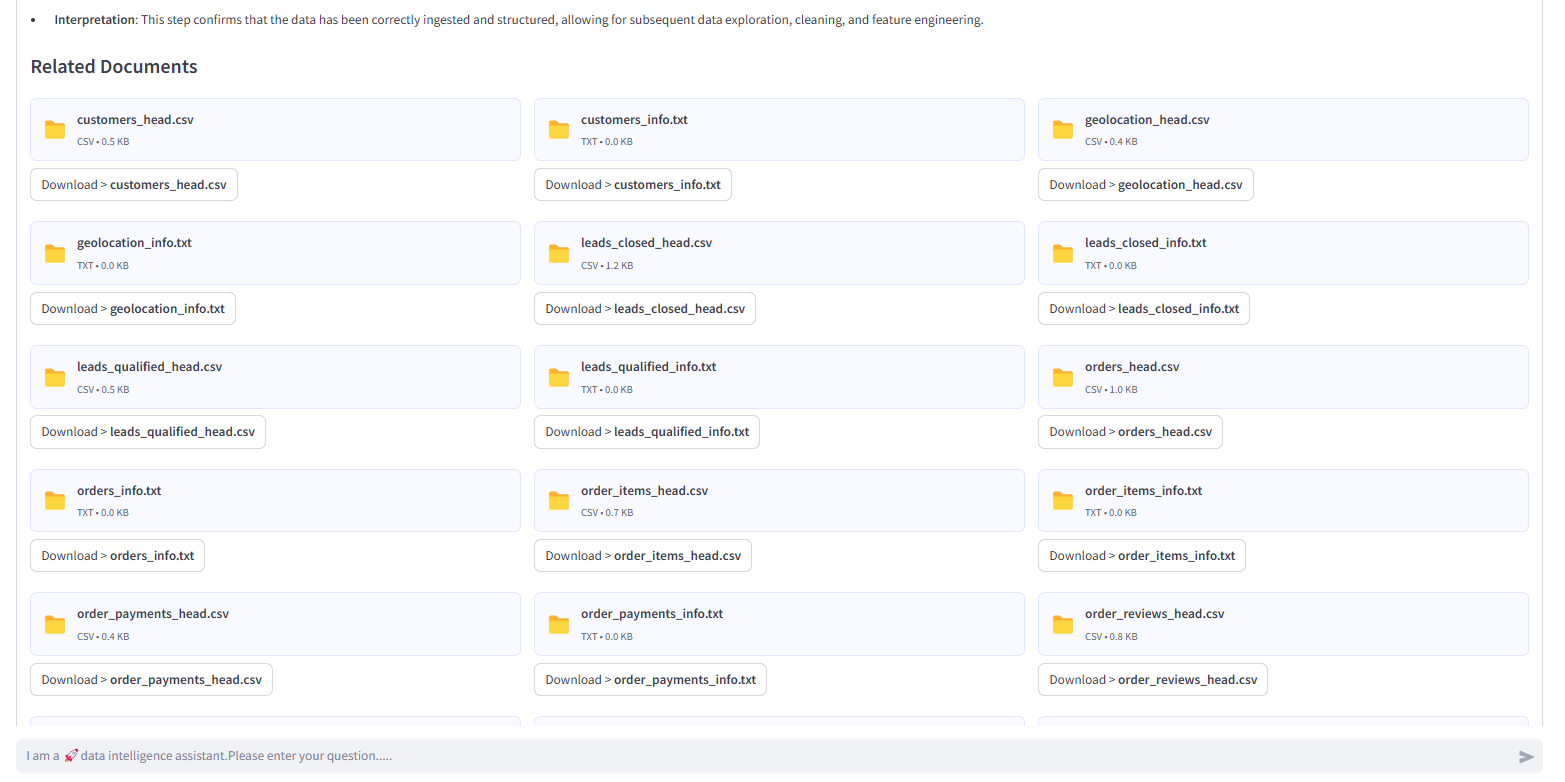
-
中间结果
1)sql合并生成所需要的数据文件
2)数据分析结果
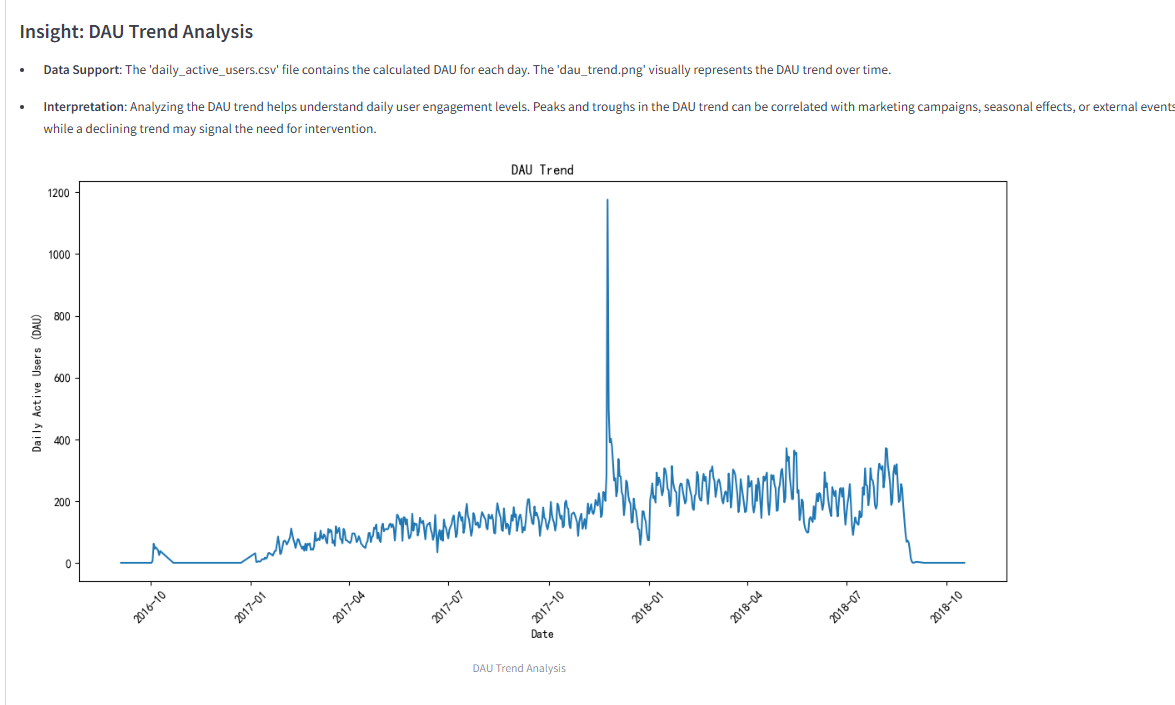
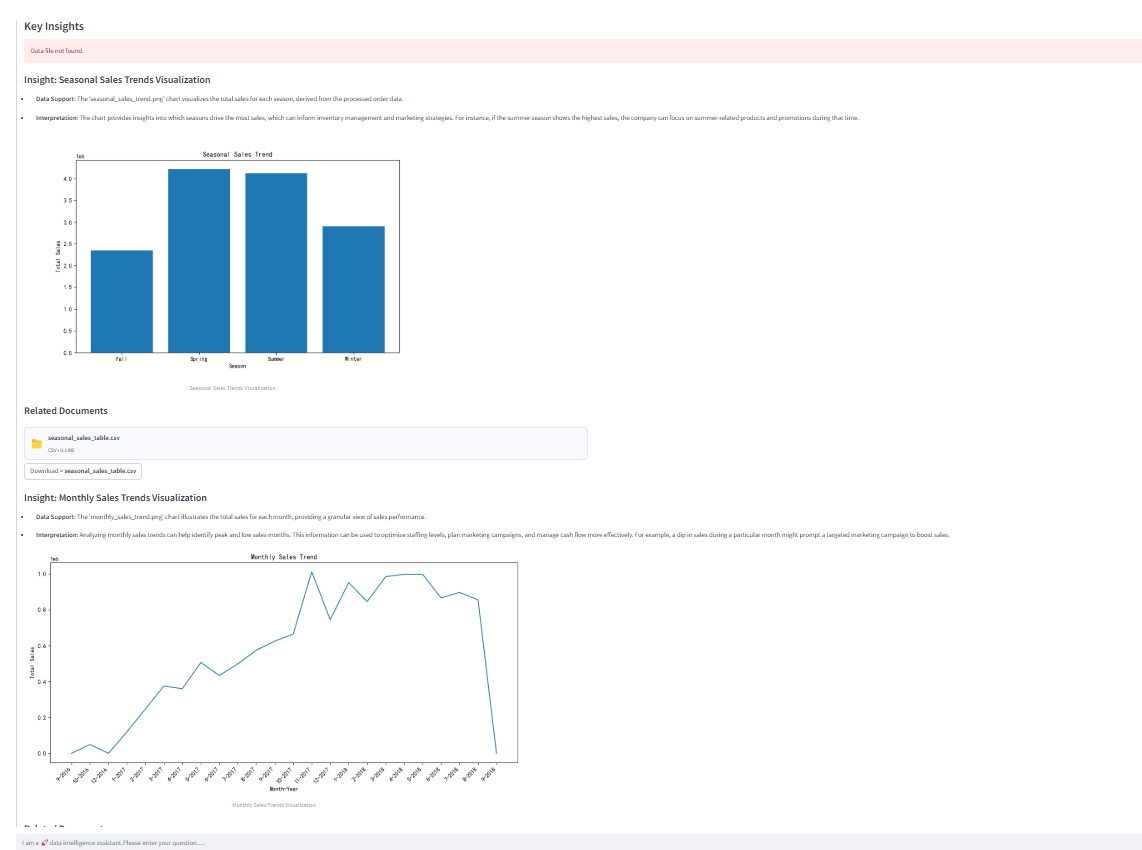
总结与讨论
技术可行性
从产品实践部分展示的案例来看,"Multi Agents Collaboration OS"的技术路线具备明确的可行性。系统通过结合检索增强生成(RAG)技术,成功将外部知识库(如农业市场、零售行业分析方法)融入任务流程,克服了大型语言模型在特定领域知识上的短板。实践中,系统能够根据用户输入和检索到的知识,自主进行多步骤的任务规划(如数据检索、调用pandas_data_analy或sql_agents进行分析、生成报告),并协调不同的智能体(Agent)分步执行代码完成任务。这验证了通过LLM进行规划、RAG提供知识、Agent执行具体操作的协同模式,足以支撑起自动化数据分析等工作流场景。
瓶颈
尽管前景广阔,当前技术仍面临若干瓶颈。首先,大型语言模型的上下文窗口长度限制了其处理极其复杂或长链条任务的能力,过多的历史信息、检索知识和中间结果可能导致信息丢失或处理失败。其次,虽然LLM具备代码生成能力(如生成SQL查询或Python分析脚本),但其生成代码的准确性、效率和安全性在面对复杂逻辑和边缘情况时仍有待提高,直接执行存在风险。此外,知识库的构建、更新和质量管理是一项持续挑战,RAG的效果强依赖于知识库的质量。最后,多智能体间的状态同步、错误传递与处理、资源竞争等协同问题,也需要更鲁棒的机制来保障整体流程的稳定性。
未来方向
未来,"Multi Agents Collaboration OS"有望在以下几个方向深化发展。一是更智能的知识融合,超越简单的文档块检索,探索与知识图谱、数据库等结构化知识源的深度融合,实现更精准、动态的上下文理解和推理。二是更高阶的数据分析自动化,从执行用户指令向更主动的洞察发掘演进,智能体不仅能完成分析任务,还能基于数据特征主动推荐分析维度、解释结果、甚至自主学习优化分析流程。三是大小模型协同的数据工程,结合大型语言模型(LLM)的理解、规划能力与小型专业模型(SLM)或传统代码的高效、稳定执行能力,构建混合智能系统,侧重于将这种协同能力应用于复杂的数据清洗、ETL、数据治理等数据工程领域,实现更高效、可靠的数据全链路自动化。