**全文链接:**https://tecdat.cn/?p=41391
在当今数据驱动的时代,数据科学家面临着处理各种复杂数据和构建有效模型的挑战。本专题合集聚焦于有序分类变量处理、截断与删失数据回归分析以及强化学习模型拟合等多个重要且具有挑战性的数据分析场景,旨在为数据科学家提供全面且深入的解决方案**(** 点击文末"阅读原文"获取完整代码、数据、文档******** )。
在有序分类变量处理方面,传统处理方式容易丢失顺序信息或忽略间距不等和非线性响应问题。本专题合集通过构建简单线性系数模型和狄利克雷超先验分配器模型,对比展示了模型在考虑有序分类特征非等距特性上的优势,为处理此类复杂数据关系提供了更可靠的方法。
对于截断与删失数据回归分析,传统线性回归会低估回归斜率。专题合集引入截断回归模型和删失回归模型,通过合理调整似然函数,有效解决了偏差问题,为处理截断或删失数据提供了更准确的回归分析结果。
在强化学习模型拟合到行为数据部分,专题合集利用 PyMC进行贝叶斯后验估计,不仅能得到学习参数的估计值,还能获取参数值周围合理不确定性的信息。同时,提供了使用伯努利似然的替代模型,实现了先验和后验预测采样以及模型比较。
本专题合集已分享在交流社群,阅读原文进群和 500 + 行业人士共同交流和成长。
pymc3对医疗健康 数据集的分析:简单线性模型与狄利克雷超先验分配器模型对比及非等距特征关系捕捉研究|附数据代码
在实际生活中,人们的各种决策以及经济活动,常常涉及在有限的选项中表达自己的顺序偏好。比如在选择商品时,我们可能会对不同品牌的同类产品按照喜好程度进行排序;在评价服务质量时,也会给出从差到好的不同等级评价。在数据领域,尤其是在保险和医疗健康等行业,我们经常会遇到这样的情况:数据集中的某个预测特征是一个有序分类变量,它要么记录着人们的某种偏好,要么是对某个度量值的概括总结。就好比对健康状况进行自我评分,从 "差" 到 "好" 划分几个等级,或者把年龄划分为不同的区间。
但是,这类有序分类变量存在一些问题。首先,它们的类别值与其顺序等级和目标变量之间,并不一定存在线性关系。就拿常见的4级李克特量表来说,"强烈同意"(等级为4)对目标变量的影响,可不一定是 "同意"(等级为3)的影响再加上1这么简单,即3 + 1并不等于4。其次,不同顺序类别之间的度量距离是不确定的,而且可能不相等。在这个4级李克特量表里,"不同意"和"同意"之间的差异,大概率和"同意"与"强烈同意"之间的差异不一样。
这些特性会误导模型构建者,他们可能会错误地将有序特征当作普通分类变量来处理(这样会导致失去顺序信息),或者当作数值系数来处理(忽略了间距不等和非线性响应的问题)。这两种处理方式都不太好,会对模型的性能产生负面影响。还有一种情况也很常见,就是在训练数据集中,可能不会出现所有有效的有序类别。比如,我们知道某个特征的取值范围是"c0", "c1", "c2", "c3",但实际数据中却只出现了"c0", "c1", "c3",这就产生了数据缺失问题,可能会进一步导致人们错误地用数值系数去平均或 "插值" 来处理这个缺失值。正确的做法是,把我们对数据领域的了解融入到模型结构中,自动估算出系数值。在本文用到的这个数据集中,就存在这样的问题(具体可查看第0节)!
本文的目的,就是要解决在面对这类有序特征时,如何推断出一系列先验分配器,将有序类别转换为线性(多项式)尺度,以及在捕捉到有序特征信息的基础上,像往常一样预测内生特征的问题。接下来,让我们一起看看具体是怎么做的吧。
数据处理与分析
在本次研究中,我们使用的是一个来自医疗健康领域的数据集,它最初以一种特殊的R语言二进制格式存储,并且被压缩打包。为了方便使用,我们需要将其下载、解压并转换为常见的CSV文件格式。这里借助了pyreadr这个实用的工具包来完成数据读取和格式转换的操作:
go
import pandas as pd
# 下载并解压数据
filehandle, _ = urllib.request.urlretrieve(url)
rbytes =这段代码的作用是,先从指定的网址下载数据文件,然后利用tarfile库解压文件,再通过pyreadr库读取其中的数据,并将其保存为CSV格式,方便后续处理。
原始数据集包含了很多健康相关的特征,为了简化研究,我们从中挑选了两个特征,暂且将它们记为特征1和特征2(原数据中为d450和d450),这两个特征用于衡量患者行走能力的受损程度,取值范围是从0到4,表示从"没有问题"到"完全有问题" 。我们的目标是利用这两个特征来预测另一个特征,记为目标特征(原数据中为phcs),它代表了一种主观的身体健康度量值。
值得注意的是,特征1的最高等级值4在数据集中并没有出现这就意味着我们面临一个数据缺失的问题。如果不恰当处理,很可能会导致人们错误地采用数值系数来进行平均值计算或者"插值"处理,从而影响模型的准确性。为了解决这个问题,我们需要将对数据领域的理解融入到模型结构中,以实现对系数值的自动估算,确保模型在遇到包含该缺失值的新数据时,依然能够进行有效的预测。
拿到数据集后,我们需要对其进行清洗和预处理。因为数据集中的特征1和特征2最初是以整数形式存储的,这对于我们后续的分析不太方便,所以要将它们转换为字符串表示,并设置为有序分类的数据类型。例如,对于特征1,我们通过以下代码进行转换:
go
ft = "d450"
idx = df\[ft\].notnull()这段代码首先筛选出特征1中不为空的索引,然后将这些索引对应的值转换为以"c"开头加上原数值的字符串形式。接着,定义了所有可能的类别等级列表,最后将特征1转换为有序分类变量,并且确保包含了在数据领域中存在但在当前数据集中未观测到的"c4"类别。对特征2也进行类似的操作,以统一数据格式,方便后续分析。
完成数据清洗后,我们对数据集进行了一些初步的探索性数据分析(EDA)。先来看目标特征的单变量分析,通过以下代码绘制小提琴图来展示其分布情况:
从生成的图(图1)中可以观察到,目标特征是一个主观评分的身体健康度量值,其分布呈现出单峰且较为平滑的状态,这表明该数据在一定程度上具有较好的规律性,为后续的建模分析提供了一定的基础。
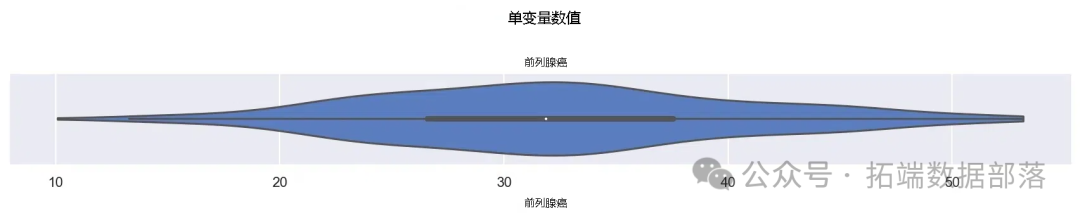
图1:目标特征的单变量分析小提琴图
随后,我们分析了目标特征与特征1、特征2之间的关系。通过以下代码绘制箱线图和计数图来直观展示:
在目标特征与特征1的关系图(图2)中,我们可以看到,"c0"类别对应的目标特征分布范围更广且数值较高,这可能是一个包含较多情况的类别,因为其观测数量也较多;"c3"类别的计数相对较少;而"c4"类别在数据中未被观测到,尽管它在数据领域中是有效的。
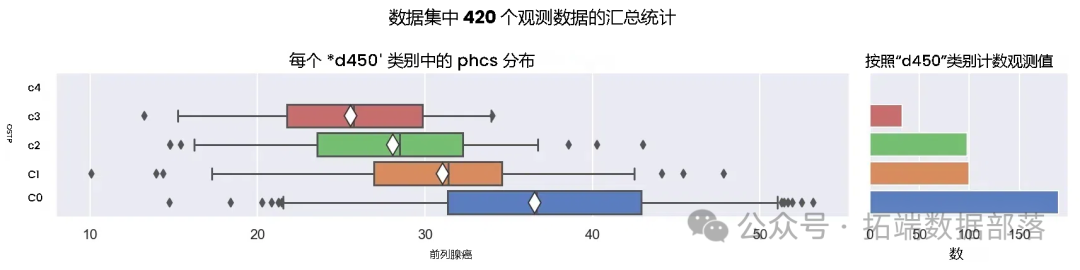
图2:目标特征与特征1的关系图
在目标特征与特征2的关系图(图3)中,"c1"和"c2"类别看起来非常相似,"c4"类别的计数较少。这些观察结果为我们后续选择合适的模型提供了重要的参考依据。

图3:目标特征与特征2的关系图
为了将数据集转换为适合模型输入的格式,我们进行了一系列操作。首先,将有序分类变量映射为基于其已有分类顺序的有序数值(整数)
然后,对数值型特征进行标准化处理,使其具有零均值和单位方差
经过这些处理后,数据集dfx就可以作为模型的输入数据了。
模型构建与分析
模型A:简单线性系数模型(错误示范)
首先,我们构建了一个简单线性模型,即模型A。在这个模型中,我们虽然认识到分类特征是有序的,但却错误地忽略了因素值对系数的影响可能并非等间距的问题,而是简单地假设了等间距。该模型的数学表达式如下:

其中,(\sigma_{\beta})表示(\beta)的标准差,服从逆伽马分布;(\beta)是模型的系数,服从正态分布;(\text{lm})是线性子模型;(\epsilon)表示误差项,服从逆伽马分布;(\hat{y_{i}})是对目标变量的估计值,服从正态分布。在这个模型中,(\mathbb{x}{i,d450})和(\mathbb{x}{i,d455})被错误地当作数值特征来处理。
接下来,我们使用代码构建这个模型对象:
go
COORDS = dict(oid=dfx.index.values, y\_nm=ft\_y, x\_nm=fts\_x)
with pm.Model(coords=COORDS) as mdla:这段代码首先定义了目标特征和自变量特征的名称,以及坐标信息。然后在pm.Model环境中,创建了数据容器用于观测数据(目标特征y和自变量特征x),定义了系数(\beta)的先验分布(逆伽马分布和正态分布),以及误差项(\epsilon)的先验分布(逆伽马分布),最后通过pm.Normal定义了目标特征的似然函数,将线性模型的预测值与观测值联系起来。
构建好模型后,我们对其进行了一系列诊断分析。首先是采样先验预测值并查看诊断结果
在查看先验预测的结果时,我们发现预测值虽然范围合理,但具体数值与真实值相差较大,这是符合预期的,因为此时模型还未经过训练。
随后,我们进行了后验采样并查看诊断结果。先通过以下代码进行后验采样和PPC(后验预测检查):
从后验采样的结果来看,模型的样本混合情况良好,各项诊断指标表现也较为合理。例如,从迹图(图4)中可以看出,样本的轨迹较为平稳,没有出现明显的异常波动,这表明模型的采样过程是稳定可靠的。
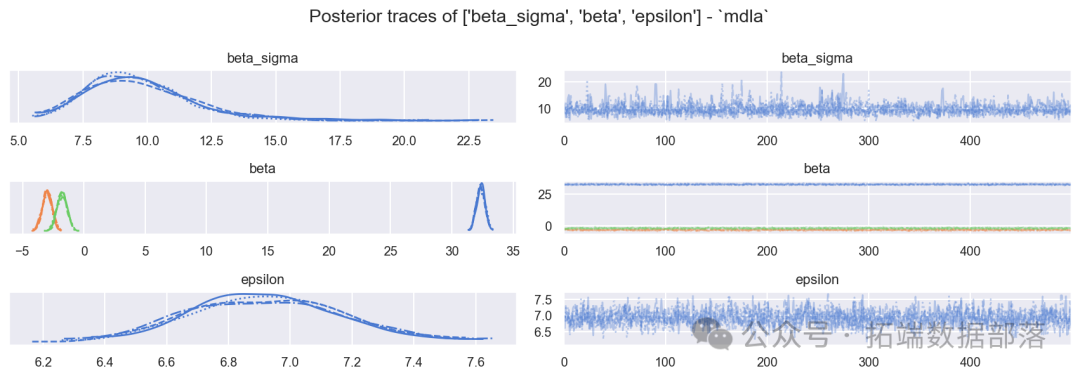
图4:模型A后验迹图
在查看模型的能量图(图5)时,发现其边际能量和能量转换看起来也较为合理,这进一步说明了模型的稳定性。

图5:模型A能量图
点击标题查阅往期内容


左右滑动查看更多
01
02
03
04

此外,通过计算得到的有效样本量(ess_bulk)和R-hat值都在合理范围内,表明模型的收敛性较好。从样本的后验预测检查结果(图6)来看,模型的预测值与观测值有一定的拟合度,但存在稍微的过度分散现象,这可能意味着使用具有更厚尾的似然函数(如学生t分布)会更加合适。
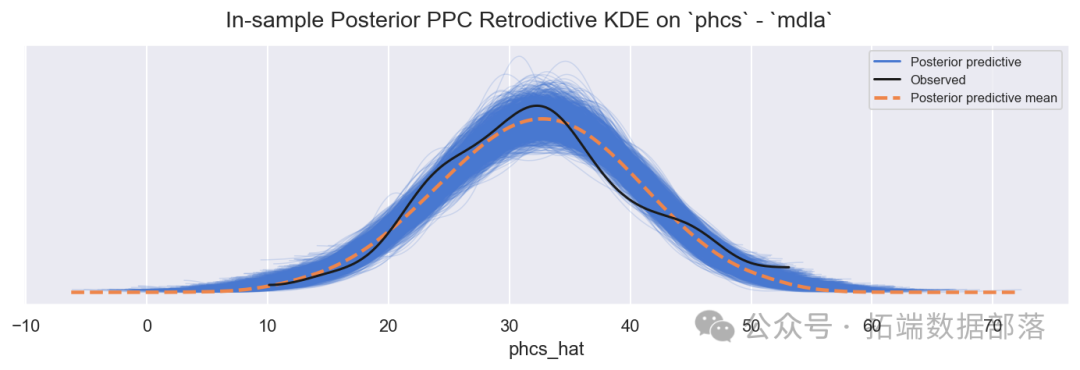
图6:模型A样本内后验PPC(回顾性检查)
再看样本内PPC的LOO-PIT(留一交叉验证预测信息准则)结果(图7),其看起来表现良好,虽然也存在稍微的过度分散,但在可接受范围内,说明模型在一定程度上具有较好的预测性能。
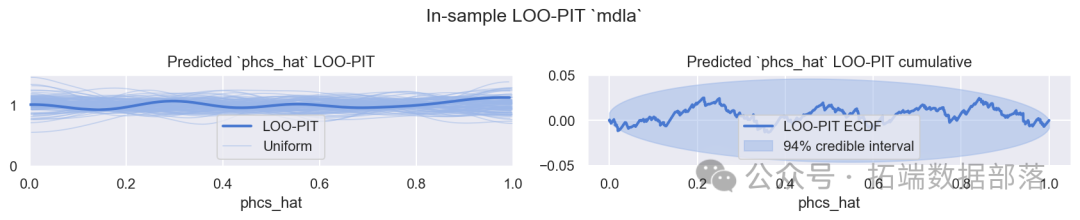
图7:模型A样本内PPC LOO-PIT
最后,我们对模型的后验参数进行评估。通过分析后验参数的分布(图8),我们可以得到一些有用的信息。例如,beta_sigma的期望值约为10,这表明在模型中,(\beta)的位置需要较高的方差;beta: intercept的期望值约为32,这说明(\beta)位置的大部分方差是由于将标准化后的值调整到目标特征phcs的范围内所需的截距偏移导致的,这是合理的;beta: d450_num为负数,其94%最高密度区间(HDI94)不包含0,说明该特征对目标特征有显著影响,且随着d450_num值的增加,phcs_hat会减小;beta: d455_num同样为负数,HDI94不包含0,也有显著影响,只是随着d455_num值的增加,phcs_hat的减小幅度相对较小;epsilon的期望值约为7,这表明数据中仍然存在较多未被模型特征解释的方差。

图8:模型A后验参数分布
为了进一步验证模型的性能,我们在简化的预测集上创建了PPC预测。首先,我们将数据集替换为预测集dffx并重新构建模型,然后进行后验预测采样:
从预测结果(图9)来看,模型虽然能够对未在数据中出现的d450=c4情况进行预测,但这种预测是基于纯粹的线性外推,在当前模型设定下,可能会产生完全错误且具有误导性的结果。同时,我们可以看到模型对d450和d455作为数值特征处理时呈现出的线性响应和等间距特性。此外,我们绘制了每个数据点的完整后验分布,这强调了数据和模型中仍然存在大量的方差。
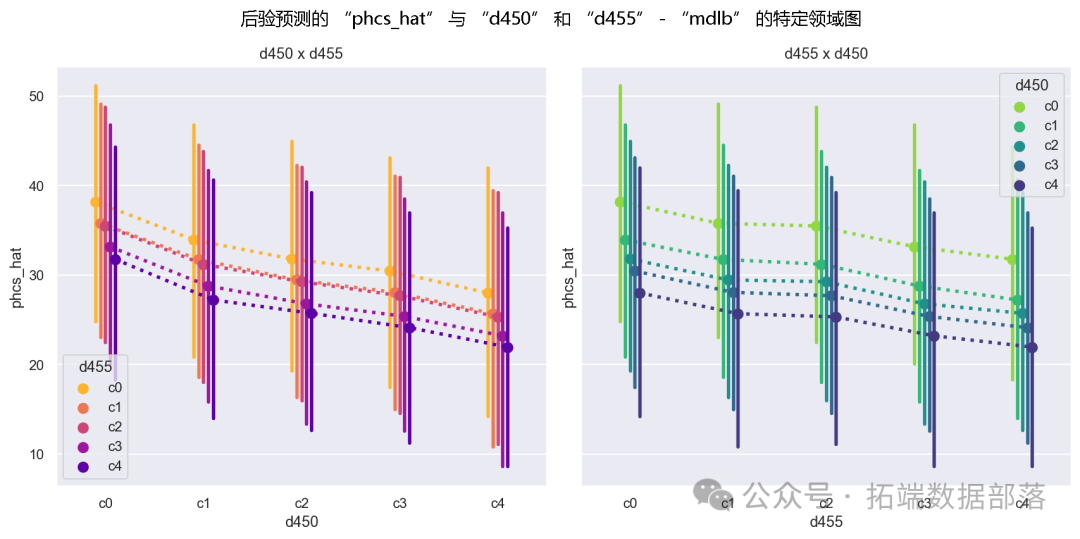
图9:模型A在预测集上的预测结果
模型B:狄利克雷超先验分配器模型(改进方案)
鉴于模型A存在的问题,我们构建了一个改进的线性模型,即模型B。在这个模型中,我们不仅认识到分类特征是有序的,还考虑到有序值之间的间距可能不相等。例如,可能存在(A > B > C),但它们之间的间距并非等距,而是(A >>> B > C)这种非等距关系。为了实现这一点,我们使用狄利克雷超先验来分配线性系数的异质间隔部分,模型的数学表达式如下:

其中,(\lambda_{1})和(\lambda_{2})是狄利克雷分布的随机变量,用于生成非等距的间隔系数(\delta)。这些(\delta)值会根据分类变量的不同类别,动态地调整线性模型中对应特征的系数权重,从而更灵活地捕捉特征与目标变量之间的关系。
接下来通过代码构建模型B对象:
这段代码首先定义了目标特征和自变量特征名称以及坐标信息。在pm.Model环境中,创建了数据容器用于观测数据(目标特征y和自变量特征x),定义了系数(\beta)的先验分布(逆伽马分布和正态分布),以及误差项(\epsilon)的先验分布(逆伽马分布)。然后通过狄利克雷分布生成(\lambda)变量,再基于(\lambda)构建非等距的(\delta)变量,最后利用这些变量构建线性模型部分,并通过pm.Normal定义目标特征的似然函数。
与模型A类似,构建好模型B后,同样需要对其进行一系列诊断分析。先进行采样先验预测值并查看诊断结果,通过以下代码实现:
go
with mdlb:
idb\_ida = pm.sample\_prior_predictive(
var\_names=RVS\_PPC + RVS\_SIMPLE\_COMMON,
samples=2000,
return_inferencedata=True,
random_seed=42,
)在查看先验预测结果时,如同模型A,预测值范围虽合理但与真实值相差大,这是模型未训练的正常表现。
接着进行后验采样和PPC:
go
pm.sample\_posterior\_predictive(trace=idb\_ida.posterior, var\_names=RVS_PPC)从后验采样结果来看,模型B的样本混合情况和各项诊断指标同样表现良好。迹图中样本轨迹平稳,没有明显异常波动,表明采样过程稳定可靠。能量图中的边际能量和能量转换也较为合理,体现了模型的稳定性。有效样本量(ess_bulk)和R - hat值在合理范围内,证明模型收敛性佳。
在样本内后验预测检查方面,模型B的预测值与观测值拟合度有所提升,过度分散现象相比模型A有所改善。从样本内PPC的LOO - PIT结果来看,表现良好,进一步说明模型在预测性能上相较于模型A有一定进步。
再分析模型B的后验参数,通过对后验参数分布的研究,可以发现与模型A不同的特征影响模式。例如,beta_sigma的期望值与模型A有所差异,反映出模型B中(\beta)位置所需方差的不同设定。beta: intercept的期望值也因模型结构改变而变化,beta: d450_idx和beta: d455_idx的系数正负及HDI94范围同样呈现出与模型A不同的特征影响情况,这表明模型B通过狄利克雷超先验分配器能够更灵活地捕捉特征与目标变量之间的复杂关系。
为了评估模型B在预测集上的表现,与模型A一样,在简化的预测集上创建PPC预测。先将数据集替换为预测集dffx并重新构建模型,再进行后验预测采样:
从预测结果(图10)来看,模型B能够更合理地处理未在数据中出现的d450 = c4等情况,预测结果不再像模型A那样基于简单线性外推产生可能误导性的结果。它对d450和d455特征的响应更加符合数据的潜在规律,进一步展示了狄利克雷超先验分配器在捕捉非等距特征关系上的优势。同时,绘制的每个数据点的完整后验分布也显示出,相比模型A,模型B对数据中方差的解释能力有所增强。
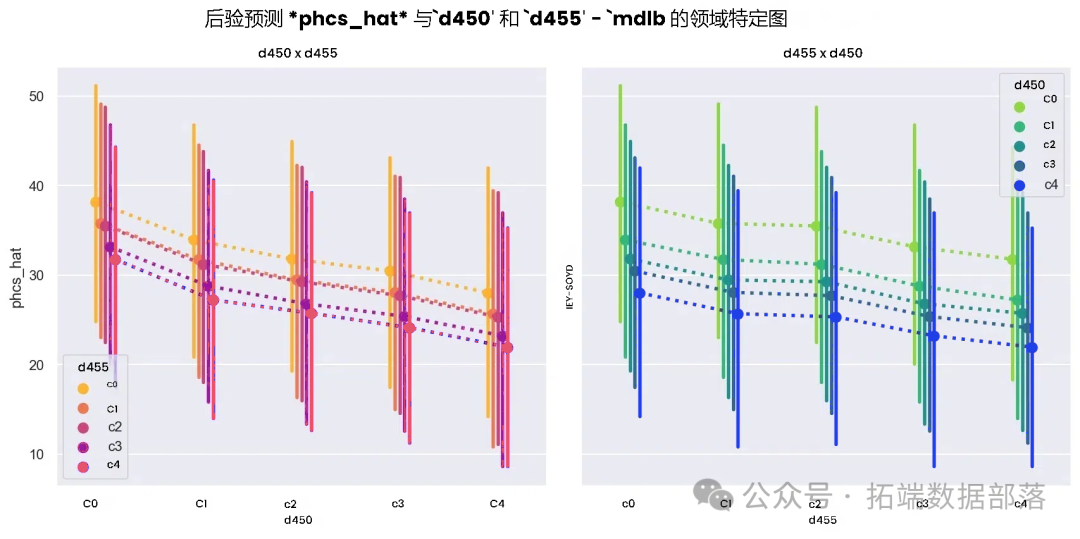
图10:模型B在预测集上的预测结果
通过对比模型A和模型B在数据处理、模型构建、诊断分析以及预测性能等多方面的表现,可以明显看出模型B由于考虑了有序分类特征的非等距特性,在处理复杂数据关系和预测未知情况时具有更好的性能和可靠性,为后续更准确的数据分析和预测任务提供了有力支持。
模型应用拓展与潜在改进方向
在实际应用场景中,模型B展现出了相较于模型A的优势。例如,在医疗健康领域,如果该模型用于预测患者基于某些症状或指标(如特征1和特征2所代表的类似情况)的身体健康评分(目标特征phcs),模型B能够更准确地考虑不同症状严重程度之间可能存在的非等距关系,从而为医生提供更具参考价值的预测结果,辅助诊断决策。
然而,模型B仍然存在一些潜在的改进方向。一方面,虽然狄利克雷超先验分配器在一定程度上解决了特征间距非等距问题,但对于一些极端复杂的数据关系,可能需要进一步优化超先验的参数设置或采用更复杂的超先验分布。例如,可以尝试基于数据驱动的方法来动态调整狄利克雷分布的参数,而不是固定设置为均匀的alpha值。另一方面,当前模型仅考虑了两个主要特征与目标特征的关系,在实际应用中可能存在更多相关特征。未来可以探索如何将更多的特征合理地纳入模型中,同时要注意避免因特征过多导致的过拟合问题。可以采用特征选择算法,如基于Lasso回归的特征选择,先筛选出最具影响力的特征,再将其加入模型,以提高模型的泛化能力和预测准确性。
此外,模型在处理缺失数据方面虽然采取了一些初步措施,但仍有提升空间。对于大量缺失数据的情况,当前方法可能不够稳健。可以研究一些先进的缺失数据处理技术,如多重填补法,通过多次模拟缺失值并综合多个填补结果来提高模型对缺失数据的适应性。同时,在模型评估指标方面,除了目前使用的一些诊断指标和后验预测检查指标外,可以引入更多与实际应用场景紧密相关的指标,如在医疗领域引入临床决策相关的指标,以更全面地评估模型在实际应用中的性能。
含截断或删失数据的贝叶斯回归分析|附数据代码
在数据的海洋里"航行",我们常常会遭遇各种复杂状况,其中数据的截断与删失问题,就如同潜藏在海面下的暗礁,给数据处理与分析带来诸多挑战。接下来,就让我们一同深入探索如何在结果变量存在截断或删失的情况下,巧妙运用贝叶斯回归分析,精准地驾驭数据之船,驶向正确的方向。
数据准备与基础概念
进行回归分析前,得先把"工具"准备好。在Python的世界里,我们需要导入一系列强大的库。就像工匠开工前要准备好锤子、钉子等工具一样,我们通过以下代码导入处理数据、构建模型、可视化结果等所需的库
这些库各有所长,arviz能帮我们进行统计推断和可视化分析;matplotlib.pyplot用于绘制各种精美的图表;numpy提供高效的数值计算功能;pymc则是构建贝叶斯模型的得力助手;xarray方便处理带有标签的多维数组数据;default_rng用于生成随机数;norm和truncnorm分别是正态分布和截断正态分布的相关工具。
截断与删失的概念
理解截断和删失这两个概念,对于后续的分析至关重要。简单来说:
-
截断:想象我们在收集一群学生的考试成绩,但只记录了成绩在60分到90分之间的数据,对于低于60分和高于90分的成绩,我们完全不知道它们的存在,这就是数据的截断现象。
-
删失 :同样是学生成绩,如果规定成绩最高只能记录为100分,那么当有学生考了105分,我们也只能记录为100分,这就是删失。删失并不是丢弃这些超出范围的数据,而是将其记录为边界值。
为了更直观地感受,我们通过代码生成一些模拟数据,就像在实验室里模拟真实的场景一样。以下代码生成了一些真实的散点数据
(x, y),其中y是结果变量,就好比学生的考试成绩;x是预测变量,类似学生平时的学习时间等可能影响成绩的因素:
go
# AI提示词:请生成一段Python代码,用于生成模拟的截断和删失数据的线性回归分析所需的真实散点数据,包括斜率、截距、标准差和数据点数量的设定
slope, intercept, σ, N = 1, 0, 2, 200
x = rng.uniform(-10, 10, N)
y = rng.normal(loc=slope * x + intercept, scale=σ)这里设定了斜率为1,截距为0,标准差为2,生成了200个数据点。通过rng.uniform函数生成在-10到10之间均匀分布的x值,再利用rng.normal函数根据线性关系y = slope * x + intercept加上正态分布的噪声生成y值。
截断与删失的实现
为了对生成的数据进行截断和删失处理,我们需要编写相应的函数,这就如同打造专门的工具来处理特定的材料。以下是定义的两个函数:
go
# AI提示词:请生成一个Python函数,用于对给定的x和y数据进行截断处理,根据指定的边界值筛选出符合条件的数据
def truncate_y(x, y, bounds):
return (x, cy)truncate_y函数会根据给定的边界bounds,筛选出y值在边界范围内的数据,就像用一个筛子把符合条件的数据筛出来。censor_y函数则是对超出边界的y值进行替换,将其变为边界值,如同给超出范围的数据套上一个"边界壳"。
我们设定边界为[-5, 5],然后使用这两个函数对生成的数据进行处理,得到截断数据(xt, yt)和删失数据(xc, yc):
此时,xt和yt是经过截断处理后的数据,xc和yc是经过删失处理后的数据。
为了直观地看到截断和删失的效果,我们将潜在数据(灰色)和处理后的数据(黑色)进行可视化,就像绘制一幅地图,清晰地展示不同区域的数据情况:
运行这段代码后,会生成一个包含两个子图的图表(如图1所示)。左边子图展示了截断数据的情况,右边子图展示了删失数据的情况。潜在数据用灰色点表示,截断和删失后的数据用黑色点表示,同时用红色虚线标注出了边界[-5, 5]。从图中可以清晰地看到截断是直接剔除了边界外的数据,而删失是将边界外的数据调整为边界值。
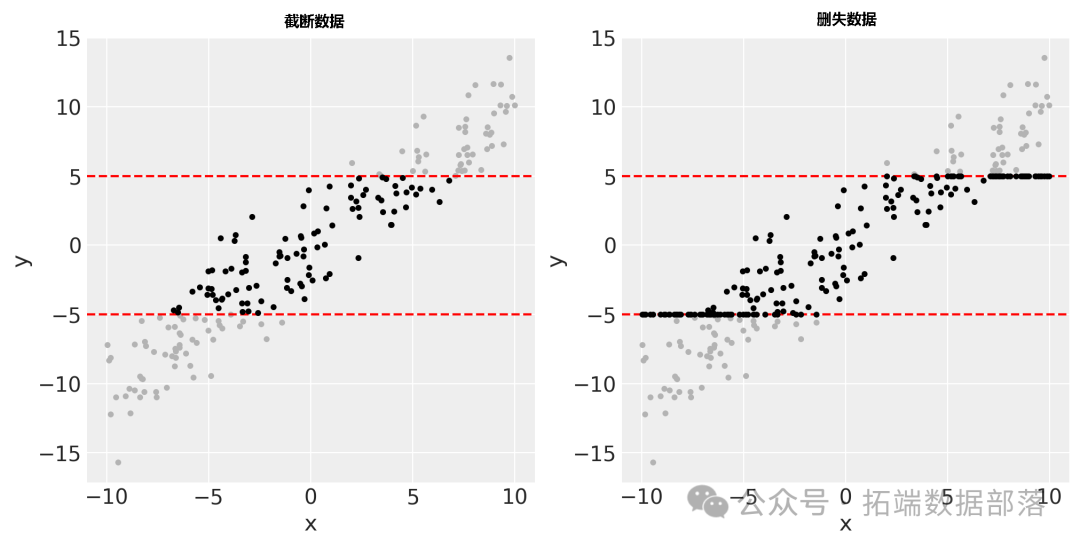
图1:截断和删失数据可视化
传统线性回归的问题
如果我们直接对截断或删失数据进行传统的线性回归分析,就好比驾驶一艘没有校准罗盘的船,很可能会偏离正确的航线,也就是会低估回归斜率。为了验证这一点,我们定义一个函数来进行贝叶斯线性回归分析,并分别对截断和删失数据进行分析:
在linear_regression函数中,我们使用pymc库构建了一个简单的贝叶斯线性回归模型。模型中假设斜率slope和截距intercept都服从正态分布,噪声标准差σ服从半正态分布,然后根据给定的x和y数据构建似然函数。接着,分别对截断数据(xt, yt)和删失数据(xc, yc)应用这个函数进行模型构建和采样。
通过绘制斜率参数的后验分布,我们可以看到传统线性回归对斜率的估计偏差较大,确实低估了回归斜率,就像看错了地图上的方向标识,导致路线判断错误:
运行这段代码后,会生成一个包含两个子图的图表(如图2所示)。左边子图展示了截断数据的线性回归中斜率参数的后验分布,右边子图展示了删失数据的情况。真实斜率用参考线表示,可以明显看出估计的斜率分布偏离了真实值,说明传统线性回归在处理截断和删失数据时存在偏差。
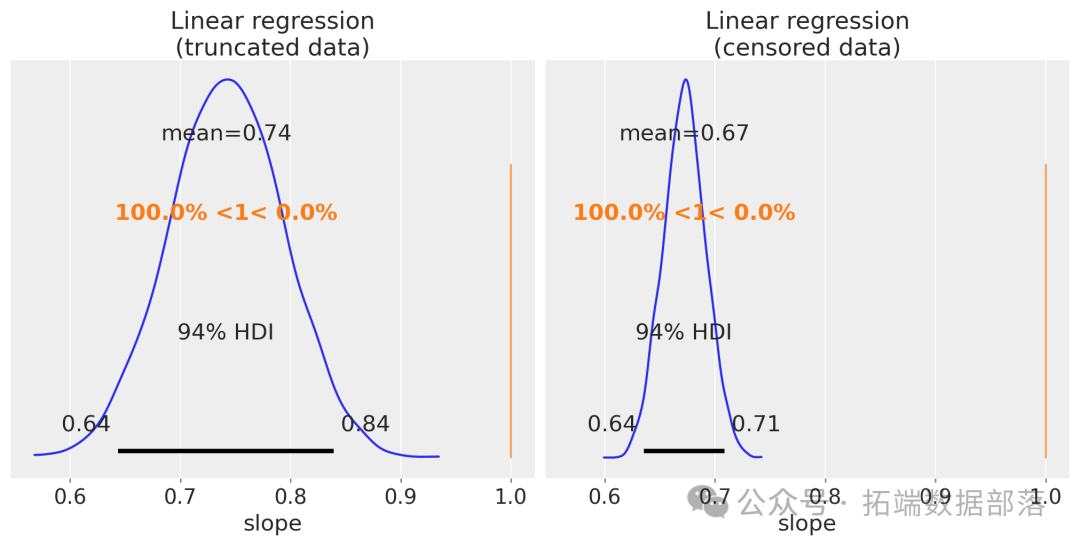
图2:传统线性回归斜率后验分布
为了更直观地观察问题的严重程度,我们还可以绘制后验预测拟合图,这就像是在地图上标记出根据错误判断的路线行驶的预测轨迹:
运行代码后生成的图表(如图3所示)中,每个子图都展示了数据点(黑色点)、后验预测拟合线(浅蓝色半透明线)、真实值线(黑色粗线)以及边界(红色虚线)。从图中可以直观地看到,后验预测拟合线与真实值线存在较大偏差,进一步说明了传统线性回归在处理截断和删失数据时的不足。
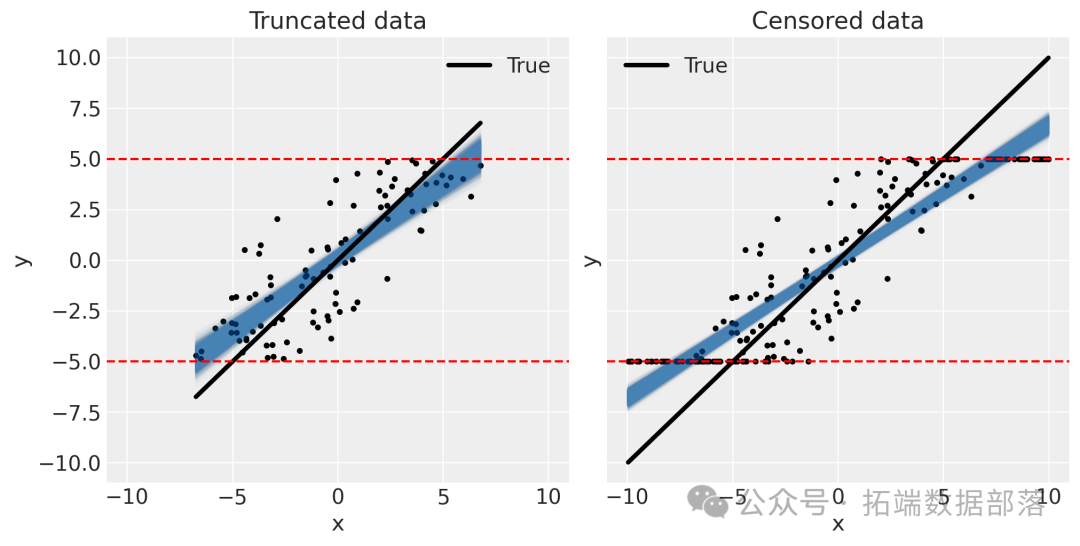
图3:传统线性回归后验预测拟合图
从这些图中,我们可以直观地预测出影响低估偏差程度的因素。比如,截断或删失边界越宽,就好比筛子的孔越大,影响的数据点越少,低估偏差就越小;测量误差越小,就像尺子刻度越精确,低估偏差也会相应减小。
截断和删失回归模型的实现
为了解决传统线性回归在处理截断或删失数据时的偏差问题,我们引入截断回归模型和删失回归模型,这就像是为船只换上了更精准的导航设备。
截断回归模型
截断回归模型的实现相对简单,我们只需要指定一个在边界处截断的正态分布,就像给正态分布戴上了"边界枷锁":
在这个函数中,我们先定义了斜率、截距和噪声标准差的分布,然后构建了一个正态分布normal_dist,最后使用pm.Truncated将其截断,使其符合截断数据的特点。
通过更新似然函数,截断回归模型解决了偏差问题。我们可以通过绘图直观地比较正态分布和截断正态分布的概率密度,就像对比两种不同形状的曲线:
go
# AI提示词:请生成一段Python代码,用于绘制正态分布和截断正态分布的概率密度对比图,展示截断正态分布在截断边界外概率密度为零的特点
fig, ax = plt.subplots(figsize=(10, 3))
y = np.linspace(-4, 4, 1000)
ax.fill_between(y, norm.pd运行代码后生成的图表(如图4所示)中,蓝色区域表示正态分布的概率密度,红色区域表示截断正态分布的概率密度,垂直虚线表示截断边界。可以清晰地看到,截断正态分布在截断边界外的概率密度为零,这符合截断数据的特性。
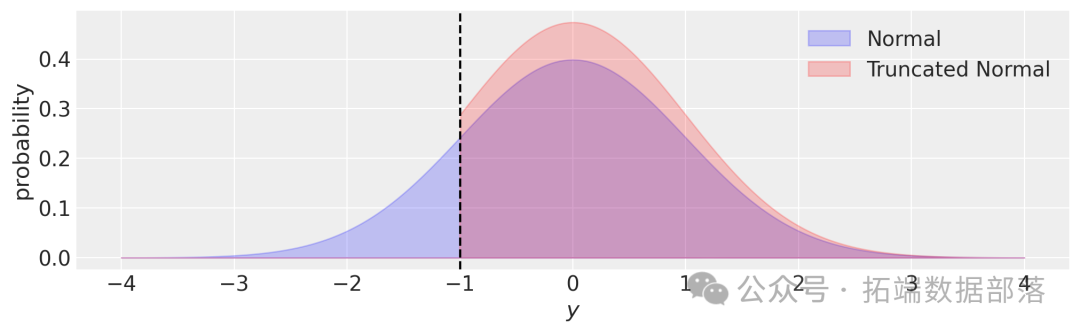
图4:正态分布与截断正态分布概率密度对比
删失回归模型
删失回归模型的实现也很直观,我们使用pm.Censored分布来调整似然函数,就像给似然函数加上了一个"删失滤镜":
在这个函数中在这个函数中,我们同样先对斜率、截距以及噪声标准差设定分布,构建出潜在的正态分布y_latent。随后,借助pm.Censored对观测数据进行处理,让模型适配删失数据的特征。
pm.Censored分布会巧妙地调整似然函数,仔细考虑边界处的概率情况。为了直观展示这一特性,我们通过以下代码绘图:
运行上述代码后,生成的图表(图5)将呈现出未删失和删失情况下概率密度的差异。图中蓝色曲线代表未删失数据的概率密度,红色粗线代表删失数据的概率密度,垂直虚线指示出删失边界。从中可以明显看出,在边界处,删失数据的概率密度出现了独特的变化,体现了pm.Censored分布对边界概率的特殊处理。
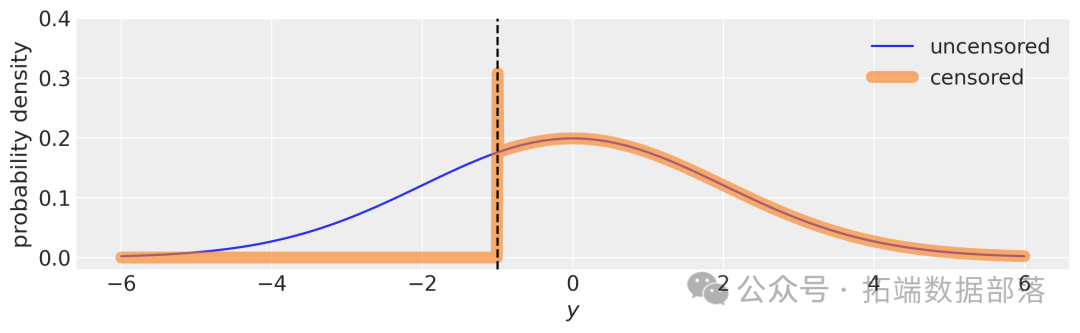
图5:未删失与删失概率密度对比
截断和删失回归的应用
理论构建完成后,接下来就是将截断回归模型和删失回归模型应用到实际数据中,看看它们能否真正解决传统线性回归的问题。我们分别对截断数据和删失数据使用相应的模型进行参数估计:
在这段代码里,我们先利用truncated_regression函数为截断数据(xt, yt)构建截断回归模型truncated_model,并通过pm.sample进行采样以获取参数估计结果truncated_fit。类似地,针对删失数据(xc, yc),使用censored_regression函数构建删失回归模型censored_model,并完成采样得到censored_fit。
通过绘制斜率参数的后验分布,我们能够直观地评估模型的效果。
运行上述代码后,生成的图表(图6)包含左右两个子图。左图展示了截断回归模型中斜率参数的后验分布,右图呈现了删失回归模型的相应情况。真实斜率以参考线形式给出。从图中能够清晰地看到,相较于传统线性回归,截断和删失回归模型对斜率的估计更加接近真实值,显著改善了估计效果。
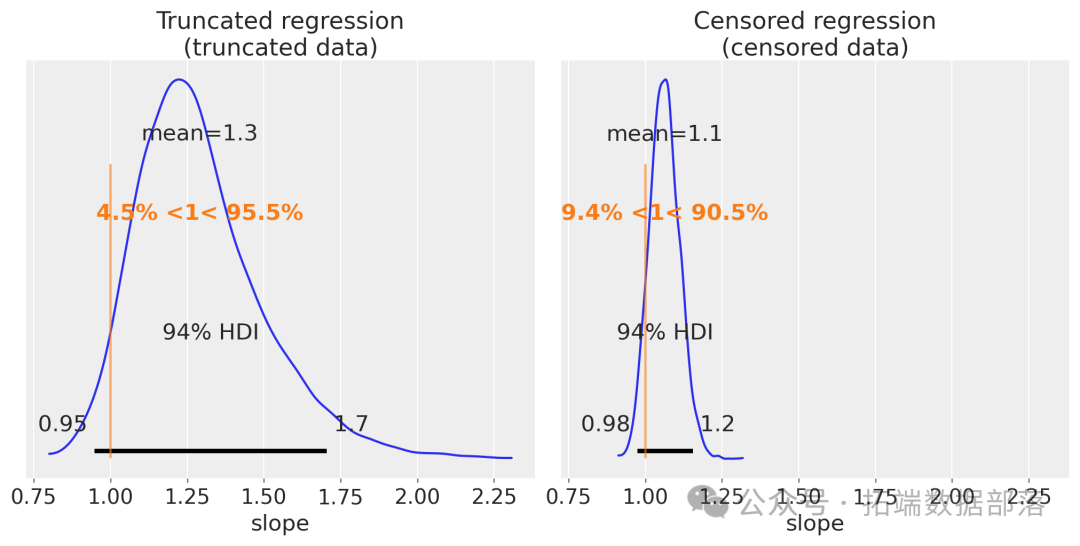
图6:截断和删失回归斜率后验分布
有趣的是,对比发现删失回归的估计结果通常比截断回归更精确。这背后的原因在于,截断操作会完全丢弃超出边界的数据,相当于扔掉了部分"拼图碎片";而删失只是部分数据未知,保留了更多"线索"。因此,如果实验者面临选择,从数据信息保留的角度考虑,删失处理往往是更优选择。
最后,我们通过后验预测图进一步验证模型的有效性:
运行这段代码后,生成的图表(图7)中,每个子图都呈现了数据点(黑色点)、后验预测拟合线(浅蓝色半透明线)、真实值线(黑色粗线)以及边界(红色虚线)。从图中可以直观地看出,截断和删失回归模型的后验预测拟合线与真实值线更为接近,充分验证了这两种模型在处理截断和删失数据方面的有效性和优越性。
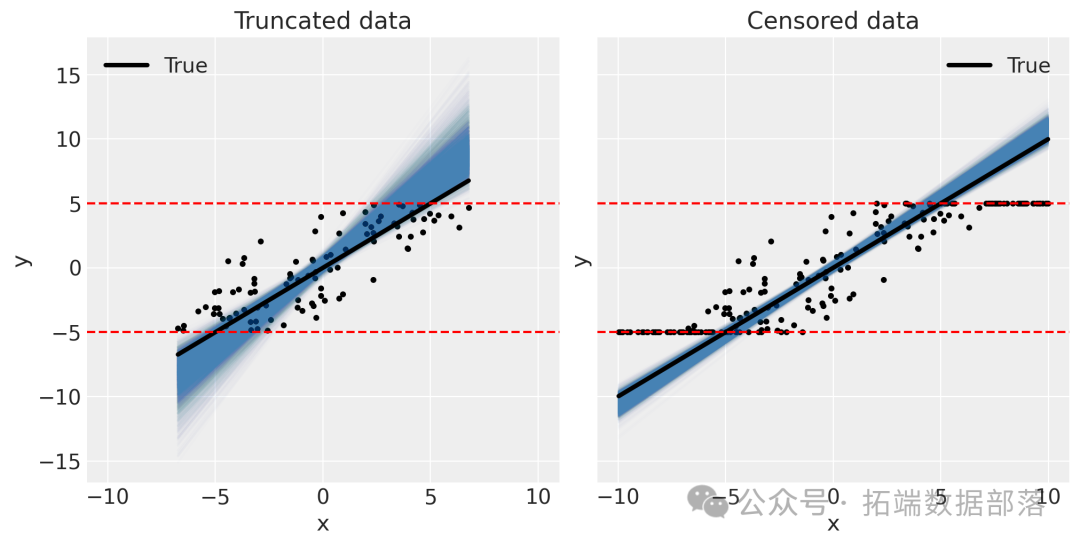
图7:截断和删失回归后验预测拟合图
综上所述,在处理截断或删失数据时,传统的线性回归方法犹如蒙眼行路,极易导致斜率估计偏差。而截断回归模型和删失回归模型则如同为我们擦亮了双眼,通过合理地调整似然函数,有效解决了这一棘手问题,为我们提供更准确的回归分析结果。在实际应用的广阔天地中,我们应依据数据的独特特点和现实需求,精准选择合适的模型,让数据发挥出最大价值,助力我们在数据分析的征程中稳步前行 。
利用 PyMC 将强化学习模型拟合到行为数据|附数据代码
在行为研究领域,强化学习模型是一个常用的工具,它可以帮助我们理解人类和动物是如何学习的。在现实中,人类和动物会不断做出选择,随后会收到各种反馈,比如奖励或者惩罚。就好比玩游戏时,每一次操作后都会得到相应的得分变化,这就是一种反馈。
在本文中,我们聚焦于最简单的学习场景,也就是只有两种可能行动的情况。每做出一个行动,都会立即得到奖励,并且每个行动的结果与之前的行动相互独立。这种场景也被叫做"多臂老虎机问题"。
假设这两种行动(比如按左边和右边的按钮)获得单位奖励的概率分别是 40% 和 60%。刚开始的时候,学习主体并不知道哪个行动更好,所以会先假设两个行动的平均价值都是 50%。我们可以用一个表格来记录这些值,这个表格通常被称为 Q 表:
Q = { 0.5, a = 左; 0.5, a = 右 }
当选择了一个行动并观察到奖励 r(r 取值为 0 或 1)后,该行动的估计值会按照以下公式更新:
Qa = Qa + α(r - Qa)
这里的 α 是一个学习参数,它会影响每次试验中行动值向观察到的奖励偏移的程度。最后,通过 softmax 变换将 Q 表中的值转换为行动概率:
P(a = 右) = exp(βQ右) / exp(βQ右) + exp(βQ左)
其中,β 参数决定了主体选择的随机性程度。β 值越大,选择就越确定;β 值越小,选择就越随机。
生成模拟数据
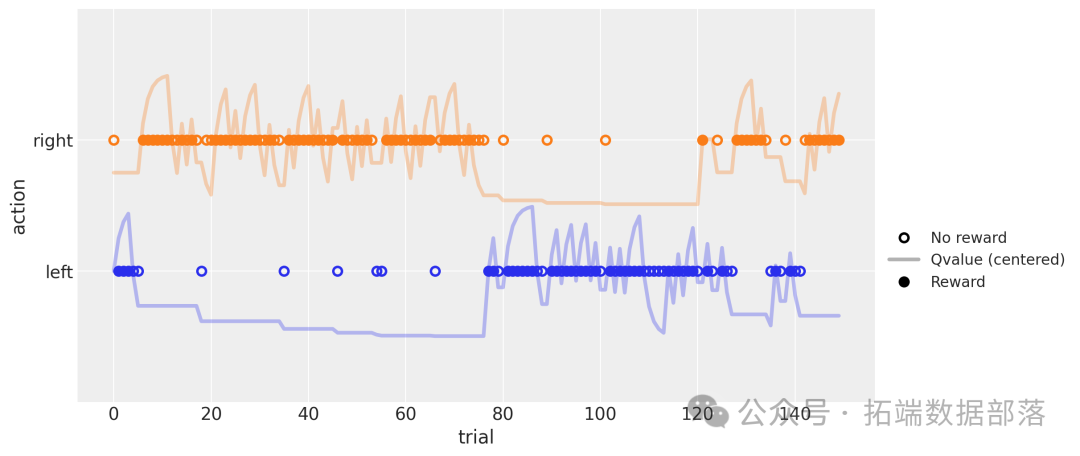
上图展示了 150 次试验的模拟过程,参数 α 为 0.5,β 为 5,左边(蓝色)和右边(橙色)行动的奖励概率分别固定为 0.4 和 0.6。实心点表示有奖励的行动,空心点表示无奖励的行动。实线表示每个行动的估计 Q 值,以相应颜色的点为中心(当 Q 值大于 0.5 时,线在点上方;反之则在下方)。可以看到,有奖励时 Q 值增加,无奖励时 Q 值减小。
α 参数直接影响每次结果后 Q 值的变化幅度。而 β 参数的影响相对难理解一些,可以这样想:β 值越大,主体越倾向于选择估计值最高的行动,即使两个行动的估计值差异很小;当 β 值接近 0 时,主体会随机选择行动,而不考虑行动的估计值。
通过最大似然估计学习参数
生成数据后,我们的目标是"反转模型"来估计学习参数 α 和 β。首先,我们使用最大似然估计(MLE)方法。这需要编写一个自定义函数,用于计算给定潜在的 α 和 β 以及固定观察到的行动和奖励时数据的似然值(实际上,为了避免下溢问题,该函数计算的是负对数似然值)。
这个 llik_td 函数和 generate_data 函数很相似,不过它不是模拟每个试验中的行动和奖励,而是存储观察到的行动的对数概率。scipy.special.logsumexp 函数用于更稳定地计算 logexp(βQ右) + exp(βQ左) 这一项。最后,函数返回所有对数概率的负和,这相当于在原始尺度上乘以概率。
估计得到的 MLE 值与真实值比较接近。但是,这种方法无法给出这些参数值周围的合理不确定性信息。为了得到这些信息,我们将使用 PyMC 进行贝叶斯后验估计。
通过 PyMC 估计学习参数
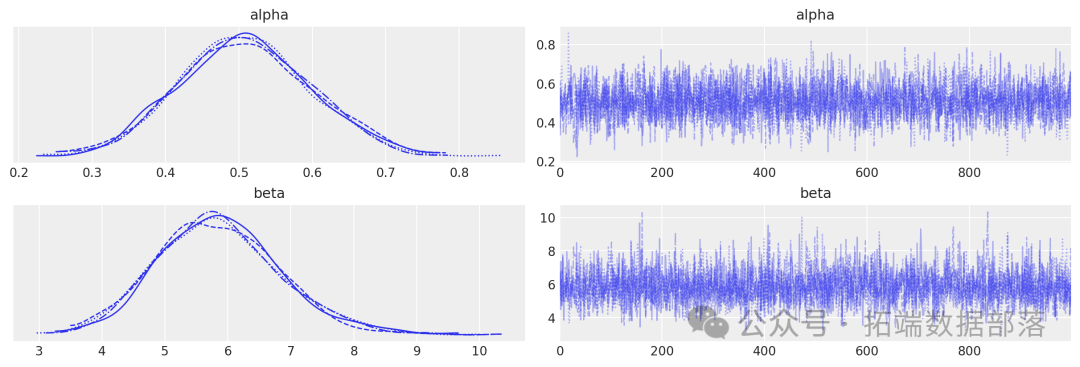
在使用 PyMC 采样参数时,最具挑战性的部分是创建一个 PyTensor 函数或循环来估计 Q 值。
得到了相同的结果,这说明 PyTensor 循环正常工作。现在我们可以实现 PyMC 模型了。
go
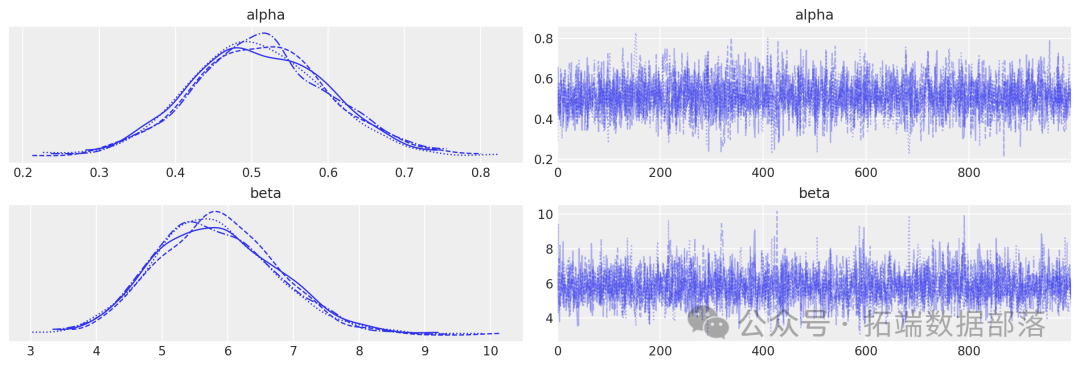
az.plot\_posterior(data=tr, ref\_val=\[true\_alpha, true\_beta\]);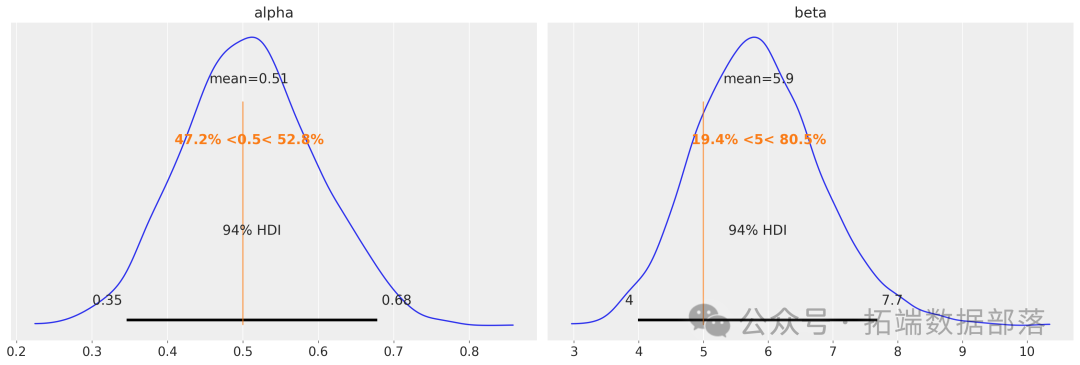
在这个例子中,得到的后验分布很好地以 MLE 值为中心。我们通过这种方式获得了这些参数值周围合理不确定性的信息。
使用伯努利似然的替代模型
最后,我们提供一个使用伯努利似然的替代模型实现。使用伯努利似然的一个好处是,可以进行先验和后验预测采样以及模型比较。而使用 pm.Potential 则无法实现这些,因为 PyMC 不知道什么是似然、什么是先验,也不知道如何生成随机样本。使用伯努利似然就不会有这些问题。
go
az.plot\_posterior(data=tr\_alt, ref\_val=\[true\_alpha, true_beta\]);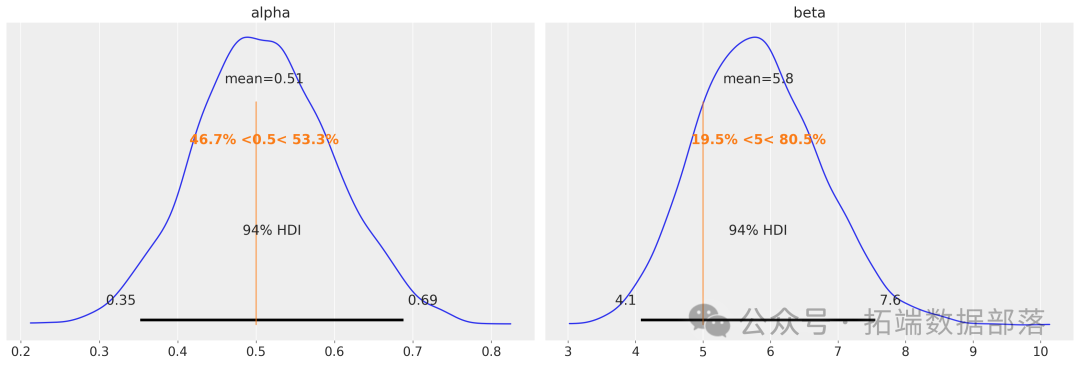
环境信息
go
Python implementation:CPython
Pythonversion :3.9.13
IPythonversion :8.4.0
aeppl:0.0.34
xarray:2022.6.0
pytensor :2.7.9
arviz :0.12.1
pymc :4.1.5
sys :3.9.13
\[Clang13.1.6(clang-1316.0.21.2)\]
scipy :1.8.1
numpy :1.22.4
matplotlib:3.5.3
Watermark:2.3.1参考文献
1 Robert C Wilson 和 Anne G E Collins. Ten simple rules for the computational modeling of behavioral data. eLife, 8:e49547, nov 2019. doi:10.7554/eLife.49547.

本文中分析的完整数据、代码、文档**** 分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取完整代码、数据、文档。
本文选自《Python贝叶斯回归、强化学习分析医疗健康数据拟合截断删失数据与参数估计3实例》。
点击标题查阅往期内容
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言RStan贝叶斯示例:重复试验模型和种群竞争模型Lotka Volterra
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计




