【MATLAB第114期】基于MATLAB的SHAP可解释神经网络分类模型(敏感性分析方法)
引言
该文章实现了一个可解释的神经网络分类模型,使用BP神经网络(BPNN)来预测特征输出。该模型利用12个变量参数作为输入特征进行训练。为了提高可解释性,应用了SHapley Additive exPlanations(SHAP),去深入了解每个参数对模型预测的贡献。
优化部分
1、套数据更加便捷,只需要更改数据、以及生成数据量
2、计算效率更快
(1)向量化预测:将所有特征子集的输入组合成矩阵instances,一次性完成网络预测,减少循环次数。通过net(instances")"批量获取所有子集的预测结果,充分利用MATLAB矩阵运算优化。
(2)并行计算:使用parfor并行处理每个样本的SHAP值计算,充分利用多核CPU资源
(3)预计算与哈希表:预计算所有子集的二进制表示和对应的哈希键,加速子集索引查找。预计算阶乘值避免重复计算权重,提升计算效率。
一、案例数据
1、导入数据
matlab
res = xlsread('分类数据集.xlsx'); %103行样本,7输入,1输出
x = res (:,1:end-1); %
y = res(:,end); % 最后一列为输出2、数据标准化
该部分使用mapminmax函数对输入和输出数据进行标准化,将数据缩放到-1, 1范围内。
matlab
% 输入数据归一化
[x_norm, x_settings] = mapminmax(x',-1,1);
% 输出数据归一化
[y_norm, y_settings] = mapminmax(y',-1,1);
normalization_x = x_settings;
save ('normalization_x.mat', 'x_settings');
normalization_y = y_settings;
save ('normalization_y.mat', 'y_settings');
x_norm_t = x_norm';
y_norm_t = y_norm';输入数据标准化:输入特征被标准化,标准化设置(x_settings)保存在名为normalization_x.mat的文件中,以便后续使用或反转标准化.
输出数据标准化:同样,输出数据被标准化,标准化设置(y_settings)保存在名为normalization_y.mat的文件中. 标准化后的数据被转置回原始方向,以保持模型进一步处理的一致性. 此步骤确保输入和输出数据适当缩放,以便于神经网络训练,从而有助于提高模型性能和收敛速度.
二、交叉验证和模型评估
该部分执行5折交叉验证以评估基于优化超参数构建的模型性能.
1、交叉验证设置
脚本使用K折交叉验证,numFolds = 5,将数据分成5个子集(折)。在每次迭代中,一个子集用于测试,其余子集用于训练模型.
2、模型训练和测试
对于每个折,使用cvpartition生成的索引将训练和测试数据分开. 使用BP神经网络(BPNN)训练模型,超参数设置:
matlab
%% 创建分类网络
neuron = 5;
net = patternnet([neuron], 'trainscg'); % 使用模式识别网络
%% 网络参数设置
net.trainParam.epochs = 1000;
net.trainParam.showWindow = false; % 关闭训练窗口
%% 训练网络
[net, tr] = train(net, trainData', ind2vec(trainLabels')); % 转换为向量形式3、解释交叉验证结果
最终模型选择:完成交叉验证后,可以通过所有折的平均ACC正确率总结模型的整体性能。这有助于选择最佳权衡的模型.
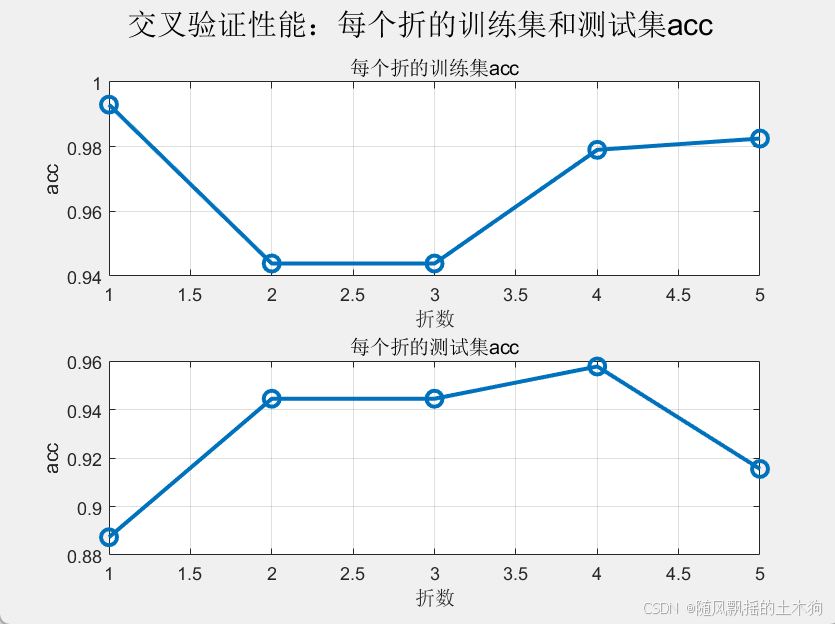
通过训练数据集评估模型的预测性能
测试集平均ACC: 0.92989
训练集平均ACC: 0.96845
选择最优数据集进行可视化(折数=4)
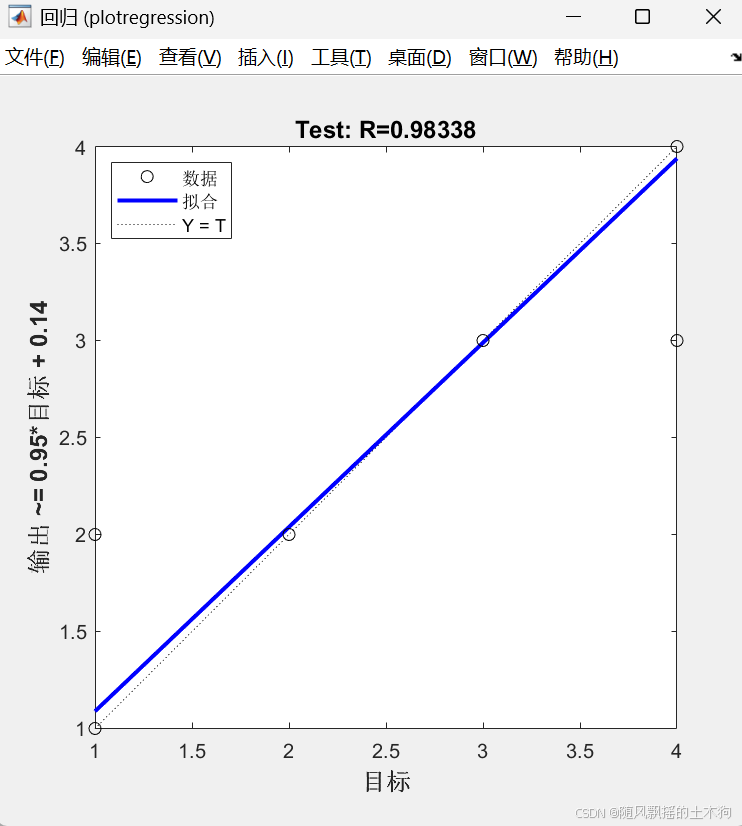

三、SHAP分析
1、生成随机数据
在本部分,生成一组合成输入数据用于SHAP分析。这种合成数据允许在受控和一致的方式下评估模型的特征贡献。步骤包括:
样本数量:脚本设置生成的合成样本数量为80(numSamples = 80).
特征范围: 定义操作参数在特定范围内,选择训练数据中各个输入变量的最大值和最小值
matlab
num_samples = 80;
VarMin = min(x);
VarMax = max(x);随机数据生成: 使用rand函数在定义的范围内为每个特征生成随机值,创建80个样本.
matlab
for i=1:size(x,2)
x_shap(:,i)=VarMin(i)+ (VarMax(i) - VarMin(i)) * rand(numSamples, 1);
end此生成数据用于评估SHAP值并分析每个特征如何影响模型的预测。生成随机输入数据确保了SHAP分析中特征值的广泛范围,便于更全面地评估特征重要性.
2、计算SHAP值
该代码计算神经网络模型的SHapley Additive exPlanations(SHAP)值。SHAP值量化了每个特征对模型预测的贡献。该过程包括:
- 预分配SHAP值矩阵:初始化一个矩阵以存储所有输入样本和特征的SHAP值.
2.计算参考值:将参考值计算为所有输入特征的平均值,用于在排除或包含特征时进行比较.
3.计算SHAP值:对于每个输入样本,使用自定义的shapley_ann函数计算SHAP值,该函数迭代所有可能的特征组合以确定每个特征对预测的贡献.
4.自定义的shapley函数接受一个训练好的神经网络(net)、当前输入样本和参考值来计算每个特征的SHAP值。该方法提供了对单个特征如何影响模型输出的洞察.
matlab
% ------------------------------------
function shapValues = shapley(net, x_shap, refValue) % 假设您有一个名为'net'的训练好的网络
% 使用Shapley公式计算SHAP值
如果有7个特征,则依次分析每个特征的累计贡献值
当分析第1个特征时,排除当前特征,即 1 0 0 0 0 0 0
迭代所有可能的特征组合
for i=1:2^(D-1)
xt1: 每个样本的特征变量输入值(处理后) 1*7
xt2: 计算的每个样本平均值(处理后) 1*7
xt3: 当分析不同特征时,将该特征值替换为平均值。 1*7
shapValues=shapValues+net(xt3)-net(xt2)
end3、可视化
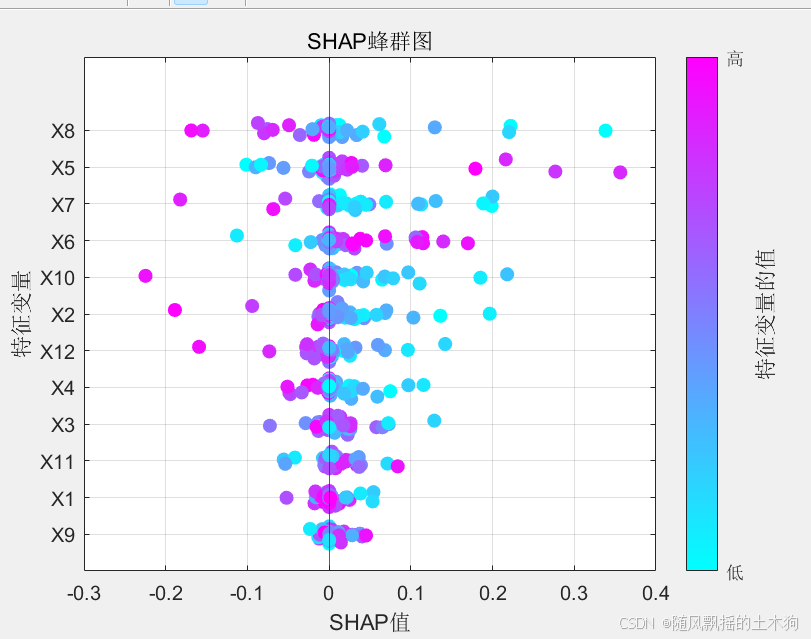
------蜂群图:为每个特征创建散点图(蜂群图),显示所有样本的SHAP值。特征值被标准化并颜色编码以提高可解释性.
包括轴标签、网格、框以提高清晰度以及带有操作参数标签的颜色条. 此SHAP摘要图有助于理解哪些特征对模型的预测影响最大以及特征在样本中的变化情况.显示每个特征对模型预测的贡献。
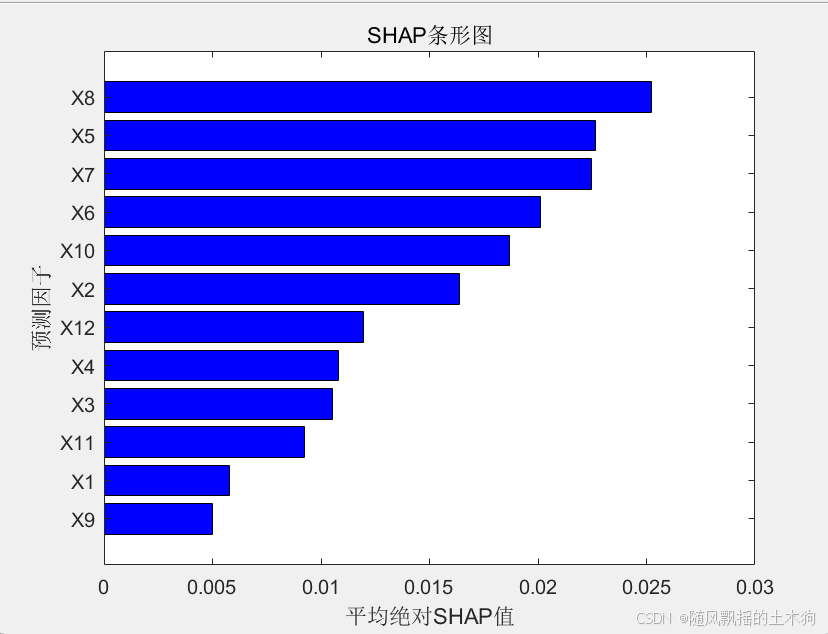
-----条形图
计算平均绝对SHAP值:计算每个特征的绝对SHAP值的平均值,以量化每个特征的整体重要性.
条形图可视化:创建一个水平条形图,特征按其平均绝对SHAP值排序。这提供了模型中特征重要性的清晰、排序表示. 结果的SHAP摘要条形图有助于识别哪些特征对模型的预测影响最大.
四、代码获取
1.阅读首页置顶文章
2.关注CSDN
3.根据自动回复消息,私信回复"114期"以及相应指令,即可获取对应下载方式。