Python刷题笔记
1、输出格式化
第一种格式化的输出:
python
name = "jack"
age = 17
salary = 20031.8752
print("你的名字是:%s,今年 %d 岁,工资 %7.2f" % (name,age,salary) )
---------------------------------------
你的名字是:jack,今年 17 岁,工资 20031.88
---------------------------------------第二种格式化的输出:
python
name = "jack"
age = 17
salary = 20031.8752
print(f"你的名字是:{name},今年 {age} 岁,工资:{salary}")
---------------------------------------
你的名字是:jack,今年 17 岁,工资:20031.8752
---------------------------------------2、数值类型转换
| 基本格式 | 解释 |
|---|---|
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将x转换为一个字符串 |
| chr(x) | 将x转换为一个字符 |
3、字符串类题型
题型一:大小写转换
1、使用str.lower()方法,把所有大写字母转换成小写字母。
pythonn=input() print(n.lower()) -------------------- 输入:HeLLo WORLD 输出:hello world --------------------
2、使用str.upper()方法,把所有小写字母转换成大写字母
pythonn=input() print(n.upper()) -------------------- 输入:hello world 输出:HELLO WORLD --------------------
3、使用str.capitalize()方法,仅首字母转化为大写字母,其余小写字母
pythonn=input() print(n.capitalize()) -------------------- 输入:hello world 输出:Hello world --------------------
4、使用str.title()方法,每个单词的首字母大写
pythonn=input() print(n.title()) -------------------- 输入:hello world 输出:Hello World --------------------
题型二:字母(a-z)之间的转换
讲解:ord()表示该字母的ASCII数值【配合ASCII表进行求解】
python
n = int(input())
a=input()
out = ''
for i in range(len(a)):
m = ord(a[i]) + n
while m > ord('z'):
m = m - ord('z') + ord('a') - 1
out += chr(m)
print(out)
-----------------
输入:
1
qwez
输出:rxfa
-----------------题型三:反转问题(数字,符号,字母...)
2.1: 全部进行反转操作
python
a = "Love You"
b = a[::-1]
print(b)
--------------
uoY evoL
--------------单词倒序问题1
给定一堆用空格隔开的英文单词,输出这些英文单词的倒序(单词内部保持原序)。
比如,输入:Hao Hao Xue Xi,输出:Xi Xue Hao Hao
python
words = input().split() # ['Hao', 'Hao', 'Xue', 'Xi']
words.reverse()
# 基本格式:'分隔符'.join(列表【list】)
result = ' '.join(words)
print(result)2.2: 局部进行反转操作
单词倒序问题2
给定一堆用空格隔开的英文单词,将每个单词内部逆序后输出(单词顺序不变)。
比如,输入:Hao Hao Xue Xi,输出:oaH oaH euX iX
python
a = input().split() # ['Hao', 'Hao', 'Xue', 'Xi']
re_words = [word[::-1] for word in a]
result = ' '.join(re_words)
print(result)【补充】回文数题型
方式一:回文数的基本思路:
pythondef f(n): temp = n ans = 0 while temp>0: ans = ans*10 + temp%10 temp = int(temp/10) return ans方式二:字符串特性
pythonn=input() n2=n[::-1]
4、判断某字符是否包含于字符串内(STL+KMP)
python
n = input().strip()
if "No Information" in n:
print("???")
elif "is greater than" in n:
parts = n.split()
a = int(parts[0])
b = int(parts[-1])
if a>b:
print("Yes")
else:
print("No")
------------------------------------
输入:10 is greater than 5
输出:Yes
------------------------------------5、公共前缀
给定n个字符串,求它们的公共前缀。
python
num = int(input())
#列表:其中for _ in range(num)表示循环num次,其中下划线 _ 通常用来忽略不需要返回值的循环变量
strings = [input().strip() for _ in range(num)] # 常规写法
common = []
min_length = min(len(s) for s in strings)
for i in range(min_length):
temp = strings[0][i]
if all(s[i]==temp for s in strings):
common.append(temp)
else:
break
print(''.join(common))
-------------------------------
输入:
3
actrpg
actfps
actarpg
输出:act
-------------------------------6、持续输入(遇到0停)
输入两个正整数a和b,求a+b的值。当a和b同时为0时停止执行。
python
while 1:
# 返回的是数字
a,b=list(map(int,input().split()))
if a==0 and b==0:
break
print(a+b)
-------------------------
输入:
2 3
1 8
7 9
0 0
输出:
5
9
16
-------------------------7、排序题型【sorted题型】
给定n个考生的姓名、语文分数、数学分数,按下面三种排序要求之一进行排序:
- 按语文分数从高到低排序,分数相同时按姓名字典序从小到大排序
- 按数学分数从高到低排序,分数相同时按姓名字典序从小到大排序
- 按总分(语文+数学)从高到低排序,分数相同时按姓名字典序从小到大排序
输入描述:
第一行两个整数n(1≤n≤1000)、k(1≤k≤3),分别表示考生个数、排序方式(k=1时表示按第一种方式排序,k=2时表示按第二种方式排序,k=3时表示按第三种方式排序);
接下来n行,每行为一个考生的姓名name、语文分数score1、数学分数score2(name为仅由大小写字母组成的不超过15个字符的字符串,0≤score≤100),用空格隔开。数据确保不会出现相同的姓名。
输出描述:
输出排序后的结果,共n行,每行为一个考生的姓名、语文分数、数学分数、总分,用空格隔开。
python
m,n = list(map(int,input().split()))
# tuple相当于struct结构体
students = [tuple(input().split()) for _ in range(m)]
# 新添tuple元素:总分
for i in range(len(students)):
n1,s1,s2 = students[i]
new = int(s1)+int(s2)
students[i] = (n1,s1,s2,new)
if n == 1:
sorted_students = sorted(students,key=lambda x:(-int(x[1]),x[0]))
elif n == 2:
sorted_students = sorted(students,key=lambda x:(-int(x[2]),x[0]))
elif n == 3:
sorted_students = sorted(students,key=lambda x:(-int(x[3]),x[0]))
for name,score1,score2,total in sorted_students:
print(name,score1,score2,total)
---------------------------------------------------------
输入:
5 1
SunWuKong 92 88
ShaWuJing 90 92
TangSanZang 100 100
BaiLongMa 90 88
ZhuBaJie 87 91
输出:
TangSanZang 100 100 200
SunWuKong 92 88 180
BaiLongMa 90 88 178
ShaWuJing 90 92 182
ZhuBaJie 87 91 178
---------------------------------------------------------sorted讲解:
顺序:sorted(序列)
倒序:sorted(序列,reverse=True)
对其中某个部分进行排序:sorted(序列,key=lambda x:(x3,x0,...))
8、Python中实现数据结构模型
1:String类型【STL】
字符串【拼接】
python
a,b=input().split()
print(a+b)
--------------------------
输入:good bad
输出:goodbad
--------------------------字符串【比较】
python
a,b=input().split()
if a==b:
print(0)
elif a>b:
print(1)
else:
print(-1)
----------------------
输入:good bad
输出:1
----------------------字符串【长度】和【清空】
python
# 读取输入字符串
s = input()
# 输出【字符串的长度】
print(len(s), end=" ")
# 【清空】字符串
s = ""
# 再次输出字符串的长度
print(len(s))字符串的【插入】与【删除指定位置字符】
python
# 读取输入字符串
s = input().strip()
# 读取插入操作的参数
k1, c = input().strip().split()
k1 = int(k1)
# 读取删除操作的参数
k2 = int(input().strip())
# 【插入元素】
s = s[:k1] + c + s[k1:]
print(s)
# 【删除指定位置的元素】
s = s[:k2] + s[k2+1:]
print(s)
------------------------------------
输入:
good
2 u
3
输出:
gouod
goud
------------------------------------判断是否为【子串】
使用s1.find(s2)函数判断s2是否是s1的子串,如果是的话,输出s2第一次在s1中出现的起始位置;如果不是,那么输出-1。
python
# 读取输入的两个字符串
s1, s2 = input().split()
# 使用find方法查找s2在s1中的位置
pos = s1.find(s2)
# 输出查找结果
print(pos)字符串【替换】
python
# 输入
s1=input()
a,lens=list(map(int,input().split()))
a=int(a)
lens=int(lens)
s2=input()
# 将s1中下标从a开始,长度为lens的子串替换为s2
new=s1.replace(s1[a:a+lens],s2)
print(new)【思想】:字符串删除特定元素
python
a="abbcdd"
temp=[]
for i in range(len(a)):
if a[i]=='b':
continue
temp.append(a[i])
new_a=''.join(temp)
print(new_a)【延伸题】:ds的字符串
ds 给了 xf 一个字符串。ds 对字符串可以进行若干次(可能是 0 次)如下操作:选择子串 "ds" 或者子串 "xf",将其从字符串中删去。求最后剩下字符串的最短长度。子串是指原字符串中下标连续的一段字符串。
python
n=int(input())
strings=input()
temp=strings
while ('xf' in temp) or ('ds' in temp):
lens=len(temp)
li=[]
for i in range(lens):
li.append(temp[i])
if len(li)>=2:
if ''.join(li[-2:])=='ds':
li.pop()
li.pop()
if ''.join(li[-2:])=='xf':
li.pop()
li.pop()
temp=''.join(li)
print(len(temp))
-------------------------------------
输入:
10 # 长度
xdsxffxacf # 字符串
输出:4
-------------------------------------2:栈类型【先进后出】
python
stack=[]
# 添加新元素至栈中
stack.append(1)
stack.append(2)
stack.append(3)
print(f"添加元素:%s" % stack)
# 删除栈顶【先进后出】❤
stack.pop()
print(f"删除栈顶元素:%s" % stack)
# 查询栈顶
num=stack[len(stack)-1]
print(f"查询栈顶元素:%s" % num)
# 判断栈是否为空
print(stack == [])
# 判断栈元素个数
print(f"判断栈元素个数:%d" % len(stack))
------------------------------------
添加元素:[1, 2, 3]
删除栈顶元素:[1, 2]
查询栈顶元素:2
False
判断栈元素个数:2
------------------------------------3:双端队列
python
# 创建一个空的列表作为双端队列
deque_list = []
# 在双端队列的右侧添加元素
deque_list.append('a')
deque_list.append('b')
print(deque_list) # 输出: ['a', 'b']
# 在双端队列的左侧添加元素
deque_list.insert(0, 'c')
print(deque_list) # 输出: ['c', 'a', 'b']
# 从双端队列的右侧移除并返回元素
right_element = deque_list.pop()
print(right_element) # 输出: 'b'
print(deque_list) # 输出: ['c', 'a']
# 从双端队列的左侧移除并返回元素
left_element = deque_list.pop(0)
print(left_element) # 输出: 'c'
print(deque_list) # 输出: ['a']4:队列类型【先进先出】
python
queue=[]
# 添加新元素至队列中
queue.append(1)
queue.append(2)
queue.append(3)
print(f"添加元素:%s" % queue)
# 删除队列元素【先进先出】❤
queue.pop(0)
print(f"删除栈顶元素:%s" % queue)
# 查询队列首个元素
num=queue[0]
print(f"查询栈顶元素:%s" % num)
# 判断栈是否为空
print(queue == [])
# 判断栈元素个数
print(f"判断栈元素个数:%d" % len(queue))
------------------------------------
添加元素:[1, 2, 3]
删除栈顶元素:[2, 3]
查询栈顶元素:2
False
判断栈元素个数:2
------------------------------------5:Set集合
基本语法
python
# 定义
1、语法:变量名={元素1,元素2,元素3,...}
2、注意:内部无序,且去重【不支持重复元素】,允许被修改
3、案例:
set1 = {1,2,3} # set集合定义
set2 = set() # set空集合定义
4、【不支持下标索引访问】常用操作方法
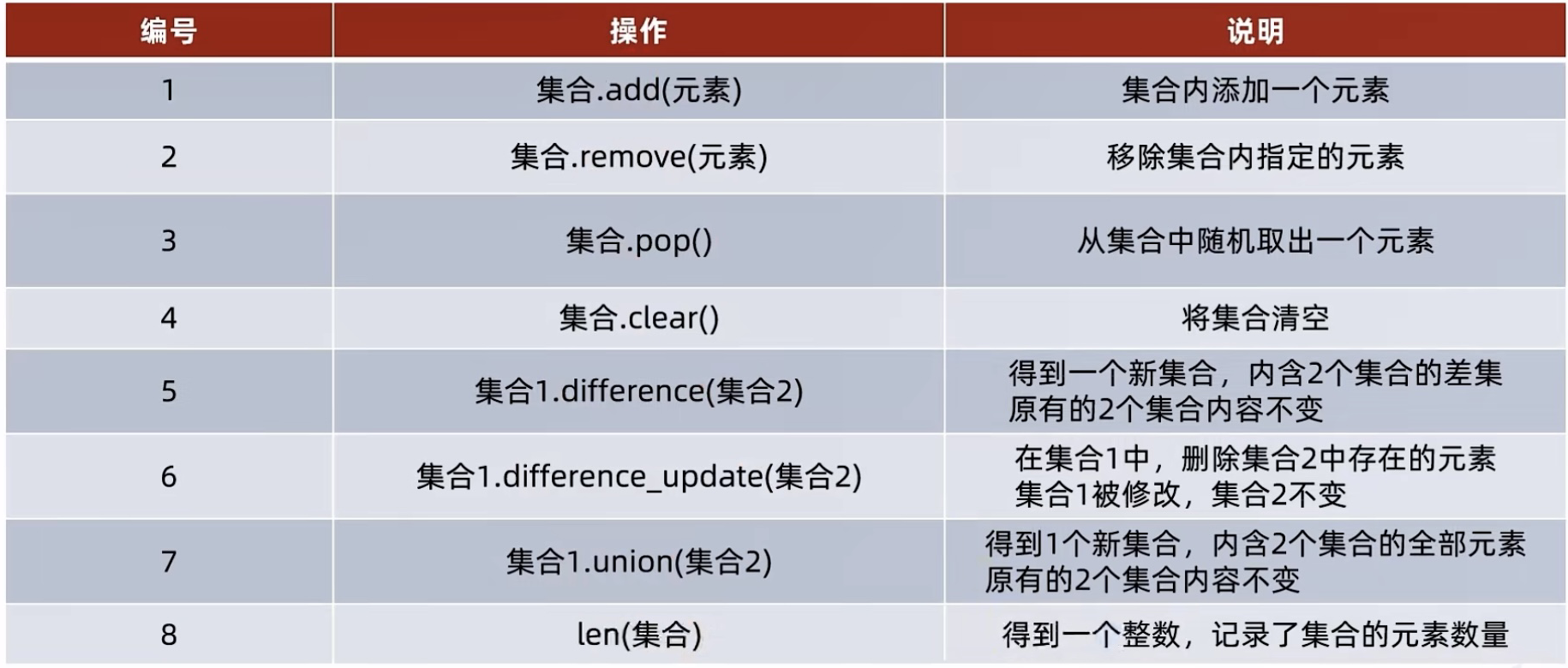
python
my_set={"你好","china","beauty"}
# 添加新元素add
my_set.add("三玖")
print(my_set)
------------------------------------
{'beauty', 'china', '你好', '三玖'}
------------------------------------
# 移除元素remove
my_set.remove("你好")
print(my_set)
----------------------
{'beauty', 'china'}
----------------------
# 随机取出一个元素pop
element = my_set.pop()
print(f"集合被取出的元素:{element},去除元素后:{my_set}")
----------------------------------------------------
集合被取出的元素:china,去除元素后:{'你好', 'beauty'}
----------------------------------------------------
# 清空set集合clear
my_set.clear()
print(my_set)
----------
set()
----------
# 取两个集合差集difference => 注意点:结果会得到一个新的集合,集合1和集合2不变【差集】
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2) # 取出set1和set2差集(set1有而set2没有)
print(f"去除差集后的结果:{set3}")
-----------------------
去除差集后的结果:{2, 3}
-----------------------
# 消除两个集合差集difference_update => 注意点:集合1被修改,集合2不变【差集】
set1 = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2) # set1中,删除和set2相同的元素
print(f"去除差集后,set1的结果:{set1}")
print(f"去除差集后,set2的结果:{set2}")
----------------------------
去除差集后,set1的结果:{2, 3}
去除差集后,set2的结果:{1, 5, 6}
----------------------------
# 两集合合并union【交集】
set1 = {1,2,3}
set2 = {1,5,6}
new_set = set1.union(set2)
print(new_set)
------------------
{1, 2, 3, 5, 6}
------------------
# 统计集合元素数量len
set = {1,2,3}
cnt = len(set)
print(cnt)
-----------
3
-----------
# 集合遍历 => 只支持for循环python经典题型
一:双指针
1、序列合并【典型写法】
给定两个升序的正整数序列A和B,将它们合并成一个新的升序序列并输出。
python
n,m=list(map(int,input().split())) # 两行的长度
a=list(map(int,input().split()))
b=list(map(int,input().split()))
# 合并两个升序序列
i,j=0,0
merged = []
while i<n and j<m:
if a[i]<=b[j]:
merged.append(a[i])
i+=1
else:
merged.append(b[j])
j+=1
# 将剩余的元素加入到结果中去
while i<n:
merged.append(a[i])
i+=1
while j<m:
merged.append(b[j])
j+=1
for i in range(len(merged)):
if i<len(merged)-1:
print(merged[i],end=' ')
else:
print(merged[i],end='')
------------------------------------------
输入:
4 3
1 5 6 8
2 6 9
输出:
1 2 5 6 6 8 9
------------------------------------------2、2-SUM-双指针【典型写法】
给定一个严格递增序列A和一个正整数k,在序列A中寻找不同的下标i、j,使得Ai+Aj=k。问有多少对(i,j)同时i<j满足条件。
python
size,target=list(map(int,input().split()))
array=list(map(int,input().split()))
# 存放结果数
result=0
# 定义指针
i=0
j=size-1
# 双指针遍历求解
while i<j:
if array[i]+array[j]==target:
result+=1
i+=1
j-=1
elif array[i]+array[j]<target:
i+=1
else:
j-=1
print(result)
--------------------------------
输入:
5 6
1 2 4 5 6
输出:
2
--------------------------------解释:1 + 5 = 6、2 + 4 = 6,因此有两对
3、集合交集
给定一个包含n个正整数的集合S1,再给定一个包含m个正整数的集合S2,求两个集合的交集。
python
n,m=list(map(int,input().split()))
a=list(map(int,input().split()))
b=list(map(int,input().split()))
# 排序
a=sorted(a)
b=sorted(b)
# 定义指针 与 结果集
i=0
j=0
result=[]
# 双指针遍历求解
while i<n and j<m:
if a[i]==b[j]:
result.append(a[i])
i+=1
j+=1
elif a[i]<b[j]:
i+=1
else:
j+=1
for i in range(len(result)):
if i<len(result)-1:
print(result[i],end=' ')
else:
print(result[i],end='')
----------------------------------------
输入:
5 4
1 2 5 6 8
2 4 6 7
输出:
2 6
----------------------------------------4、集合并集
给定一个包含n个正整数的集合S1,再给定一个包含m个正整数的集合S2,求两个集合的并集。
python
n,m=list(map(int,input().split()))
a=list(map(int,input().split()))
b=list(map(int,input().split()))
# 排序
a=sorted(a)
b=sorted(b)
# 定义指针 与 结果集
i=0
j=0
result=[]
# 双指针遍历求解
while i<n and j<m:
if a[i]==b[j]:
result.append(a[i])
i+=1
j+=1
elif a[i]<b[j]:
result.append(a[i])
i+=1
else:
result.append(b[j])
j+=1
# 将剩余的元素加入到结果中去
while i<n:
result.append(a[i])
i+=1
while j<m:
result.append(b[j])
j+=1
for i in range(len(result)):
if i<len(result)-1:
print(result[i],end=' ')
else:
print(result[i],end='')
----------------------------------------
输入:
5 4
1 2 5 6 8
2 4 6 7
输出:
1 2 4 5 6 7 8
----------------------------------------5、集合差集
给定一个包含n个正整数的集合S1,再给定一个包含m个正整数的集合S2,求两个集合的差集,即S1−S2。
注:使用双指针法完成。
python
n,m=list(map(int,input().split()))
a=list(map(int,input().split()))
b=list(map(int,input().split()))
# 排序
a=sorted(a)
b=sorted(b)
# 定义指针 与 结果集
i=0
j=0
result=[]
# 双指针遍历求解
while i<n and j<m:
if a[i]==b[j]:
i+=1
j+=1
elif a[i]<b[j]:
result.append(a[i])
i+=1
else:
j+=1
# 将剩余的元素加入到结果中去
while i<n:
result.append(a[i])
i+=1
for i in range(len(result)):
if i<len(result)-1:
print(result[i],end=' ')
else:
print(result[i],end='')
----------------------------------------
输入:
5 4
1 2 5 6 8
2 4 6 7
输出:
1 5 8
----------------------------------------6、美丽的区间【区间和】
题目大意:求序列里区间和大于或等于常数s的最小区间长度
给定一个长度为 n 的序列 a1,a2,⋯,an 和一个常数 S。对于一个连续区间如果它的区间和大于或等于 S,则称它为美丽的区间。对于一个美丽的区间,如果其区间长度越短,它就越美丽。请你从序列中找出最美丽的区间。
python
n,s=list(map(int,input().split()))
a=list(map(int,input().split()))
i,j=0,0 # 双指针
sum = 0 # 记录【区间和】
lens=10000000000000
while i < len(a):
if sum < s:
sum+=a[i]
i+=1
else:
if lens > i-j:
lens = i-j
sum -= a[j]
j+=1
if lens==10000000000000:
print(0)
else:
print(lens)
----------------------------------
输入:
5 6 # n=5,s=6
1 2 3 4 5
输出:2
----------------------------------二:二分查找
基本题型
在一个严格递增序列A中寻找一个指定元素x,如果能找到,那么输出它的下标;如果不能找到,那么输出−1。
注:使用二分法实现。
python
size,target=list(map(int,input().split())) # 元素的个数、需要寻找的元素
a=list(map(int,input().split()))
def f(a,size,target):
left=0
right=size-1
while left <= right:
mid=left+(right-left)//2
if a[mid]==target:
return mid
elif a[mid]<target:
left=mid+1
else:
right=mid-1
return -1
print(f(a,size,target))
-------------------------------
输入:
5 3
1 2 3 5 8
输出:
2
-------------------------------【延伸】单峰序列❤
单峰序列是指,在这个序列中存在一个位置,满足这个位置的左侧(含该位置)是严格递增的、右侧(含该位置)是严格递减的,这个位置被称作峰顶位置。现在给定一个单峰序列,求峰顶位置的下标。
python
n=int(input())
a=list(map(int,input().split()))
def f(n,a):
left=0
right=n-1
while left<right:
mid = int((left+right)/2)
if a[mid]<a[mid-1]:
right=mid
else:
left=mid+1
return left-1
print(f(n,a))
-------------------------------------
输入:
5
1 3 5 2 1
输出:
2
-------------------------------------【延伸】木棒切割问题
给出n根木棒的长度,现在希望通过切割它们来得到至少k段长度相等的木棒(长度必须是整数),问这些长度相等的木棒的最大长度。
python
n,k=map(int,input().split())
a = list(map(int,input().split()))
def f(n,k,a):
l=0
r=10**5
while l<r:
mid = (l + r + 1) // 2 # 计算中间值
stick_count=sum(x//mid for x in a)
if stick_count<k:
r=mid-1
else:
l=mid
return l
print(f(n,k,a))
--------------------------------------
输入:
3 7
10 24 15
输出:
6
--------------------------------------解释:
对三根长度分别为10、24、15的木棒来说,k=7,即需要至少7段长度相等的木棒,此时可以得到最大长度为6,因为在这种情况下,第一根木棒可以提供10/6=1段、第二根木棒可以提供24/6=4段、第三根木棒可以提供15/6=2段,达到了7段的要求。
【延伸】分巧克力
儿童节那天有 K 位小朋友到小明家做客。小明拿出了珍藏的巧克力招待小朋友们。
小明一共有 N 块巧克力,其中第 i 块是 Hi×Wi 的方格组成的长方形。为了公平起见,
小明需要从这 N 块巧克力中切出 K 块巧克力分给小朋友们。切出的巧克力需要满足:
- 形状是正方形,边长是整数;
- 大小相同;
例如一块 6×5 的巧克力可以切出 6 块 2×2 的巧克力或者 2 块 3×3 的巧克力。
当然小朋友们都希望得到的巧克力尽可能大,你能帮小明计算出最大的边长是多少么?
python
n,k = list(map(int,input().split()))
a=[]
for _ in range(n):
x=list(map(int,input().split()))
a.append(x)
def f(x):
count=0
for j in range(len(a)):
x1=a[j][0]
y1=a[j][1]
count+=(x1//x)*(y1//x) # 数量
return count
left=1
right=10000000
while left<=right:
mid=(left+right)//2
sums=f(mid)
if sums<k:
right=mid-1
elif sums>=k:
left=mid+1
print(right)
------------------------------------------
输入:
2 10
6 5
5 6
输出:2
------------------------------------------三:并查集
并查集的基本写法 :
初始化,查询,合并。

1、合根植物
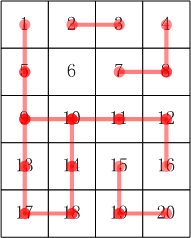
w 星球的一个种植园,被分成 m×n个小格子(东西方向 m 行,南北方向 n 列)。每个格子里种了一株合根植物。
这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的植物合成为一体。
如果我们告诉你哪些小格子间出现了连根现象,你能说出这个园中一共有多少株合根植物吗?
python
m,n=map(int,input().split())
ans=m*n # 单独集合数量
# 【初始化】
nums=[i for i in range(m*n+1)]
#寻找父节点【寻找】
def find_root(x):
if x==nums[x]:
return x
nums[x]=find_root(nums[x])
return nums[x]
# 【合并】
def merge(x,y):
global ans
# 找到 l 和 r 的根节点
x_root=find_root(x)
y_root=find_root(y)
# 如果 l 和 r 的根节点不同,说明它们原本不属于同一个集合
if x_root!=y_root:
nums[x_root] = nums[y_root]
ans-=1 # 每次合并操作后,独立集合的数量减少 1
k=int(input())
# 对于每组数据,读取两个整数 l 和 r,表示要将 l 和 r 所在的集合合并。
for i in range(k):
# 找到 l 和 r 的根节点
l,r=map(int,input().split())
merge(l,r)
print(ans)
---------------------------------------------
输入:
5 4 # m行 n列
16 # k为16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17
输出:5
---------------------------------------------2、蓝桥幼儿园
蓝桥幼儿园的学生是如此的天真无邪,以至于对他们来说,朋友的朋友就是自己的朋友。小明是蓝桥幼儿园的老师,这天他决定为学生们举办一个交友活动,活动规则如下:
小明会用红绳连接两名学生,被连中的两个学生将成为朋友。
小明想让所有学生都互相成为朋友,但是蓝桥幼儿园的学生实在太多了,他无法用肉眼判断某两个学生是否为朋友。于是他起来了作为编程大师的你,请你帮忙写程序判断某两个学生是否为朋友(默认自己和自己也是朋友)。
输入描述 :
第 1 行包含两个正整数 N,M,其中 N 表示蓝桥幼儿园的学生数量,学生的编号分别为 1∼N。
之后的第 2∼M+1 行每行输入三个整数,op,x,y:
如果 op=1,表示小明用红绳连接了学生 x 和学生 y 。
如果 op=2,请你回答小明学生 x 和 学生 y 是否为朋友。
输出描述 :
对于每个 op=2 的输入,如果 x 和 y 是朋友,则输出一行 YES,否则输出一行 NO。
python
n,m=list(map(int,input().split()))
# 【初始化】
a=[i for i in range(n+1)]
#寻找父节点【寻找】
def find_root(x):
if x==a[x]:
return x
a[x]=find_root(a[x])
return a[x]
# 【合并】
def merge(x,y):
x_root=find_root(x)
y_root=find_root(y)
if x_root!=y_root:
a[x_root]=a[y_root]
for i in range(m):
op,x,y=list(map(int,input().split()))
if op==1:
merge(x,y)
elif op==2:
x_root=find_root(x)
y_root=find_root(y)
if x_root==y_root:
print("YES")
else:
print("NO")
---------------------------------------------
输入:
5 5
2 1 2
1 1 3
2 1 3
1 2 3
2 1 2
输出:
NO
YES
YES
---------------------------------------------四:STL + KMP
KMP算法是一种用于解决字符串匹配问题的经典算法,它的核心思想是利用已经匹配过的信息,避免不必要的匹配尝试,从而提高匹配效率。
5.1、理论篇

5.2、实战篇
Next数组【前缀表】
next数组是KMP算法中的一个关键概念,它记录了模式串中每个位置的最长相同前后缀的长度。
在字符串匹配的KMP算法中有一个重要的概念是next数组,next数组的直接语义是:使"长度为L的前缀"与"长度为L的后缀"相同的最大L,且满足条件的前后缀不能是原字符串本身。
例如对字符串ababa来说,长度为1的前缀与后缀都是a,它们相同;长度为2的前缀与后缀分别是ab和ba,它们不相同;长度为3的前缀与后缀都是aba,它们相同;长度为4的前缀与后缀分别是abab和baba,它们不相同。因此对字符串ababa来说,使"长度为L的前缀"与"长度为L的后缀"相同的最大L是3。
我们把这个最大的L值称为原字符串S的next值。在此概念的基础上,对给定的字符串S,下标为从1到n,那么next[i]就是指子串S[1...i]的next值。
现在给定一个字符串,求next数组每一项的值。
python
# next数组,用于填充这个数组
# s为模式串
def get_next(next,s):
# 初始化
j=0 # 前缀末尾位
next[0]=0
# i为后缀末尾位
for i in range(1,len(s)):
# 前后位不匹配,j边界就是0【循环过程】
while j>0 and s[i] != s[j]:
# j回退到前一位对应的next表中的值
j=next[j-1]
# 前后缀相同情况
if s[i]==s[j]:
j+=1
# 更新next数组
next[i]=j
return next
s=input()
next1=[0]*len(s) # 初始化next长度
next=get_next(next1,s)
for i in range(0,len(s)):
if i<len(s)-1:
print(next[i],end=' ')
else:
print(next[i],end='')
-----------------------------------------
输入:ababaa
输出:0 0 1 2 3 1
-----------------------------------------解释:
子串a的最长相等前后缀不存在(因为不能等于本身),因此L=0;
子串ab的最长相等前后缀不存在,因此L=0;
子串aba的最长相等前后缀是a,因此L=1;
子串abab的最长相等前后缀是ab,因此L=2;
子串ababa的最长相等前后缀是aba,因此L=3;
子串ababaa的最长相等前后缀是a,因此L=1。
子串判定
现有两个字符串s1和s2,使用KMP算法判断s2是否s1的子串。
python
s1=input() # 文本串
s2=input() # 模式串
# next数组
def get_next(next,s):
# 初始化
j=0 # 前缀末尾位
next[0]=0
# i为后缀末尾位
for i in range(1,len(s)):
# 前后位不匹配,j边界就是0【循环过程】
while j>0 and s[i] != s[j]:
# j回退到前一位对应的next表中的值
j=next[j-1]
# 前后缀相同情况
if s[i]==s[j]:
j+=1
# 更新next数组
next[i]=j
return next
def KMP(s1,s2):
n=len(s1) # 文本串
m=len(s2) # 模拟串
next=[0]*len(s2) # 初始化next长度
if m==0:
return True
next=get_next(next,s2)
j=0
for i in range(0,len(s1)):
# s1对应元素 与 s2对应元素 不匹配
while j>0 and s1[i] != s2[j]:
j=next[j-1]
# s1对应元素 与 s2对应元素 匹配
if s1[i]==s2[j]:
j+=1
if j==len(s2):
return True
return False
result=KMP(s1,s2)
print("Yes" if result else "No")
----------------------------------------
输入:
abadc
bac
输出:
No
----------------------------------------偷懒技巧:
pythons1=input() # 文本串 s2=input() # 模式串 if s2 in s1: print("Yes") else: print("No")
五:递归和递推
【回溯法】,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
基本框架:
pythonvoid backtracking(参数) { if (终止条件) { 存放结果; return; } for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 } }
1、数的计算
输入一个自然数 n (n≤1000),我们对此自然数按照如下方法进行处理:
- 不作任何处理;
- 在它的左边加上一个自然数,但该自然数不能超过原数的一半;
- 加上数后,继续按此规则进行处理,直到不能再加自然数为止。
问总共可以产生多少个数。
python
def f(n):
if n==1:
return 1
num=1
for i in range(1,n//2+1):
num=num+f(i)
return num
n=int(input())
print(f(n))
-----------------------------
输入:6
输出:6
-----------------------------2、汉诺塔题型
汉诺塔(又称河内塔)问题源于印度一个古老传说的益智玩具。大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。并且规定,在小圆盘上不能放大圆盘,在三根柱子之间一次只能移动一个圆盘。
抽象成模型就是说:
有三根相邻的柱子,标号分别为A、B、C,A柱子按金字塔状叠放着n个不同大小的圆盘,现在要把所有盘子一个一个移动到柱子C上,并且任何时候同一根柱子上都不能出现大盘子在小盘子上方,请问至少需要多少次移动,并给出具体的移动方案。

输入:一个正整数n(1≤n≤16),表示圆盘的个数。
输出:
第一行输出一个整数,表示至少需要的移动次数。
接下来每行输出一次移动,格式为
X->Y,表示从柱子X移动最上方的圆盘到柱子Y最上方。
python
def f(n,from_rod,to_rod,mid_rod):
if n==0:
return
# 将前n-1个盘子从from_rod到mid_rod,借助to_rod作为辅助
f(n-1,from_rod,mid_rod,to_rod)
# 将第n个盘子直接从from_rod移到to_rod
print(f"{from_rod}->{to_rod}")
# 将前n-1个盘子从mid_rod到to_rod,借助from_rod作为辅助
f(n-1,mid_rod,to_rod,from_rod)
n = int(input())
print(2**n-1)
f(n,'A','C','B')3、 数字螺旋矩阵
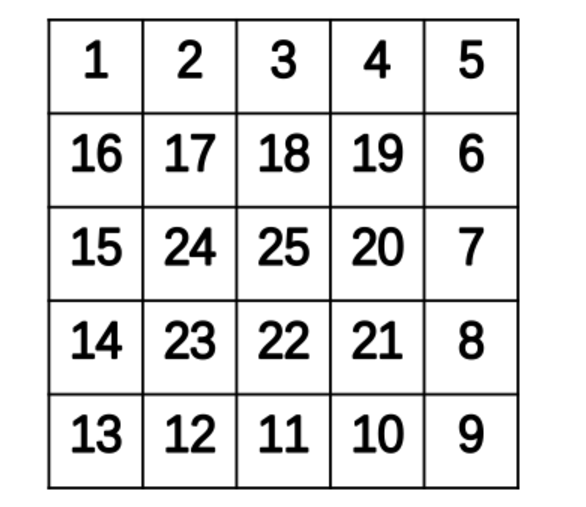
给定一个正整数n,生成一个大小为n∗n的方阵,其中按顺时针的顺序给出从1到n∗n的每一个整数。
如下图是n=5的螺旋矩阵。
python
def f(n):
# 初始化n * n的矩阵:[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
matrix=[[0]*n for _ in range(n)]
index=1
def fill_matrix(x,y,size):
nonlocal index
if size == 0:
return
if size == 1:
matrix[x][y] = index
index+=1
return
# 填充最上边的行
for i in range(y,y+size-1):
matrix[x][i]=index
index+=1
# 填充最右边的列
for i in range(x,y+size-1):
matrix[i][y+size-1]=index
index+=1
# 填充最下边的行
for i in range(y+size-1,y,-1):
matrix[x+size-1][i] = index
index+=1
# 填充最左边的行
for i in range(x+size-1,x,-1):
matrix[i][y]=index
index+=1
# 递归填充内圈
fill_matrix(x+1,y+1,size-2)
fill_matrix(0,0,n)
return matrix
n=int(input())
# [[1, 2, 3, 4, 5], [16, 17, 18, 19, 6], [15, 24, 25, 20, 7], [14, 23, 22, 21, 8], [13, 12, 11, 10, 9]]
result=f(n)
for row in result:
for i in range(len(row)):
if i<len(row)-1:
print(row[i],end=' ')
else:
print(row[i])
-------------------------------
输入:5
输出:
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
-------------------------------六、基础题
1、卡片
小蓝有 k 种卡片, 一个班有 n 位同学, 小蓝给每位同学发了两张卡片, 一 位同学的两张卡片可能是同一种, 也可能是不同种, 两张卡片没有顺序。没有 两位同学的卡片都是一样的。
给定 n , 请问小蓝的卡片至少有多少种?

注意 :C 计算两种不同的卡片【比如(1,2)(1,3)(2,3)】,题目中还可以相同的卡片【比如(1,1)(2,2)(3,3)】,因此需要加k。
python
n=int(input())
k=1
while 1:
if k*(k+1)/2 >= n:
print(k)
break
else:
k+=1
----------------------------
输入:6
输出:3
----------------------------2、水仙花数
如果一个三位数 n 的各位数字的立方和等于 n ,那么称 n 为水仙花数。例如 153=13+53+3^3,因此 153 是水仙花数。
给定一个正整数,判断这个数是否是水仙花数。
python
n = int(input())
temp = n
bai = temp // 100
shi = (temp // 10) % 10
ge = temp%10
if ge**3+bai**3+shi**3 == n:
print("YES")
else:
print("NO")
---------------------------------
输入:153
输出:YES
---------------------------------七、Hash法【补充】
给定一个严格递增序列A和一个正整数k,在序列A中寻找不同的下标i、j,使得Ai+Aj=k。问有多少对(i,j)同时i<j满足条件。
注:使用hash法实现
python
def find(n, k, A):
# 初始化hash表,大小为10^6+1
hashTable = [False] * (10 ** 6 + 1)
# 填充hash表
for num in A:
hashTable[num] = True
count = 0
# 查找数对
for num in A:
if k - num >= 0 and hashTable[k - num]:
count += 1
# 每个数对被找到两次,所以结果需要除以 2
return count // 2
n, m = map(int, input().split())
A = list(map(int, input().split()))
print(find(n, m, A))
------------------------
输入:
5 6
1 2 4 5 6
输出:2
------------------------