文章目录
-
- [📊 背景说明](#📊 背景说明)
- [🛠️ 修改 systemd 服务配置](#🛠️ 修改 systemd 服务配置)
-
- [1. 配置文件路径](#1. 配置文件路径)
- [2. 编辑服务文件](#2. 编辑服务文件)
- [2. 重新加载配置并重启服务](#2. 重新加载配置并重启服务)
- [3. 验证配置是否成功](#3. 验证配置是否成功)
- [📈 应用效果示例](#📈 应用效果示例)
-
- [1. 调用单个70b模型](#1. 调用单个70b模型)
- [2. 调用多个模型(70b和32b模型)](#2. 调用多个模型(70b和32b模型))
- 总结
- [📌 附:自动化脚本(可选)](#📌 附:自动化脚本(可选))
- 额外补充
- [🧠 1. Open WebUI多用户同时访问同一个模型,是否相互影响?](#🧠 1. Open WebUI多用户同时访问同一个模型,是否相互影响?)
-
- [🔍 详细说明:](#🔍 详细说明:)
-
- [✅ 互不干扰的部分](#✅ 互不干扰的部分)
- [⚠️ 可能"互相影响"的部分](#⚠️ 可能“互相影响”的部分)
- [📚 2. 使用知识库(向量检索/RAG)是否会影响模型?](#📚 2. 使用知识库(向量检索/RAG)是否会影响模型?)
-
- [✅ 简短回答](#✅ 简短回答)
- [🔍 具体解释](#🔍 具体解释)
默认的ollama调用的各种大模型,如deepseek 70b模型,每个模型实例只绑定一张 GPU,如果是多卡,其它卡会一直闲置,造成一定浪费。
本文档介绍如何通过 systemd 配置文件为 Ollama 服务添加 GPU 和调度相关的环境变量,从而实现多 GPU 的高效利用与负载均衡。
📊 背景说明
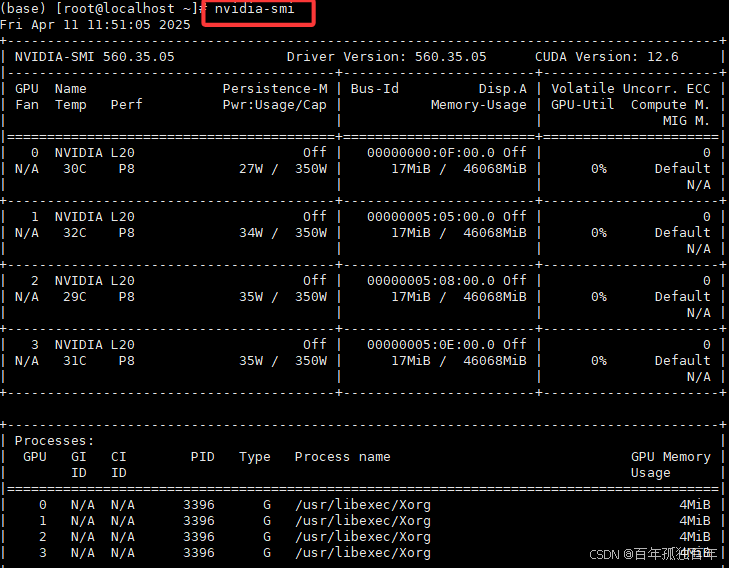
我们首先通过命令nvidia-smi查看有几张GPU,如下图,可以看到我们当前有4张卡,GPU编号是0,1,2,3(为了之后配置中设置数字)。
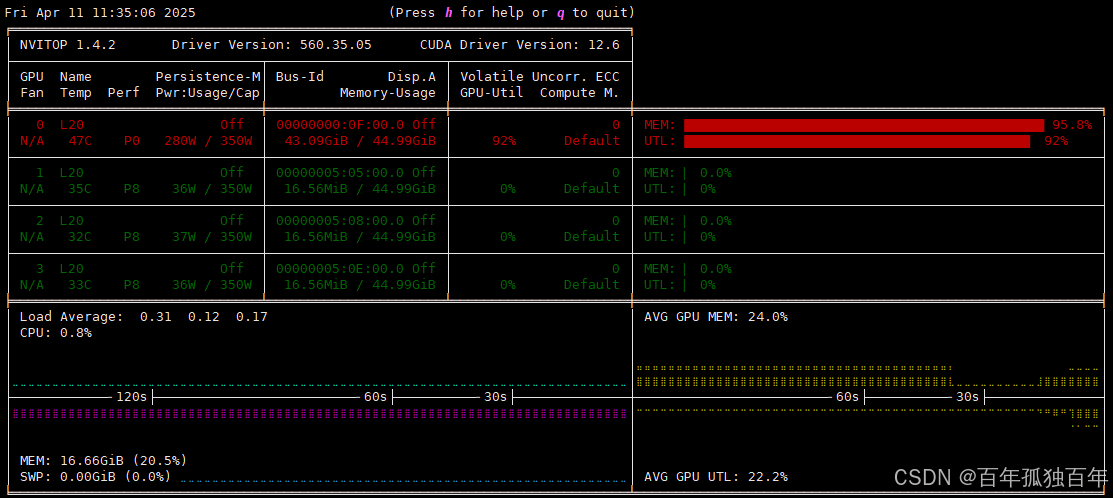
如果只是通过Open WebUI 使用ollama的deepseek-r1:70b模型,我们观察GPU使用情况,如下图,可以发现只有一张卡使用,即使是多个用户同时使用deepseek-r1:70b模型,也依然只有单个GPU使用,这造成了极大的资源浪费,没有相应的负载均衡。
如果局域网内用户,几个人访问70b模型,几个人访问32b模型,第一张卡显存占满了之后,才会调用第二张卡,第三张卡和第四张卡永远都不用使用到,造成一定程度上的资源浪费。
Ollama 也只会在部分 GPU 上负载,其他 GPU 处于空闲状态。
Ollama 默认每个模型实例只绑定一张 GPU,并不具备自动负载均衡的能力。
为实现模型多卡部署与更高的吞吐量,我们可以通过设置环境变量来调整 Ollama 的调度行为。
因此我们需要相应的环境设置,设置也很简单。
🛠️ 修改 systemd 服务配置
1. 配置文件路径
Ollama 的 systemd 服务配置文件路径如下:
bash
/etc/systemd/system/ollama.service2. 编辑服务文件
bash
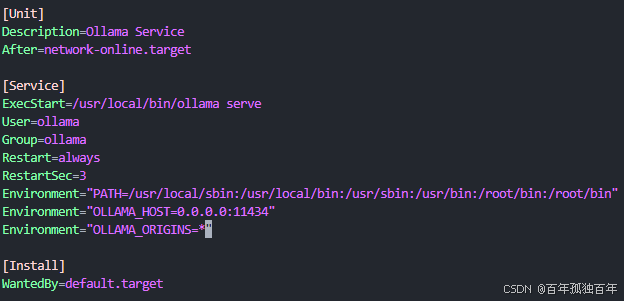
sudo vim /etc/systemd/system/ollama.service默认的整体配置如下:
bash
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target按下
i进入插入模式,找到[Service]段,我们需要在Service的下面添加几个环境变量设置,如下:
bash
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"✨参数说明:
- Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" 代表让ollama能识别到第几张显卡,因为4张显卡,从0开始编号,所以为0,1,2,3。根据你的显卡数量进行设置。
- Environment="OLLAMA_SCHED_SPREAD=1" 这几张卡均衡使用
- Environment="OLLAMA_KEEP_ALIVE=-1" 模型一直加载, 不自动卸载,这个设置会一直占用显存不释放,相应会快一些。如果不经常使用模型,可以把这个去掉,啥时候通过Open Webui访问,然后啥时候加载模型,第一次加载一般会慢一些。
添加之后的完整配置:
bash
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
### 添加如下配置,下面三个是新增的
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"
[Install]
WantedBy=default.target按下 Esc,然后输入 :wq 保存并退出。
2. 重新加载配置并重启服务
使用如下命令:
bash
sudo systemctl daemon-reload
sudo systemctl restart ollama
💡 注意:若出现
Failed信息,仅为非关键错误,通常不影响实际运行。
sudo systemctl daemon-reload命令解释:
重新加载 systemd 管理器的配置文件。当你修改了服务的配置文件 (比如 /etc/systemd/system/ollama.service)后,systemd 并不会自动发现这些改动,你需要显式告诉它:"配置文件变了,请重新读取"。
sudo systemctl restart ollama命令解释:
停止 再重新启动 ollama 服务,使其立即应用你新修改的配置。
3. 验证配置是否成功
查看服务状态:
bash
systemctl status ollama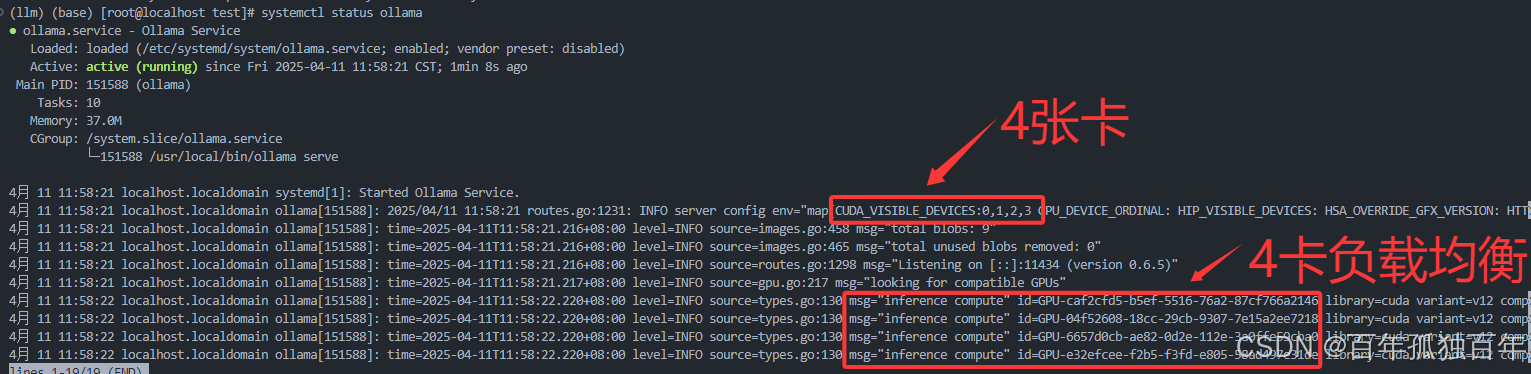
检查环境变量是否注入成功:
bash
sudo systemctl show ollama | grep Environment你应当看到如下输出:
ini
Environment=CUDA_VISIBLE_DEVICES=0,1,2,3
Environment=OLLAMA_SCHED_SPREAD=1
Environment=OLLAMA_KEEP_ALIVE=-1参数说明
| 参数 | 含义 |
|---|---|
CUDA_VISIBLE_DEVICES=0,1,2,3 |
指定可用的 GPU 编号(0 到 3),表示总共使用 4 张显卡 |
OLLAMA_SCHED_SPREAD=1 |
启用多 GPU 均衡调度,让模型推理在多卡之间分摊负载 |
OLLAMA_KEEP_ALIVE=-1 |
模型常驻内存,保持加载状态,防止自动卸载,提高响应速度 |
📈 应用效果示例
1. 调用单个70b模型
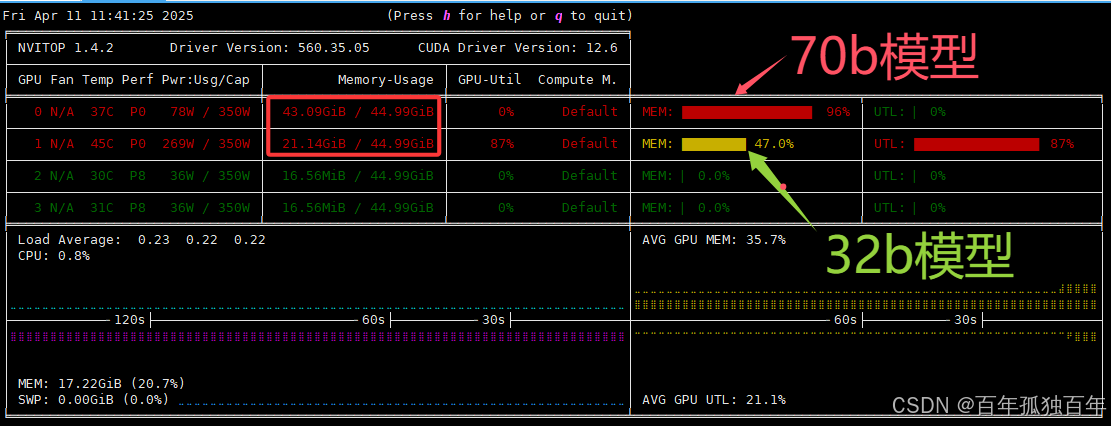
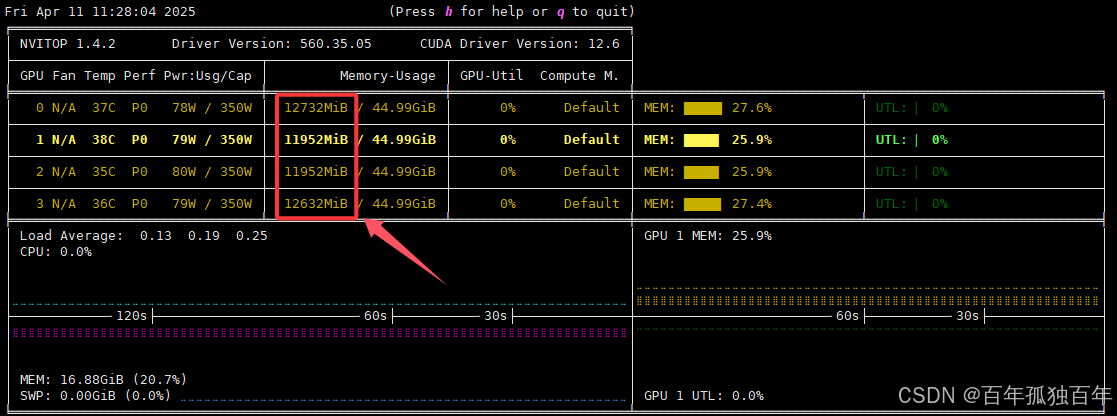
进行上述设置之后,我们通过Open Webui访问70b模型,如下

此时查看显存占用,如下图,可以发现此时会同时使用4张卡,模型占用的43G左右的显存会均衡分布在4张卡中,而不是用单个卡推理。
2. 调用多个模型(70b和32b模型)
此时再访问32b的模型,如下:
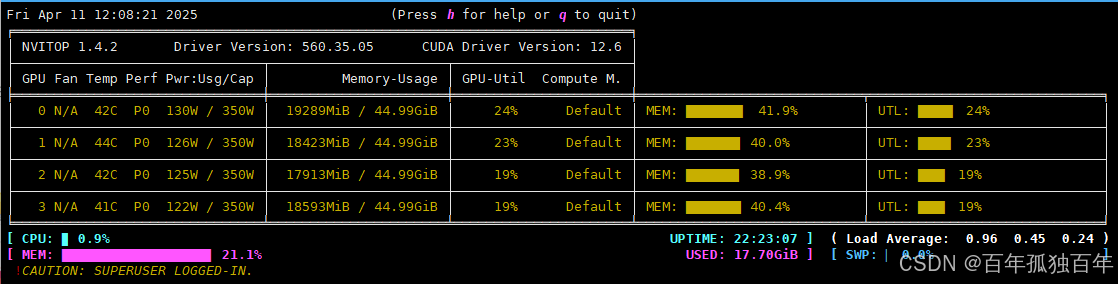
此时显存占用如下图,可以发现依然会均衡的调用每个GPU,而不会使用单个GPU。
总结
通过为 systemd 添加环境变量配置,Ollama 可以实现:
- 多 GPU 推理任务的自动均衡调度
- 模型常驻显存,减少加载时间
- 灵活控制资源占用,提升整体性能表现
该方法适用于高并发场景、长时间部署服务、模型启动延迟敏感等使用场景。
📌 附:自动化脚本(可选)
如需自动完成上述步骤,可使用以下脚本:
bash
#!/bin/bash
SERVICE_FILE="/etc/systemd/system/ollama.service"
# 插入环境变量(如果没有手动加过)
sudo sed -i '/^\[Service\]/a Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"\nEnvironment="OLLAMA_SCHED_SPREAD=1"\nEnvironment="OLLAMA_KEEP_ALIVE=-1"' "$SERVICE_FILE"
# 重新加载并重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
# 检查状态
sudo systemctl status ollama额外补充
🧠 1. Open WebUI多用户同时访问同一个模型,是否相互影响?
🔍 详细说明:
✅ 互不干扰的部分
- 推理上下文是隔离的:每个用户的输入输出在 WebUI 层面是分开的,彼此看不到对方内容。
- 会话状态是用户独立的:对话记录、聊天上下文、调用参数不会混淆。
⚠️ 可能"互相影响"的部分
- GPU 显存竞争 :
- 70B 模型非常吃显存,如果同时多个用户发起推理,可能卡顿、OOM、速度变慢。
- 尤其是 batch size、上下文长度较大时会挤爆内存。
- 此时你看到的"互相影响"其实是性能瓶颈,不是逻辑混乱。
- 线程/队列调度 :
- 如果使用的是单实例模型服务(比如 Ollama 只加载一次模型),请求会被排队处理。
- 一个用户长时间生成内容可能导致另一个用户响应慢。
📚 2. 使用知识库(向量检索/RAG)是否会影响模型?
✅ 简短回答
不会直接影响模型本身,但会影响模型的"输出内容"。
🔍 具体解释
- 模型本体(参数、权重)是静态的,不会被修改。
- 知识库的作用是提供额外的上下文信息(通过检索,拼接在 prompt 前),相当于给模型"补充资料"。
- 所以:
- 每个用户的知识库是独立配置的话,互不影响。
- 如果多个用户使用同一个知识库,那检索到的内容可能类似,影响回答的风格/方向,但不至于"污染"模型。
- 不会长期改变模型行为,只是短暂地影响一次回答。