mysql 是什么?
你是一个程序员,做了一个网站应用,站点里的用户数据需要存储到某一个地方,方便随时读写。
很容易可以想到将数据存到文件里。
但如果数据量很大,想从大量文件数据中查找某部分数据并更新是一件很痛苦的事。
有解法吗?
有。没有什么是加一层中间层不能解决的,如果不行就再加一层。
这次我们加的中间层就是mysql。

所以,什么是mysql呢?
它是一款存放和管理数据的软件。
它介于应用和数据之间,通过一些设计将大量数据变成一张张像excel的数据表,为应用提供创建、读取、更新、删除等核心操作。
那它是怎么实现的呢?
数据页是什么?
mysql 将数据组织成一张 excel 表的样子,excel文件在磁盘上是一个.xls文件。
mysql 的数据表也类似,在磁盘上则是个.ibd后缀的文件。


数据表越大,磁盘上的.idb文件也就越大。
直接读写一个idb文件里的全部数据会很慢,所以,mysql 将数据拆成一个个数据页,每页的大小16kb。

这样读写数据表的数据时,只需要读取磁盘里面的几个数据页就好了。
索引是什么?
但数据页那么多,查某条数据时怎么知道要读哪些数据页呢?
好办啊,可以为每个数据页加上页号。

再为每行数据加个序号,这个序号其实就是所谓的主键。

按主键大小排序,将每个数据页最小的主键序号和所在的页号提取出来,放入到一个新生成的数据页 中,并且给数据页加上层级的概念,这样我们就可以通过上层的数据页,快速缩小查找的范围,加速查找数据页的过程。
这就相当于你查找某本书的章节内容时,首先翻到目录页,根据目录页记录的章节位置,去查找章节内容。

现在,页跟页之间的关系像是一棵倒过来的树。
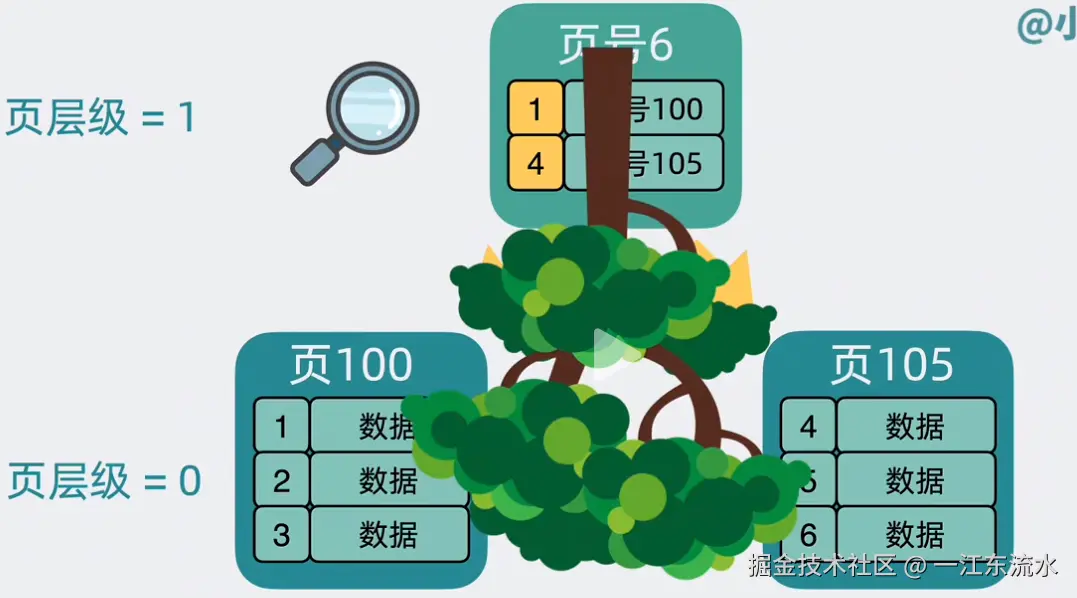
这棵可以加速查找数据页的树,就是我们常说的B+索引树。

下图这样一个一个的小圆圈就是数据页。

当你通过主键id 进行查询时,首先查找目录页,根据id编号确定是在哪一个数据页,拿到数据页号之后,就直接到对应的数据页中查找即可。
上面提到的是针对主键的索引。
按同样的思路,也可以为其他字段建立索引,比如用户表的名称字段,这样我们就能快速查找到名字为xx的用户有哪些,这就是所谓的辅助索引。

Buffer pool 是什么?
但就算有了索引,数据还是在磁盘上,每次都读磁盘太慢了,有办法能提升下性能吗?
有。在磁盘数据和应用之间加一层进程内缓存。

缓存里面装的就是前面提到的16kb数据页和索引页 ,它就是所谓的buffer pool。

读数据时优先读 buffer pool,有数据就返回,没数据就去读磁盘,减少了读磁盘的次数,大大提升了性能。
上面的图中buffer pool就包含了索引的数据页和索引对应的数据页。
先从索引数据页查找,找到数据所在的地址,然后到对应的数据页中获取数据。这就是上面说的一个倒着的树。
自适应哈希索引是什么?
除了B+树索引外,还有自适应哈希索引,那么它是什么呢?
就算有了buffer pool要查到某个数据,也依然要查找 B+ 树,查询复杂度为O(lnN)。

查找能更快吗?
可以的,可以使用查询复杂度为O(1)的哈希表进行优化,记录每个数据页的查询频率。
哈希表(Hash Table)也叫散列表,是一种数据结构,就好像一个有很多小格子的超级大盒子。你可以把它想象成一个学校的快递存放点,每个小格子都可以用来放快递包裹。 每个快递包裹上都有收件人的名字,这个存放点有一个神奇的 "分配规则",就像一个特殊的数学公式,能根据收件人的名字算出应该把包裹放在哪个小格子里,这个 "分配规则" 就叫哈希函数。比如,可能是把收件人名字里所有字母的 ASCII 码加起来,再除以小格子的数量,得到的余数就是包裹要放的格子编号。
对于热点数据页,我们可以把查询的值为key,数据页的地址为value,构建哈希表。
比如,name 为小白的数据被频繁的查询,key 就是小白,value 就是包含小白记录的数据页地址。

存储引擎 innoDB 是什么?
讲了这么多,我们将上面提到的内容分为内存和磁盘两部分。

内存里面的 buffer pool 以及相关log文件,以及磁盘里面的.idb文件和log文件,共同构成了存储引擎。

这些log文件作用只需要知道它们是为了更快更好的读写磁盘里面的数据,以及当内存挂了之后,如何回滚和恢复数据用的就行了。
存储引擎对外提供一系列函数接口,比如操作数据行的write_row()、update_row()等,以及操作数据表的create()、drop()等。
我们平时写的sql语句,都会转换成innoDB提供的接口函数调用。

比如,insert语句会调用write_now(),create语句会调用create()。
那么,现在问题来了,我们平时写的sql语句,是怎么转换成存储引擎的函数接口的呢?
那就需要介绍server层?
server层是什么?
server层本质上是sql语句和innoDB存储引擎之间的中间层。

server层里面有一个连接管理的模块,用于管理来自应用层的网路连接。

并提供一个分析器,用于判断sql语法有没有错误。
再提供一个优化器,用于根据一定的规则,选择该用什么索引生成执行计划。
之后,还提供了一个执行器,根据执行计划去调用innoDB存储引擎的接口函数。

server层和存储引擎构成了一个完整的数据库,它就是我们常说的 mysql 数据库。

并且,server 层和存储引擎是通过接口函数进行解耦的。
换句话说,只要实现了上面这些接口函数,就能作为存储引擎与server层对接。
比如,mysql早期使用的是myisam,后来采用的innoDB。

binlog 是什么?
你一定听说过删库跑路吧。
为了防止数据库被删除带来的影响,server层会将历史所有的变更操作记录到磁盘上的日志文件中。这个日志文件就是所谓的binlog。
一旦误删表,就会利用binlog来恢复数据。
数据库查询更新流程是怎么样的?
下面我们用一个实际的例子将上面提到的内容串起来。
首先,不管是查询还是更新操作,客户端都会先跟 mysql 建立网络连接,并将 sql 发送到 server 层。

经过分析器解析sql语法,优化器选择索引生成执行计划,最终给到执行器,调用innoDB的函数接口。
对于读操作,innoDB会先检查butter pool中是否存在所需的 B+ 树数据页,如果存在直接返回。
如果没有所需的数据,则会从磁盘中读取相应的数据页加载到buffer pool中,再返回数据。
同时,如果查询的数据是热点数据,还会将哈希索引引入到豪华套餐中,加速后续的查询。

到这里,本文就结束了,本文所有的内容来自视频号小白debug,这个视频号非常不错,用通俗的语言解释了计算机基本知识,这对于一个前端工程师来说大大降低了学习后端的难度,大家如果看到这里,觉得还不错就关注这个视频号吧。