本节课接上节课继续对于RDD进行学习,首先是对于创建RDD的不同方式,接着学习了RDD的三种转换算子:Value类型、双Value类型、Key-Value类型,以及各个转换算子的不同使用方式。
学习到如下的区别:
map 与 mapPartitions:前者是逐条处理数据,后者以分区为单位进行批处理,性能上后者可能更高,但内存占用也更大。
map 与 flatMap:map 是一对一映射,flatMap 先扁平化再映射,可能会改变数据的数量。
reduceByKey 与 groupByKey:reduceByKey 可在 shuffle 前预聚合,减少落盘数据量,性能更好;groupByKey 仅能分组,不能聚合。
reduceByKey、foldByKey、aggregateByKey、combineByKey:它们在对第一个数据的处理方式、分区内和分区间的计算规则方面存在差异
创建RDD
在 scala 文件夹下创建一个新的 Scala 文件,CreateRDD.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CreateRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
// 1) 从集合(内存)中创建 RDD
val rdd1 = sparkContext.parallelize(List(1, 2, 3, 4))
val rdd2 = sparkContext.makeRDD(List(1, 2, 3, 4))
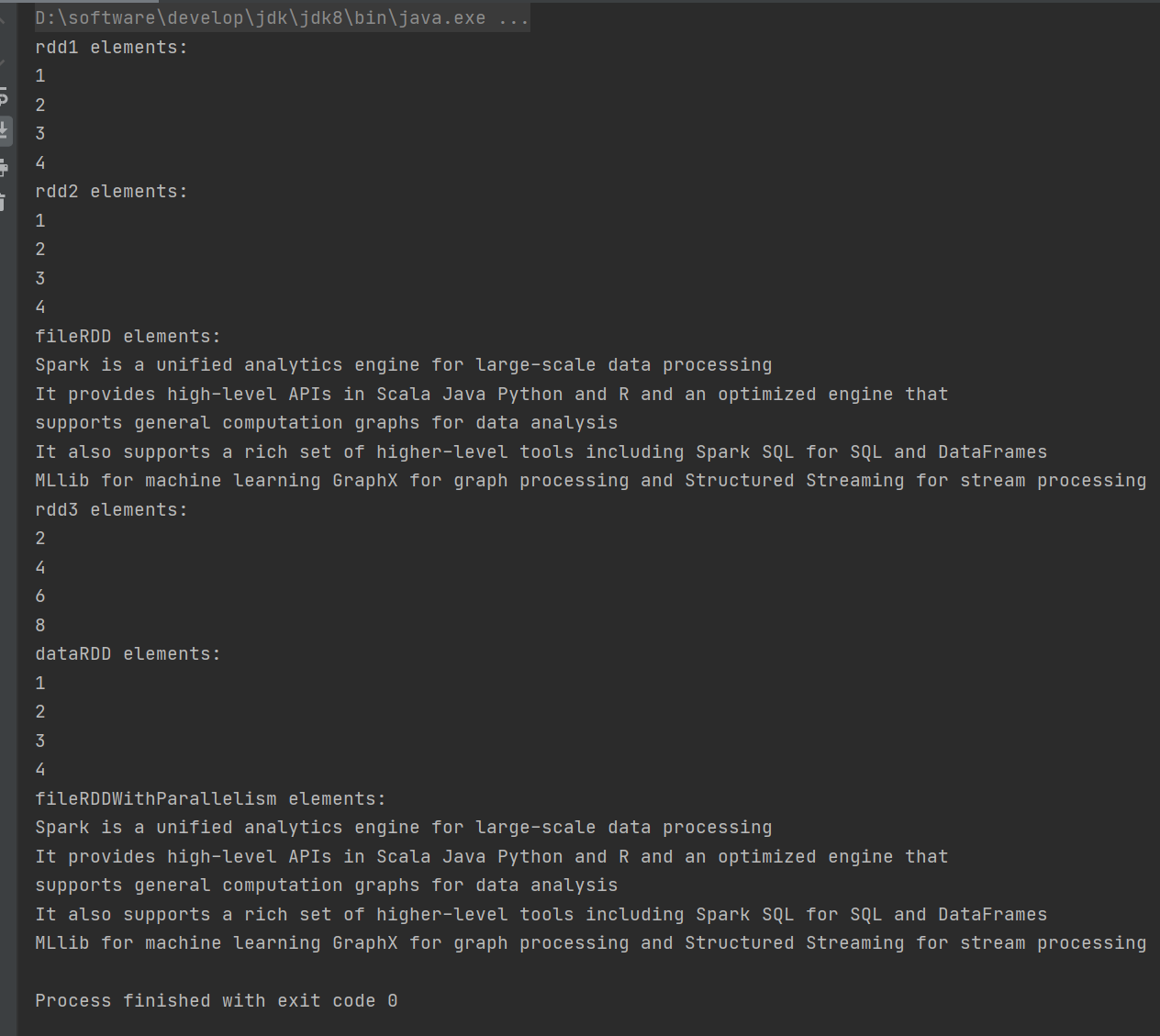
println("rdd1 elements:")
rdd1.collect().foreach(println)
println("rdd2 elements:")
rdd2.collect().foreach(println)
// 2) 从外部存储(文件)创建 RDD
val fileRDD: RDD[String] = sparkContext.textFile("spark-core/input")
println("fileRDD elements:")
fileRDD.collect().foreach(println)
// 3) 从其他 RDD 创建
val rdd3 = rdd1.map(_ * 2)
println("rdd3 elements:")
rdd3.collect().foreach(println)
// 4) 直接创建 RDD(new),一般由 Spark 框架自身使用,这里不做演示
// RDD 并行度与分区
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 4)
val fileRDDWithParallelism: RDD[String] = sparkContext.textFile("spark-core/input", 2)
println("dataRDD elements:")
dataRDD.collect().foreach(println)
println("fileRDDWithParallelism elements:")
fileRDDWithParallelism.collect().foreach(println)
sparkContext.stop()
}
} 
RDD转换算子
Value类型
首先添加以下前提
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDTransformations {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_function")
val sparkContext = new SparkContext(sparkConf)
sparkContext.stop()
}}RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型
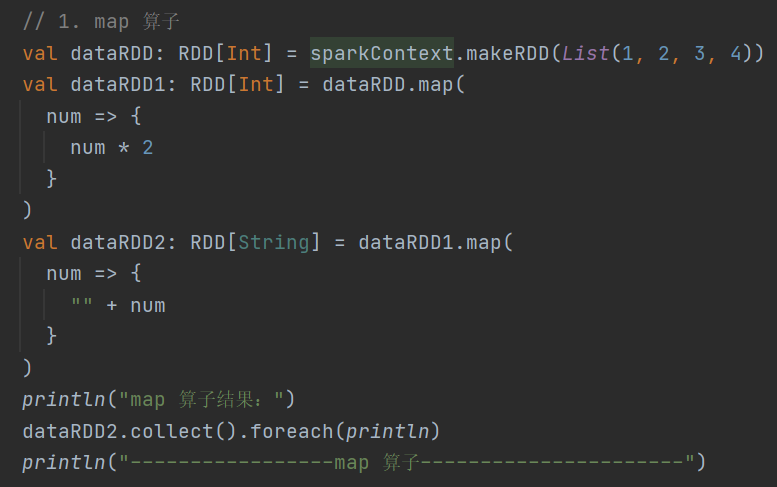
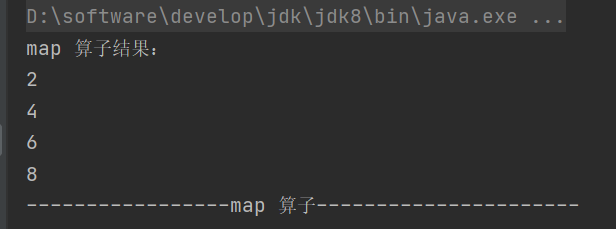
1.map
def map[U: ClassTag](f: T => U): RDD[U]对 RDD 里的数据逐条进行映射转换,能够实现类型或者值的转换
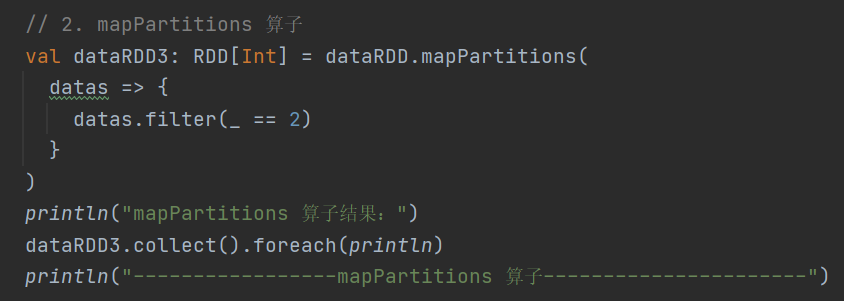
2.mapPartitions
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]以分区为单位对数据进行批处理操作,可在计算节点上对数据开展任意处理

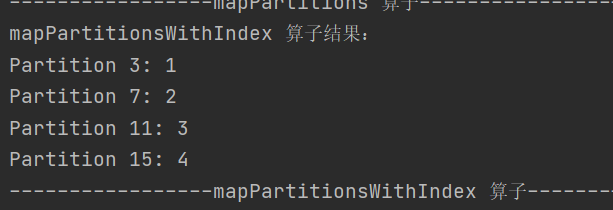
3.mapPartitionsWithIndex
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]和 mapPartitions 类似,不过在处理时能获取当前分区的索引

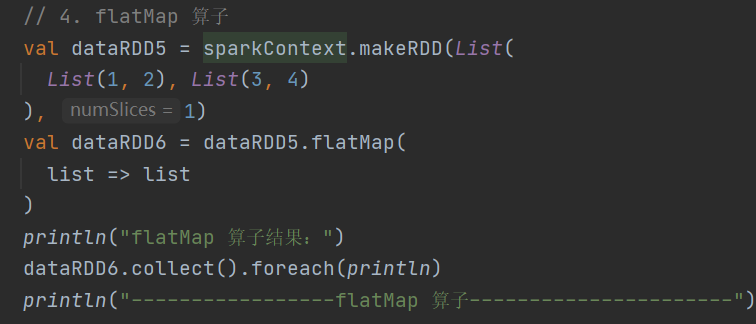
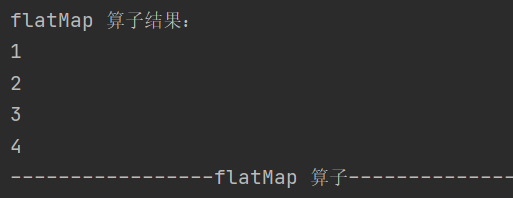
4.flatMap
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]先对数据进行扁平化处理,再进行映射操作
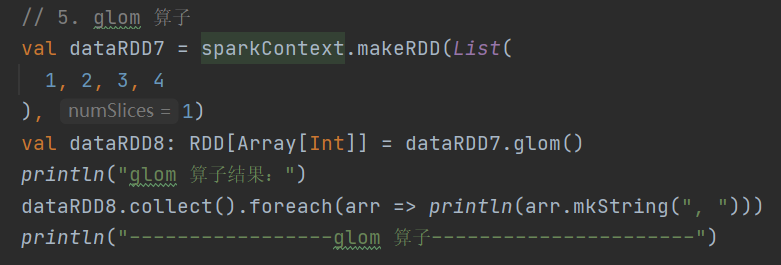
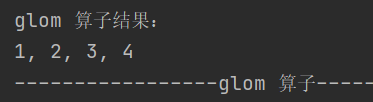
5.glom
def glom(): RDD[Array[T]]把同一个分区的数据转换为相同类型的内存数组,分区保持不变
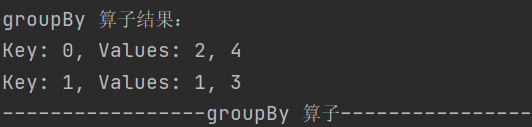
6.groupBy
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]按照指定规则对数据进行分组,会产生 shuffle 操作

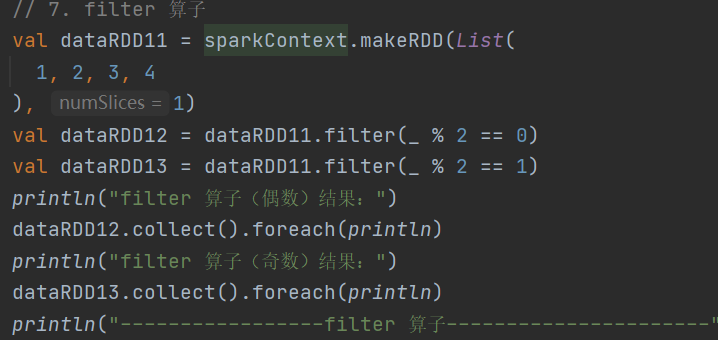
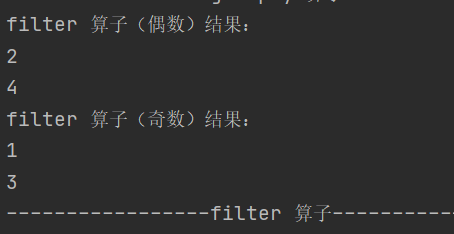
7.filter
def filter(f: T => Boolean): RDD[T]依据指定规则筛选过滤数据,符合规则的数据会被保留
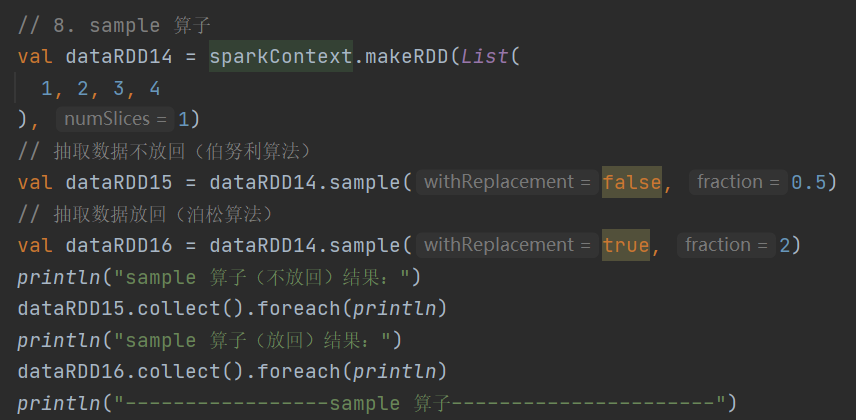
8.sample
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]按照指定规则从数据集中抽取数据,支持放回和不放回抽样

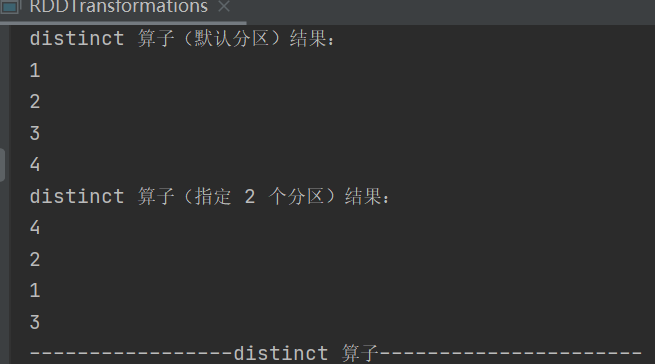
9.distinct
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]去除数据集中的重复数据

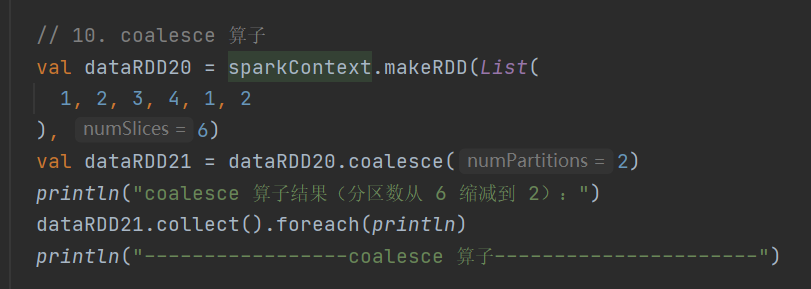
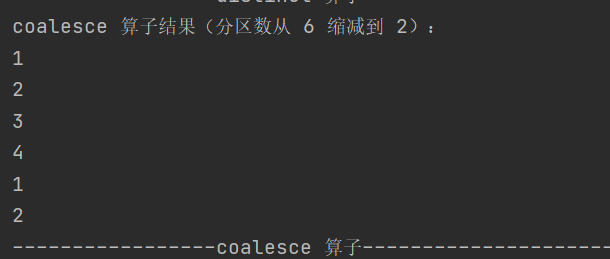
10.coalesce
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T]根据数据量缩减分区,降低任务调度成本
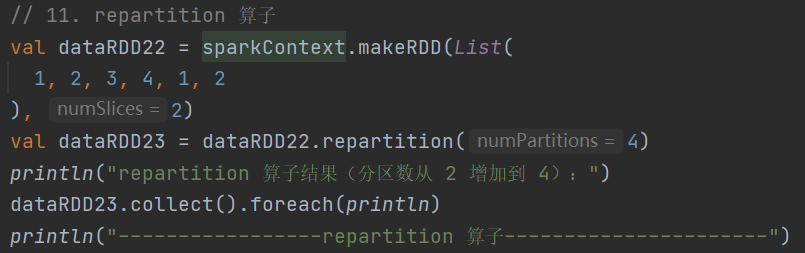
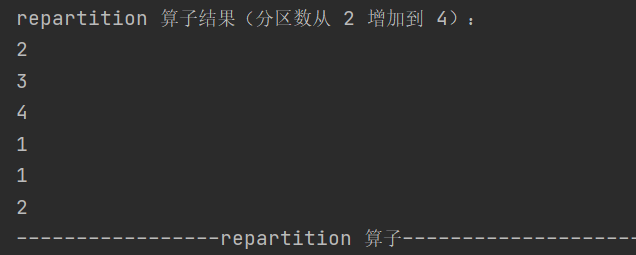
11.repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]可增加或减少分区数,内部会进行 shuffle 操作
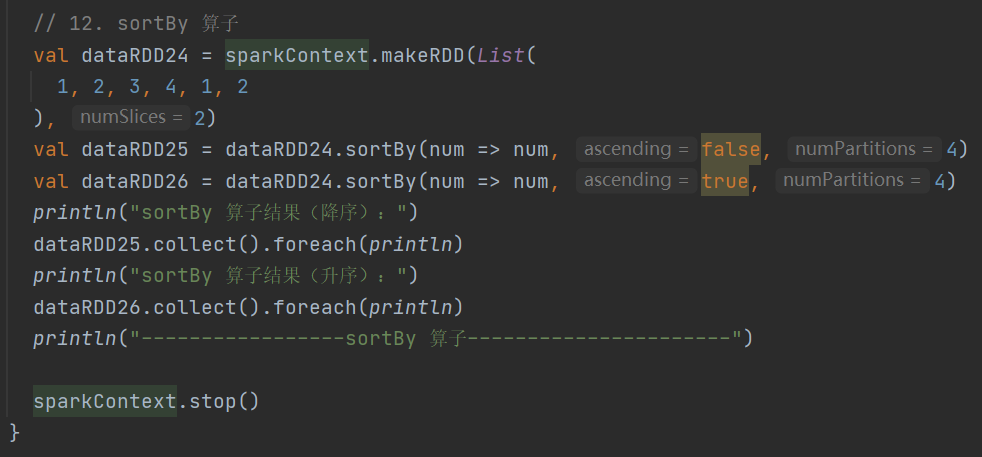
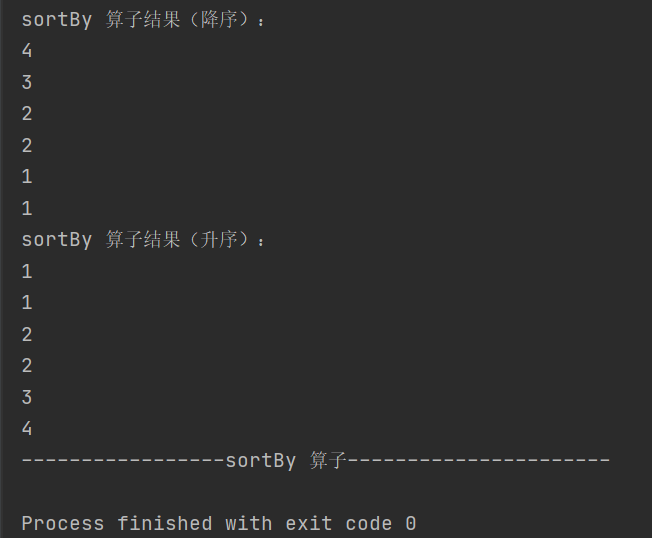
12.sortBy
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]对数据进行排序,可指定排序规则和分区数
双Value类型
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDDoubleValueTransformations {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDDoubleValue_function")
val sparkContext = new SparkContext(sparkConf)
sparkContext.stop()
}
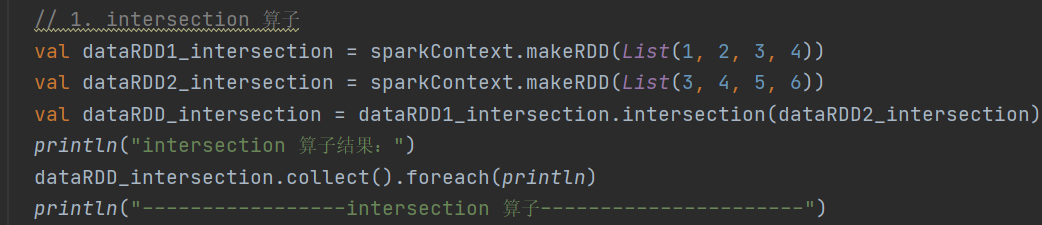
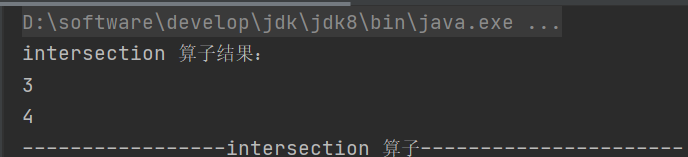
}1. intersection
def intersection(other: RDD[T]): RDD[T]求两个 RDD 的交集
2.union
def union(other: RDD[T]): RDD[T]求两个 RDD 的并集,重复数据不会去重
3.subtract
def subtract(other: RDD[T]): RDD[T]以源 RDD 元素为主,去除两个 RDD 中的重复元素,保留源 RDD 的其他元素
4.zip
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]将两个 RDD 中的元素以键值对的形式合并
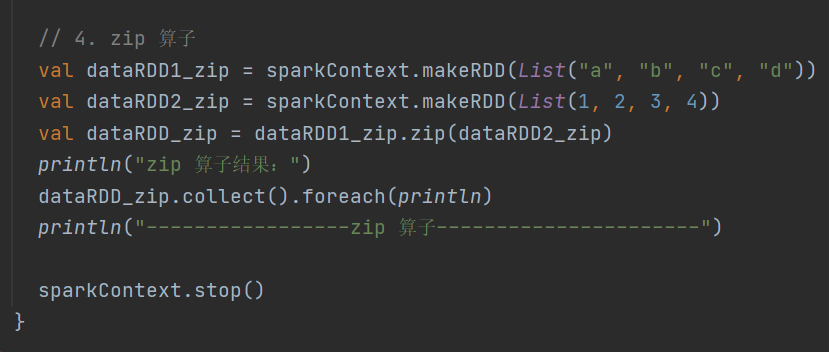
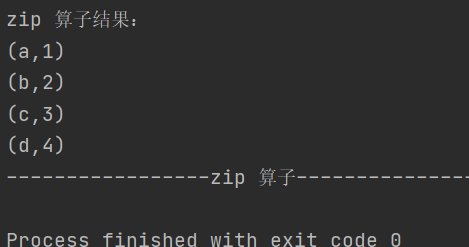
Key-Value类型
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object RDDKeyValueTransformations {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDKeyValue_function")
val sc = new SparkContext(sparkConf)
sc.stop()
}
}1.partitionBy
def partitionBy(partitioner: Partitioner): RDD[(K, V)]按照指定的 Partitioner 对数据重新分区

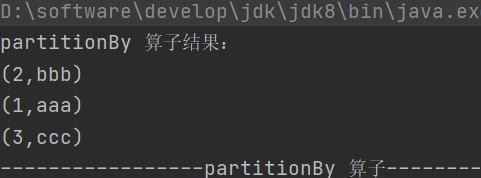
2.groupByKey
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]依据 key 对 value 进行分组
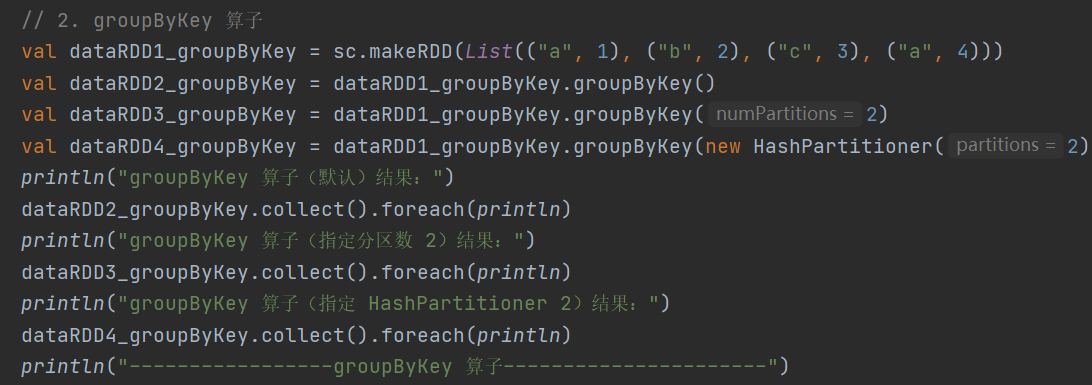

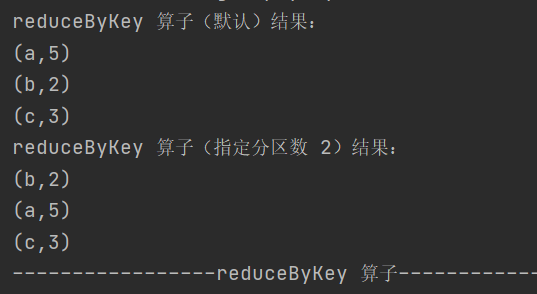
3.reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]按照相同的 key 对 value 进行聚合,可在 shuffle 前进行预聚合,性能较高

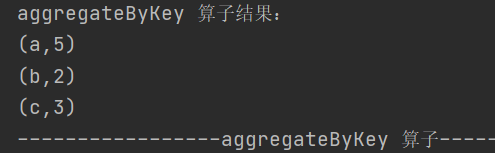
4.aggregateByKey
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]按照不同规则进行分区内和分区间的计算

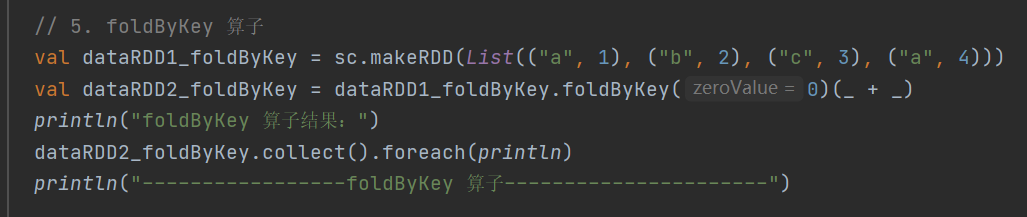
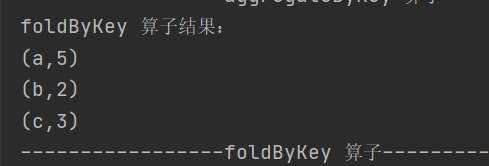
5.foldByKey
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]当分区内和分区间的计算规则相同时,可简化 aggregateByKey 的使用
6.combineByKey
def combineByKey[C](
createCombiner: V => C,//将当前值作为参数进行附加操作并返回
mergeValue: (C, V) => C,// 在分区内部进行,将新元素V合并到第一步操作得到的C中
mergeCombiners: (C, C) => C): RDD[(K, C)]//将第二步操作得到的C进行分区间计算最通用的对 key - value 型 RDD 进行聚集操作的函数,允许返回值类型与输入不同
示例:现有数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),求每个key的总值及每个key对应键值对的个数
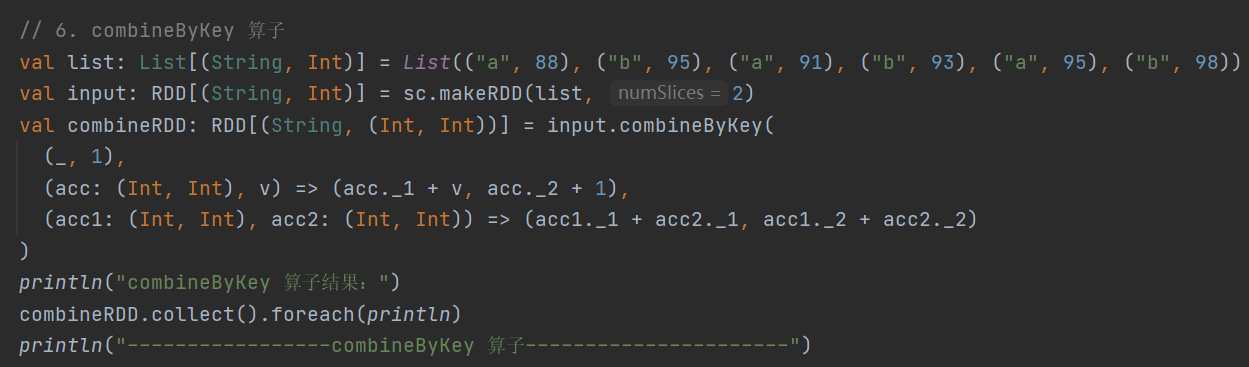

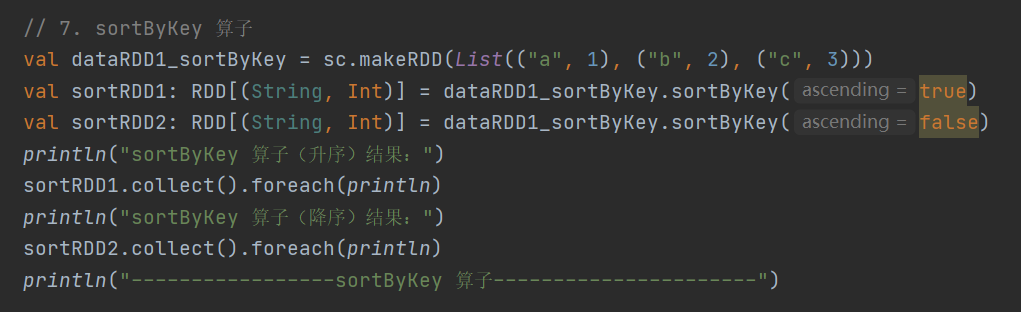
7.sortByKey
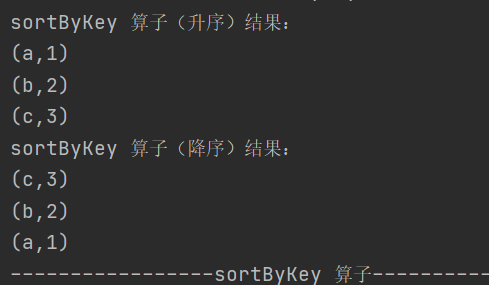
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]按照 key 对 RDD 进行排序
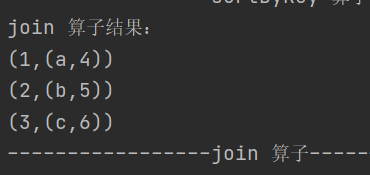
8. join
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]对两个类型为 (K, V) 和 (K, W) 的 RDD 进行连接操作

9. leftOuterJoin
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]类似于 SQL 中的左外连接

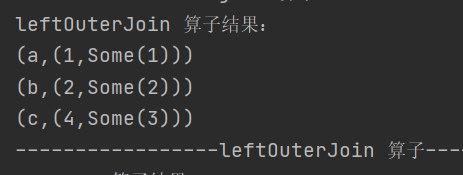
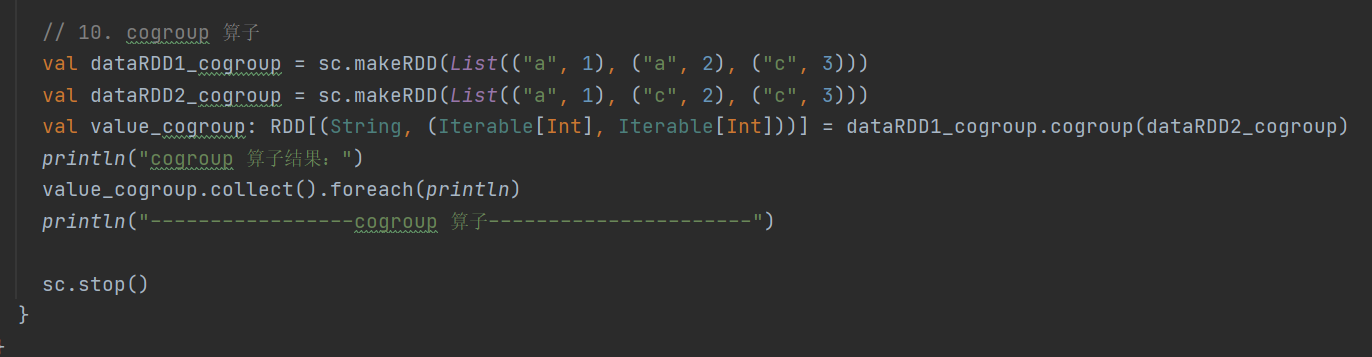
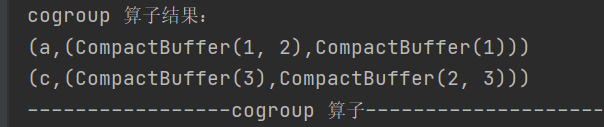
10.cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]对两个类型为 (K, V) 和 (K, W) 的 RDD 进行分组操作