用到的技术:
通过腾讯OCR文字识别,deepseek的api实现
目录
需求分析:
需要将任意图片中的信息中提取文字,随后将文字提交给deepseek要求其提取自定义的关键信息
这里以简历为例子,首先将简历的文字识别,随后将简历文字交给deepseek,要求其提取中简历中人员的关键信息并且返回json字符串,从而将字符串来反序列化为对象
文字识别(OCR)具体实现步骤
起步工作
首先在腾讯云中进行登录以及注册,随后进入到腾讯云OCR的快速入门教学(链接:文字识别 一分钟接入服务端 API_腾讯云),跟随教学开通文字识别服务,进入文字识别控制台开通,获取到免费的额度
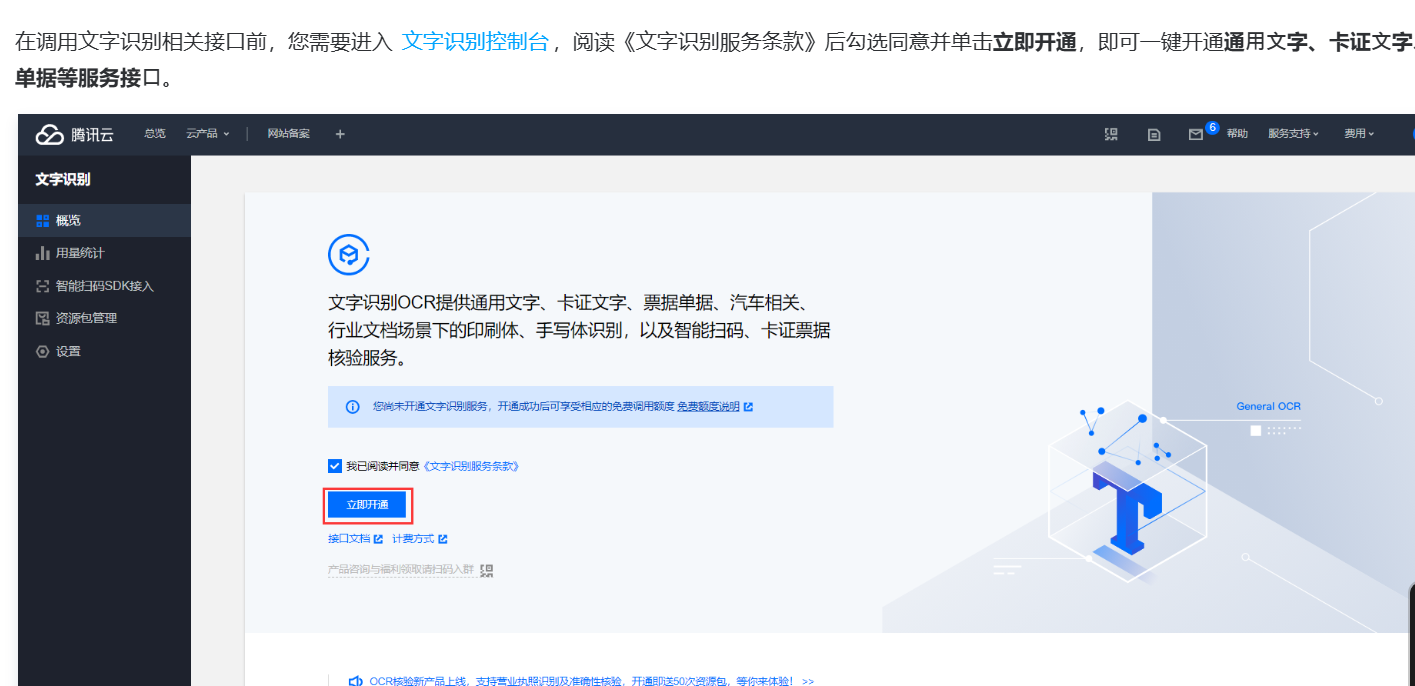
随后跟随教学页面,获取到我们主要需要的两个参数,文字识别api的sercrekey以及sercrevalue
代码编写
配置文件编写
获取到腾讯OCRapi的secrekey以及sercrevalue之后,我们首先将获取到的这两个写入到配置文件application.yml中,里面放入自己的api的对应的的两个值
java
TENCENT:
TENCENT_SERCREKEY: "xxxxxxxxxxxxxxxxxxxxxxxx"
TENCENT_SERCREVALUE: "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"工具类编写
在开始调用文字识别api的时候,我们需要先根据我们获取的api的key以及value来验证并创建认证对象,创建HTTP配置,创建客户端配置来创建OCR客户端实例(用来调用文字识别api)
java
package cn.enilu.flash.utils;
import com.tencentcloudapi.common.Credential;
import com.tencentcloudapi.common.exception.TencentCloudSDKException;
import com.tencentcloudapi.common.profile.ClientProfile;
import com.tencentcloudapi.common.profile.HttpProfile;
import com.tencentcloudapi.ocr.v20181119.OcrClient;
import com.tencentcloudapi.ocr.v20181119.models.GeneralBasicOCRRequest;
import com.tencentcloudapi.ocr.v20181119.models.GeneralBasicOCRResponse;
import com.tencentcloudapi.ocr.v20181119.models.TextDetection;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class OcrClientUtil {
@Value("${TENCENT.TENCENT_SERCREKEY}")
private String secretKey;
@Value("${TENCENT.TENCENT_SERCREVALUE}")
private String secretValue;
/**
* 创建OCR客户端
* @return OCR客户端实例
*/
public OcrClient createOcrClient() {
try {
// 创建认证对象,需要提供你api的key以及value
Credential cred = new Credential(
secretKey,
secretValue
);
// 创建HTTP配置
HttpProfile httpProfile = new HttpProfile();
httpProfile.setEndpoint("ocr.tencentcloudapi.com");
// 创建客户端配置
ClientProfile clientProfile = new ClientProfile();
clientProfile.setHttpProfile(httpProfile);
// 返回OCR客户端实例
return new OcrClient(cred, "", clientProfile);
} catch (Exception e) {
log.error("创建OCR客户端失败", e);
throw new RuntimeException("创建OCR客户端失败", e);
}
}
}获取到了OCR客户端实例后,就能使用OCR客户端来调用通用文字识别接口,我们需要提供的是pdf文件的链接(注意是链接,不是文件,可以先将文件上传至OSS中获取文件链接)
java
public String userGeneralBasicOCR(String pdfUrl) {
OcrClient client = createOcrClient();
// 实例化一个请求对象,每个接口都会对应一个request对象
GeneralBasicOCRRequest req = new GeneralBasicOCRRequest();
if(pdfUrl == null){
throw new RuntimeException("pdfUrl不能为空");
}
req.setImageUrl(pdfUrl);
req.setLanguageType("zh");
req.setIsPdf(true);
GeneralBasicOCRResponse response=new GeneralBasicOCRResponse();
try{
response=client.GeneralBasicOCR(req);
} catch (TencentCloudSDKException e) {
System.out.println(e.toString());
}
TextDetection[] textDetections = response.getTextDetections();
if (textDetections == null || textDetections.length == 0) {
throw new RuntimeException("简历信息为空");
}
StringBuilder detectedTextBuilder = new StringBuilder();
for (TextDetection textDetection : textDetections) {
detectedTextBuilder.append(textDetection.getDetectedText());
}
return detectedTextBuilder.toString();
}代码解析
req.setImageUrl(pdfUrl);---》设置要进行文字识别文件的url
req.setLanguageType("zh");---》设置识别文字的语言类型,zh可以实现中英文的识别,想要更多的语言参数设置为auto,自动识别文字内容
GeneralBasicOCRResponse response=new GeneralBasicOCRResponse();获取到文字识别的结果
TextDetection\[\] textDetections = response.getTextDetections();获取到文字识别内容中的文字内容,文字识别的结果不仅仅包含文字,还有文字的坐标准确度等等,可以自行打印response查看有上面信息
测试类实验
java
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
@RunWith(SpringJUnit4ClassRunner.class)
@ComponentScan(basePackages = "cn.enilu.flash.api")
public class OcrClientUtilTest {
@Autowired
private OcrClientUtil ocrClientUtil;
@Test
public void tryGetMessage(){
//可以不是jpg,也可以是pdf等等
String generalBasicOCRResponse = ocrClientUtil.userGeneralBasicOCR("xxxx.pdf");
//随后就是直接看答案
System.out.println(generalBasicOCRResponse);
}
}实验对象

识别结果示例
老鱼简历J 12345678909 java@gmail.com在职资深
Java开发工程师老鱼简历教育经历清华大学计算机科学与技术2019-09 ~ 2023-07
全日制计算机学院专业技能Java熟练掌握Java 后端开发,包括Java 核心技术、Spring 框架、MyBatis 等数据库
老鱼简历老鱼简熟悉关系型数据库(如MySQL)和非关系型数据库(如MongoDB)
,能够编写高效的SQL查询语句网络编程具备网络编程基础,了解TCP/IP、HTTP协议,能够进行网络通信、接口调试等
工作经历ABC科技有限公司2020-01~ 2021-01软件开发部Java 后端开发工程师北京负责公司内部物流管理系统的开发和维护,参与需求分析、数据库设计、接口开发等工作,主要使用Java、Spring Boot、MySQL 等技术。解决了系统性能瓶颈问题,优化了查询速度,提升了用户体验。
XYZ软件公司2019-01~2020-01云计算部Java 开发工程师上海参与公司自研云平台的开发与维护,负责用户管理、权限控制、日志记录等功能模块的设计和实现。使用Java、Spring Cloud、MySQL 等技术,解决了平台稳定性和可扩展性的问题,提供了良好的用户体验。项目经历订单管理系统2021-03 ~ 2021-05
Java后端开发工程师北京老鱼简迂包主工首竺田亥弦的巨毕工尖句手工首净悠收本询竺陆此的迟斗n守现声田3注意!
该文字识别只能实现识别一页pdf,如果需要识别多页pdf需要自己设计分页传输并且多次调用接口
deepseek整合消息,返回文本关键信息
起步工作
首先就是要获取到deepseek的api的key

随后将获取到的key写入配置文件或者直接明文写入代码
需要添加的依赖
java
<dependencies>
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>3.4.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<!-- HTTP客户端 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.9.0</version>
</dependency>
<!-- JSON处理 -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>com.mashape.unirest</groupId>
<artifactId>unirest-java</artifactId>
<version>1.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpasyncclient</artifactId>
<version>4.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpmime</artifactId>
<version>4.3.6</version>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20140107</version>
</dependency>
</dependencies>编写工具类
注意,下面代码中写到的deepseek的api的key需要写入自己的
java
import cn.enilu.flash.bean.entity.zhiyou.user.DeeseekRequest;
import cn.enilu.flash.bean.entity.zhiyou.user.ResumeInfo;
import cn.enilu.flash.bean.entity.zhiyou.user.WorkExperience;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.google.gson.Gson;
import com.mashape.unirest.http.Unirest;
import com.mashape.unirest.http.exceptions.UnirestException;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringEscapeUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.mashape.unirest.http.HttpResponse;
import java.util.ArrayList;
import java.util.List;
/**
* 调用deepseek处理信息
*
*/
@Component
@Slf4j
public class DeepSeekUtil {
@Autowired
private OcrClientUtil ocrClientUtil;
private final Gson gson = new Gson();
public ResumeInfo askDeepSeek(String pdfUrl){
Unirest.setTimeouts(0, 0);
//DeeseekRequest: 自己的实体类名称
List<DeeseekRequest.Message> messages = new ArrayList<>();
//给deepSeek一个角色
messages.add(DeeseekRequest.Message.builder().role("system").content("你负责给我格式化简历字符串信息").build());
// question:说你自己想说的话
StringBuilder question= new StringBuilder(ocrClientUtil.userGeneralBasicOCR(pdfUrl));
question.append("\n现在我要求你格式化上面的信息,并且以json字符串格式返回信息方便我后续解析成java对象,有的话给出值,没有的话直接给出空,以下是希望你从上面信息中获取的信息" +
"\n1.username,2.school,3.email,4.phone,5.education,6.major,7.graduationYear,8.workExperience,我要求其中每一个值长度不超过15,并且在输出开始输出一个startX,结束的地方输出一个endX");
messages.add(DeeseekRequest.Message.builder().role("user").content(question.toString()).build());
DeeseekRequest requestBody = DeeseekRequest.builder()
.model("deepseek-chat")
.messages(messages)
.build();
HttpResponse<String> response = null;
try {
response = Unirest.post("https://api.deepseek.com/chat/completions")
.header("Content-Type", "application/json")
.header("Accept", "application/json")
.header("Authorization", "Bearer "+"你自己获取到的deepseek的api的key")
.body(gson.toJson(requestBody))
.asString();
} catch (UnirestException e) {
throw new RuntimeException(e);
}
String ansString = response.getBody();
// 找到 startX 和 endX 的位置
int startIndex = ansString.indexOf("startX") + "startX".length();
int endIndex = ansString.indexOf("endX");
if (startIndex != -1 && endIndex != -1) {
// 截取 startX 和 endX 之间的内容
ansString = ansString.substring(startIndex + 2, endIndex - 2).trim();
} else {
throw new RuntimeException("未检测到有效简历信息");
}
ansString=StringEscapeUtils.unescapeJava(ansString);
ResumeInfo resume=new ResumeInfo();
// 确保ansString是有效的JSON格式
if (ansString.startsWith("{") && ansString.endsWith("}")) {
JSONObject resumeInfoJson = JSONUtil.parseObj(ansString);
resume = JSONUtil.toBean(resumeInfoJson, ResumeInfo.class);
List<WorkExperience> workExperience = resume.getWorkExperience();
} else {
System.out.println("Extracted content is not a valid JSON.");
}
return resume;
}
}代码解析
返回的实体对象再下面具体调用实现
工具类用于处理简历 PDF,自动提取并结构化简历信息,主要流程如下:
- OCR识别: 通过 OCR 工具读取简历中的文本内容。
- 构造请求: 把文本内容发送给 DeepSeek 大模型,请求其格式化为结构化 JSON。
- 接口调用: 调用 DeepSeek 接口获取模型返回结果。
- 结果解析: 提取模型返回的 JSON 并转为 ResumeInfo 对象,便于后续处理。
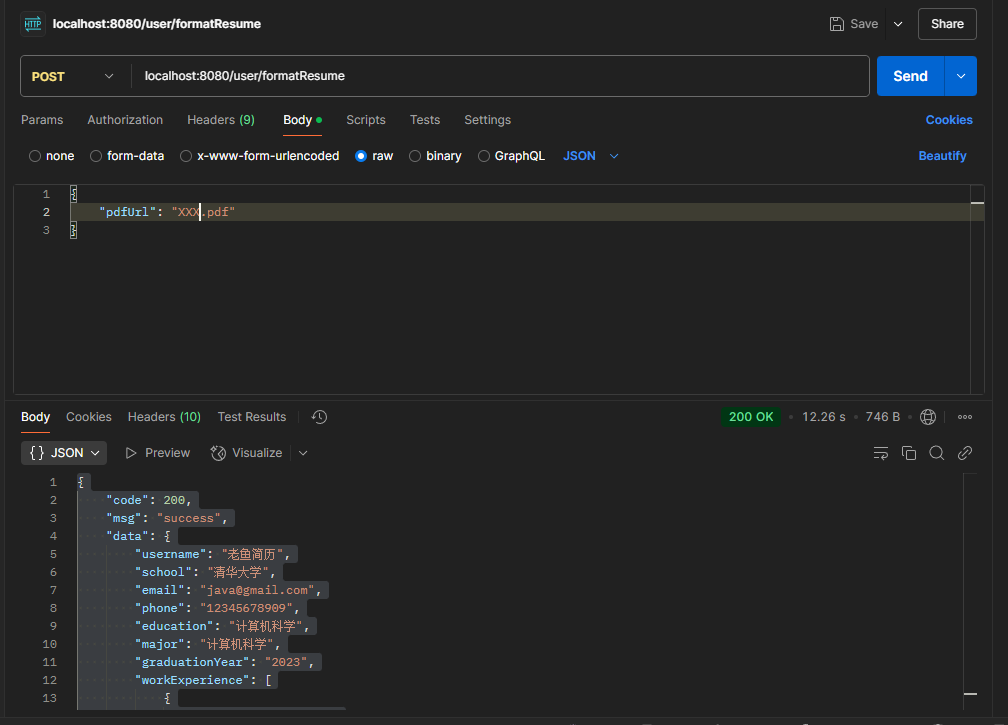
具体测试调用结果
需要注意,这里我们要传入的是要识别的图片的url(这里是简历的url,也就是pdf结尾的文件),不是直接上传文件,可以考虑使用OSS对象存储技术存储文件随后返回文件的url
实体类(其实就是url)
java
@Data
public class PdfRequest {
private String pdfUrl;
private String otherParam;
}返回结果实体类(也就是将返回的json字符串转为对象)
java
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class ResumeInfo {
private String username;
private String school;
private String email;
private String phone;
private String education;
private String major;
private String graduationYear;
private List<WorkExperience> workExperience;
}
java
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class WorkExperience {
private String company;
private String position;
private String period;
}controller层:
java
@PostMapping("/formatResume")
public CommonResponse formatResume(@RequestBody PdfRequest pdfRequest){
return resumeService.formatResume(pdfRequest);
}service层
java
@Autowired
private AliOSSUtil ossUtil;
@Autowired
private DeepSeekUtil deepSeekUtil;
@Override
public CommonResponse formatResume(PdfRequest pdfRequest) {
if(pdfRequest==null){
//简历不存在
throw new ApplicationException(ApplicationExceptionEnum.RESUME_NOT_FOUND);
}
String pdfUrl = pdfRequest.getPdfUrl();
if(pdfUrl==null||StringUtils.isBlank(pdfUrl)){
throw new ApplicationException(ApplicationExceptionEnum.RESUME_LINK_EMPTY);
}
ResumeInfo resumeInfo = deepSeekUtil.askDeepSeek(pdfUrl);
if(resumeInfo!=null){
return new CommonResponse(200,"success",resumeInfo);
}
return new CommonResponse(404,"Resume not found",null);
}具体运行结果:
文字识别并且提取创建信息后返回的结果